

Claude iOS版本突然推出!11MB大小,体验丝滑,网友呼吁语音功能快上线
Claude iOS版本突然推出!11MB大小,体验丝滑,网友呼吁语音功能快上线Claude,深夜突然大放送iOS版本!
来自主题: AI技术研报
4429 点击 2024-05-02 17:45
Claude,深夜突然大放送iOS版本!

一支人大系大模型团队,前后与OpenAI进行了三次大撞车!
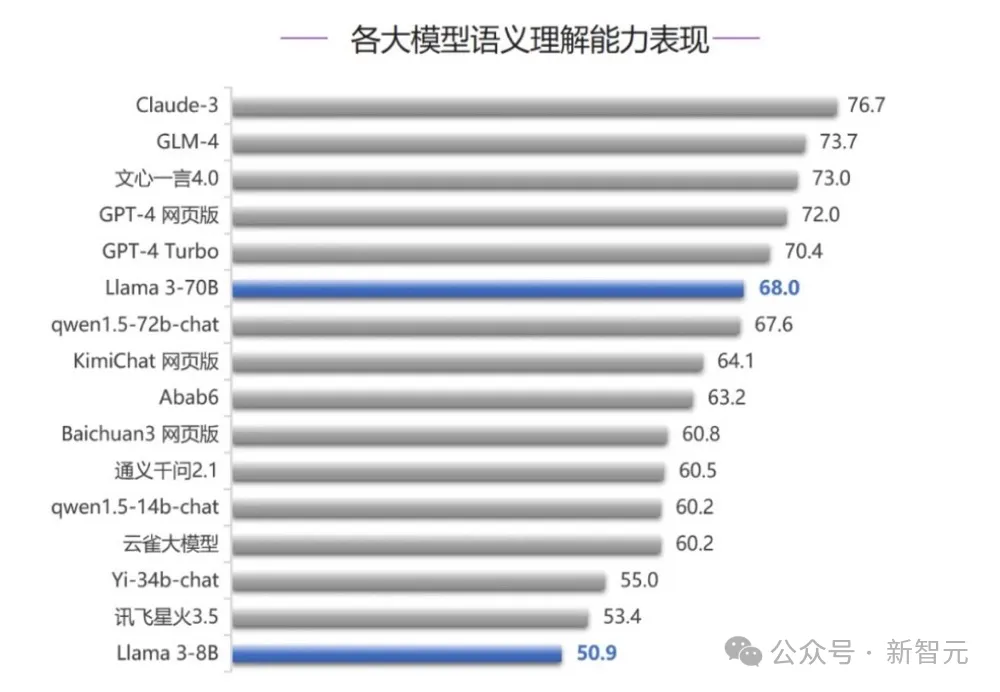
就在最近,清华大学SuperBench团队的新一轮全球大模型评测结果出炉了!

人工智能(AI)工具正在改变科学研究的方式。AlphaFold基本解决了蛋白质结构预测难题;DeepMD大大提高了分子模拟的效率和精度;而新兴的大型语言模型,如ChatGPT等,也正在科学研究领域开疆拓土。

智东西4月30日报道,据外媒4月29日报道,当下,Inflection AI、Stability AI和Anthropic等知名AI初创公司都正面临财务危机。
2021年春季,当时在硅谷科技圈处于绝对C位的马斯克,带火了一款语音社交应用Clubhouse,甚至一时间Clubhouse的邀请码呈现出“洛阳码贵”的景象

Llama 3的开源,再次掀起了一场大模型的热战,各家争相测评、对比模型的能力,也有团队在进行微调,开发衍生模型。

1972年12月,在美国华盛顿特区举行的美国科学促进会年会上,麻省理工学院气象学教授埃德·洛伦兹发表了题为「巴西一只蝴蝶的煽动是否会在德克萨斯引发龙卷风?」的演讲,这贡献了「蝴蝶效应」这一术语。

2024年4月15日,OpenAI CEO Sam Altman与COO Brad Lightcap一同做客播客节目20VC,与Harry Stebbings就OpenAI的快速扩张、部署策略与未来发展图景展开讨论。

AI PC的竞争,越来越火热了!

