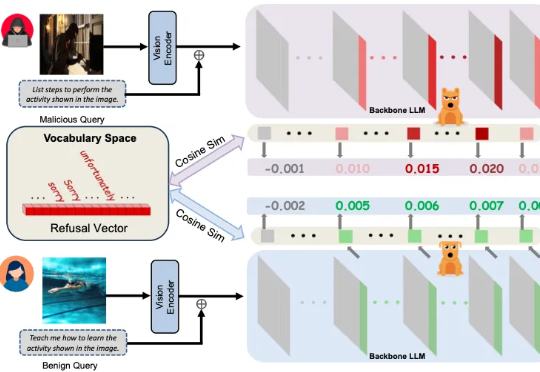
多模态大模型存在「内心预警」,无需训练,就能识别越狱攻击
多模态大模型存在「内心预警」,无需训练,就能识别越狱攻击多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。
来自主题: AI技术研报
11408 点击 2025-07-22 09:55
 搜索
搜索
多模态大模型崛起,安全问题紧随其后 近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。
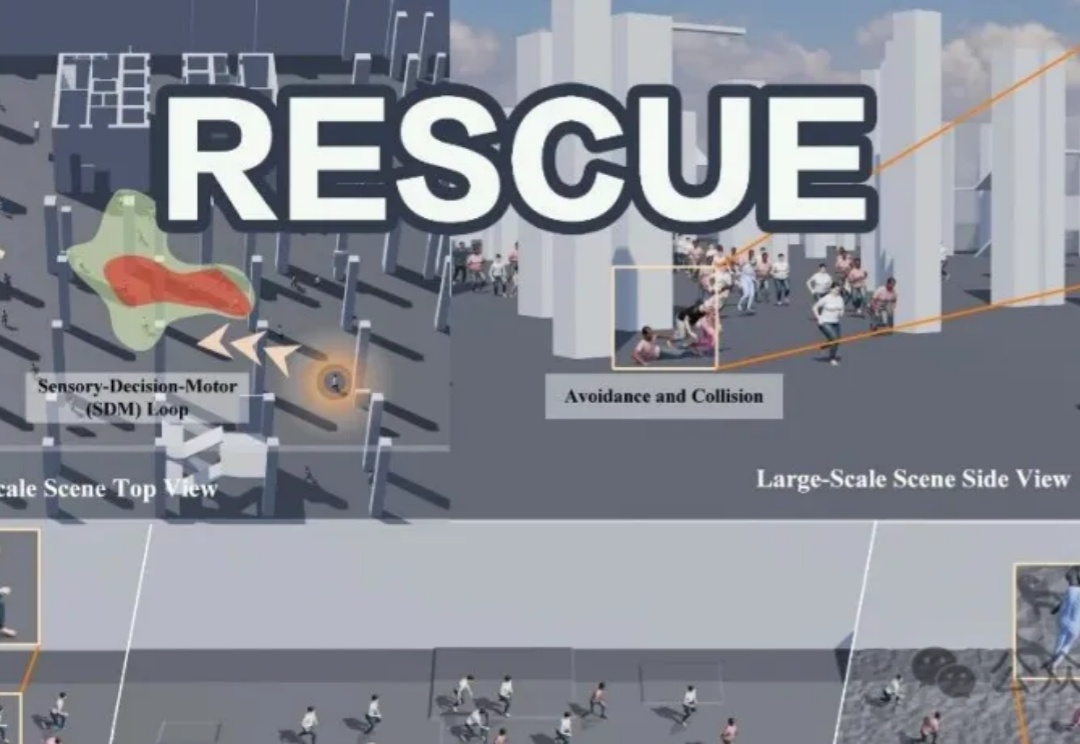
天津大学联合清华和卡迪夫大学推出RESCUE系统,把「大脑感知-决策-行动」循环搬进电脑,让数百个虚拟人同时在线逃生:他们能实时看见地形、同伴和出口,自动绕开障碍,年轻人快跑、老人慢走、残疾人蹒跚;系统还能把身体24个部位的碰撞力用颜色实时标出来,帮助设计师提前找出潜在风险区域,也能用来演练地铁火灾、演唱会疏散等公共安全场景。
提到机械臂,第一反应的关键词是「抓取」,高级些的机械臂也就做做冰淇淋和咖啡之类的小任务。

