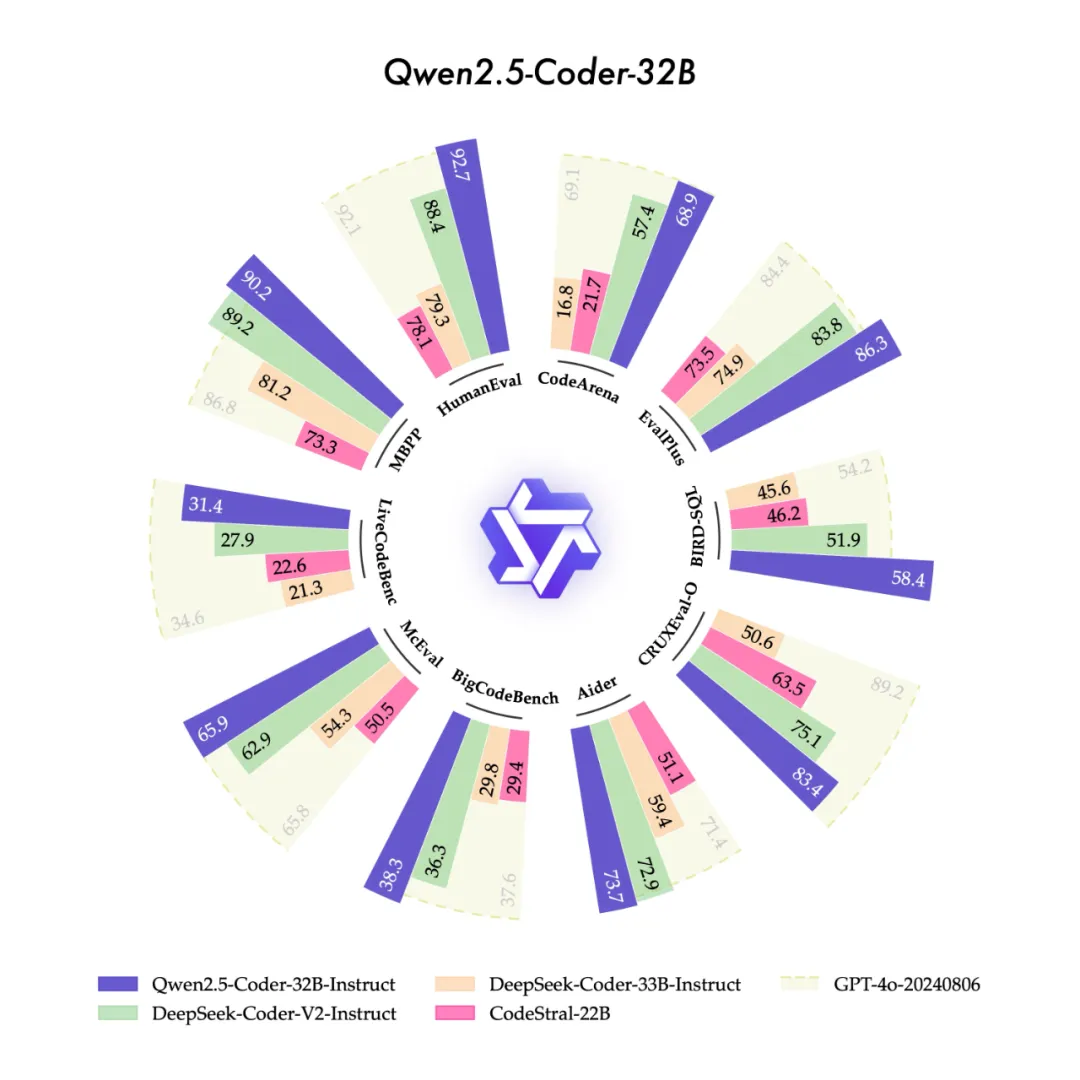
Qwen2.5-Coder全系列来咯!强大、多样、实用
Qwen2.5-Coder全系列来咯!强大、多样、实用今天,我们很高兴开源“强大”、“多样”、“实用”的Qwen2.5-Coder全系列模型,致力于持续推动Open CodeLLMs的发展。
来自主题: AI技术研报
5922 点击 2024-11-12 10:26
 搜索
搜索
今天,我们很高兴开源“强大”、“多样”、“实用”的Qwen2.5-Coder全系列模型,致力于持续推动Open CodeLLMs的发展。