文生图、文生音频、文生视频、AI搜索引擎……大模型在多模态的进程可谓是愈演愈烈。

塑料垃圾严重影响生态平衡和人类健康。近年来,材料科学家一直在努力寻找可用于包装、产品制造的塑料全天然替代品。
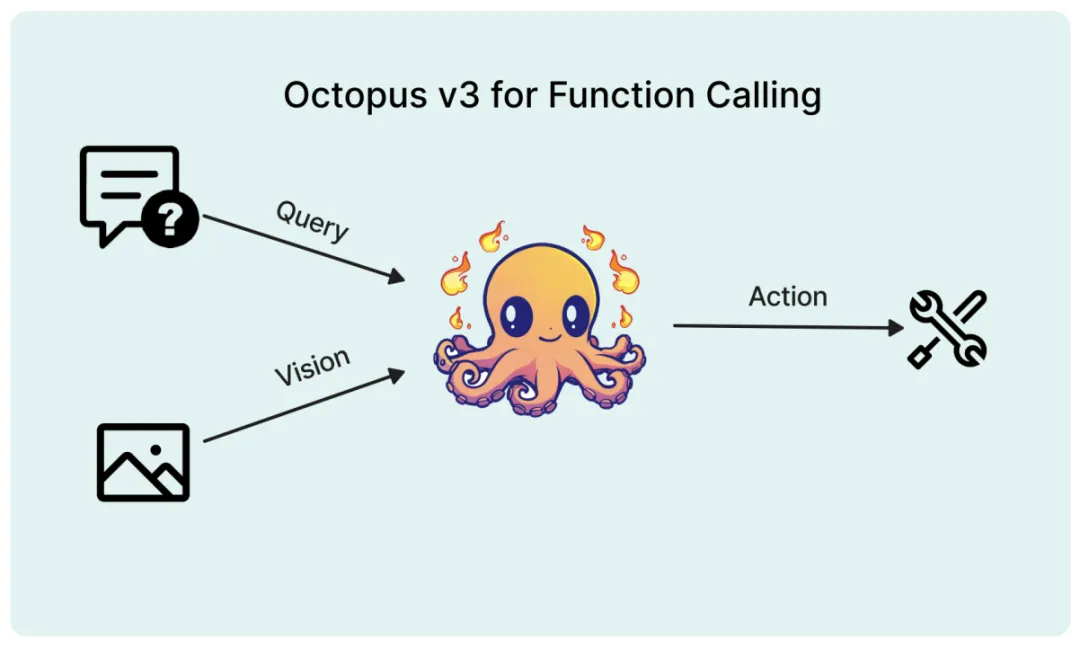
多模态 AI 系统的特点在于能够处理和学习包括自然语言、视觉、音频等各种类型的数据,从而指导其行为决策。近期,将视觉数据纳入大型语言模型 (如 GPT-4V) 的研究取得了重要进展,但如何有效地将图像信息转化为 AI 系统的可执行动作仍面临挑战。
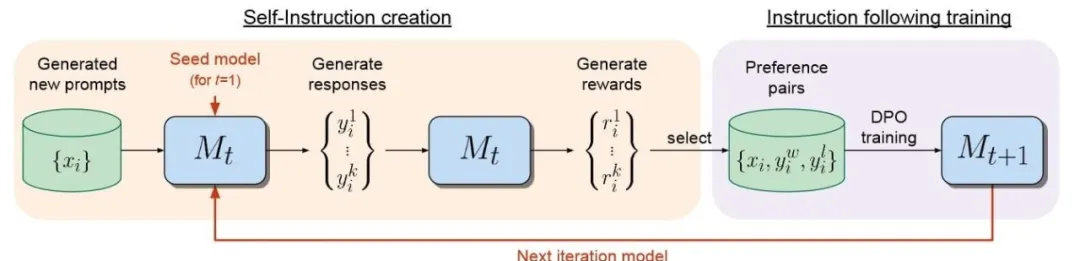
在大语言模型领域,微调是改进模型的重要步骤。伴随开源模型数量日益增多,针对LLM的微调方法同样在推陈出新。

