
重返谷歌的Transformer作者,开始掌管Gemini AI
重返谷歌的Transformer作者,开始掌管Gemini AINoam Shazeer 2021 年离职谷歌,3 年后又以特殊方式重回谷歌。
来自主题: AI资讯
11436 点击 2024-08-23 17:42
 搜索
搜索
Noam Shazeer 2021 年离职谷歌,3 年后又以特殊方式重回谷歌。

AI,智能体,ADAS,元智能体搜索,模型训练
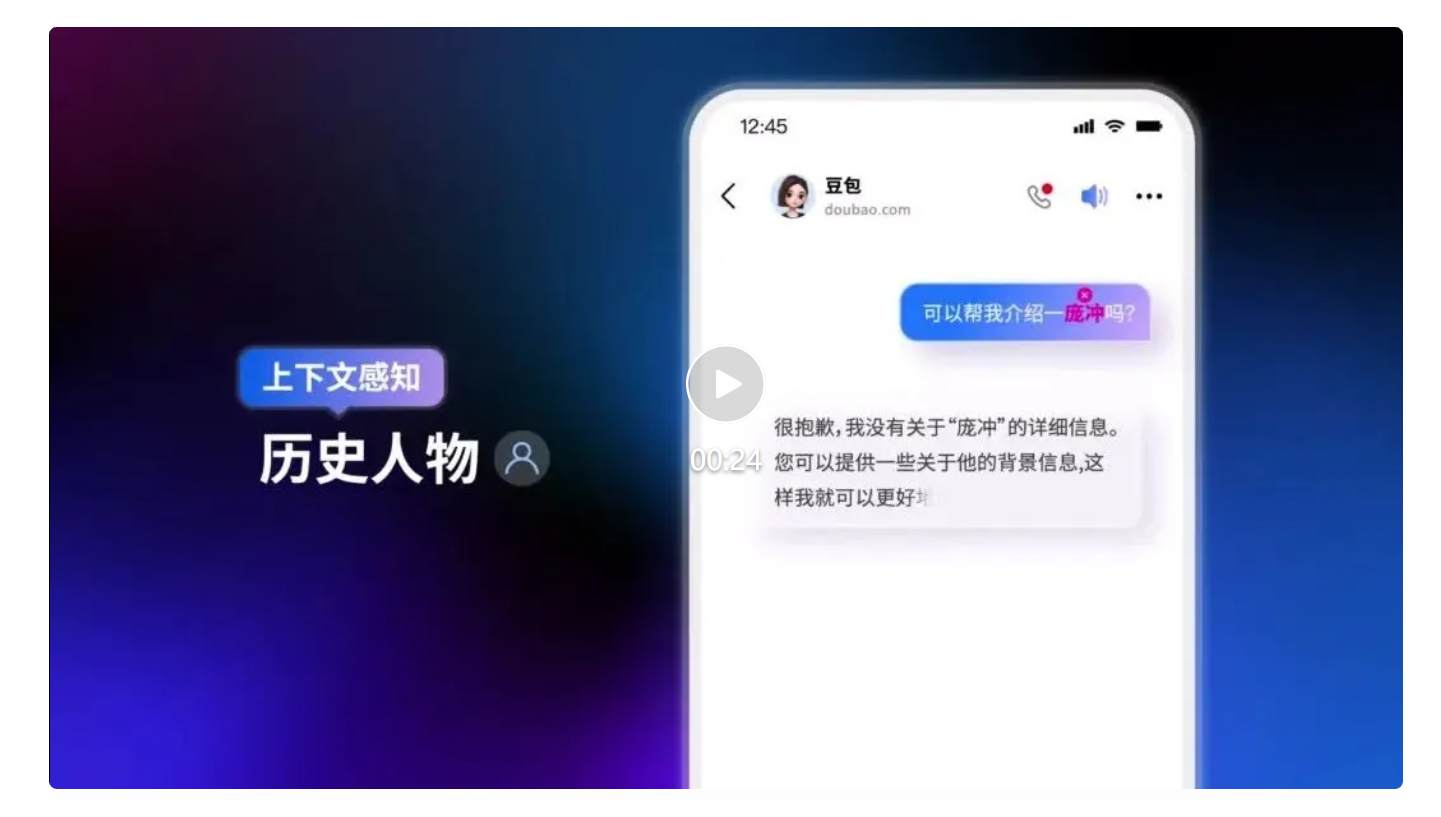
8 月 21 日,2024 火山引擎 AI 创新巡展﹒上海站带来了豆包大模型最新进展。

Emory大学的研究团队提出了一种创新的方法,将大语言模型(LLM)在文本图(Text-Attributed Graph, 缩写为TAG)学习中的强大能力蒸馏到本地模型中,以应对文本图学习中的数据稀缺、隐私保护和成本问题。通过训练一个解释器模型来理解LLM的推理过程,并对学生模型进行对齐优化,在多个数据集上实现了显著的性能提升,平均提高了6.2%。

人自信的时候,说话都会变得坦率很多。

浙江宁波,吉利旗下极氪的汽车工厂里,10多公斤重的箱子被双手抬起,稳稳放到流水线里,而这个搬运任务已经连续执行了21天。

AI视频生成技术又一里程碑
Midjourney推网页版编辑器应对Ideogram 2.0竞争。

这场峰会到底说了什么?一文速览2024全球品牌都在如何用AI。

随着萝卜快跑在武汉进行规模式投放,自动驾驶的热度再次升高。自 2009 年,Google 便开始试验无人驾驶技术,旗下无人出租车公司 Waymo 无疑是该领域的领跑者。目前,Waymo 每周单量已经超过中国最大自动驾驶出行平台萝卜快跑。