

大模型生成RPG游戏,情节角色全自定义!谷歌出品,一作上海交大校友
大模型生成RPG游戏,情节角色全自定义!谷歌出品,一作上海交大校友现在,大模型能生成RPG角色扮演游戏了。
来自主题: AI技术研报
10727 点击 2024-10-26 21:37
现在,大模型能生成RPG角色扮演游戏了。
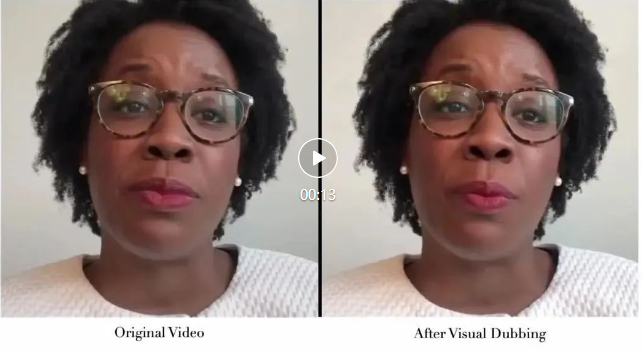
在 AIGC 的热潮下,基于语音驱动的视频口型编辑技术成为了视频内容个性化与智能化的重要手段之一。

最近这几天,让大模型具备控制计算机(包括电脑和手机)的相关研究和应用如雨后春笋般不断涌现。

如果你是一位开放世界或角色扮演游戏的玩家,你一定梦想过一款无限自由的游戏。没有空气墙,没有剧情杀,也没有任何交互限制。

今年的诺奖将物理和化学两个领域的奖项都颁给了AI成果,这究竟代表着怎样的含义,又会产生怎样的影响?Demis Hassabis在本次专访中提出了自己的见解。

OpenAI 最近发布的 o1 模型在数学、代码生成和长程规划等复杂任务上取得了突破性进展,据业内人士分析披露,其关键技术在于基于强化学习的搜索与学习机制。通过迭代式的自举过程,o1 基于现有大语言模型的强大推理能力,生成合理的推理过程,并将这些推理融入到其强化学习训练过程中。
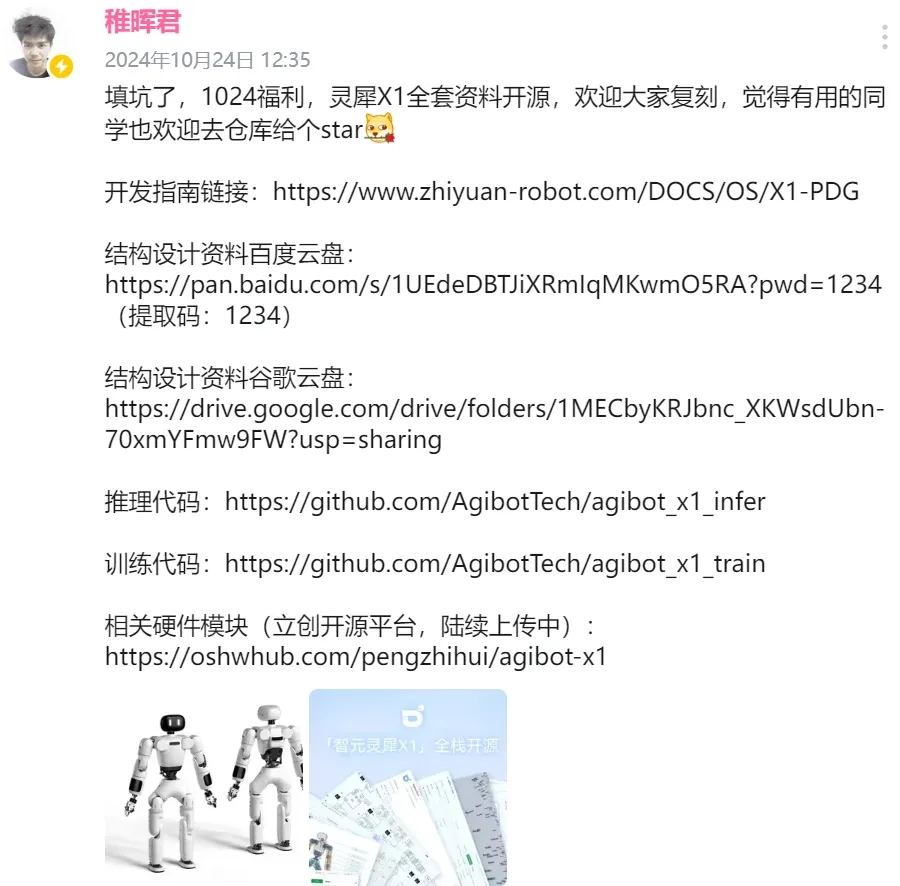
稚晖君表示,这是 1024 的福利。

