

首个o1复现开源RL框架OpenR来了,UCL、上交等高校联合团队发布
首个o1复现开源RL框架OpenR来了,UCL、上交等高校联合团队发布o1 作为 OpenAI 在推理领域的最新模型,大幅度提升了 GPT-4o 在推理任务上的表现,甚至超过了平均人类水平。o1 背后的技术到底是什么?OpenAI 技术报告中所强调的强化学习和推断阶段的 Scaling Law 如何实现?
来自主题: AI技术研报
5334 点击 2024-10-14 15:37
o1 作为 OpenAI 在推理领域的最新模型,大幅度提升了 GPT-4o 在推理任务上的表现,甚至超过了平均人类水平。o1 背后的技术到底是什么?OpenAI 技术报告中所强调的强化学习和推断阶段的 Scaling Law 如何实现?

在用模拟环境训练机器人时,所用的数据与真实世界存在着巨大的差异。为此,李飞飞团队提出「数字表亲」,这种虚拟资产既具备数字孪生的优势,还能补足泛化能力的不足,并大大降低了成本。
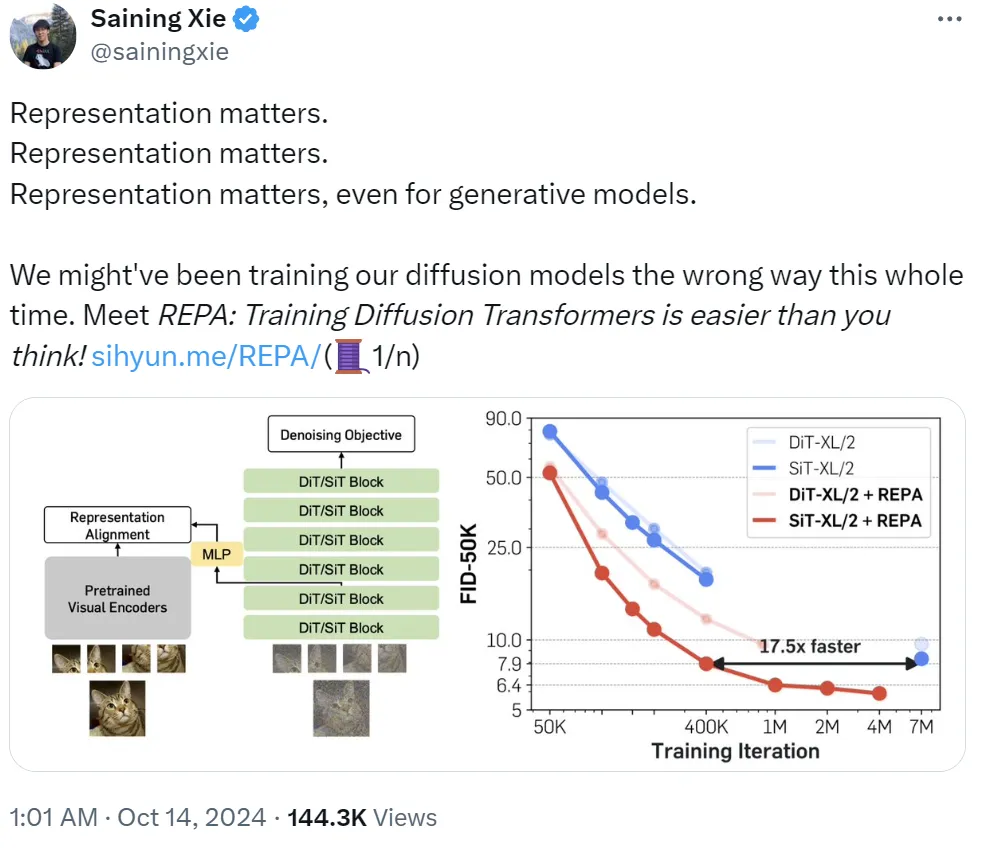
是什么让纽约大学著名研究者谢赛宁三连呼喊「Representation matters」?他表示:「我们可能一直都在用错误的方法训练扩散模型。」即使对生成模型而言,表征也依然有用。基于此,他们提出了 REPA,即表征对齐技术,其能让「训练扩散 Transformer 变得比你想象的更简单。」

