

权重、代码、数据集全开源,性能超越Mistral-7B,苹果小模型来了
权重、代码、数据集全开源,性能超越Mistral-7B,苹果小模型来了小模型成趋势?
来自主题: AI技术研报
11393 点击 2024-07-21 14:19
小模型成趋势?
首个专为各种机器人设计的模拟互动 3D 社会。
![使用视觉语言模型进行 PDF 检索 [译]](https://blog.vespa.ai/assets/2024-07-15-retrieval-with-vision-language-models-colpali/GRuDx-xXAAAFqBR.jpeg)
近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。

低秩适应(Low-Rank Adaptation,LoRA)通过可插拔的低秩矩阵更新密集神经网络层,是当前参数高效微调范式中表现最佳的方法之一。此外,它在跨任务泛化和隐私保护方面具有显著优势。

GPT-4o mini头把交椅还未坐热,Mistral AI联手英伟达发布12B参数小模型Mistral Nemo,性能赶超Gemma 2 9B和Llama 3 8B。

AI经过多轮“自我提升”,能力不增反降?

著名AI学者、斯坦福大学教授吴恩达提出了AI Agent的四种设计方式后,Agentic Workflow(智能体工作流)立即火爆全球,多个行业都在实践智能体工作流的应用,并推动了新的Agentic AI探索热潮。
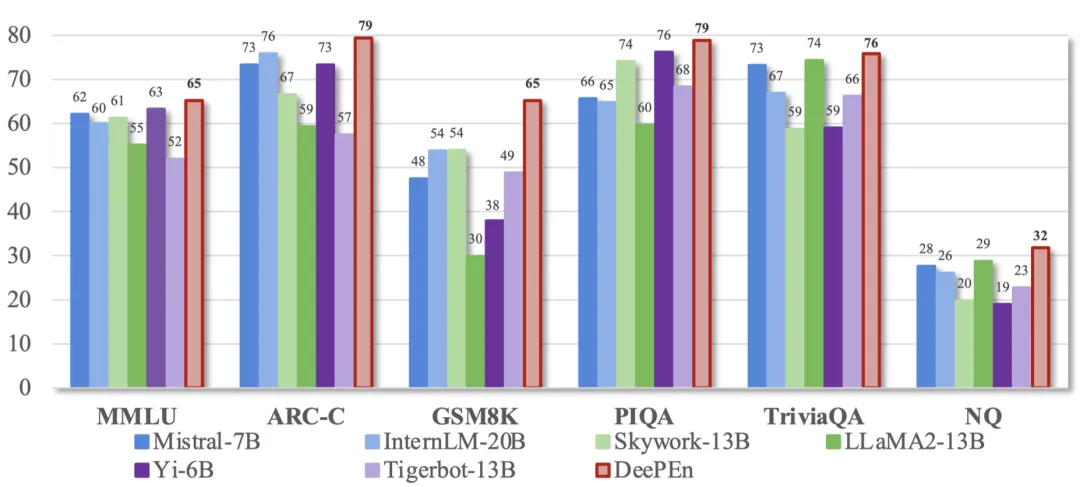
随着大语言模型展现出惊人的语言智能,各大 AI 公司纷纷推出自己的大模型。这些大模型通常在不同领域和任务上各有所长,如何将它们集成起来以挖掘其互补潜力,成为了 AI 研究的前沿课题。

MoE 因其在训推流程中低销高效的特点,近两年在大语言模型领域大放异彩。作为 MoE 的灵魂,专家如何能够发挥出最大的学习潜能,相关的研究与讨论层出不穷。此前,华为 GTS AI 计算 Lab 的研究团队提出了 LocMoE ,包括新颖的路由网络结构、辅助降低通信开销的本地性 loss 等,引发了广泛关注。

