
视频生成Open-Sora-Plan 升级至v1.3.0,引入五大新特性
视频生成Open-Sora-Plan 升级至v1.3.0,引入五大新特性Open-Sora-Plan迎来又一次升级。新的Open-Sora-Plan v1.3.0版本引入了五个新特性:性能更强、成本更低的WFVAE;Prompt refiner;高质量数据清洗策略;全新稀疏注意力的DiT,以及动态分辨率、动态时长的支持。
来自主题: AI技术研报
12839 点击 2024-10-30 10:55
Open-Sora-Plan迎来又一次升级。新的Open-Sora-Plan v1.3.0版本引入了五个新特性:性能更强、成本更低的WFVAE;Prompt refiner;高质量数据清洗策略;全新稀疏注意力的DiT,以及动态分辨率、动态时长的支持。

让大模型能快速、准确、高效地吸收新知识!

TimeMixer++是一个创新的时间序列分析模型,通过多尺度和多分辨率的方法在多个任务上超越了现有模型,展示了时间序列分析的新视角,在预测和分类等任务带来了更高的准确性和灵活性。

Janus 是 DeepSeek AI 开发的一个先进的多模态理解和生成框架,它通过创新性地解耦视觉编码路径来应对多模态理解和生成任务之间的需求冲突。

LLM统一了语言生成任务,图像生成可以吗?就在刚刚,智源推出了全新扩散模型架构OmniGen,单个模型就能生成图像,彻底告别繁琐工作流!

PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)是一项创新的多模态大型语言模型(MLLM),由商汤科技联合来自香港中文大学、港大和清华大学的研究人员共同开发。它通过统一的框架处理和生成多粒度的视觉表示,巧妙地平衡了视觉生成任务中的多样性与可控性。

随着2024年生成式AI大爆发,推理端成本呈指数级激增,推动了泛智能硬件端持续增长,“端云混合AI部署”模式正走向主流,端侧智能则加速了终端“换机热潮”:AI PC、AI手机、AIoT设备、智能座舱。
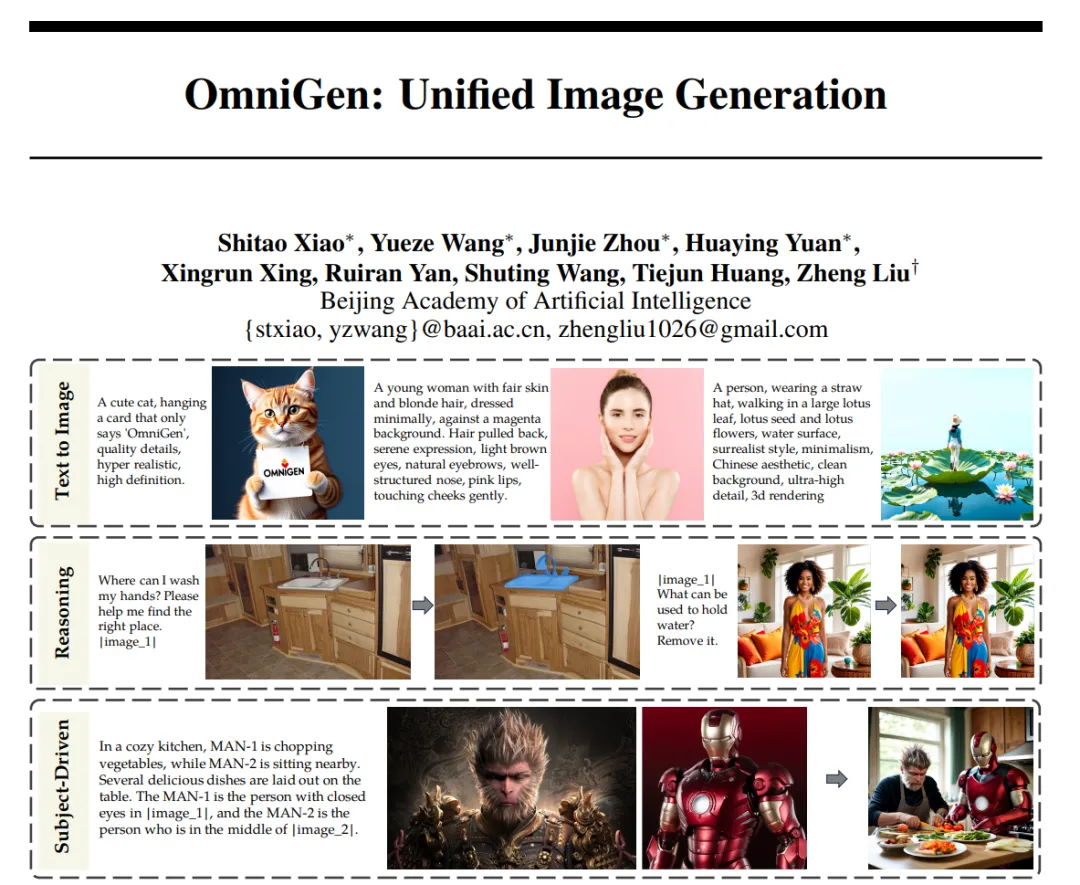
大型语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。近日,智源推出了新的扩散模型架构 OmniGen,一种新的用于统一图像生成的多模态模型。

