

DeepSeek新作Janus:解耦视觉编码,引领多模态理解与生成统一新范式
DeepSeek新作Janus:解耦视觉编码,引领多模态理解与生成统一新范式我们提出了 Janus,一种基于自回归的多模态理解与生成统一模型。
来自主题: AI技术研报
4718 点击 2024-10-22 14:35
我们提出了 Janus,一种基于自回归的多模态理解与生成统一模型。

最近,DeepMind 今年 2 月份的一篇论文在社交媒体上掀起了一些波澜。

最近,来自德国奥尔登堡大学计算智能实验室的研究人员Oliver Kramer和Jill Baumann提出了一种创新的方法——认知提示(Cognitive Prompting),通过模拟人类认知过程来提升LLM的问题解决能力。这项研究将在ICLR 2025会议上发表,本文将为各位读者朋友详细解读这一突破性的技术。
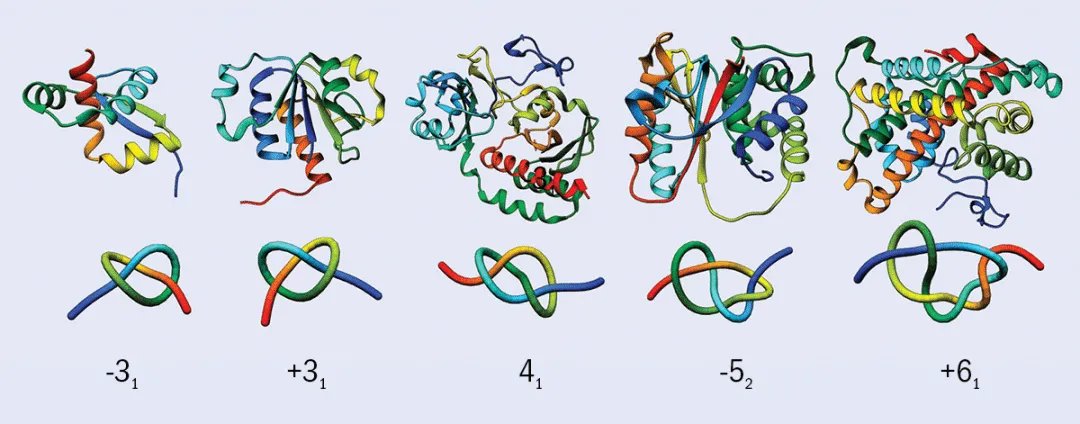
纽结理论长期困扰着数学家,但随着人工智能的进步,有研究者在生物学中找到了突破口,因为纽结结构存在于许多重要的生物分子中,例如蛋白质、DNA等。对于难以识别归类的复杂纽结结构,AI给出了令人惊讶的结果。

近日,来自乔治梅森大学和腾讯AI实验室的研究团队在这一领域取得了重大突破。他们提出了一种名为DOTS(Dynamic Optimal Trajectory Search)的创新方法,通过最佳推理轨迹搜索,显著提升LLMs的动态推理能力。

多年来,浙江大学周晟老师团队与阿里安全交互内容安全团队持续开展产学研合作。近日,双⽅针对标签噪声下图神经⽹络的联合研究成果《NoisyGL:标签噪声下图神经网络的综合基准》被 NeurIPS Datasets and Benchmarks Track 2024 收录。本次 NeurIPS D&B Track 共收到 1820 篇投稿,录⽤率为 25.3%。