传统的歌声任务,如歌声合成,大多是在利用输入的歌词和乐谱生成高质量的歌声。随着深度学习的发展,人们希望实现可控和能个性化定制的歌声生成。

1%的合成数据,就让LLM完全崩溃了? 7月,登上Nature封面一篇论文证实,用合成数据训练模型就相当于「近亲繁殖」,9次迭代后就会让模型原地崩溃。

毫无疑问,多智能体肯定是 OpenAI 未来重要的研究方向之一,前些天 OpenAI 著名研究科学家 Noam Brown 还在 X 上为 OpenAI 正在组建的一个新的多智能体研究团队招募机器学习工程师。

诺贝尔物理学奖和化学奖被AI「包圆」后,人们再次确信:基础科学研究的范式,已经被AI从根本上改变。

如果你对 arXiv 的版本号有所了解,你就知道这篇论文已经更新了 4 次,现在已经来到了第 5 个版本。实际上,这个 arXiv 编号属于上海交通大学牛力团队一篇持续更新了四年的综述报告。

在当今的人工智能领域,Transformer 模型已成为解决诸多自然语言处理任务的核心。然而,Transformer 模型在处理长文本时常常遇到性能瓶颈。传统的位置编码方法,如绝对位置编码(APE)和相对位置编码(RPE),虽然在许多任务中表现良好,但其固定性限制了其在处理超长文本时的适应性和灵活性。
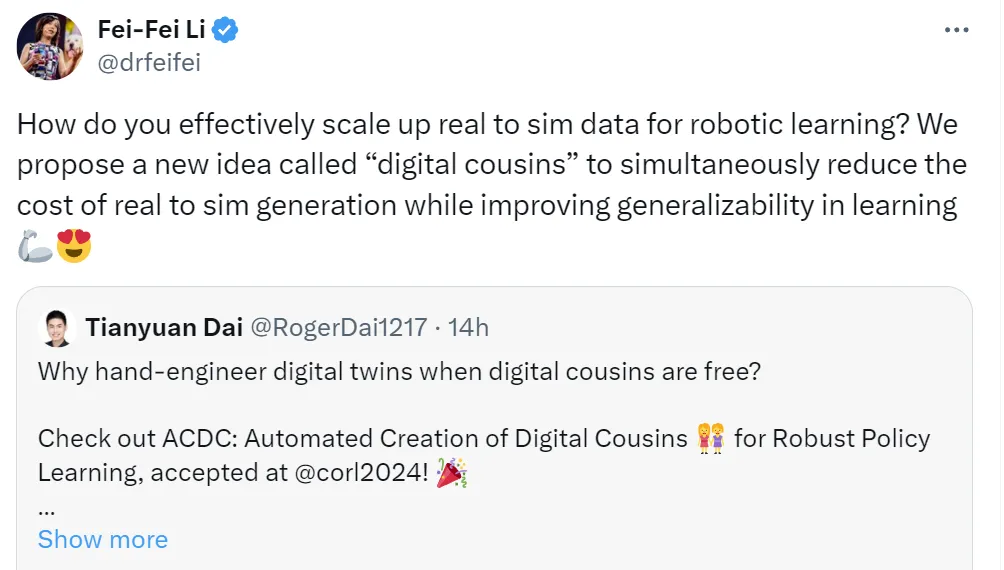
不百分百还原出虚拟场景,效果反而更好。

近日,来自谷歌DeepMind的研究人员提出了Michelangelo,「用米开朗基罗的观点」来测量任意上下文长度的基础模型性能。

本文是一篇发表在 NeurIPS 2024 上的论文,单位是香港大学、Sea AI Lab、Contextual AI 和俄亥俄州立大学。论文主要探讨了大型语言模型(LLMs)的词表大小对模型性能的影响。

