
2024大模型之战:从技术浪漫到落地求生
2024大模型之战:从技术浪漫到落地求生AI大模型技术商业化探索与竞争加剧。从业者们从技术浪漫到商业务实的心态转变,正不断推高大模型市场竞争的激烈程度。
来自主题: AI资讯
4777 点击 2024-10-08 11:34
 搜索
搜索
AI大模型技术商业化探索与竞争加剧。从业者们从技术浪漫到商业务实的心态转变,正不断推高大模型市场竞争的激烈程度。

Goodfire于2024年在旧金山成立,研发用于提高生成式AI模型内部运作可观察性的开发工具,希望提高AI系统的透明度和可靠性,帮助开发者更好地理解和控制AI模型。

来自中国科学技术大学数据空间研究中心、香港科技大学、香港理工大学以及奥胡斯大学的研究者们提出一种新的场景生成方法 DreamScene,只需要提供场景的文本就可以生成高质量,视角一致和可编辑的 3D 场景。

自去年以来,文本到图像生成模型取得了巨大进展,模型的架构从传统的基于UNet逐渐转变为基于Transformer的模型。
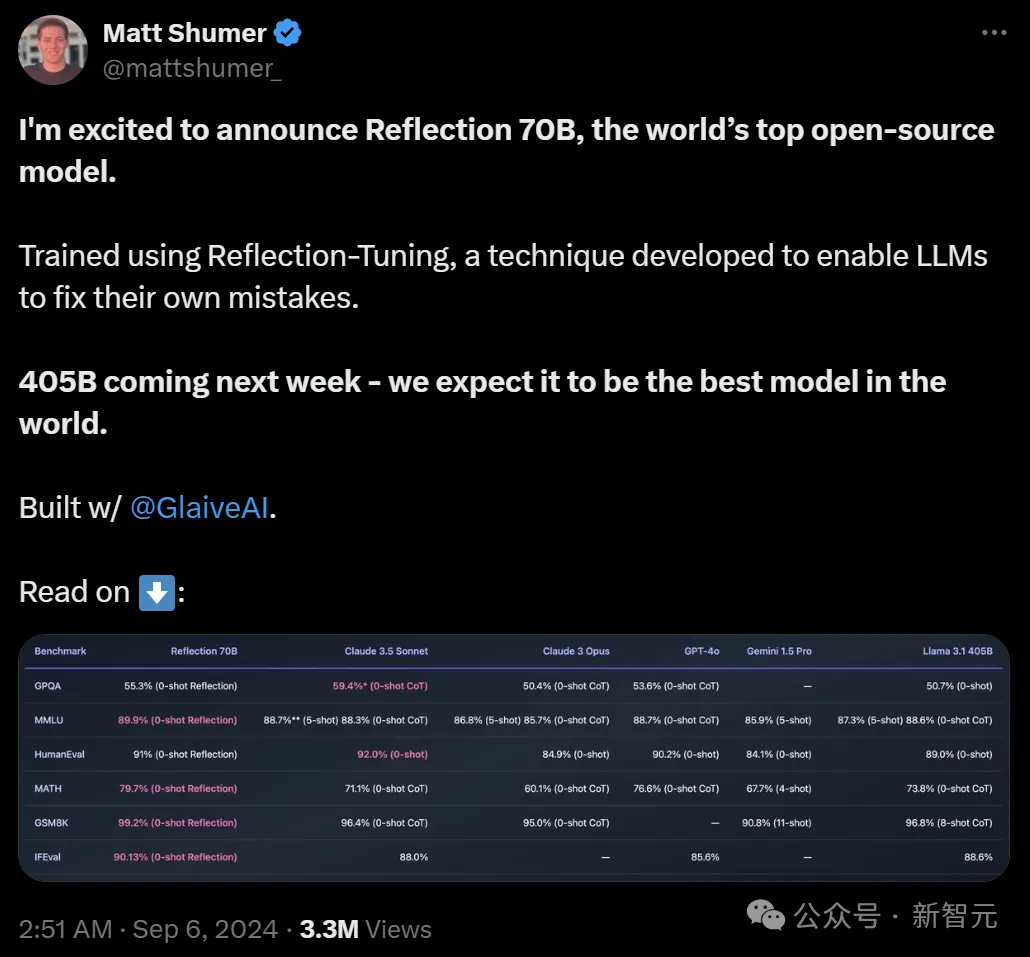
「开源新王」Reflection 70B,才发布一个月就跌落神坛了? 9月5日,Hyperwrite AI联创兼CEO Matt Shumer在X上扔出一则爆炸性消息—— 用Meta的开源Llama 3.1-70B,团队微调出了Reflection 70B。