大模型开源的热潮下,隐藏着诸多问题,从定义的模糊到实际开放内容的局限性,Lecun再陷Meta大模型是否真开源的质疑风波只是冰山一角。
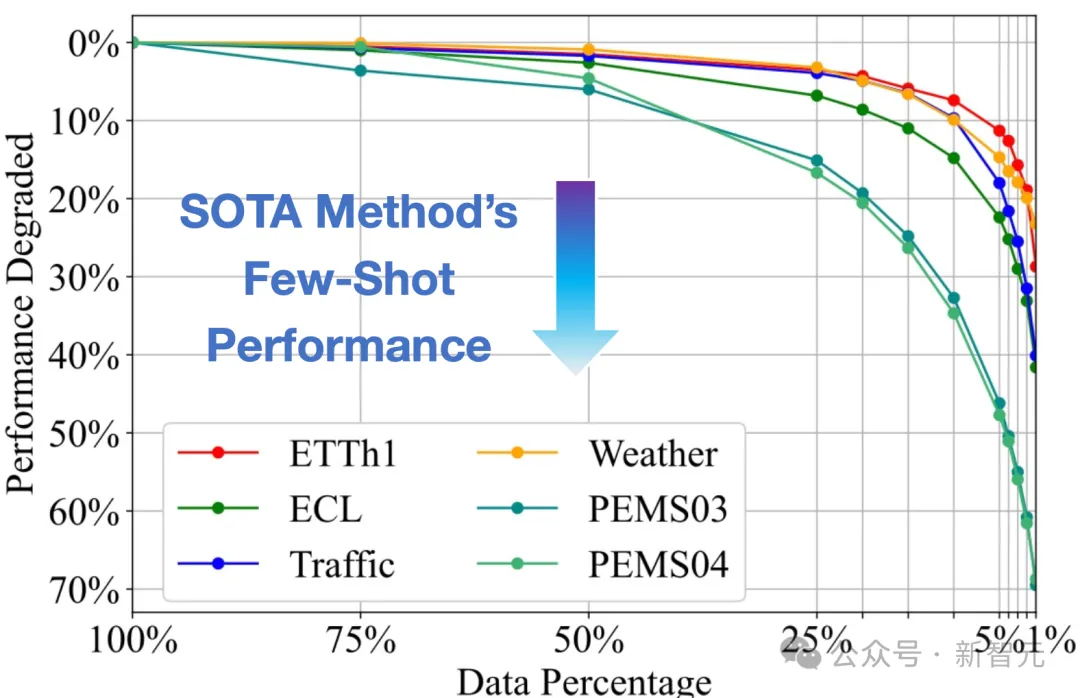
大模型在语言、图像领域取得了巨大成功,时间序列作为多个行业的重要数据类型,时序领域的大模型构建尚处于起步阶段。近期,清华大学的研究团队基于Transformer在大规模时间序列上进行生成式预训练,获得了任务通用的时序分析模型,展现出大模型特有的泛化性与可扩展性