猛,实在是猛!就在今日,老牌芯片巨头AMD交出了一份令人印象深刻的AI答卷。

OpenAI即将要兑现L3级智能体承诺了!MLE-bench新基准汇聚75个Kaggle竞赛,o1首测便拿下7金,多次尝试性能还能飙升17%,堪称首个AI Kaggle特级大师。

本届诺奖的AI含量,实在是过高了!今晚的文学奖会颁给ChatGPT或者奥特曼吗?已经有一大波网友下注了。另一边,Hinton已经炮轰起了奥特曼,力挺Ilya当初赶走他;而LSTM之父则怒斥Hinton不配诺奖。

该研究主要探讨了大语言模型的全局剪枝方法,旨在提高预训练语言模型的效率。该成果的发表为大模型的剪枝与优化研究提供了新的视角,并在相关领域具有重要的应用潜力。

随着诺贝尔物理学奖颁给了「机器学习之父」Geoffrey Hinton,另一个借鉴物理学概念的模型架构也横空出世——微软清华团队的最新架构Differential Transformer,从注意力模块入手,实现了Transformer的核心能力提升。

随着大规模语言模型的快速发展,如 GPT、Claude 等,LLM 通过预训练海量的文本数据展现了惊人的语言生成能力。然而,即便如此,LLM 仍然存在生成不当或偏离预期的结果。这种现象在推理过程中尤为突出,常常导致不准确、不符合语境或不合伦理的回答。为了解决这一问题,学术界和工业界提出了一系列对齐(Alignment)技术,旨在优化模型的输出,使其更加符合人类的价值观和期望。

Transformer 的强大实力已经在诸多大型语言模型(LLM)上得到了证明,但该架构远非完美,也有很多研究者致力于改进这一架构,比如机器之心曾报道过的 Reformer 和 Infini-Transformer。

在人工智能领域掀起巨浪的 OpenAI o1 模型发布三周后,一支由高校年轻研究者组成的团队今天发布了题为 "o1 Replication Journey: A Strategic Progress Report (o1 探索之旅:战略进展报告)" 的研究进展报告。

众所周知,人类的本质是复读机。 我们遵循复读机的自我修养:敲黑板,划重点,重要的事情说三遍。 but,事实上同样的方法对付AI也有奇效!
会议组织者都是 NLP 头部科学家,在语言建模方面有着相当的成果。

Transformer计算,竟然直接优化到乘法运算了。MIT两位华人学者近期发表的一篇论文提出:Addition is All You Need,让LLM的能耗最高降低95%。

现实世界中的强化学习在应用过程中也面临着巨大的挑战,尤其是如何保证系统的安全性。为了解决这一问题,安全强化学习(Safe Reinforcement Learning, Safe RL)应运而生,成为当前学术界和工业界关注的焦点。

Mila、谷歌DeepMind和微软的研究团队近期联合发布了一项重要研究成果,揭示了LLM在推理能力上存在的显著差异。这项研究不仅挑战了我们对LLM推理能力的认知,也提醒我们在开发AI应用时,LLM的选择上要多考虑一些因素,尤其是需要注意Prompt的敏感性和一致性。

Goodfire于2024年在旧金山成立,研发用于提高生成式AI模型内部运作可观察性的开发工具,希望提高AI系统的透明度和可靠性,帮助开发者更好地理解和控制AI模型。