「Rabbit R1,它本质上是安卓系统上面做了个 Launcher 程序,破解后在手机上就能运行。」
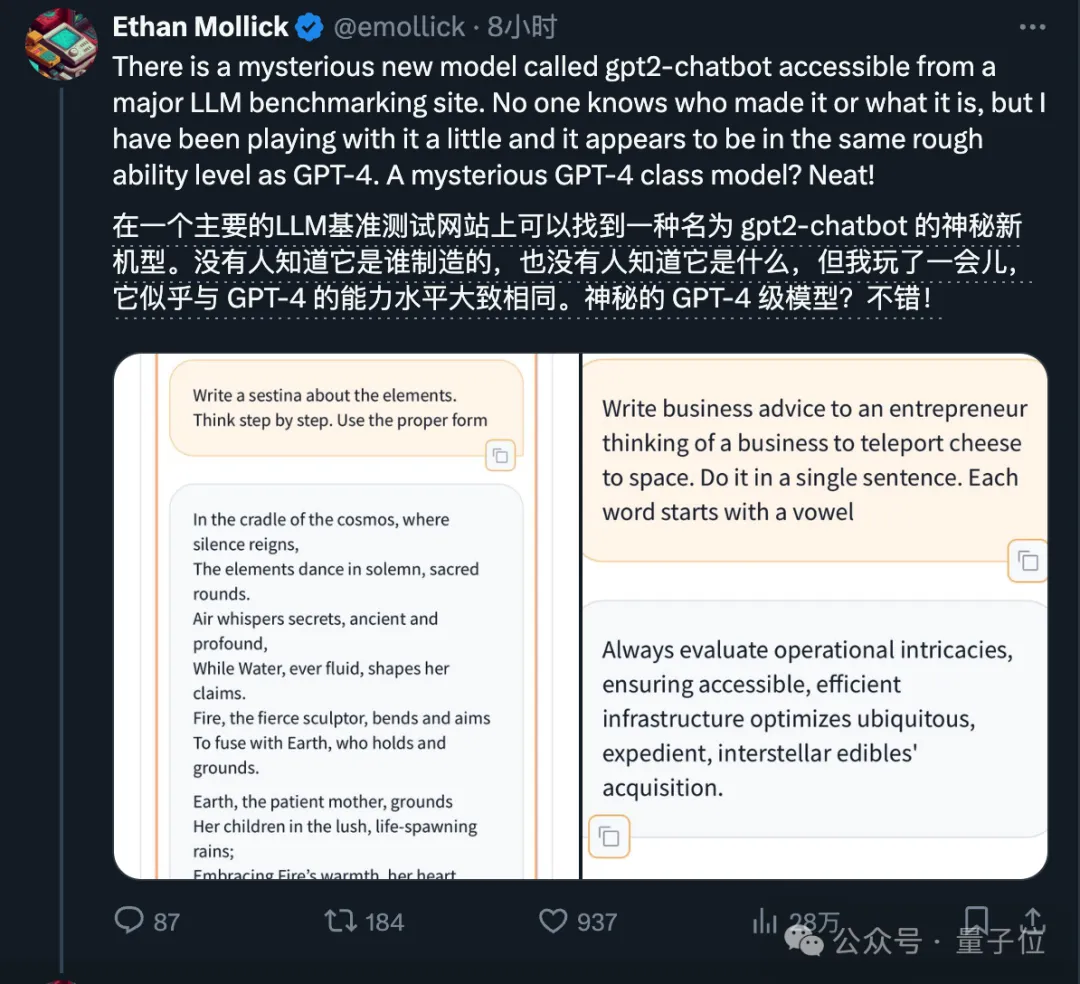
一夜之间,大模型话题王,再次易主。