研究显示,「国民基本收入」等于每年多放一个十一长假(不调休版),从 13 薪变 12 薪。

在AI技术广泛应用的企业场景中,提高检索准确度和效率已成为关键挑战。特别是面对生成式AI中的“幻觉”问题,企业急需有效解决方案。

通用机器人模型,目前最大的障碍便是「异构性」。

2024 年 7 月,清华大学计算机系 PACMAN 实验室发布开源深度学习编译器 MagPy,可一键编译用户使用 Python 编写的深度学习程序,实现模型的自动加速。
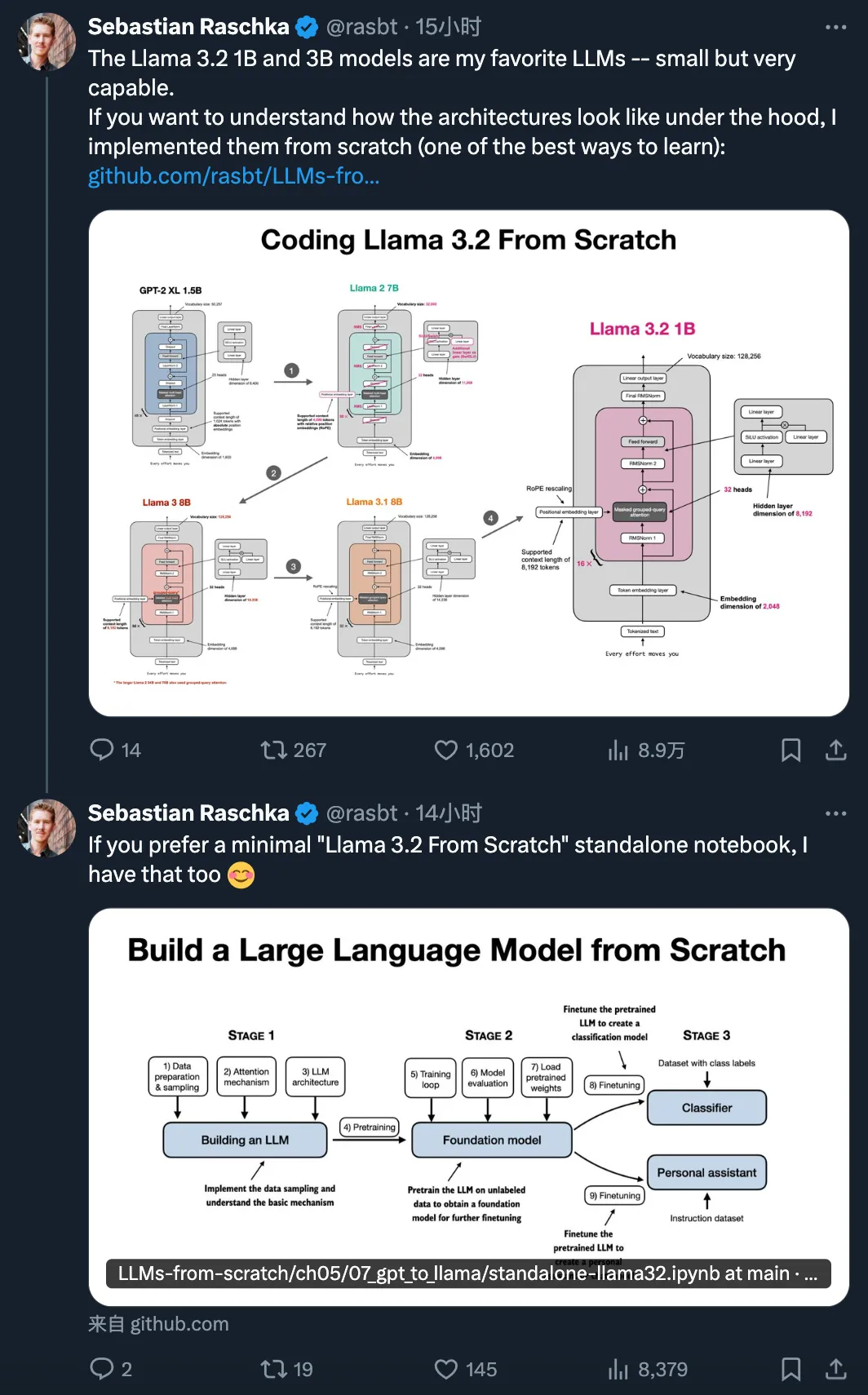
十天前的 Meta Connect 2024 大会上,开源领域迎来了可在边缘和移动设备上的运行的轻量级模型 Llama 3.2 1B 和 3B。两个版本都是纯文本模型,但也具备多语言文本生成和工具调用能力。Meta 表示,这些模型可让开发者构建个性化的、在设备本地上运行的通用应用 —— 这类应用将具备很强的隐私性,因为数据无需离开设备。