来自中国科学技术大学数据空间研究中心、香港科技大学、香港理工大学以及奥胡斯大学的研究者们提出一种新的场景生成方法 DreamScene,只需要提供场景的文本就可以生成高质量,视角一致和可编辑的 3D 场景。

chatGPT,AI,AI 3D,CE3D,扩散模型
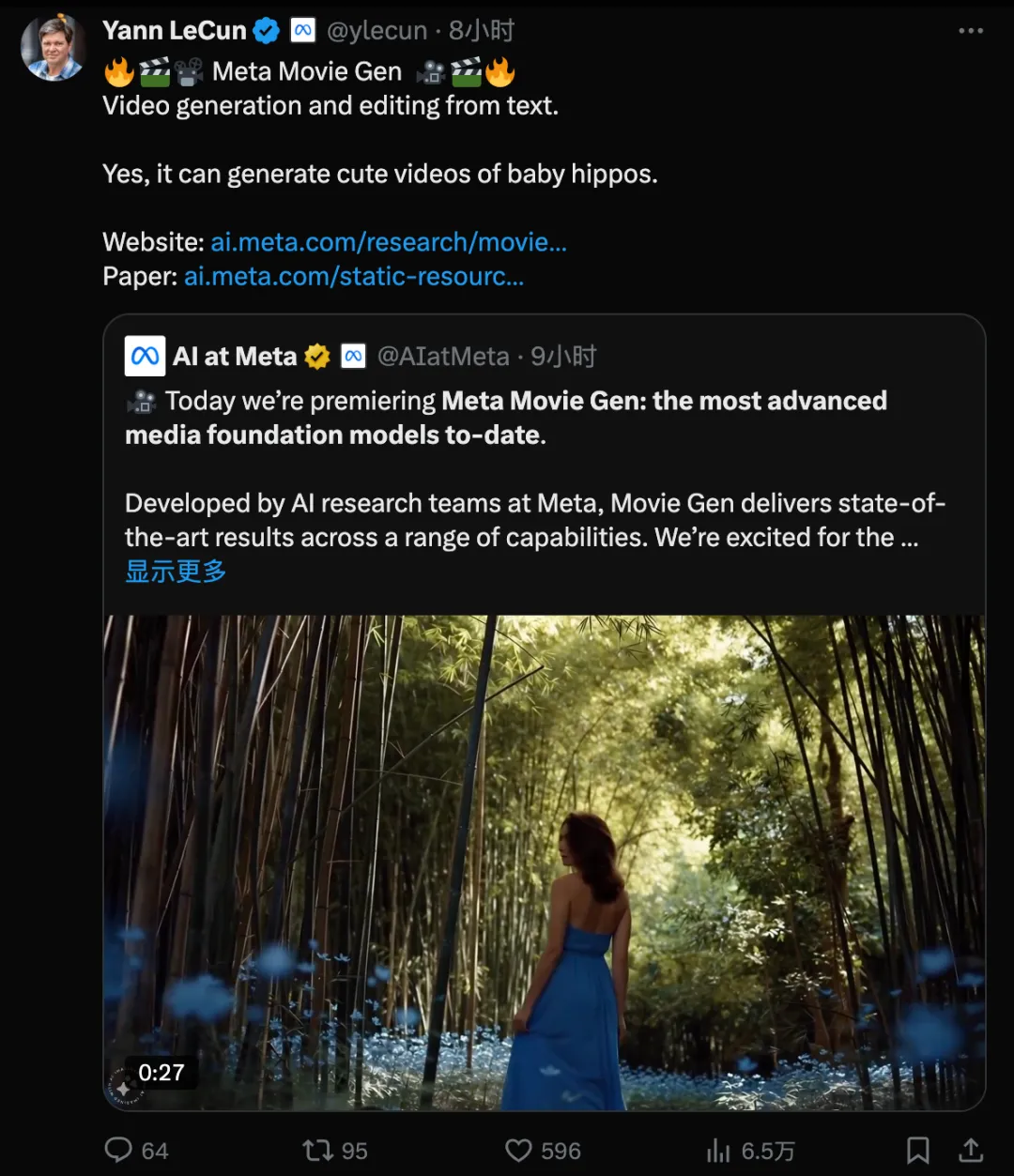
视频生成领域真是越来越卷且越来越迈向实用性!

OpenAI的o1模型在通用语言任务上展现了显著的性能,最新测评展现了o1模型在医学领域的表现,主要关注理解、推理和多语言能力,结果大幅超越以往的模型!