

5秒内快速生成、直出工业级PBR资产,三维扩散模型3DTopia-XL开源
5秒内快速生成、直出工业级PBR资产,三维扩散模型3DTopia-XL开源是否还在苦恼于开源图生 / 文生三维模型无法直接嵌入到 CG 工作流中?是否在寻找具备高质量几何与物理材质的三维生成大模型?
来自主题: AI技术研报
8376 点击 2024-10-04 19:05
是否还在苦恼于开源图生 / 文生三维模型无法直接嵌入到 CG 工作流中?是否在寻找具备高质量几何与物理材质的三维生成大模型?
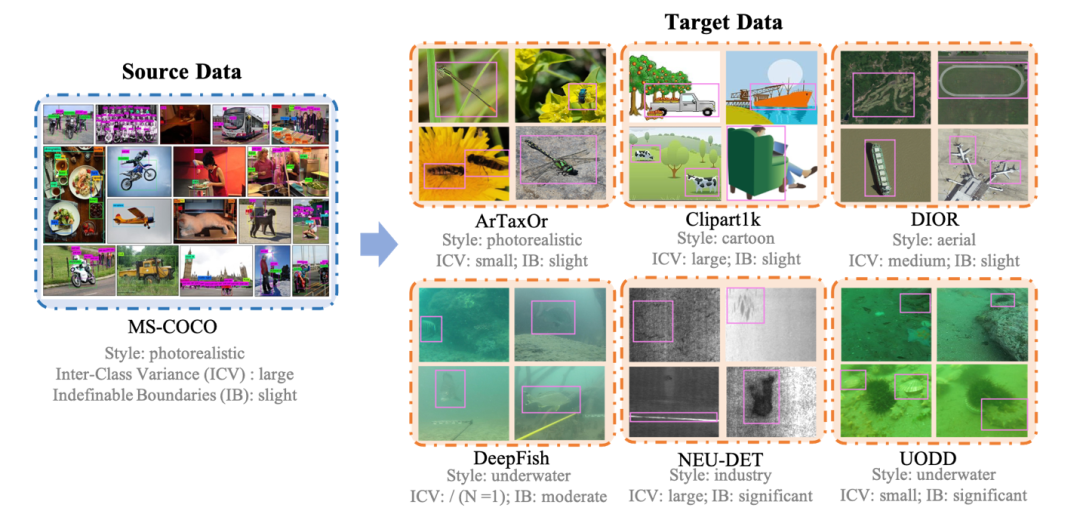
解决跨域小样本物体检测问题,入选ECCV 2024。

挑战Transformer,MIT初创团队推出LFM(Liquid Foundation Model)新架构模型爆火。

摩根大通(J.P. Morgan)在2024年9月发布“Investable AI Summary of J.P. Morgan research and industry developments in 2024”关于人工智能(AI)2024年的研究和行业发展总结。

在机器人研究领域,抓取任务始终是机器人操作中的一个关键问题。这项任务的核心目标是控制机械手移动到合适位置,并完成对物体的抓取。近年来,基于学习的方法在提高对不同物体的抓取的泛化能力上取得了显著进展,但针对机械手本身,尤其是复杂的灵巧手(多指机械手)之间的泛化能力仍然缺乏深入研究。由于灵巧手在不同形态和几何结构上存在显著差异,抓取策略的跨手转移一直存在挑战。