这两天,Claude 3.5 Sonnet升级版刷爆了朋友圈,满屏都是:它能像人一样操作电脑。 大语言模型(Large Language Model,LLM)能够像人一样操作电脑这件事,看起来蛮炸裂的,但在AI Agent圈子里早已经见多不怪了。
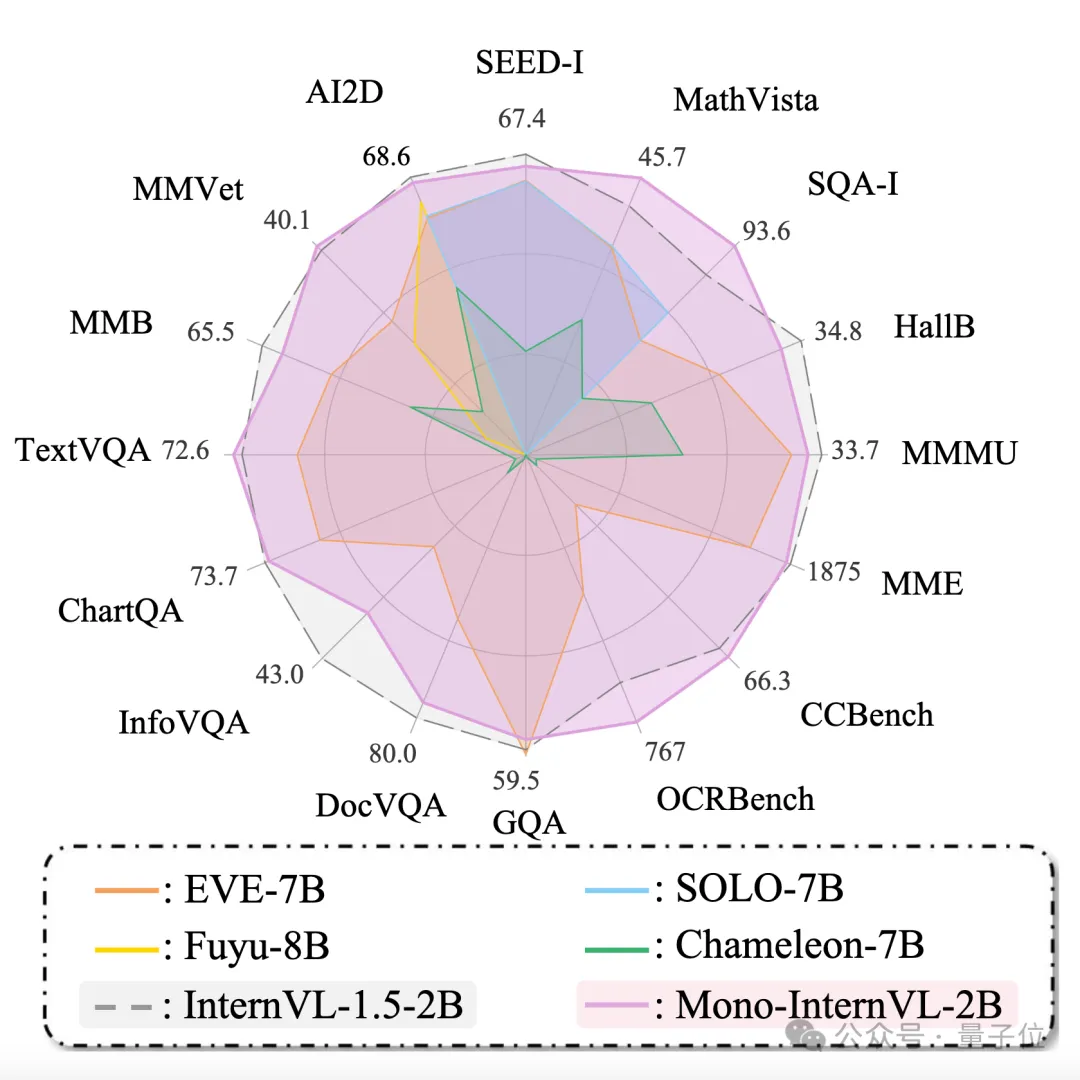
原生多模态大模型性能瓶颈,迎来新突破! 上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。 与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。

近日,深度学习三巨头之一的Yoshua Bengio,带领团队推出了全新的RNN架构,以大道至简的思想与Transformer一较高下。
「这才是开放研究该有的样子。」 经常刷 arXiv 的同学,你有没有发现页面上多了个新功能?这个新功能(图中的「Hugging Face」按钮)隐藏在「Code, Data, Media」选项卡下,选中之后就可以直达相关的 Hugging Face 论文、模型和数据集。
Zamba2-7B是一款小型语言模型,在保持输出质量的同时,通过创新架构实现了比同类模型更快的推理速度和更低的内存占用,在图像描述等任务上表现出色,能在各种边缘设备和消费级GPU上高效运行。

北京大学的研究人员开发了一种新型多模态框架FakeShield,能够检测图像伪造、定位篡改区域,并提供基于像素和图像语义错误的合理解释,可以提高图像伪造检测的可解释性和泛化能力。

西安电子科大、上海AI Lab等提出多模态融合检测算法E2E-MFD,将图像融合和目标检测整合到一个单阶段、端到端框架中,简化训练的同时,提升目标解析性能。 相关论文已入选顶会NeurlPS 2024 Oral,代码、模型均已开源。