视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。
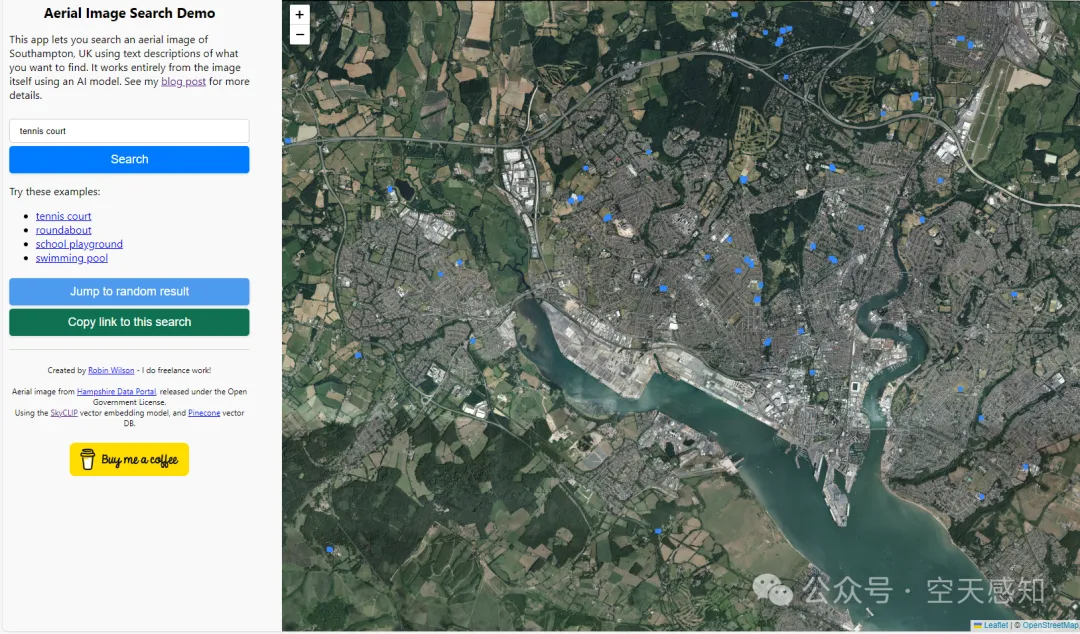
近期在LLM方面,AI搜索热度居高不下,遥感业务也能做AI搜索。

比传统MoE推理速度更快、性能更高的新一代架构,来了! 这个通用架构叫做MoE++,由颜水成领衔的昆仑万维2050研究院与北大袁粒团队联合提出。

内存占用小,训练表现也要好……大模型训练成功实现二者兼得。 来自北理、北大和港中文MMLab的研究团队提出了一种满足低秩约束的大模型全秩训练框架——Fira,成功打破了传统低秩方法中内存占用与训练表现的“非此即彼”僵局。
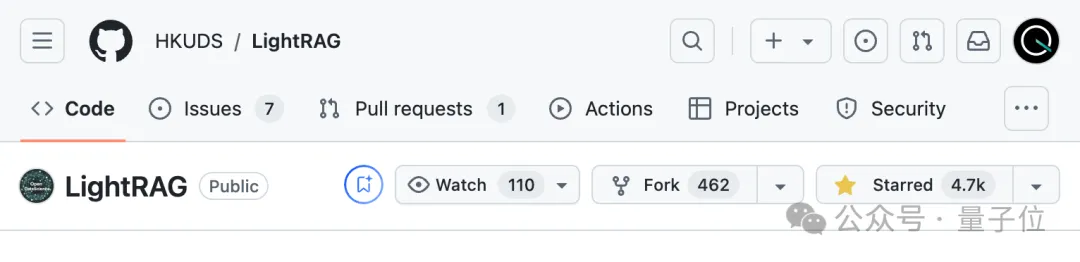
简单高效的大模型检索增强系统LightRAG,香港大学黄超团队最新研究成果。 开源两周时间在GitHub上获得将近5k标星,并登上趋势榜。

能拿下数学奥赛银牌水平的AI是否达到了12岁陶哲轩的水平? 陶神本人的回答来了

Indeed Hiring Lab 评估了OpenAI开发的生成式AI模型GPT-4在超过2800项工作技能中的表现。


近日,来自谷歌和苹果的研究表明:AI模型掌握的知识比表现出来的要多得多!这些真实性信息集中在特定的token中,利用这一属性可以显著提高检测LLM错误输出的能力。

LLM训练速度还可以再飙升20倍!英伟达团队祭出全新架构归一化Transformer(nGPT),上下文越长,训练速度越快,还能维持原有精度。

大型语言模型(LLMs)虽然在适应新任务方面取得了长足进步,但它们仍面临着巨大的计算资源消耗,尤其在复杂领域的表现往往不尽如人意。

现在正是「文本生视频」赛道百花齐放的时代,而且其应用场景非常多,比如生成创意视频内容、创建游戏场景、制作动画和电影。

牛顿没解决的问题,AI给你解决了? AI的推理能力一直是研究的焦点。作为最纯粹、要求最高的推理形式之一,能否解决高级的数学问题,无疑是衡量语言模型推理水平的一把尺。

