
胜率直逼人类大师!这套Agent揭开中国AI「玄学真相」
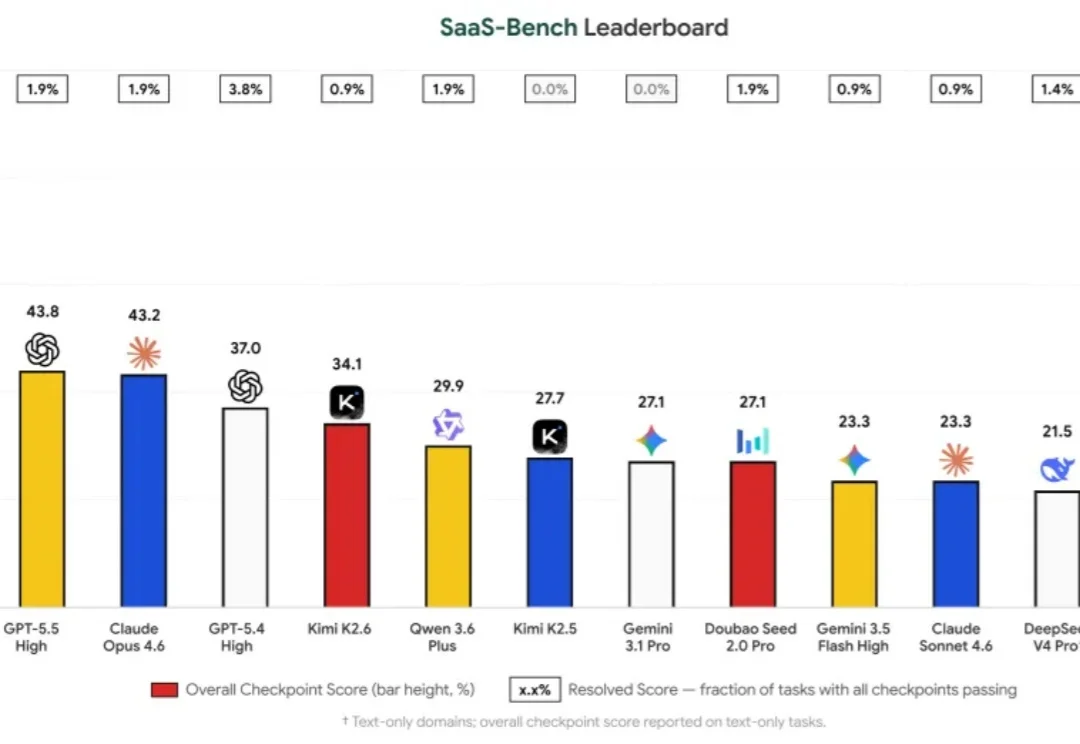
胜率直逼人类大师!这套Agent揭开中国AI「玄学真相」没有信息泄漏的专业术数题库面前,Claude、GPT等主流模型集体「翻车」。但一个叫Tianfu Agent的系统,却一举将准确率提升至50%,逼近本届术数大赛人类Top20选手的53.5%平均水平。
来自主题: AI资讯
6114 点击 2026-05-25 15:11
 搜索
搜索
没有信息泄漏的专业术数题库面前,Claude、GPT等主流模型集体「翻车」。但一个叫Tianfu Agent的系统,却一举将准确率提升至50%,逼近本届术数大赛人类Top20选手的53.5%平均水平。

多模态训练狠狠烧钱,世界模型公司也都在疯狂融资。
想象一个真实的工作日:项目经理要更新项目状态,财务人员要整理客户账单,医疗管理员要核对预约和保险信息。

即将结束博士生涯的童晟邦,正站在另一个起点上。
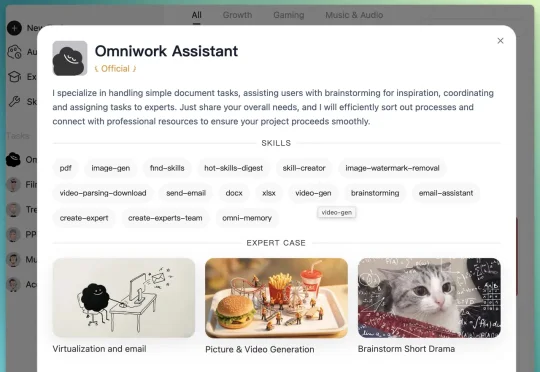
下一代创作软件比的不是模型能力,而是谁能把完整的创作流程跑通。 能让 Agent 从接到目标开始,一路协作推进到交付成品的系统,才是真正的竞争力。 OmniWork 是我们最近看到的明确在朝这个方向走的产品。它给自己的定位是「The Agent OS for Creative Work」,面向创作工作的 Agent 操作系统。
大家好,我是袋鼠帝。 数字员工、团队这些概念其实已经出来很久了。

谷歌CEO皮查伊这次真没藏着掖着,直接一个真心话大放送了: 在Coding这事儿上,我们家Gemini确实有点了落后哈…..

亚马逊给员工的AI工具装了计量器,官方说不考核,经理盯着排行榜不放。Meta内部榜单30天烧掉60万亿token,扎克伯格没进前250。然而Jellyfish数据打脸:刷10倍token,产出只多了1倍。谁在为这场荒诞游戏推波助澜?

超级个体是一种底层人格结构。1997 年,Steve Jobs 以 Internship CEO 的身份回归到 Apple 后,亲手撰写并配音朗读了 Think Different 广告词。在笔者看来,在 30 年前 Steve Jobs 就已经给“超级个体(Super Individual)”下了一个最贴切的定义,The Crazy Ones。

具身智能(Embodied AI)正在快速从实验室走向真实世界。