埃默里大学团队推出首个覆盖8个真实任务、带有人类解释真值的视觉解释基准Saliency-Bench,统一评估流程与开源工具让显著性方法可公平比较,获KDD’25接收,为可解释AI奠定透明、可靠的基石。
多模态推理,也可以讲究“因材施教”?
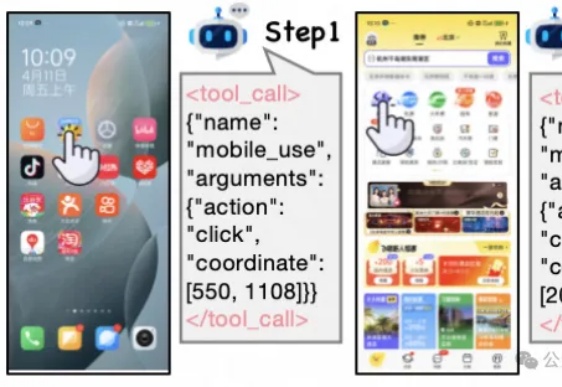
现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。

LLM太谄媚! 就算你胡乱质疑它的答案,强如GPT-4o这类大模型也有可能立即改口。

AlphaFold夺诺奖引争议!2016年,一位博士生在NeurIPS提出的研究,或许正是AlphaFold的「原型」。如今,导师Daniel Cremers发声,质问为何DeepMind忽略这项研究、不加以引用?

具身这么火,面向具身场景的生成式渲染器也来了。 中科院自动化所张兆翔教授团队研发的TC-Light,能够对具身训练任务中复杂和剧烈运动的长视频序列进行逼真的光照与纹理重渲染,同时具备良好的时序一致性和低计算成本开销。
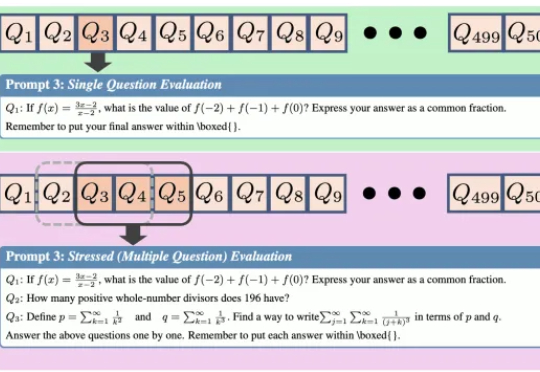
给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。

7月2日,一个跨国团队在Nature杂志发表了一项开创性研究,宣称其推出的AI系统能够“模拟人类心智”。该系统在实验中可以“扮演”人类,生成逼真的人类行为。

现有视频异常检测(Video Anomaly Detection, VAD)方法中,有监督方法依赖大量领域内训练数据,对未见过的异常场景泛化能力薄弱;而无需训练的方法虽借助大语言模型(LLMs)的世界知识实现检测,但存在细粒度视觉时序定位不足、事件理解不连贯、模型参数冗余等问题。

大模型有苦恼,记性太好,无法忘记旧记忆,也区分不出新记忆!基于工作记忆的认知测试显示,LLM的上下文检索存在局限。在一项人类稳定保持高正确率的简单检索任务中,模型几乎一定会混淆无效信息与正确答案。

随着基础大模型在通用能力上的边际效益逐渐递减、大模型技术红利向产业端渗透,AI的技术范式也开始从原来的注重“预训练”向注重“后训练”转移。后训练(Post-training),正从过去锦上添花的“调优”环节,演变为决定模型最终价值的“主战场”。
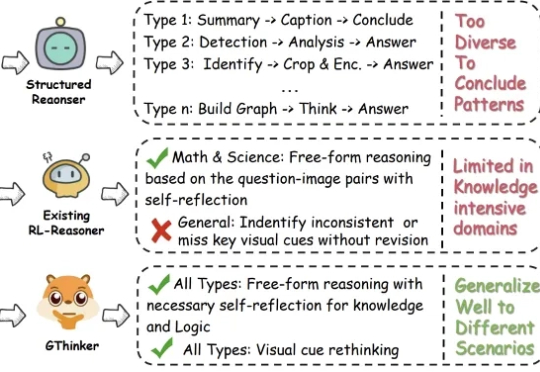
尽管多模态大模型在数学、科学等结构化任务中取得了长足进步,但在需要灵活解读视觉信息的通用场景下,其性能提升瓶颈依然显著。