家人们,OpenAI 又上新了!推出了全新的生成式模型sCM(Simplifying Continuous-Time Consistency Models),支持视频、图像、三维模型和音频的生成。

工具调用是 AI 智能体的关键功能之一,AI 智能体根据场景变化动态地选择和调用合适的工具,从而实现对复杂任务的自动化处理。例如,在智能办公场景中,模型可同时调用文档编辑工具、数据处理工具和通信工具,完成文档撰写、数据统计和信息沟通等多项任务。

现如今,大型语言模型(LLM)生成的内容已经充斥了整个互联网,并且这些模型还能模仿各种类似真人的语气和行文风格,让人难以分辨眼前的文本究竟来自人类还是 AI。

为应对公司在大规模文本、图像等非结构化数据处理上的业务增长需求,笔者着手调研当前流行的开源向量数据库。主要针对查询速度、并发度和召回率这几大核心维度进行深入分析,以确保选定的数据库方案能够在实际业务场景中高效应对大规模数据检索和高并发需求。通过全面对比不同数据库的表现,得出可靠的调研结论。

TL;DR:DuoAttention 通过将大语言模型的注意力头分为检索头(Retrieval Heads,需要完整 KV 缓存)和流式头(Streaming Heads,只需固定量 KV 缓存),大幅提升了长上下文推理的效率,显著减少内存消耗、同时提高解码(Decoding)和预填充(Pre-filling)速度,同时在长短上下文任务中保持了准确率。

在人形机器人领域,有一个非常值钱的问题:既然人形机器人的样子与人类类似,那么它们能使用网络视频等数据进行学习和训练吗?

现有的大模型主要依赖固定的参数和数据来存储知识,一旦训练完成,修改和更新特定知识的代价极大,常常因知识谬误导致模型输出不准确或引发「幻觉」现象。因此,如何对大模型的知识记忆进行精确控制和编辑,成为当前研究的前沿热点。

让大模型依靠群体的智能。

开源数字人实时对话Demo来了~
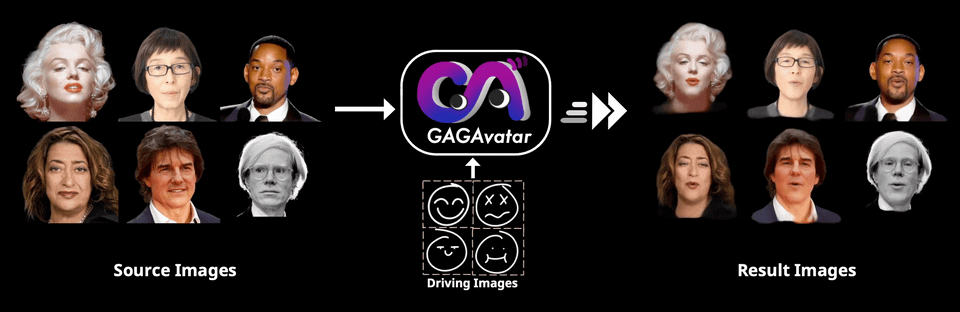
GAGAvatar的出现正是为了解决这一瓶颈,通过一次前向传播就能生成3D高斯参数,实现高效的渲染与动画驱动。

Time-MoE采用了创新的混合专家架构,能以较低的计算成本实现高精度预测。研发团队还发布了Time-300B数据集,为时序分析提供了丰富的训练资源,为各行各业的时间序列预测任务带来了新的解决方案。

在NLP领域,研究者们已经充分认识并认可了表征学习的重要性,那么视觉领域的生成模型呢?最近,谢赛宁团队发表的一篇研究就拿出了非常有力的证据:Representation matters!

RAG通过纳入外部文档可以辅助LLM进行更复杂的推理,降低问题求解所需的推理深度,但由于文档噪声的存在,其提升效果可能会受限。中国人民大学的研究表明,尽管RAG可以提升LLM的推理能力,但这种提升作用并不是无限的,并且会受到文档中噪声信息的影响。通过DPrompt tuning的方法,可以在一定程度上提升LLM在面对噪声时的性能。

Claude 3.5深夜迎来重磅升级! 不出所料,Anthropic AI这周终于有了大动作——首发Claude 3.5 Haiku,全新升级版Claude 3.5 Sonnet也来了。

让 AI 与人类价值观对齐一直都是 AI 领域的一大重要且热门的研究课题,甚至很可能是 OpenAI 高层分裂的一大重要原因 ——CEO 萨姆・奥特曼似乎更倾向于更快实现 AI 商业化,而以伊尔亚・苏茨克维(Ilya Sutskever)为代表的一些研究者则更倾向于先保证 AI 安全。

Maitrix.org 是由 UC San Diego, John Hopkins University, CMU, MBZUAI 等学术机构学者组成的开源组织,致力于发展大语言模型 (LLM)、世界模型 (World Model)、智能体模型 (Agent Model) 的技术以构建 AI 驱动的现实。