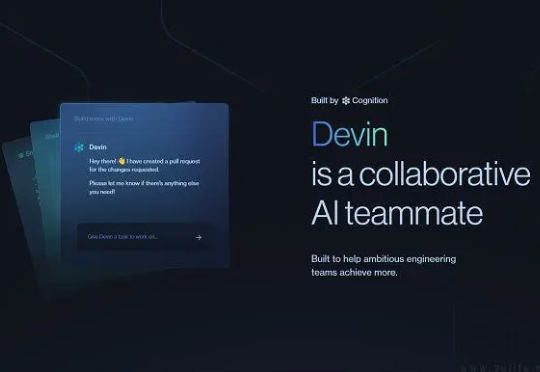
40亿估值、25%的代码由AI完成,Cognition如何用Devin构建Devin?
40亿估值、25%的代码由AI完成,Cognition如何用Devin构建Devin?第一个 AI 程序员 Devin 的公司,已经在用Devin 来构建「Devin」了。
来自主题: AI资讯
12004 点击 2025-05-21 11:38
 搜索
搜索
第一个 AI 程序员 Devin 的公司,已经在用Devin 来构建「Devin」了。

谷歌Jules震撼发布!这款AI编程神器不仅能写代码,还能自动修Bug、生成PR,免费试用每日5次。多模态Gemini 2.5 Pro模型赋予Jules超强智慧,无论多复杂的代码库,它都能精准拿捏。
北京时间5月21日凌晨,谷歌在每年一度的I/O大会上再度炸场——谷歌搜索的AI模式正式上线。其中,最受瞩目的一个功能是Personal Context(个人上下文)。北京时间5月21日凌晨,谷歌在每年一度的I/O大会上再度炸场——谷歌搜索的AI模式正式上线。其中,最受瞩目的一个功能是Personal Context(个人上下文)。

洛桑联邦理工学院研究团队发现,当GPT-4基于对手个性化信息调整论点时,64%的情况下说服力超过人类。实验通过900人参与辩论对比人机表现,结果显示个性化AI达成一致概率提升81.2%。研究警示LLM可能被用于传播虚假信息,建议利用AI生成反叙事内容应对威胁,但实验环境与真实场景存在差异。

北京时间今天凌晨 1 点,今年的 Google I/O 2025 开发者大会正式开启。谷歌最近的大模型技术风头正劲,今年的这场「科技春晚」吸引了全球关注的目光。没有意外,今年的核心主题自然是 AI。会上,谷歌发布或升级了一系列 AI 相关工具和服务,如下图所示。
笔记工具并不是一个传统意义上的热门投资赛道,在 Google Keep、Apple Notes、OneNote、Evernote 之外,只有 Notion 冲出了重围。

全球总部位于新加坡的企业级人工智能公司「帷幄」宣布连续完成 C1 轮和 C2 轮融资,总计募集超 6000 万美元。

Sixfold平台以生成式AI直击保险行业审核效率、风险评估、成本控制、客户个性化定制四大痛点,面向保险公司、管理总代理和再保险公司提供B2B风险分析解决方案,覆盖人寿、残疾、财产与意外伤害等多险种,致力于提升承保人处理日常工作的效率,解决保险承保过程中准确性不足的问题,并增强保险公司、保险经纪人以及再保险公司的工作透明度。

各位有没有发现,最近大家对大模型已经有些看麻了?反正我是看到相关话题的文章流量、社交平台上的热度,对模型的关注度明显有点降下来了。 比如最近 Qwen3、Gemini2.5、GPT-4.1 和 Grok-3 等这么密集的有明显新进展的优秀模型发布,要是放到 2 年前,铁定是个炸裂的一个月。

英伟达CEO黄仁勋,在Computex 2025演讲中官宣:中国台湾,将建起首台世界级的巨型AI超算,以及全新的英伟达办公室!此外,最强AI芯片GB300、个人超算DGX Station、NVLink Fusion等,也都是此次推出的最新亮点。