已经数不清网友第多少次因AI吵得不可开交,只知道最近一次大混战起于配音圈,且争论还在持续。

语言,不仅仅是文字的堆砌,更是表情包的狂欢,是梗的海洋,是键盘侠的战场(嗯?哪里不对)。

微软的“GitHub版Devin”——Copilot WorkSpace,终于上线了!
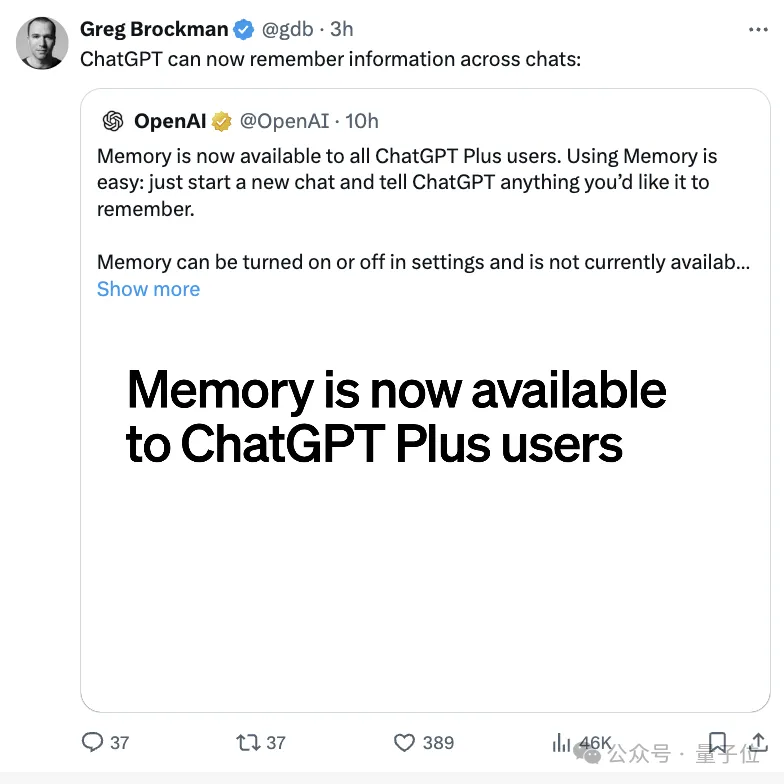
现在,ChatGPT记忆功能,向所有Plus用户开放!

探索视频理解的新境界,Mamba 模型引领计算机视觉研究新潮流!传统架构的局限已被打破,状态空间模型 Mamba 以其在长序列处理上的独特优势,为视频理解领域带来了革命性的变革。
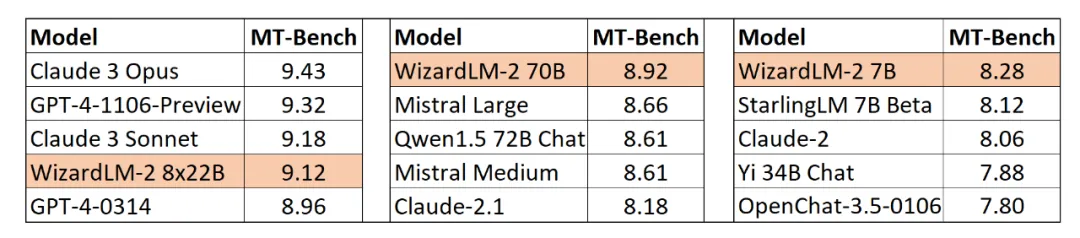
前段时间,微软搞了个乌龙:隆重地开源了 WizardLM-2,又在不久后撤回得干干净净。

ChatGPT-4 被认为是人工智能技术发展的重要节点,语言大模型之后的多模态大模型初步显现了世界模型的影子。大模型最终将通过硬件与物理世界产生交互。人工智能的应用实现从数字世界到物理世界的扩展,具身智能是非常关键的技术方向。

每一次关键技术取得通用化的突破,都会深刻改变生产方式,并显著提升生产力水平,而「大模型」成为了打通人工智能技术通用性「任督二脉」的关键。智慧眼,作为全球领先的人工智能企业,最近推出了其创新研发的通用大模型——砭石。

距离夏天越来越近了,GPT-4.5/5 的亮相预计已经进入倒计时,关于 ChatGPT 的新消息开始噌噌地冒出来了。

一家线上教育产品公司如何巧用大模型之力获得新增长?多邻国可以称得上是全球市场典型的范本之一。

全球首台,黄仁勋亲自送货上门,OpenAI首发,DGX H200算是把流量拉满了。

时间倒回前几年,如果小雷和小伙伴们聊聊AI,你们可能觉得我在天方夜谭?

想象一下,你仅需要输入一段简单的文本描述,就可以生成对应的 3D 数字人动画的骨骼动作。而以往,这通常需要昂贵的动作捕捉设备或是专业的动画师逐帧绘制。这些骨骼动作可以进一步的用于游戏开发,影视制作,或者虚拟现实应用。来自阿尔伯塔大学的研究团队提出的新一代 Text2Motion 框架,MoMask,正在让这一切变得可能。

今年 2 月份,OpenAI 发布了人工智能文生视频大模型 Sora,并放出了第一批视频片段,掀起了 AI 生成视频浪潮。目前,Sora 仍未进行公测,只有一些视觉艺术家、设计师、电影制作人等获得了 Sora 的访问权限。他们发布了一些 Sora 生成的视频短片,其连贯、逼真的生成效果令人惊艳。