计算机科学、数学、自然科学、医学、语言学、社会科学……OpenAI o1擅长什么?还有哪些不足?
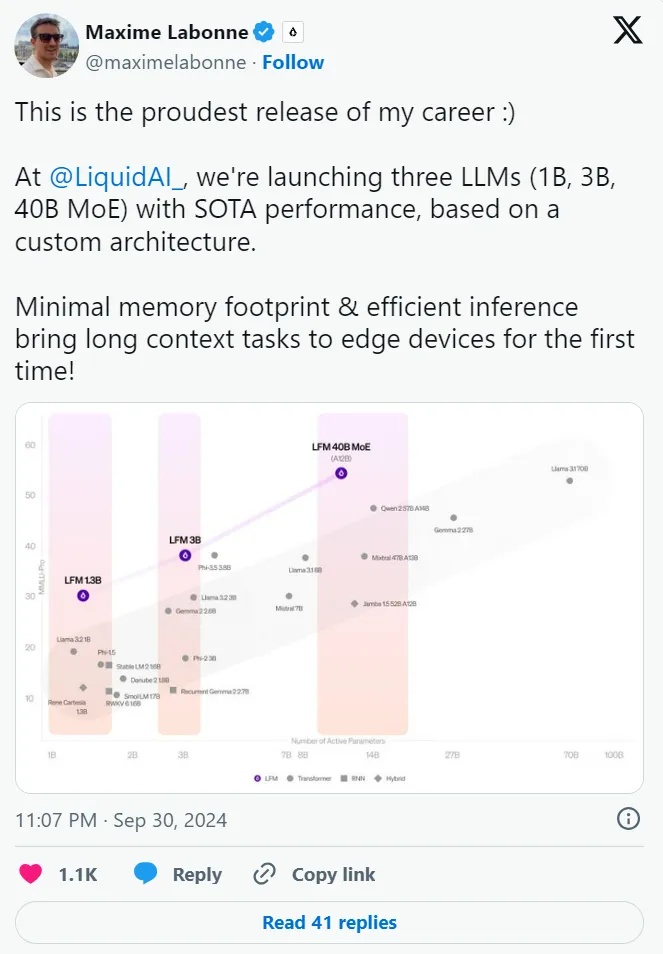
一个受线虫启发的全新架构,三大「杯型」均能实现 SOTA 性能,资源高度受限环境也能部署。移动机器人可能更需要一个虫子的大脑。

近日,北京大学陈宝权教授在第九届计算机图形学与混合现实研讨会(GAMES 2024)上,发表了题为《从图形计算到世界模型》的主旨报告,分享了他从图形仿真角度对世界模型的思考。本文是对陈教授报告的完整整理,以供大家学习。

在医疗领域中,大语言模型已经有了广泛的研究。然而,这些进展主要依赖于英语的基座模型,并受制于缺乏多语言医疗专业数据的限制,导致当前的医疗大模型在处理非英语问题时效果不佳。

在人工智能技术发展最快的美国,人们对生成式人工智能的使用情况怎样? 美国全国经济研究所(NBER)日前发布的最新一篇工作论文《The Rapid Adoption of Generative AI》给出了答案。NBER是美国最大的经济学研究组织,其发布的工作论文代表着经济学研究最新的成果。

