给NeRF开透视眼!稀疏视角下用X光进行三维重建,9类算法工具包全开源 | CVPR 2024
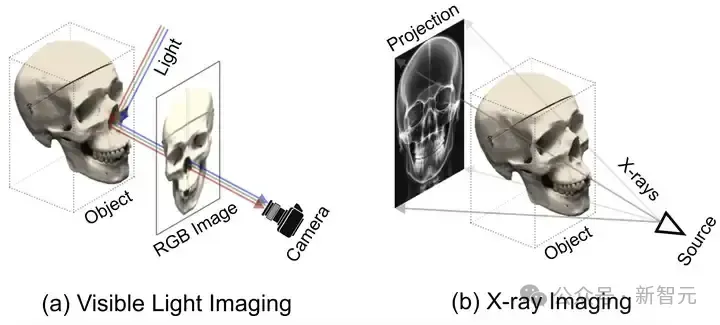
给NeRF开透视眼!稀疏视角下用X光进行三维重建,9类算法工具包全开源 | CVPR 2024SAX-NeRF框架,一种专为稀疏视角下X光三维重建设计的新型NeRF方法,通过Lineformer Transformer和MLG采样策略显著提升了新视角合成和CT重建的性能。研究者还建立了X3D数据集,并开源了代码和预训练模型,为X光三维重建领域的研究提供了宝贵的资源和工具。
来自主题: AI技术研报
10521 点击 2024-06-20 10:27