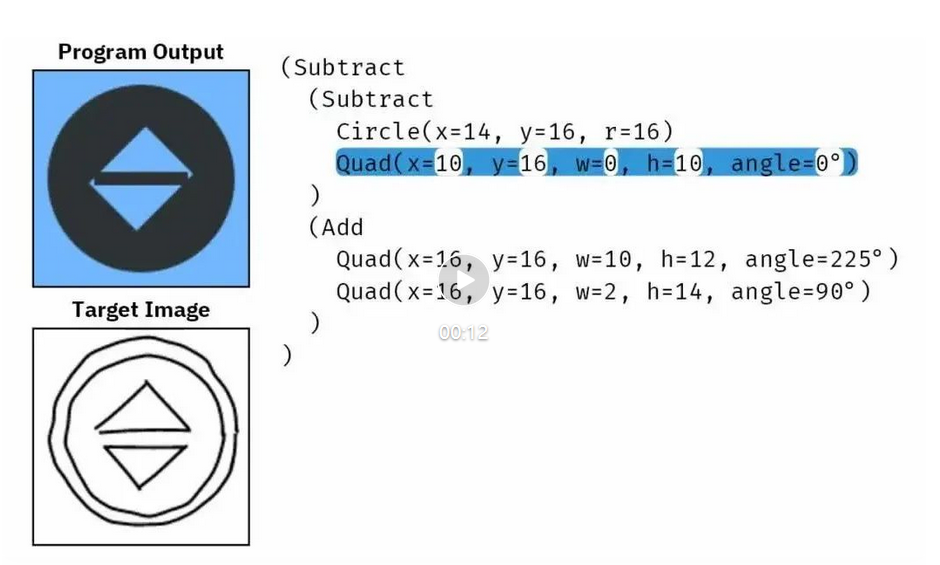
神经网络可能不再需要激活函数?Layer Normalization也具有非线性表达!
神经网络可能不再需要激活函数?Layer Normalization也具有非线性表达!神经网络通常由三部分组成:线性层、非线性层(激活函数)和标准化层。线性层是网络参数的主要存在位置,非线性层提升神经网络的表达能力,而标准化层(Normalization)主要用于稳定和加速神经网络训练,很少有工作研究它们的表达能力,例如,以Batch Normalization为例
来自主题: AI技术研报
6916 点击 2024-07-02 17:38