想参加陶哲轩发起的「众包」数学研究项目吗? 机会来了!
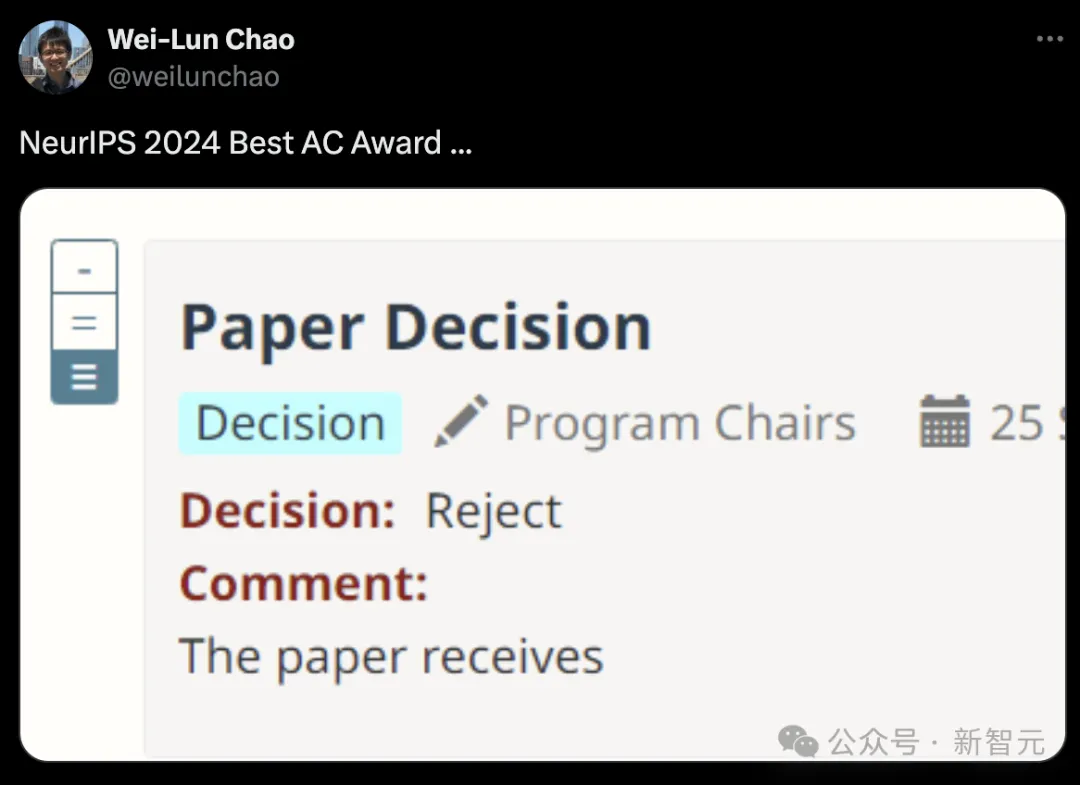
NeurIPS 2024评审结果已经公布了! 收到邮件的小伙伴们,就像在开盲盒一样,纷纷在社交媒体上晒出了自己的成绩单。
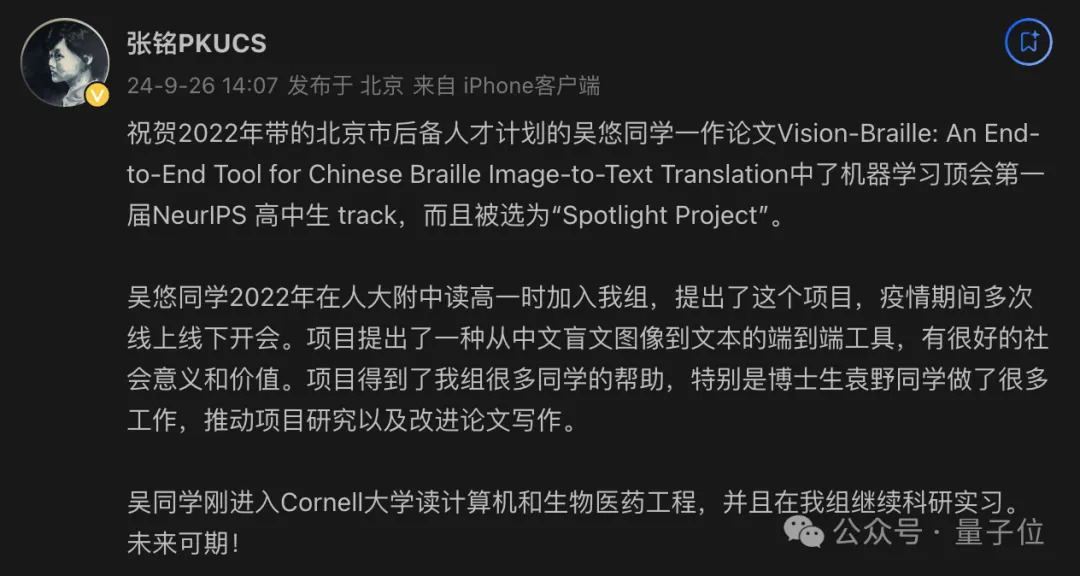
NeurIPS 2024放榜,人大附中有高中生一作入选。
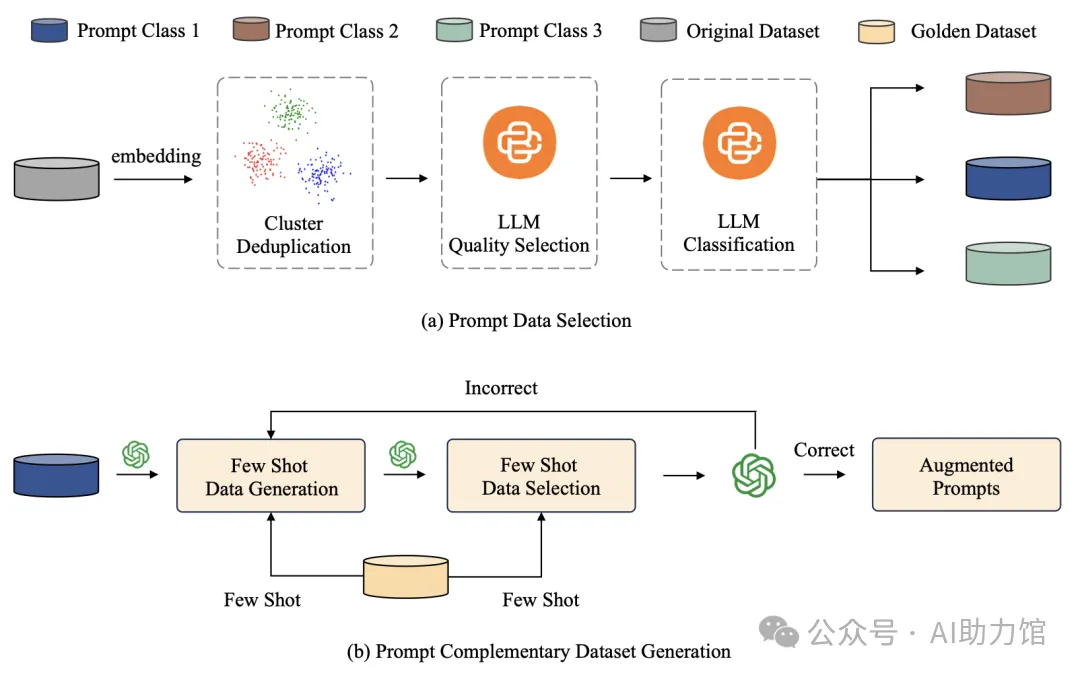
