

ACM TOG|仅通过手机拍照就可以对透明物体进行三维重建
ACM TOG|仅通过手机拍照就可以对透明物体进行三维重建三维重建是计算机图形学的经典任务,具有很强的使用价值。近年来,诸如神经辐射场的隐式场方法 [1][2][3][4] 正成为重建任务广泛采用的表示。
来自主题: AI技术研报
9396 点击 2024-09-25 09:13
三维重建是计算机图形学的经典任务,具有很强的使用价值。近年来,诸如神经辐射场的隐式场方法 [1][2][3][4] 正成为重建任务广泛采用的表示。

NVLM 1.0系列多模态大型语言模型在视觉语言任务上达到了与GPT-4o和其他开源模型相媲美的水平,其在纯文本性能甚至超过了LLM骨干模型,特别是在文本数学和编码基准测试中,平均准确率提高了4.3个百分点。
两个多月前那个对标GPT-4o的端到端语音模型,终于开源了。大神Karpathy体验之后表示:nice!

语音合成大模型赛道,王者一夜易主。

这是关于垂直 SaaS (Vertical SaaS)的两部分系列的第一部分。

AI玩黑神话,第一个精英怪牯护院轻松拿捏啊。

OpenAI的o1系列一发布,传统数学评测基准都显得不够用了。

DeepMind最近的研究提出了一种新框架AligNet,通过模拟人类判断来训练教师模型,并将类人结构迁移到预训练的视觉基础模型中,从而提高模型在多种任务上的表现,增强了模型的泛化性和鲁棒性,为实现更类人的人工智能系统铺平了道路。

视觉 / 激光雷达里程计是计算机视觉和机器人学领域中的一项基本任务,用于估计两幅连续图像或点云之间的相对位姿变换。它被广泛应用于自动驾驶、SLAM、控制导航等领域。最近,多模态里程计越来越受到关注,因为它可以利用不同模态的互补信息,并对非对称传感器退化具有很强的鲁棒性。

扩展多模态大语言模型(MLLMs)的长上下文能力对于视频理解、高分辨率图像理解以及多模态智能体至关重要。这涉及一系列系统性的优化,包括模型架构、数据构建和训练策略,尤其要解决诸如随着图像增多性能下降以及高计算成本等挑战。

无需依赖外部反馈或额外模型,纯纯的自我纠正。
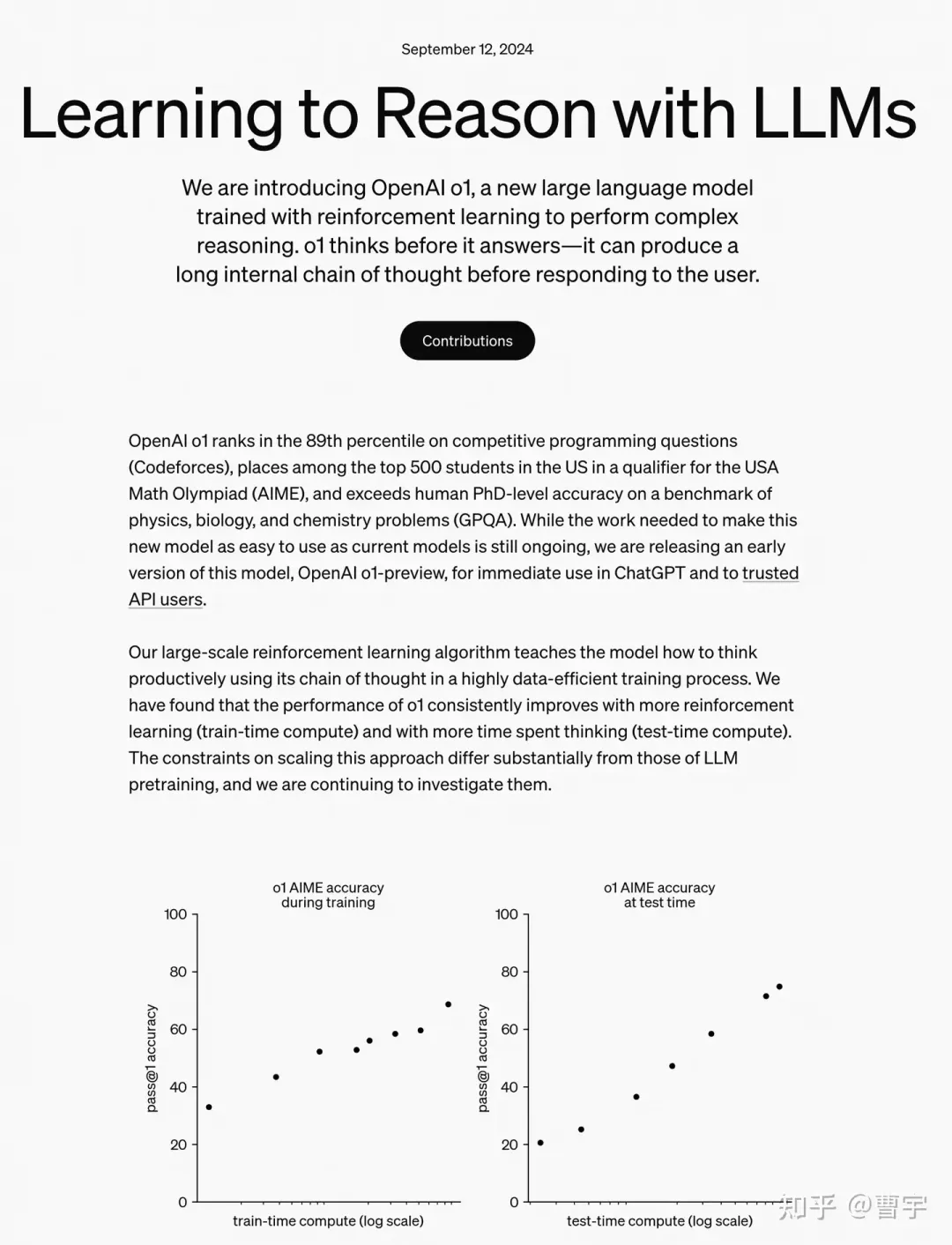
OpenAI的self-play RL新模型o1最近交卷,直接引爆了关于对于self-play的讨论。

