

ICML 2024 | 大语言模型预训练新前沿:「最佳适配打包」重塑文档处理标准
ICML 2024 | 大语言模型预训练新前沿:「最佳适配打包」重塑文档处理标准在大型语言模型的训练过程中,数据的处理方式至关重要。
来自主题: AI技术研报
10930 点击 2024-05-16 17:41
在大型语言模型的训练过程中,数据的处理方式至关重要。

最近一段时间,端侧生成式 AI 上游的「军备竞赛」异常激烈。
OpenAI总裁兼联合创始人Greg再次大秀GPT-4o操作,结果网友直接缅怀DALL-E图片。
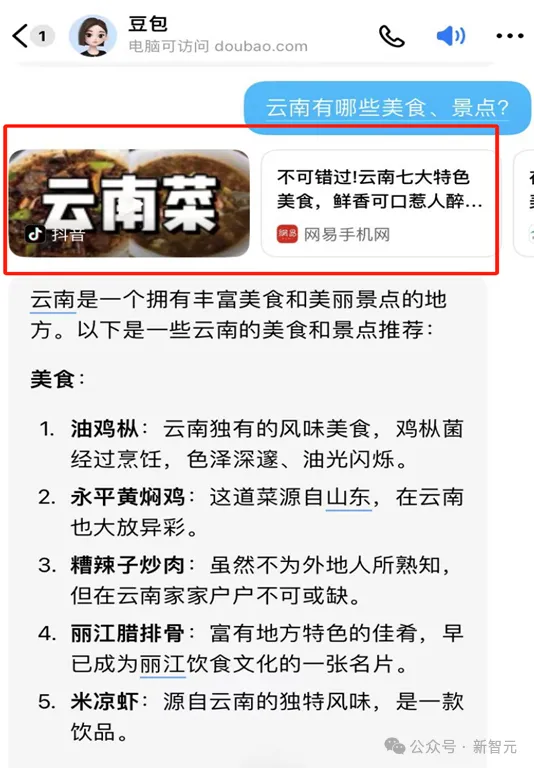
大模型正以前所未有的速度重塑我们的工作和生活方式,人们期待大模型走向千行百业,为实际业务带来真正的价值提升。

在这场“全面升级”的大模型商战中,谷歌如何还击?相信很快就会揭晓。

多模态体验,正在开始成为大模型产品的交互标准

过去一年,围绕着字节AI的几个谜团,终于都在今天被揭开了。

开源TinyML好处多

这就是谷歌对 OpenAI 的回应。

与之前的版本相比,GPT-4o最大改进在于它在整合方面的精细度,它将所有模态集成在一个端到端的模型中(All in One)。
Ilya Sutskever宣布退出OpenAI,震动整个AI圈。

起了个大早,赶了个晚集的谷歌,AI时代还有没有机会?

机器人技术已经有70年的历史了,从诞生之初就一直由美国领跑。

北京时间 5 月 15 日凌晨,在 OpenAI 春季发布会的第二天,2024 年谷歌 I/O 召开,这是一场充满了 AI 的发布会,谷歌对其旗下的多款 AI 产品发布了大更新,从基座模型 Gemini 到新的 AI 助手 Astra、新的文生视频模型 Veo,以及更强大的文生图模型 Imagen 3。

今年的Google Shoreline圆形剧场 ,弥漫着一种前所未有的角斗场般的气息。

在《如何制造一个垂直领域大模型》一文中我们列举了几种开发垂直领域模型的方法。其中医疗、法律等专业是比较能体现模型垂直行业能力的,因此也深受各大厂商的重视。

ChatGPT 横空出世,让原本有些沉寂的人工智能技术再次成为人们关注的焦点。

本文是对发表于模式识别领域顶刊Pattern Recognition 2024的最新综述论文:「Advancements in Point Cloud Data Augmentation for Deep Learning: A Survey 」的解读。

去年 11 月 8 日,新加坡政府科技局(GovTech)组织举办了首届 GPT-4 提示工程(Prompt Engineering)竞赛。数据科学家 Sheila Teo 最终夺冠,成为最终的提示女王(Prompt Queen)。

红极一时的思维链技术,可能要被推翻了!

AI教父Hinton的担心,不是没有道理。
这周既没有GPT-5,也没有搜索引擎的发布,不过,OpenAI也是没闲着。

关于大模型分词(tokenization),大神Karpathy刚刚推荐了一篇必读新论文。
OpenAI发布会前一天,员工集体发疯中……上演大型套娃行为艺术。

猛然间,大模型圈掀起一股“降价风潮”。

随着深度学习大语言模型的越来越火爆,大语言模型越做越大,使得其推理成本也水涨船高。模型量化,成为一个热门的研究课题。

提高 GPU 利用率,就是这么简单。

5 月 11 日,在上海市浦东新区科技和经济委员会指导下,由中国(上海)自由贸易试验区管理委员会金桥管理局、上海市浦东新区产业发展促进中心、上海市浦东新区投资促进二中心、上海金桥(集团)有限公司主办,上海浦东科技创业中心、机器之心(上海)科技有限公司承办

世界模型,即通过预测未来的范式对数字世界和物理世界进行理解,是通往实现通用人工智能(AGI)的关键路径之一。

在过去的一年多里,无论你是否身处科技行业,都能感受到一种强烈的趋势:人工智能正在重塑每个人的生活。