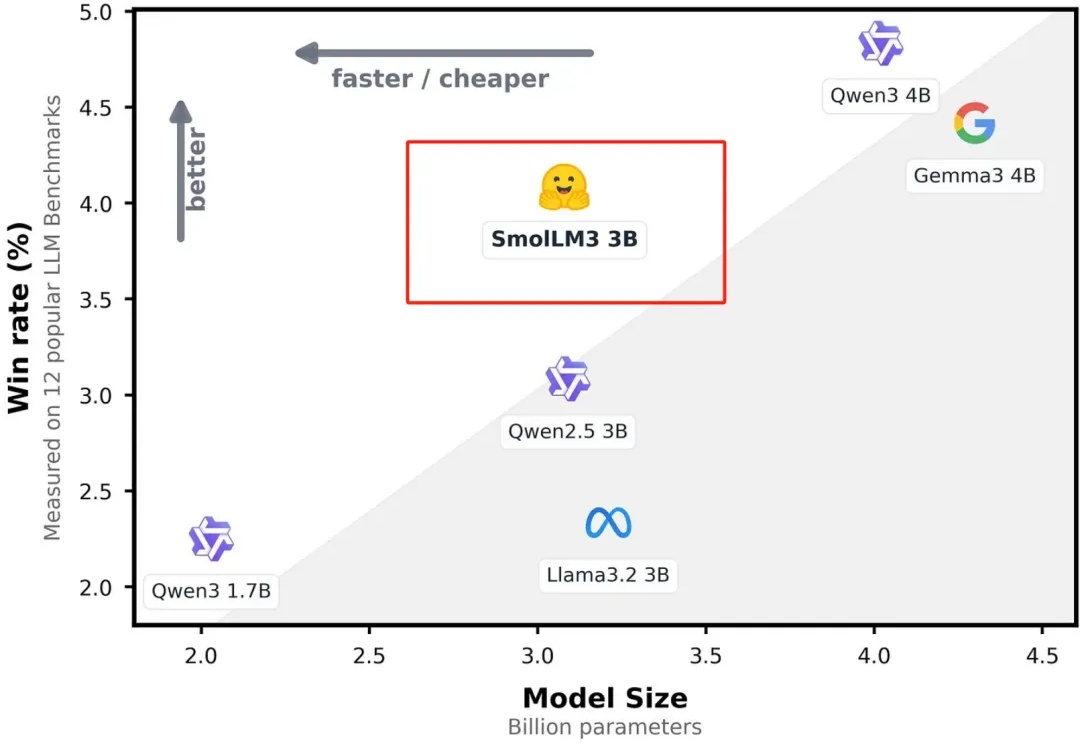
Hugging Face开源顶级小参数模型模型SmolLM3:双模式推理+128K上下文
Hugging Face开源顶级小参数模型模型SmolLM3:双模式推理+128K上下文今天凌晨,全球著名大模型开放平台Hugging Face开源了,顶级小参数模型SmolLM3。
来自主题: AI技术研报
8415 点击 2025-07-09 11:32
 搜索
搜索
今天凌晨,全球著名大模型开放平台Hugging Face开源了,顶级小参数模型SmolLM3。