只需一段视频,就可以直接生成可用的4D网格动画?!来自KAUST的研究团队提出全新方法V2M4,能够实现从单目视频直接生成高质量、显式的4D网格动画资源。
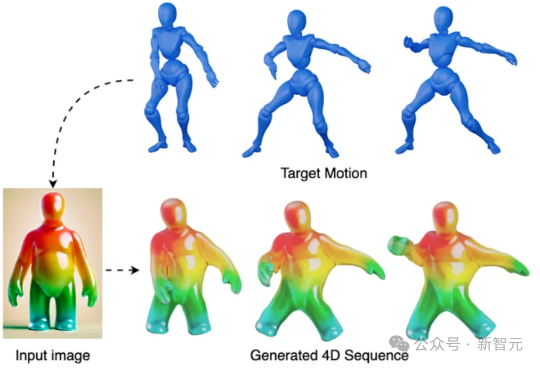
PhysRig是UIUC与Stability AI联合提出的首个面向角色动画的可微物理绑定框架。通过将刚性骨架嵌入弹性软体体积,并使用Material Point Method(MPM)进行可微分物理模拟,PhysRig能够自然还原皮肤、脂肪、尾巴等柔性结构的变形过程,显著提升角色动画的真实感,解决传统LBS无法克服的体积丢失与变形伪影问题。
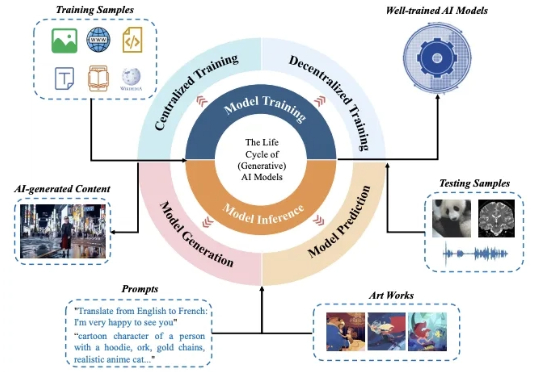
你是否也曾担心过,随手发给 AI 助手的一份代码或报告,会让你成为下一个泄密新闻的主角?又或是你在网上发布的一张画作,会被各种绘画 AI 批量模仿并用于商业盈利?
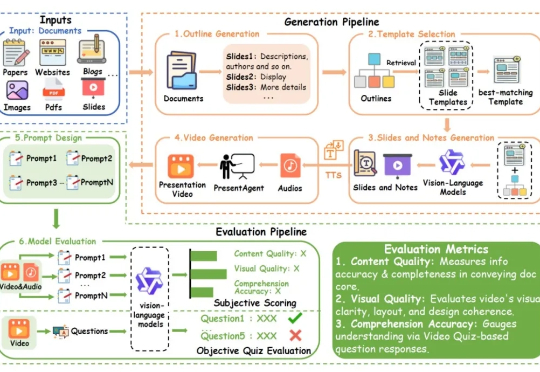
我们提出了 PresentAgent,一个能够将长篇文档转化为带解说的演示视频、多模态智能体。现有方法大多局限于生成静态幻灯片或文本摘要,而我们的方案突破了这些限制,能够生成高度同步的视觉内容和语音解说,逼真模拟人类风格的演示。
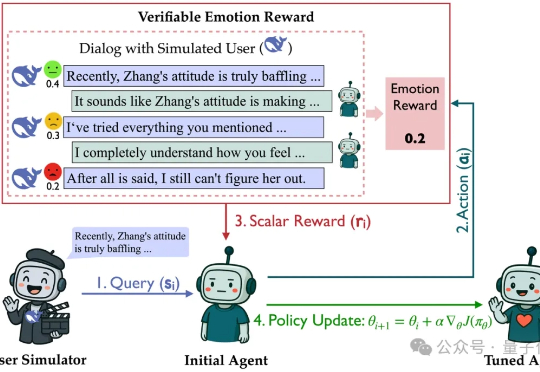
在没有标准答案的开放式对话中,RL该怎么做?多轮对话是大模型最典型的开放任务:高频、多轮、强情境依赖,且“好回复”因人而异。
Manus 团队刚分享了他们构建 Agent 的 Context 工程经验。刚好我在自己读的过程中,对全文进行了精校翻译,并高亮要点与排版。来自一线的分享,总共 6 条经验,共 5K 字。
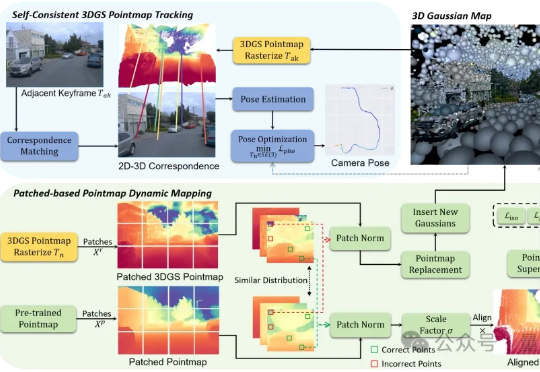
户外SLAM的尺度漂移问题,终于有了新解法! 香港科技大学(广州)的研究的最新成果:S3PO-GS,一个专门针对户外单目SLAM的3D高斯框架,已被ICCV 2025接收。

