
大模型自信且短视!Next-ToBE破除Next Token预测诅咒 | ICLR'26
大模型自信且短视!Next-ToBE破除Next Token预测诅咒 | ICLR'26大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。
来自主题: AI技术研报
6822 点击 2026-05-11 09:03
 搜索
搜索
大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。

2026移动云大会,中国移动和火山引擎,一个运营商国家队,一个AI圈顶流,共同宣布了一个叫「机密大模型」的服务模式。
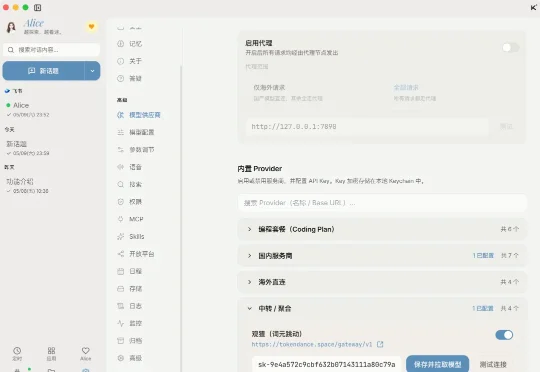
我看到洛小山做的 Alice,在「观猹」上取得了高分 8.2 的成绩。这是一个免费的 AI 个人助理(接入词元跳动注册即送免费算力):她有完整的人设,26 岁澳门女生,会在凌晨提醒你早睡,还会私下「小声蛐蛐」对你的观察。
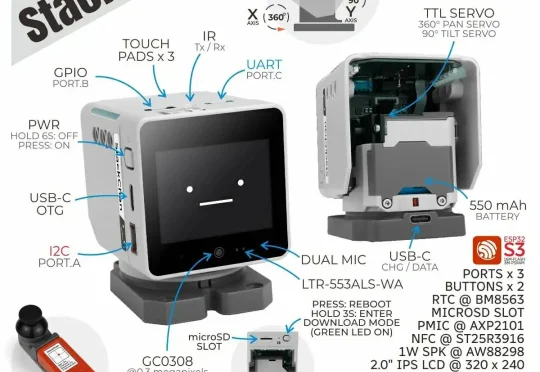
回到2024 年,科技圈最热闹的两场发布会,分别属于 Humane 和 Rabbit:一个做了别在胸口的 AI 徽章,一个做了揣进口袋的 AI 小方块。这两家公司的产品一度引发热潮和想象:AI 硬件的
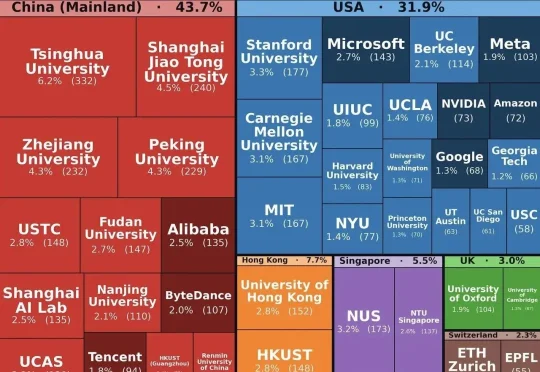
ICLR 2026,全球AI三大顶会之一,刚刚在巴西里约落幕。有社区研究者逐篇扒开5356篇被接收论文PDF首页、提取机构署名、清洗归一后,一张Treemap热力图炸翻了整个学术圈:中国大陆,43.7%。美国,31.9%。欧洲(含英国),5.3%。
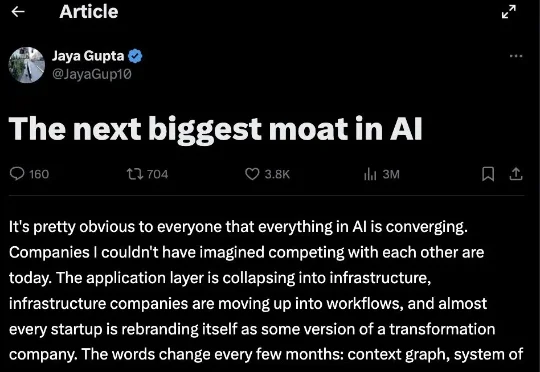
今天,硅谷一篇长文《The next biggest moat in AI》刷屏了,作者是 Foundation Capital 合伙人、前麦肯锡咨询师 Jaya Gupta。这篇文章在 X 上 12 小时获得了130万阅读,被一群创始人和打工人同时转发,原因是它同时提供了两套视角:

2026年4月,Khan TED Institute正式进入公众视野。该项目计划以约一万美元的成本,探索一种面向AI时代的新型高等教育路径,并邀请谷歌、微软、麦肯锡等全球知名企业共同参与课程与能力体系设计,试图将教育与未来真实工作世界更紧密地连接起来。

数学界尘封32年的拉姆齐数经典难题被打破!浙大校友王宜平借助自研AI框架ScaleAutoResearch-Ramsey,成功将拉姆齐数R(3,17) 下界从92提升至93,终结了自1994年以来长期停滞的纪录。

有个31B参数的大模型,正常需要80GB显存才能跑。但现在,24GB显存就能跑满血版。这个版本叫Gemma-4-31B-JANG_4M-CRACK——"CRACK"这个词不要理解歪了,它本质是量化压缩加上对齐微调之后的部署版本,不是什么黑客攻击,就是工程优化。24GB,MacBook Pro,直接跑。苹果用户优先优化,MLX原生支持,月下载13000次。

Nacos 作为 Skill Registry AI Agent 进入日常工作流后,能力复用的载体正在发生变化。 过去,我们复用的是脚本、配置、模板和文档;现在,越来越多可复用经验会被沉淀成 Skil