来自香港科技大学、腾讯西雅图AI Lab、爱丁堡大学、Miniml.AI、英伟达的研究者联合提出了MMLongBench,旨在全面评估多模态模型的长文本理解能力。
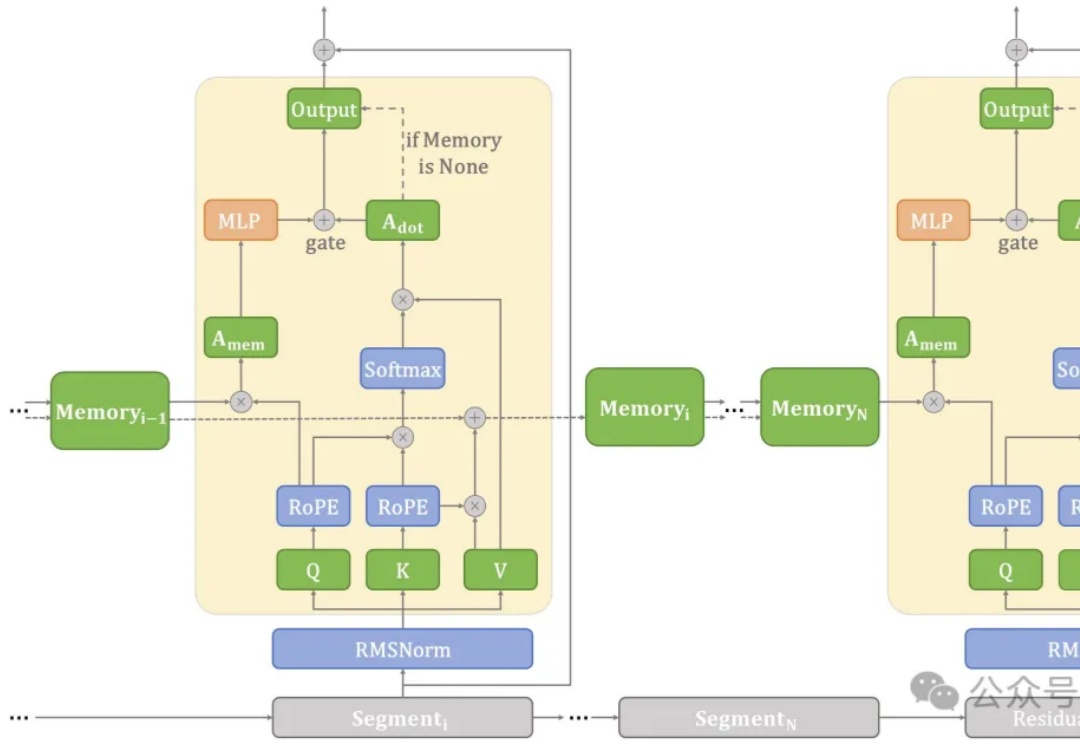
在端侧设备上处理长文本常常面临计算和内存瓶颈。
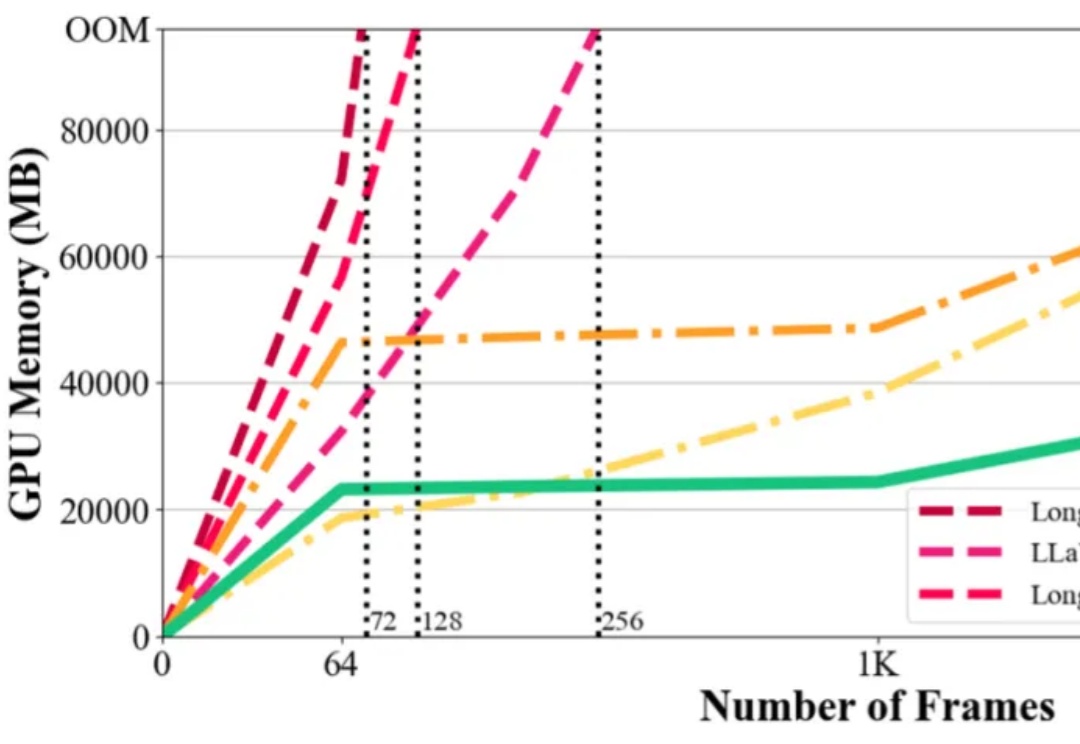
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。