在当前内卷严重的实时目标检测 (Real-time Object Detection) 领域,性能与效率始终是难以平衡的核心问题。绝大多数现有的 SOTA 方法仅依赖于更先进的模块替换或训练策略,导致性能逐渐趋于饱和。

前Neuralink总裁创立的脑机接口公司Science Corporation,正在开发一种名为「Prima」的芯片技术。初步试验结果表明,38名患者中,有81%的患者视力得到了大幅度的改善。几位知名眼科医生都直称:「这是第一个有可能成功恢复AMD患者视力的重大进展!」
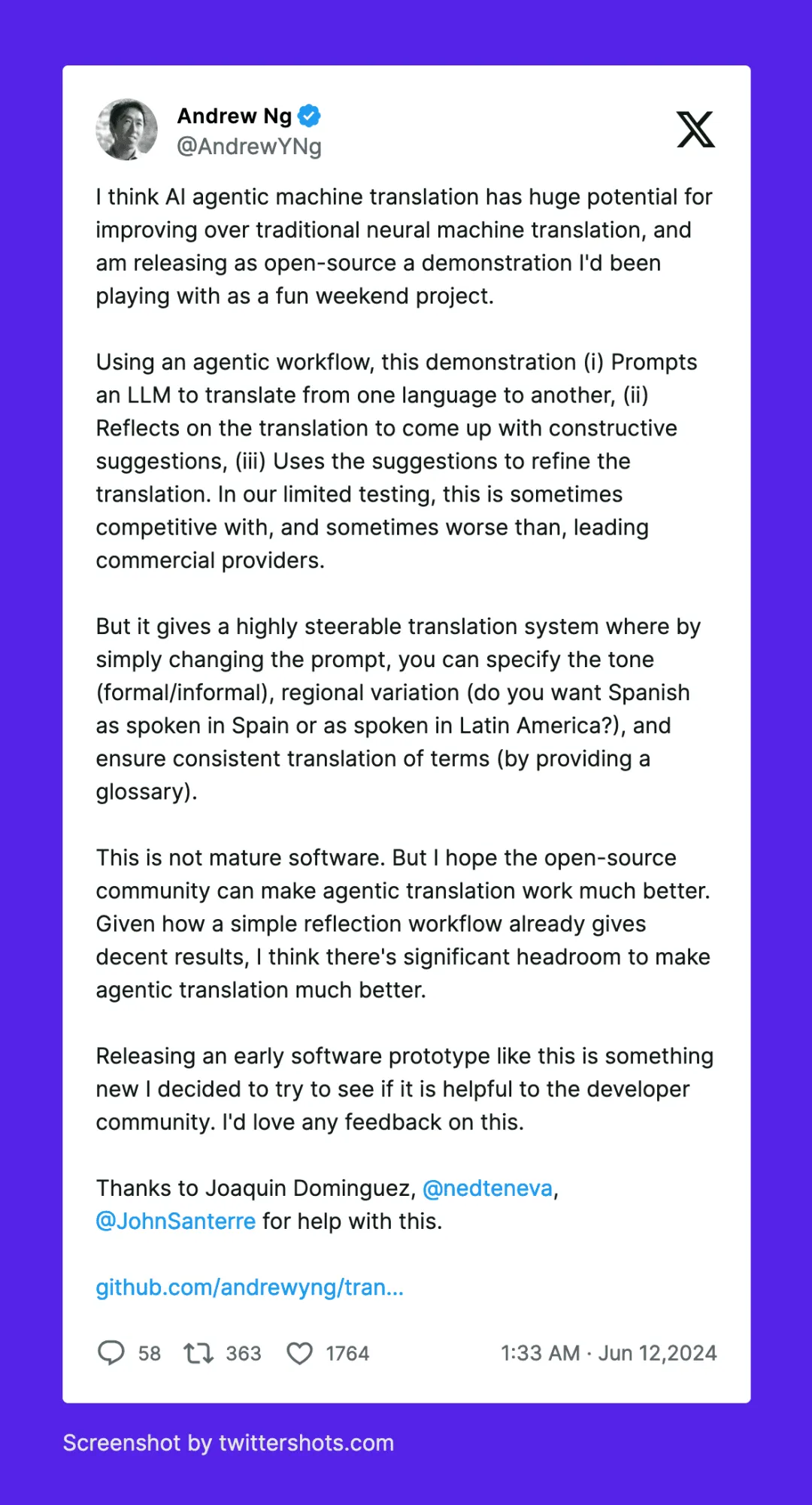
吴恩达老师提出了一种反思翻译的大语言模型 (LLM) AI 翻译工作流程