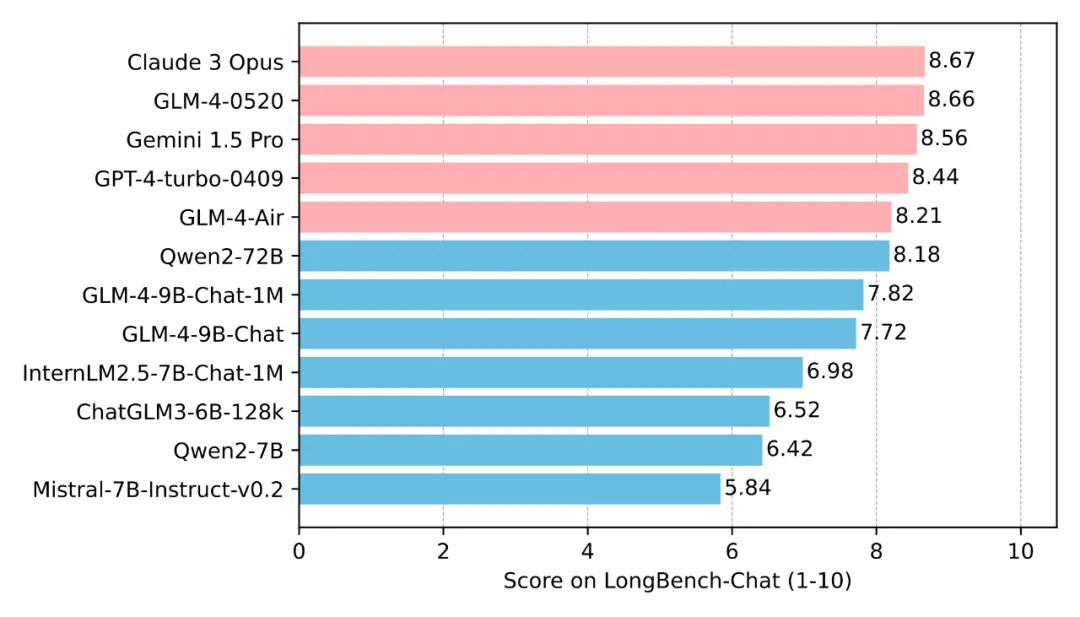
在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k。然而,时至今日,1M的上下文长度已经成为衡量模型技术先进性的重要标志之一。
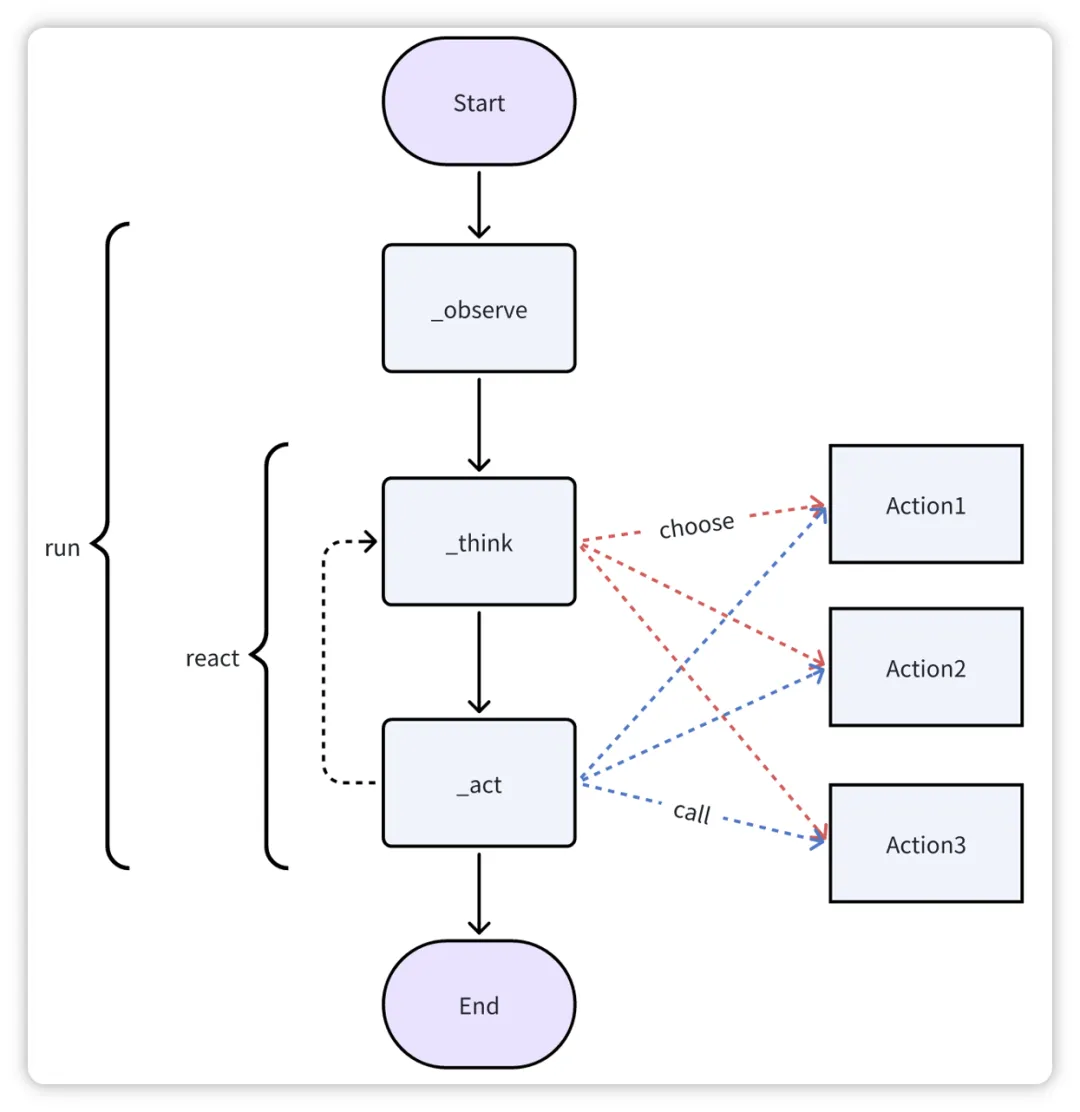
Agent 是什么