在人工智能的世界里,大型语言模型(LLM)已经成为我们探索未知、解决问题的得力助手。但是,你在编写AI提示词时,是否觉得这个过程就像在“炼丹”,既神秘又难以掌握?别担心,自动提示工程(APE)来帮你了!
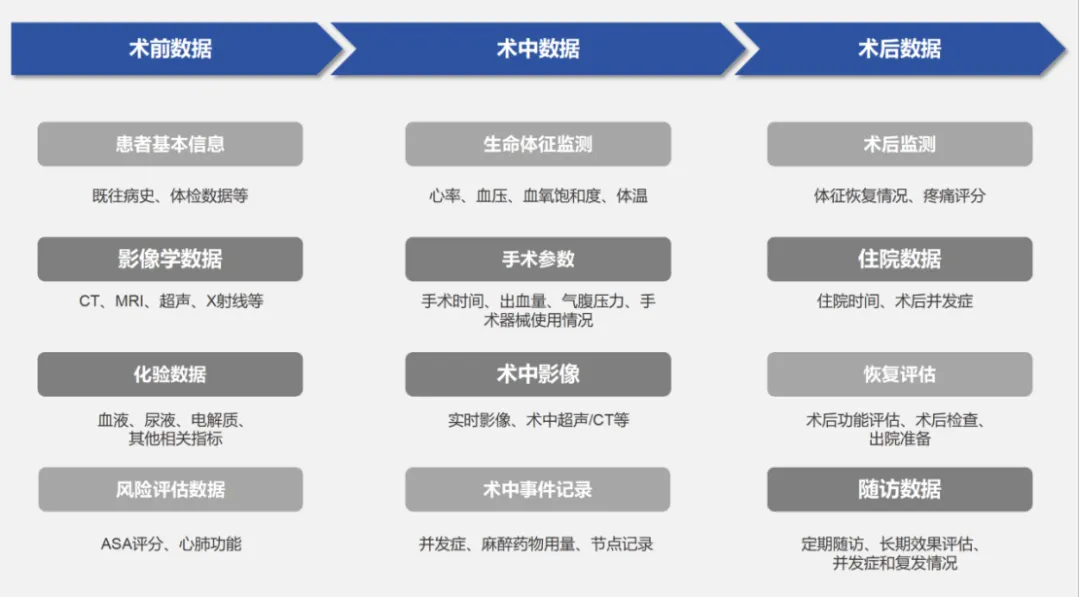
外科医生Dr. Lee在一次美敦力的学术讨论上说到,“外科医生和精英运动员非常相似,都在团队环境中工作,不断的重复训练已达到顶尖的成绩。但运动员往往花费更多的时间在影像室,回顾和研究过去的表现。而医生目前还没有得到足够、及时的信息反馈,以学习和提升手术技能。”