分享一篇近期由华为和阿卜杜拉国王科技大学合作完成的一项生信分析与大语言模型相结合的工作,相关成果发表在《Advanced Science》上。
TS-Reasoner是一个创新的多步推理框架,结合了大型语言模型的上下文学习和推理能力,通过程序化多步推理、模块化设计、自定义模块生成和多领域数据集评估,有效提高了复杂时间序列任务的推理能力和准确性。实验结果表明,TS-Reasoner在金融决策、能源负载预测和因果关系挖掘等多个任务上,相较于现有方法具有显著的性能优势。

长视频理解迎来新纪元!智源联手国内多所顶尖高校,推出了超长视频理解大模型Video-XL。仅用一张80G显卡处理小时级视频,未来AI看懂电影再也不是难事。
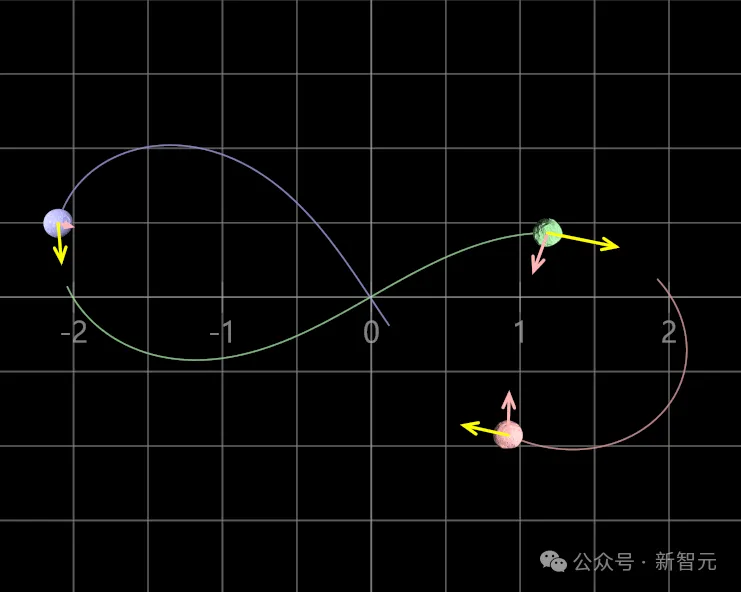
Transformer解决了三体问题?Meta研究者发现,132年前的数学难题——发现全局李雅普诺夫函数,可以被Transformer解决了。「我们不认为Transformer是在推理,它可能是出于对数学问题的深刻理解,产生了超级直觉。」AI可以搞基础数学研究了,陶哲轩预言再成真。
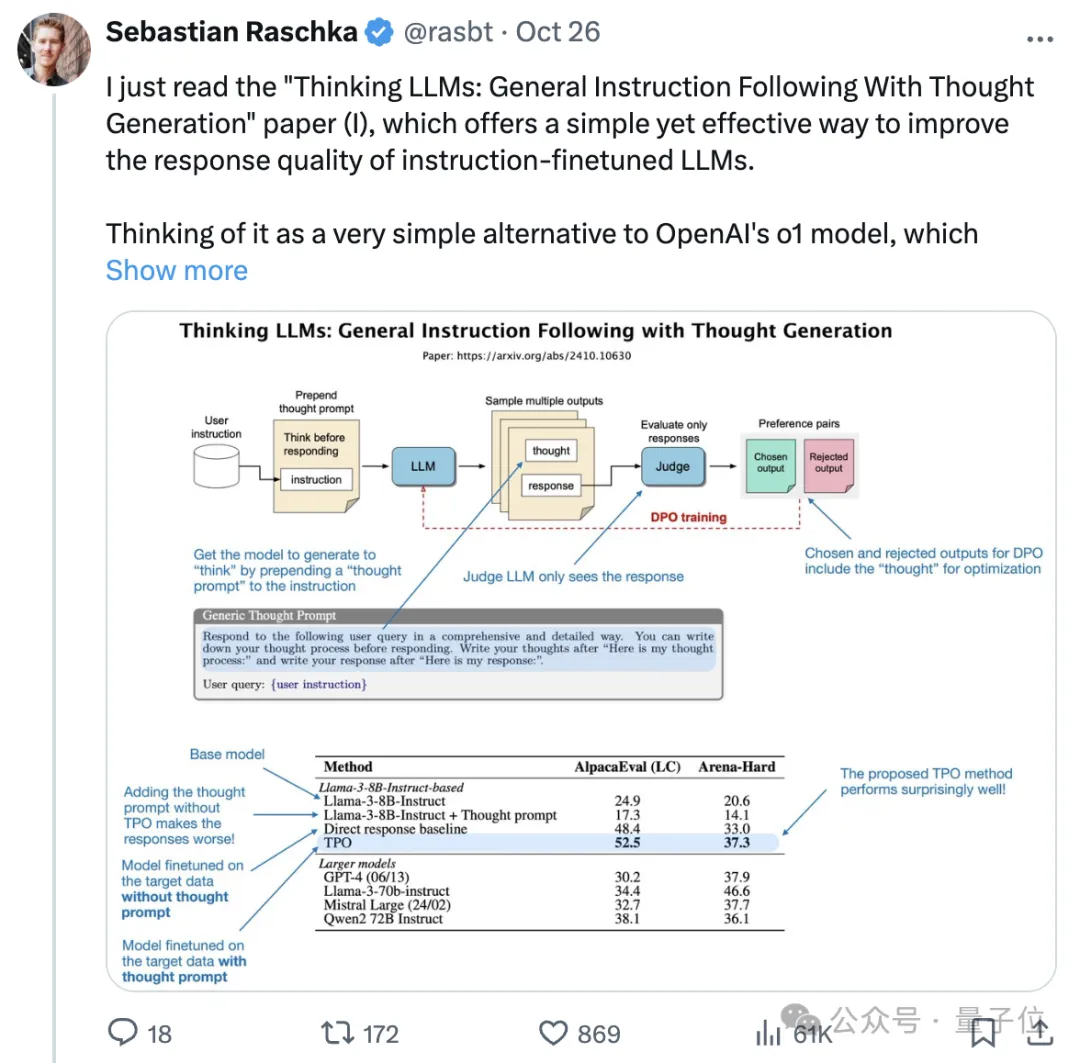
OpenAI-o1替代品来了,大模型能根据任务复杂度进行不同时间的思考。 不限于推理性的逻辑或数学任务,一般问答也能思考的那种。 最近畅销书《Python机器学习》作者Sebastian Raschka推荐了一项新研究,被网友们齐刷刷码住了。