大模型测试能拿高分,实际场景中却表现不佳的问题有解了。

只需激活60%的参数,就能实现与全激活稠密模型相当的性能。

好家伙!为了揭秘Transformer内部工作原理,陈丹琦团队直接复现——

当我们不停在CoT等领域大下苦功、试图提升LLM推理准确性的同时,OpenAI的对齐团队从另一个角度发现了华点——除了准确性,生成答案的清晰度、可读性和可验证性也同样重要。

自回归解码已经成为了大语言模型(LLMs)的事实标准,大语言模型每次前向计算需要访问它全部的参数,但只能得到一个token,导致其生成昂贵且缓慢。

近日,快手可灵大模型团队开源了名为LivePortrait的可控人像视频生成框架,该框架能够准确、实时地将驱动视频的表情、姿态迁移到静态或动态人像视频上,生成极具表现力的视频结果。

最近,7B小模型又成为了AI巨头们竞相追赶的潮流。继谷歌的Gemma2 7B后,Mistral今天又发布了两个7B模型,分别是针对STEM学科的Mathstral,以及使用Mamaba架构的代码模型Codestral Mamba。

视频生成也能参考“上下文”?!

大模型理解、推理Excel,现在变得更加精准了。
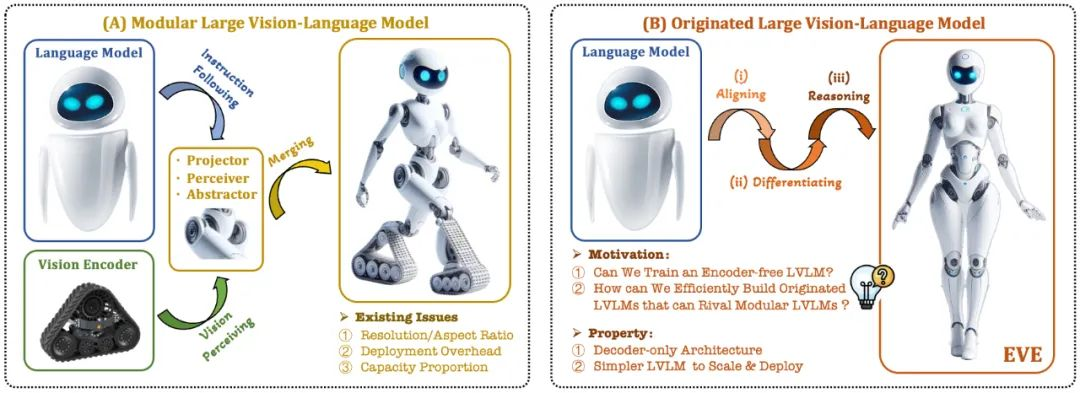
近期,关于多模态大模型的研究如火如荼,工业界对此的投入也越来越多。

把因果链展示给 LLM,它就能学会公理。

视觉大语言模型在最基础的视觉任务上集体「翻车」,即便是简单的图形识别都能难倒一片,或许这些最先进的VLM还没有发展出真正的视觉能力?
最核心的Claude 3.5编码系统提示,火遍Reddit社区。就在刚刚,原作者发布了进化后的第二版,有的网友已经将其加入工作流。

MoE已然成为AI界的主流架构,不论是开源Grok,还是闭源GPT-4,皆是其拥趸。然而,这些模型的专家,最大数量仅有32个。最近,谷歌DeepMind提出了全新的策略PEER,可将MoE扩展到百万个专家,还不会增加计算成本。

无需训练或微调,在提示词指定的新场景中克隆参考视频的运动,无论是全局的相机运动还是局部的肢体运动都可以一键搞定。

自从 Devin(首个全自动 AI 软件工程师)提出以来,针对软件工程的 AI Agent 的设计成为研究的焦点,越来越多基于 Agent 的 AI 自动软件工程师被提出,并在 SWE-bench 数据集上取得了不俗的表现、自动修复了许多真实的 GitHub issue。

准确诊断痴呆症有利于老年人晚年的身体健康,并减轻他们的家庭负担。