在这种背景下,研究团队提出了一个全新的框架:SubgoalXL,结合了子目标(subgoal)证明策略与专家学习(expert learning)方法,在 Isabelle 中实现了形式化定理证明的性能突破。

香港中文大学等机构的研究团队通过深度强化学习(DQN)开发了一种3D打印路径规划器,有效提升了打印效率和精度,为智能制造开辟了新途径。

Google DeepMind的SCoRe方法通过在线多轮强化学习,显著提升了大型语言模型在没有外部输入的情况下的自我修正能力。该方法在MATH和HumanEval基准测试中,分别将自我修正性能提高了15.6%和9.1%。
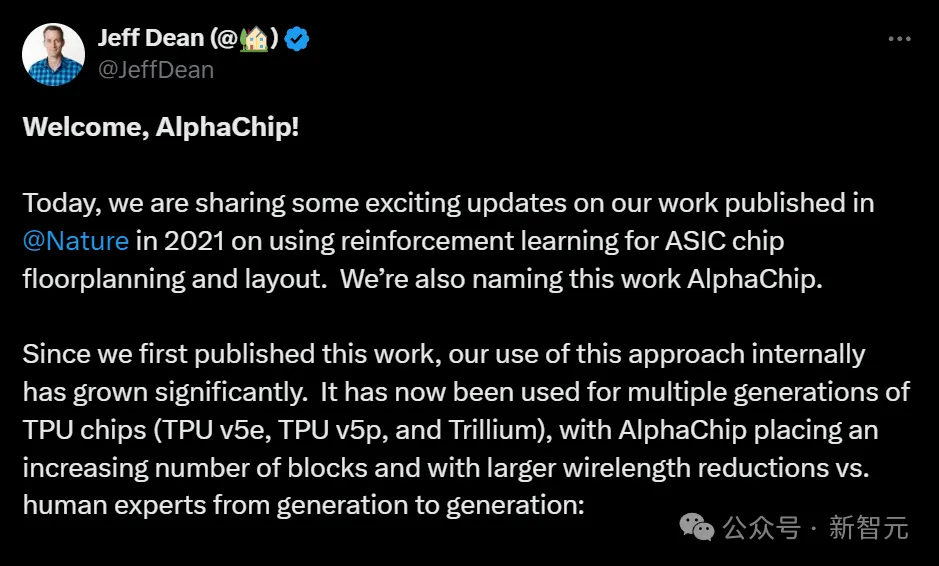
谷歌的AlphaChip,几小时内就能设计出芯片布局,直接碾压人类专家!这种超人芯片布局,已经应用在TPU、CPU在内的全球硬件中。人类设计芯片的方式,已被AI彻底改变。

通往AGI的路径只有一条吗?实则不然。这家国产AI黑马认为,「群体智能」或许是一种最佳的尝试。他们正打破惯性思维,打造出最强AI大脑,要让世界每一台设备都有自己的智能。

2024年,生成式人工智能技术正引领客户联络中心经历一场革命性变革。客户服务和支持的重要性对企业不言而喻,卓越的客户体验尤其是当下激烈竞争的市场环境中企业制胜的关键。
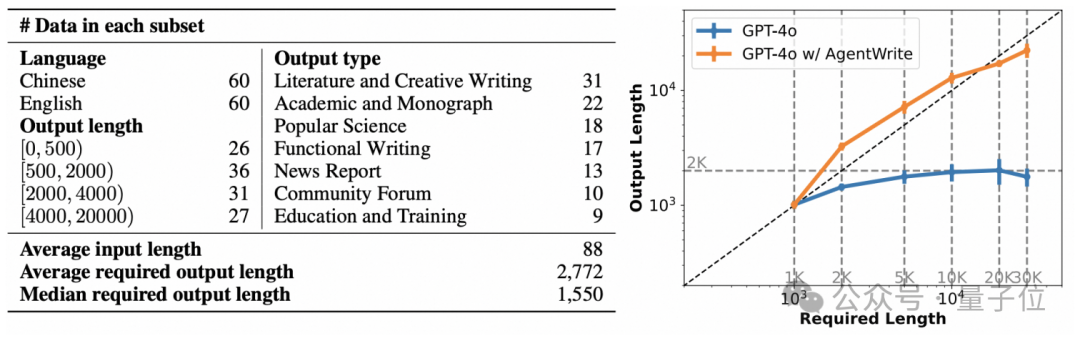
仅需600多条数据,就能训练自己的长输出模型了?!

