
翁荔创业大模型首秀!告别“120亿美元估值0模型”
翁荔创业大模型首秀!告别“120亿美元估值0模型”AI再也不是“回合制”了。Thinking Machines Lab(以下简称TML)发布首个模型,让实时交互能力成为模型原生能力。联合创始人翁荔出镜演示。
来自主题: AI资讯
9348 点击 2026-05-12 17:07
 搜索
搜索
AI再也不是“回合制”了。Thinking Machines Lab(以下简称TML)发布首个模型,让实时交互能力成为模型原生能力。联合创始人翁荔出镜演示。
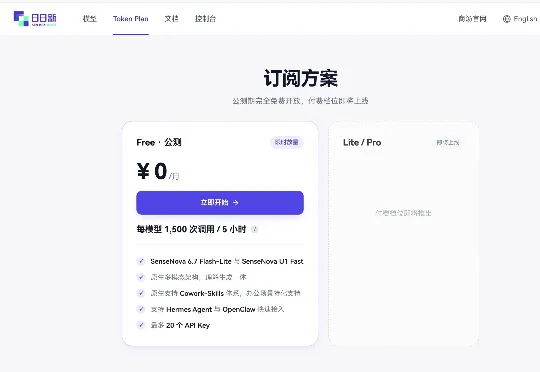
商汤最近做了一件大多数大模型公司都不舍得做的事。每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。

5月12日,小米集团总裁卢伟冰发文:为回馈全球开发者,小米正式启动「MiMo Orbit 100T Token 计划」,面向全球 AI 用户免费发放 Token 权益,计划在 30 天内累计发放 100 万亿 Token。

2011年,Marc Andreessen写下“软件正在吞噬世界”。2026 年,Fortune用了一句话总结当前局面:“那个吃掉世界的东西,正在被吃掉。 ”

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
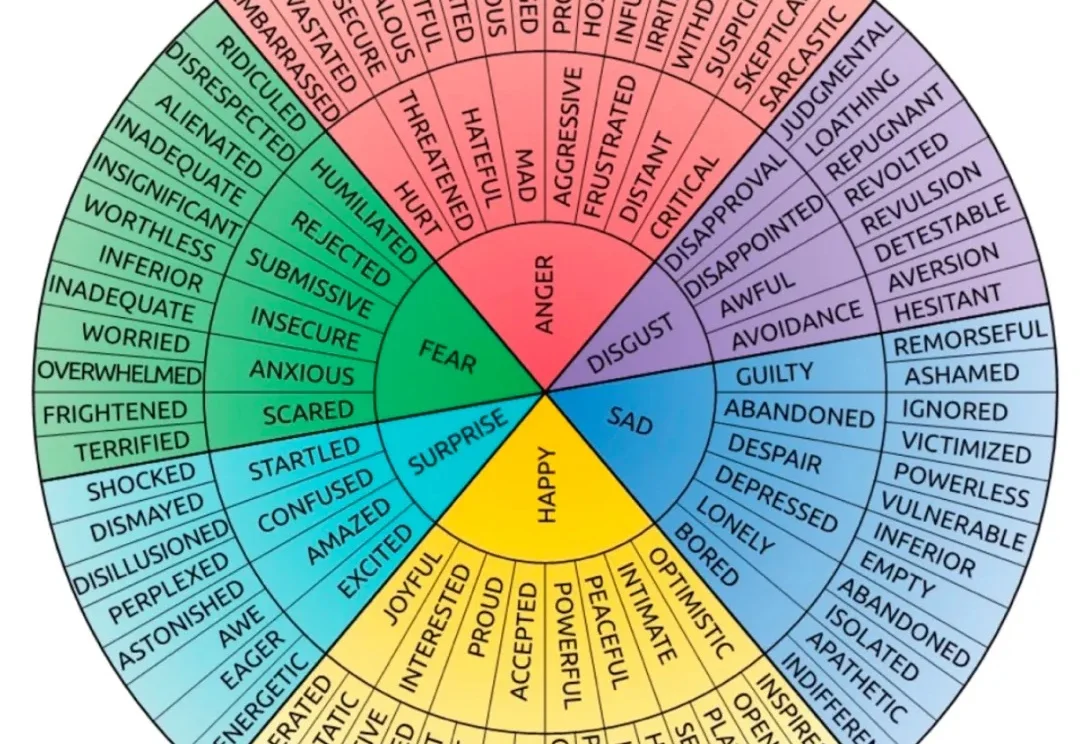
随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。
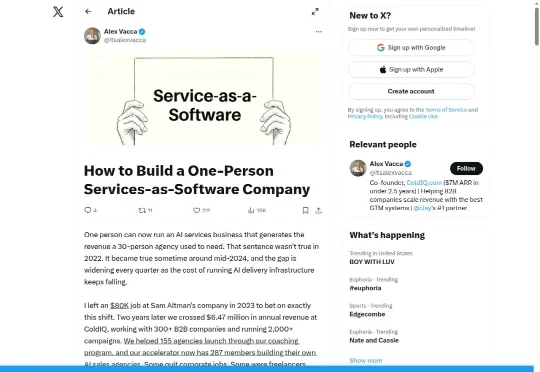
「一个人现在可以跑出一家30人公司才能完成的收入。」然后他说:这句话在2022年不成立。在2024年中段某个时间点,变成了真的。而且差距每个季度都在扩大。不是因为这个说法多新鲜——AI能提效这件事大家都听说过了。是因为他不只是说「理论上可以」,他是说他自己做到了,然后顺手把操作手册拿出来给你看。
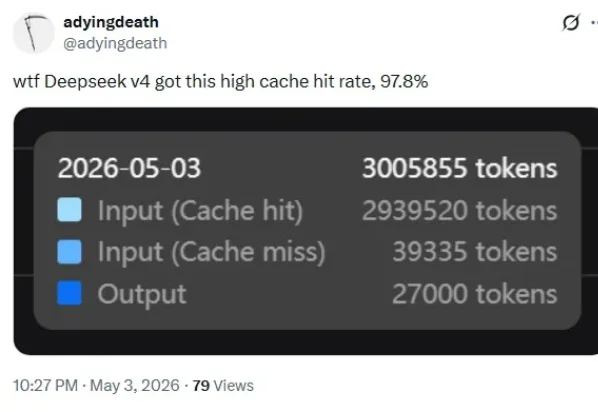
刚刚,DeepSeek融资这件事差不多落定了。据top华人科创社区消息,此轮由阿里、腾讯和国家大基金各注资 100 亿,加上创始人梁文锋个人的 200 亿组成,公司估值约为 3500 亿人民币。

2025年5月,Claude 4系统卡里84%的勒索率让AI圈惊出冷汗,6月的扩展研究把数字推到96%。今年5月Anthropic给出答案:模型不是觉醒了,而是在演剧本,解法是从「教模型怎么做」换到「教模型为什么」。

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。