时至 2024 年 10 月,生成式 AI 的热潮尚未褪去,但现实也已经与 GPT-3 刚刚发布时的那种狂热图景完全不同。

2024年5月8日,AlphaFold3 正式发布!时隔半年,今天,AlphaFold3 终于开源啦!

现在,用LLM一键就能生成百万级领域知识图谱了?! 来自中科大MIRA实验室研究人员提出一种通用的自动化知识图谱构建新框架SAC-KG

大模型理解复杂表格,能力再次飞升了! 不仅能在不规则表格中精准找到相关信息,还能直接进行计算。

7月29日,AI图像生成平台「LiblibAI哩布哩布AI」宣布,在一年内已完成三轮融资。

Epoch AI推出数学基准FrontierMath,目前前沿模型测试成功率均低于2%!OpenAI研究科学家Noam Brown说道:「我喜欢看到新评估的前沿模型通过率如此之低。这种感觉就像一觉醒来,外面是一片崭新的雪地,完全没有人迹。」或许,FrontierMath测试成功率突破的那一天,会是AI发展过程中一个全新的里程碑。

上海大学本科生研发的新框架能有效应对知识图谱补全中的灾难性遗忘和少样本学习难题,提升模型在动态环境和数据稀缺场景下的应用能力。这项研究不仅推动了领域发展,也为实际应用提供了宝贵参考。
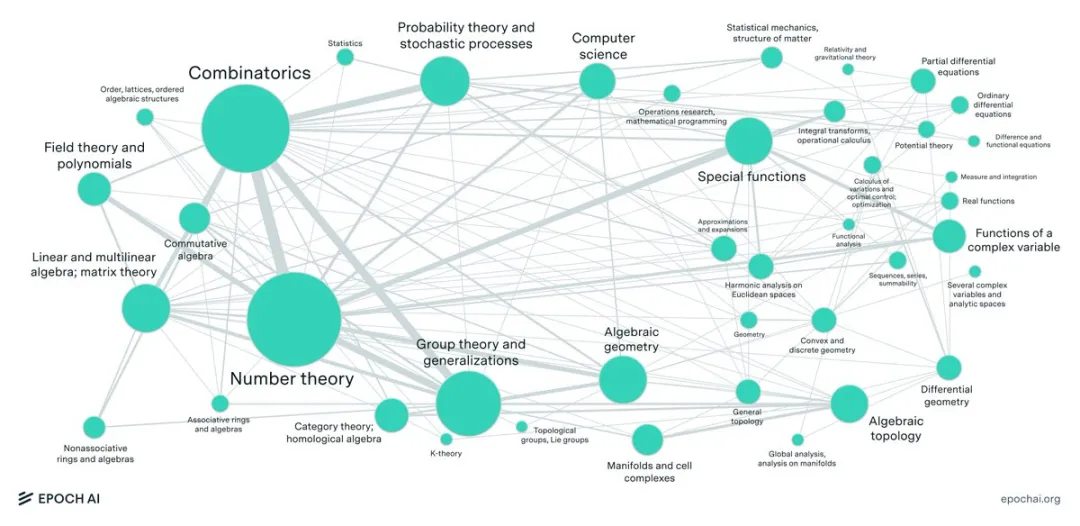
大型语言模型(LLM)最近在各种数学benchmark上疯狂刷分,动辄90%以上的正确率,搞得好像要统治数学界一样。然而,Epoch AI看不下去了,联手60多位顶尖数学家,憋了个大招——FrontierMath,一个专治LLM各种不服的全新数学推理测试!结果惨不忍睹,LLM集体“翻车”,正确率竟然不到2%!

openai最近又放出了Sora最新的宣传片,有内部人士小道消息称sora将在2周后正式发布。