服务器CPU领域持续多年的核心数量大战,被一举终结了!
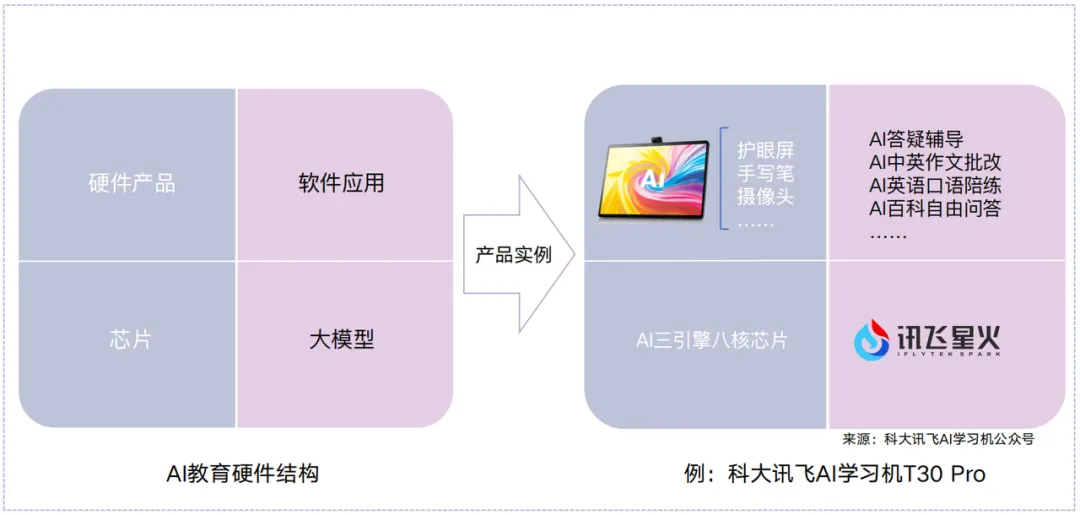
近一年来,AI硬件在教育领域迎来爆发式增长

SafeEar是一种内容隐私保护的语音伪造检测方法,其核心是设计基于神经音频编解码器的解耦模型,分离语音声学与语义信息,仅利用声学信息检测,包括前端解耦模型、瓶颈层和混淆层、伪造检测器、真实环境增强四部分。
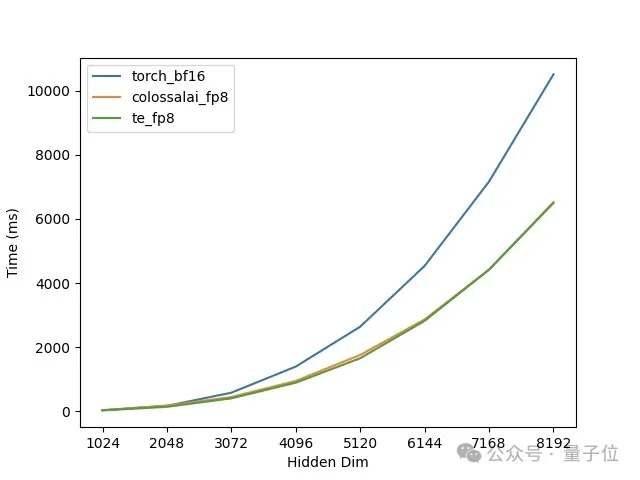
FP8通过其独特的数值表示方式,能够在保持一定精度的同时,在大模型训练中提高训练速度、节省内存占用,最终降低训练成本。

自适应系统在动态和不确定的环境中具有关键作用,广泛应用于自动驾驶、智能制造、网络安全和智能医疗等领域。

指令调优(Instruction tuning)是一种优化技术,通过对模型的输入进行微调,以使其更好地适应特定任务。先前的研究表明,指令调优样本效率是很高效的,只需要大约 1000 个指令-响应对或精心制作的提示和少量指令-响应示例即可。

科学技术的快速发展过程中,机器学习研究作为创新的核心驱动力,面临着实验过程复杂、耗时且易出错,研究进展缓慢以及对专门知识需求高的挑战。近年来,LLM 在生成文本和代码方面展现出了强大的能力,为科学研究带来了前所未有的可能性。然而,如何系统化地利用这些模型来加速机器学习研究仍然是一个有待解决的问题。

深入探讨OpenAI o1模型的技术原理以及产业影响。