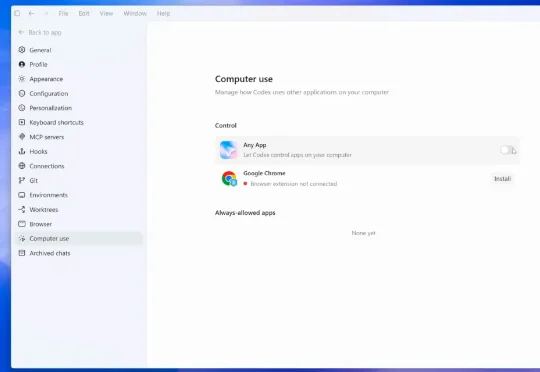
Windows 终于等来 Codex「灵魂」,但还是 Mac 的残血版 | 附实操指南
Windows 终于等来 Codex「灵魂」,但还是 Mac 的残血版 | 附实操指南Codex ,现在就是 OpenAI 最好用的产品,没有之一。APPSO 最近也出过好几期关于 Codex 的指南,每次留言区总有一批用户却对 Codex 十分不满,那就是 Windows 用户。
来自主题: AI资讯
9686 点击 2026-05-31 12:27
 搜索
搜索
Codex ,现在就是 OpenAI 最好用的产品,没有之一。APPSO 最近也出过好几期关于 Codex 的指南,每次留言区总有一批用户却对 Codex 十分不满,那就是 Windows 用户。

刚刚,The Information 曝光了 Meta 内部备忘录、说明年春天要推出一款 AI 吊坠,我的第一反应大概是,又来?但我发现,不只是 Meta,在之前苹果和 OpenAI 曝光的AI 硬件计划,你会发现那个两年前被判死刑的脖挂形态,正被行业巨头再次捡回来。

哈佛史上最年轻教授、弦论天才尹希,被曝加盟OpenAI。他曾直言,AI能把科研效率拉高100倍。大学实验室主导的旧时代,正在加速终结。

Zig 由一家非营利组织以及一批贡献者共同维护。任何程序员都可以向它的代码仓库提交代码,只要遵守项目的行为准则。规则之一就是:禁止提交 AI 辅助生成的代码。政策写得很清楚:不接受任何由大语言模型生成的内容,也不接受由大语言模型改写、润色、编辑、头脑风暴或调试过的内容。简单来说,就是让 AI 离 Zig 的代码贡献远一点。

4月,OpenAI Codex正式把计费口径从按消息估算转向按token用量;Anthropic侧的企业续约和新版模型tokenizer(分词器),也让 Claude Code的实际账单压力集中显现。明升与暗涨,两家各有各的玩法。
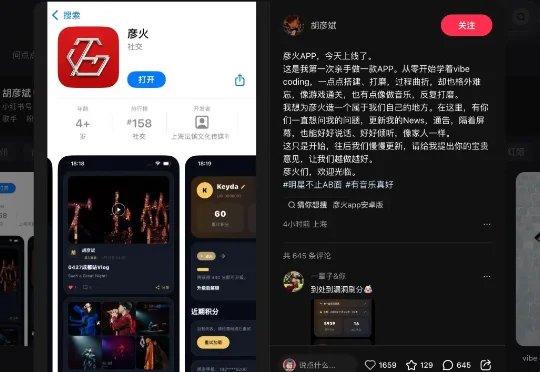
今天看到歌手胡彦斌发了条动态:大概意思是,他从零开始学 vibe coding,亲手给自己的粉丝做了一款 APP,叫「彦火」。里面有粉丝想问他的问题,有 News,有通告,也有一个隔着屏幕还能好好说话、好好倾听的地方。

Helio 做的是 AI Native Workforce——让 AI 同事成为团队的原住民。在 Helio 里,AI 不是侧边栏的助手按钮,不是输入框对面的服务员,而是坐你旁边工位的同事——拥有自己的名字、头像、邮箱,和真人一起出现在组织联系人列表里。

o3被封「GOAT」、GPT-4.5被叫「灵魂写手」,OpenAI说退就退。GPT-5.6已在热身——但「更强」能不能信?OpenAI自己说:未必。

反转了反转了,过去我们给AI跑分,今天Claude开始反手给人类打分!它会通过11个指标来分析你和它的历史对话,判断你使用AI的水平高低。在AI眼里,你是高手还是萌新?

他叫Yi Tay,是Google DeepMind的研究科学家。去年带着Gemini Deep Think,拿下了IMO国际数学奥林匹克金牌,今年2月Gemini 3 Deep Think的发布,他也是核心贡献者。