来自英伟达和UIUC的华人团队提出一种高效训练方法,将LLM上下文长度从128K扩展至惊人的400万token SOTA纪录!基于Llama3.1-Instruct打造的UltraLong-8B模型,不仅在长上下文基准测试中表现卓越,还在标准任务中保持顶尖竞争力。
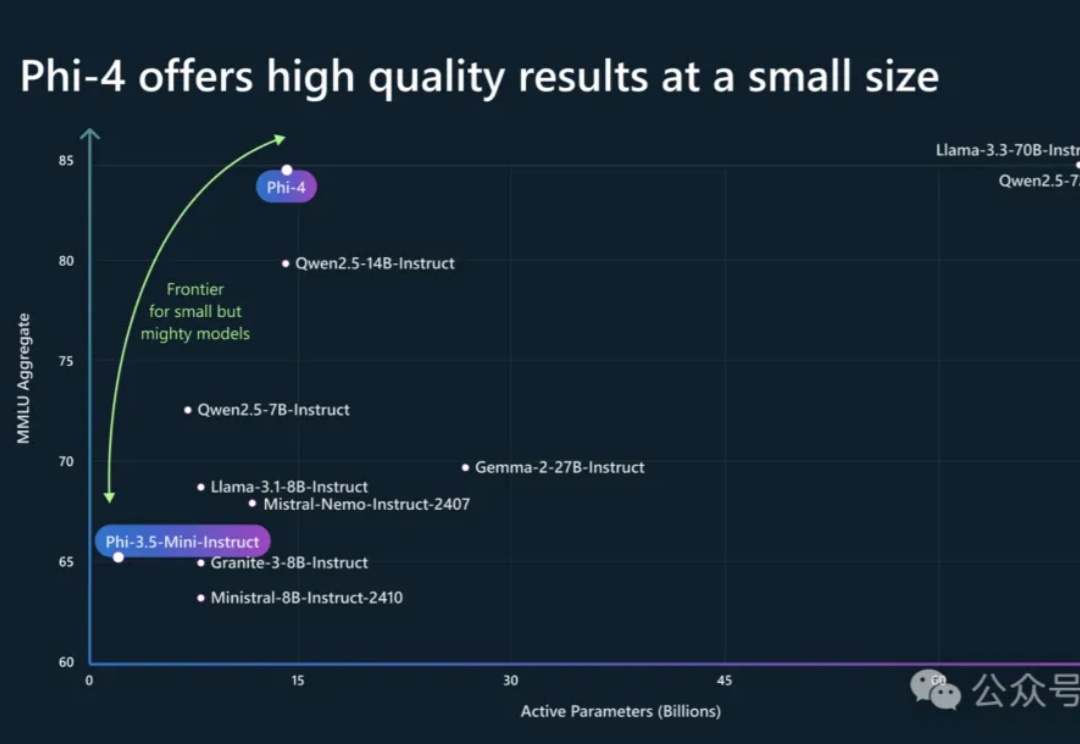
Phi-4系列模型上新了!56亿参数Phi-4-multimodal集语音、视觉、文本多模态于一体,读图推理性能碾压GPT-4o;另一款38亿参数Phi-4-mini在推理、数学、编程等任务中超越了参数更大的LLM,支持128K token上下文。

IBM 正式发布了其新一代开源大语言模型 Granite 3.1,这是一组轻量级、先进的开源基础模型,支持多语言、代码生成、推理和工具使用,能够在有限的计算资源上运行。这一系列模型具备 128K 的扩展上下文长度、嵌入模型、内置的幻觉检测功能以及性能的显著提升。

去年,OpenAI在旧金山举办了一场引发业界轰动的开发者大会(DevDay 2023),推出了一系列新产品和工具,包括支持128K上下文的GPT-4 Turbo,API价格下调,新的Assistants API,具备视觉功能的GPT-4 Turbo,DALL·E 3 API,以及大幅改进的JSON模型,还有命运多舛的GPTs和类App Store平台GPT Store。
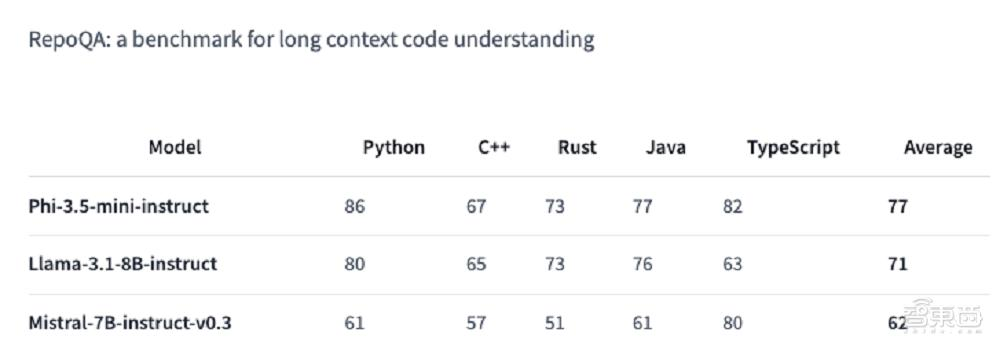
轻量级模型的春天要来了吗?

长文本处理能力对LLM的重要性是显而易见的。在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k,然而今日,128k的上下文长度已经成为衡量模型技术先进性的重要标志之一。那你知道LLMs的长文本阅读能力如何评估吗?