o1,Inference law,推理定律,模型训练

当谷歌的Gemini建议给比萨加胶水时,网友尚能发挥娱乐精神玩梗解构;但当LLM输出的诽谤信息中伤到到真实人类时,AI搜索引擎的未来是否值得再三思量?
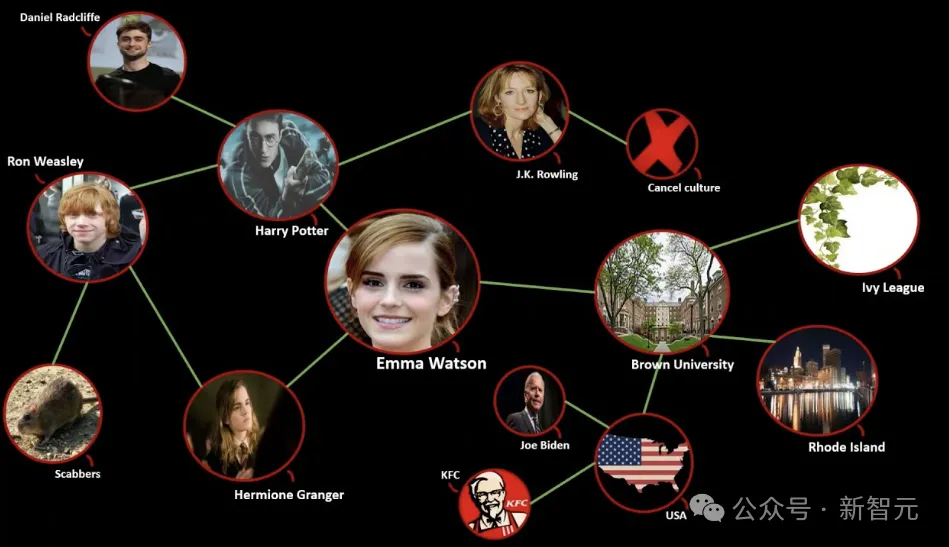
近日,来自海德堡大学的研究人员推出了图语言模型 (GLM),将语言模型的语言能力和知识图谱的结构化知识,统一到了同一种模型之中。

o1大火背后,最关键的技术是CoT。模型通过一步一步推理,恰恰是「慢思考」的核心要义。而这一观点,其实这家国内大厂早就率先实现了。

随OpenAI爆火的CoT,已经引发了大佬间的激战!谷歌DeepMind首席科学家Denny Zhou拿出一篇ICLR 2024论文称:CoT可以让Transformer推理无极限。但随即他就遭到了田渊栋和LeCun等的质疑。最终,CoT会是通往AGI的正确路径吗?

