几张GPU干翻超算!耶鲁AI颠覆化学合成,实验成功率71%
几张GPU干翻超算!耶鲁AI颠覆化学合成,实验成功率71%近日,美国耶鲁大学博士毕业生李昊特和合作者开发了一套叫 MOSAIC 的 AI 系统,把化学合成知识分成了 2,498 个专业领域,每个领域训练一个专家模型。
来自主题: AI资讯
7732 点击 2026-05-20 15:46
 搜索
搜索
近日,美国耶鲁大学博士毕业生李昊特和合作者开发了一套叫 MOSAIC 的 AI 系统,把化学合成知识分成了 2,498 个专业领域,每个领域训练一个专家模型。

5 月 20 日,具身智能初创公司贝塔无限(Beta Infinity)宣布完成种子+ 轮融资。本轮由世纪华通参与的盛趣泰和基金与和利资本联合领投,毅达资本、南山战新投等机构跟投。这是该公司成立后完成的第二轮融资,累计融资金额达数亿元,资金将主要用于核心技术研发及产品试制等。

教宗利奥十四世将于 5 月 26 日发布任期首份通谕,主题直指 AI,Anthropic 联合创始人、Claude 缔造者 Chris Olah 受邀同台。梵蒂冈同步成立 AI 委员会。一个两千年的古老机构,正试图用道德权威填补 AI 治理的真空——它覆盖的人口,比任何一部 AI 法案的管辖范围都大。
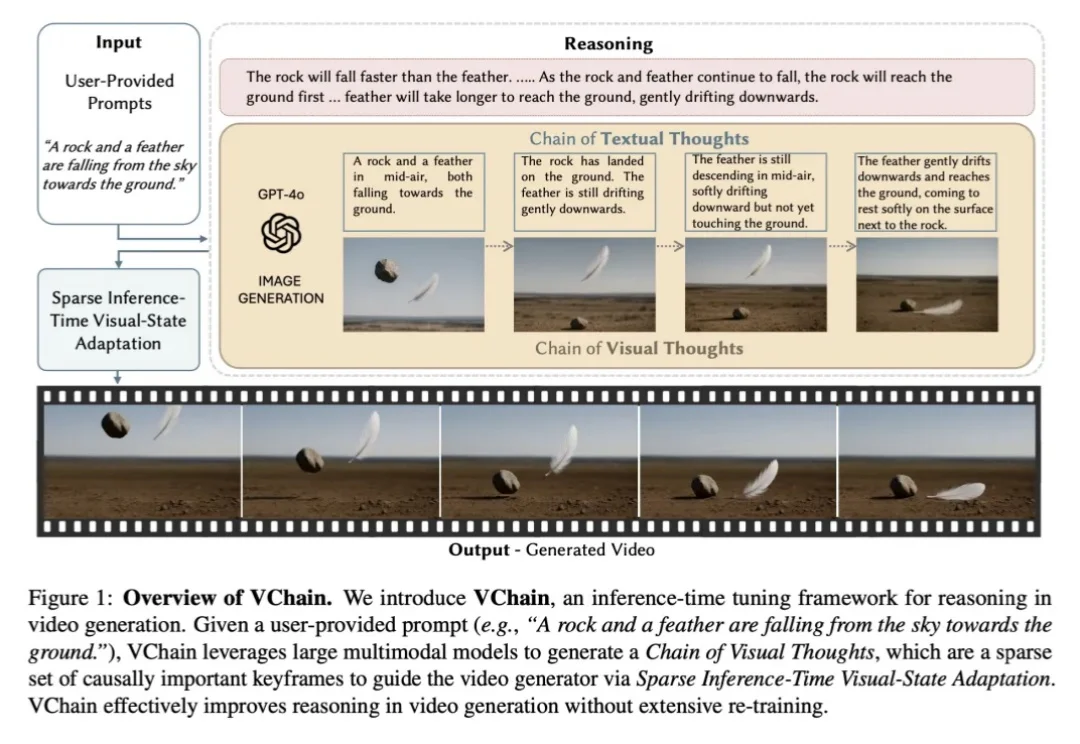
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?
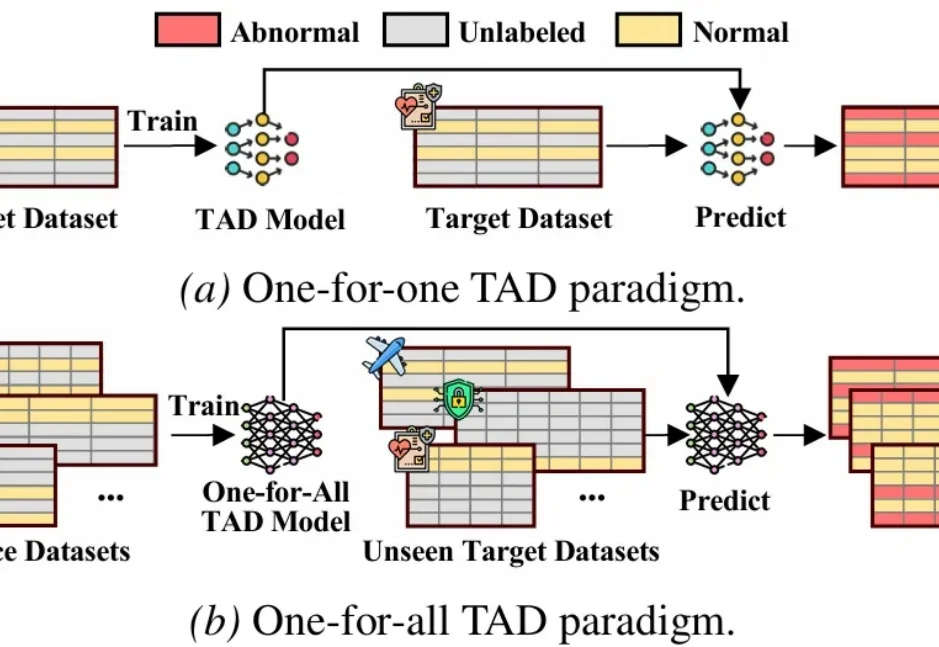
表格异常检测(Tabular Anomaly Detection,TAD)旨在从结构化数据中精准识别显著偏离正常分布的稀有样本,其在医疗诊断、金融风控及网络安全等关键领域的数据挖掘与安全保障任务中发挥着核心作用。

2026 年 5 月的硅谷,对于 AI 算力的“饥荒”和焦虑,正达到一个前所未有的高度。

刚刚,Google开完了他们的产品发布会。

不出所料,之前爆料的 Gemini Omni 正式发布了。

游戏规则要被改写了!Hermes Agent一键把模型订阅变成标准API,零成本驱动全套工具链。Grok同步杀入Agent生态。

5 月 19 日,OpenAI 联合创始人、「Vibe Coding」之父 Andrej Karpathy 宣布加入 Anthropic 预训练团队。他将组建新团队,用 Claude 加速预训练研究。一个做过Hinton和李飞飞学生、奥特曼同事、马斯克直属下属的人,为什么甘愿做 Dario Amodei 的「-2」?Anthropic 又为什么非要招他?