多模态生成新突破,字节&华师团队打造TextHarmony,在单一模型架构中实现模态生成的统一,并入选NeurIPS 2024。

机器人控制和自动驾驶的离线数据损坏问题有解了! 中科大王杰教授团队 (MIRA Lab) 提出了一种变分贝叶斯推断方法,有效地提升了智能决策模型的鲁棒性。
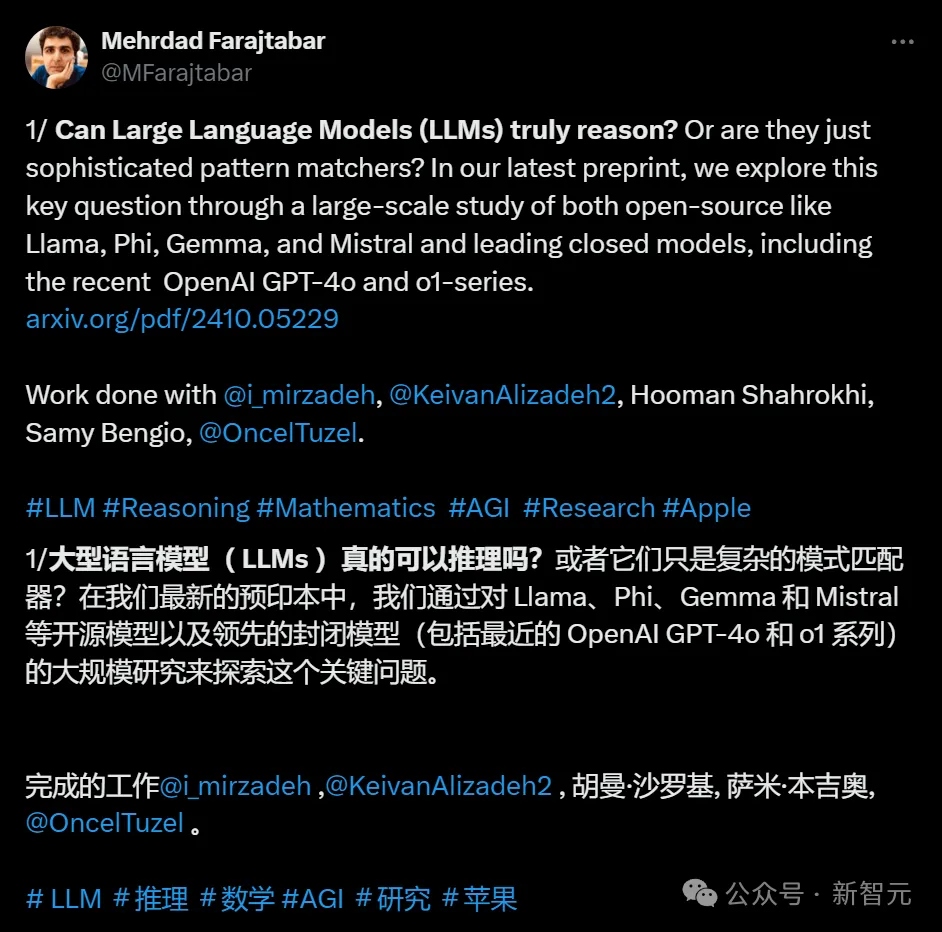
苹果研究者发现:无论是OpenAI GPT-4o和o1,还是Llama、Phi、Gemma和Mistral等开源模型,都未被发现任何形式推理的证据,而更像是复杂的模式匹配器。无独有偶,一项多位数乘法的研究也被抛出来,越来越多的证据证实:LLM不会推理!

最近,大模型训练遭恶意攻击事件已经刷屏了。就在刚刚,Anthropic也发布了一篇论文,探讨了前沿模型的巨大破坏力,他们发现:模型遇到危险任务时会隐藏真实能力,还会在代码库中巧妙地插入bug,躲过LLM和人类「检查官」的追踪!

7 年前,谷歌在论文《Attention is All You Need》中提出了 Transformer。就在 Transformer 提出的第二年,谷歌又发布了 Universal Transformer(UT)。它的核心特征是通过跨层共享参数来实现深度循环,从而重新引入了 RNN 具有的循环表达能力。

又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!

今天,Meta 分享了一系列研究和模型,这些研究和模型支撑 Meta 实现高级机器智能(AMI)目标,同时也致力于开放科学和可复现性。

在强化学习中,当智能体的奖励机制与设计者的意图不一致时,可能会导致不理想的行为,而KL正则化作为一种常用的解决方案,通过限制智能体的行为来防止这种情况,但智能体在某些情况下仍可能表现出意料之外的行为;为了提高智能体的可靠性,研究人员提出了新的理论方案,通过改变指导原则来增强智能体在未知情况下的谨慎性。

微软发布了 Copilot,Apple 将 Apple Intelligence 接入了 OpenAI 以增强 Siri。

大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。
最新消息,DenseNet 作者之一刘壮将于 2025 年 9 月加盟普林斯顿大学,担任计算机科学系助理教授一职。