近日,香港大学发布最新研究成果:智能交通大模型OpenCity。该模型根据参数大小分为OpenCity-mini、OpenCity-base和OpenCity-Pro三个模型版本,显著提升了时空模型的零样本预测能力,增强了模型的泛化能力。
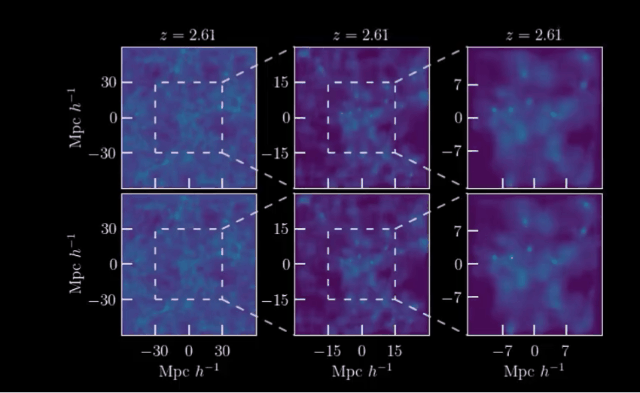
AI开启模拟宇宙!近日,来自马克斯·普朗克研究所等机构,利用宇宙学和红移依赖性对宇宙结构形成进行了场级仿真,LeCun也在第一时间转发和推荐。

APP内“智能体”数量大增,如通义已经超过14000个、讯飞星火超过11000个、豆包超过5000个
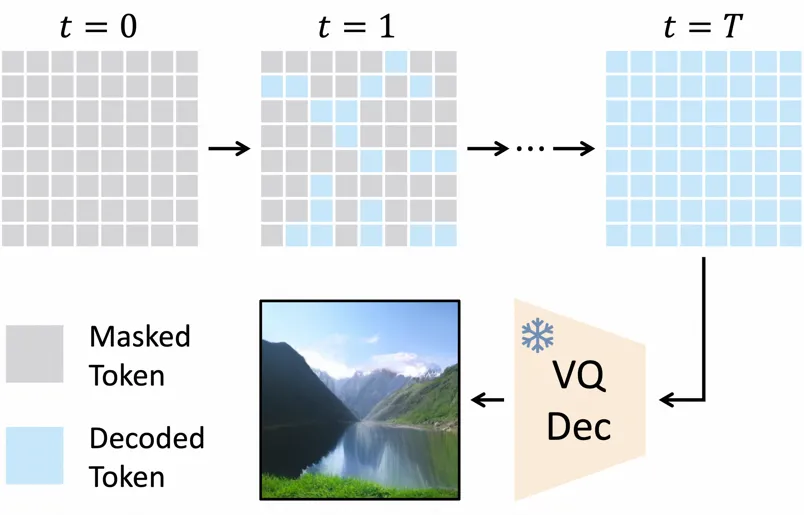
本论文第一作者倪赞林是清华大学自动化系 2022 级直博生,师从黄高副教授,主要研究方向为高效深度学习与图像生成。他曾在 ICCV、CVPR、ECCV、ICLR 等国际会议上发表多篇学术论文。

注意力是 Transformer 架构的关键部分,负责将每个序列元素转换为值的加权和。将查询与所有键进行点积,然后通过 softmax 函数归一化,会得到每个键对应的注意力权重。

金融大模型产业发展与应用趋势分析。

随便给张图就能从更多视角查看全景了?!
关注o1必备的GitHub库,它来了!
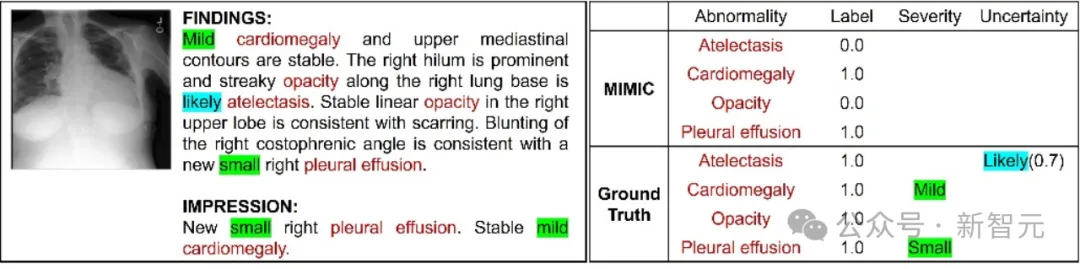
研究人员提出了一个新的胸部X光图像数据集,该数据集包含临床不确定性和严重性感知的标签,并通过多关系图学习方法进行分析,以提高疾病分类的准确性,扩展了现有的疾病标签信息。

除了蛋白质设计和药物发现,Nature上最近刊登的一篇论文又解锁了AlphaFold这类生物大模型的新用途——揭示生物的亲缘关系和进化史。

刚刚,OpenAI重金押注的人形机器人初创1X终于揭秘了背后的「世界模型」——它能够根据真实数据,生成针对不同场景的中的行为预测!机器人领域的ChatGPT时刻,或许真的要来了。
优秀的 GitHub 项目啊!有关 OpenAI ο1 的一切都在这里

斯坦福大学的最新研究通过大规模实验发现,尽管大型语言模型(LLMs)在新颖性上优于人类专家的想法,但在可行性方面略逊一筹,还需要进一步研究以提高其实用性。