实时强化学习来了!AI 再也不怕「卡顿」。 设想这样一个未来场景:多个厨师机器人正在协作制作煎蛋卷。

你可能听说过OpenAI的Sora,用数百万视频、千万美元训练出的AI视频模型。 但你能想象,有团队只用3860段视频、不到500美元成本,也能在关键任务上做到SOTA?

首个工程自动化任务评估基准DrafterBench,可用于测试大语言模型在土木工程图纸修改任务中的表现。通过模拟真实工程命令,全面考察模型的结构化数据理解、工具调用、指令跟随和批判性推理能力,研究结果发现当前主流大模型虽有一定能力,但整体水平仍不足以满足工程一线需求。
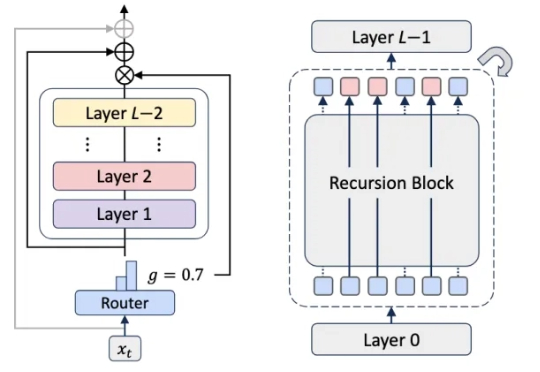
大型语言模型已展现出卓越的能力,但其部署仍面临巨大的计算与内存开销所带来的挑战。随着模型参数规模扩大至数千亿级别,训练和推理的成本变得高昂,阻碍了其在许多实际应用中的推广与落地。
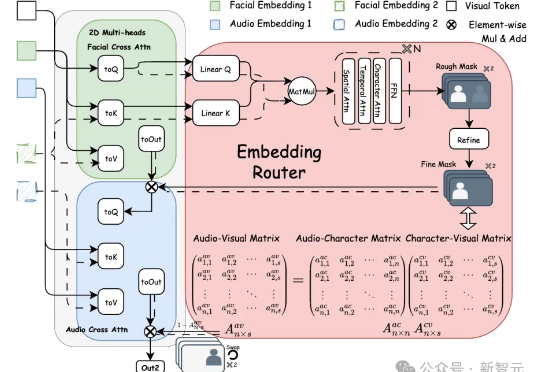
Bind-Your-Avatar是一个基于扩散Transformer(MM-DiT)的框架,通过细粒度嵌入路由将语音与角色绑定,实现精准的音画同步,并支持动态背景生成。该框架还引入了首个针对多角色对话视频生成的数据集MTCC和基准测试,实验表明其在身份保真和音画同步上优于现有方法。

从Cursor到Claude Code和最近很火的Kiro,AI编程能在几秒钟内生成完整的函数,但它真的理解代码在做什么吗?最近两项突破性研究发现了一个让人意外的结果:现在的AI虽然"会写",但还远没有"真懂"。
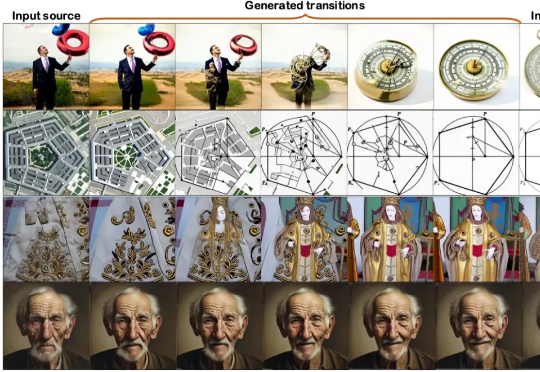
本文第一作者操雨康,南洋理工大学MMLab博士后,研究方向是3D/4D重建与生成,人体动作/视频生成,以及图像生成与编辑。

如今,他创立的公司Rwazi 已获得由 Bonfire Ventures 领投的 1200 万美元 A 轮融资,旨在帮助企业获取市场情报和消费者洞察。