仅需1块80G显卡,大模型理解小时级超长视频。 智源研究院联合上海交通大学、中国人民大学、北京大学和北京邮电大学等多所高校带来最新成果超长视频理解大模型Video-XL。

近日,天桥脑科学研究院和普林斯顿大学等多所研究机构发布了一篇研究论文,详细阐述了长期记忆对 AI 自我进化的重要性,并且他们还提出了自己的实现框架 —— 基于多智能体的 Omne,其在 GAIA 基准上取得了第一名的成绩。

近日,极佳科技联合中国科学院自动化研究所、理想汽车、北京大学、慕尼黑工业大学等单位提出DriveDreamer4D,是首个利用世界模型增强 4D 驾驶场景重建效果的工作。

视频内容的快速增长给视频检索技术,特别是细粒度视频片段检索(VCMR),带来了巨大挑战。VCMR 要求系统根据文本查询从视频库中精准定位视频中的匹配片段,需具备跨模态理解和细粒度视频理解能力。

近日,智谱在公众号陆续放出电脑版本与手机版本的AI Agent实操视频:

在人工智能技术快速发展的今天,大语言模型(LLM)已经展现出惊人的能力。然而,让这些模型生成规范的结构化输出仍然是一个难以攻克的技术难题。不论是在开发自动化工具、构建特定领域的解决方案,还是在进行开发工具集成时,都迫切需要LLM能够产生格式严格、内容可靠的输出。

扩散模型(Diffusion Models, DMs)已经成为文本到图像生成领域的核心技术之一。凭借其卓越的性能,这些模型可以生成高质量的图像,广泛应用于各类创作场景,如艺术设计、广告生成等。
今年 4 月,斯坦福大学推出了一款利用大语言模型(LLM)辅助编写类维基百科文章的神器。它就是开源的 STORM,可以在三分钟左右将你输入的主题转换为长篇文章或者研究论文,并能够以 PDF 格式直接下载。

AI评估AI可靠吗?来自Meta、KAUST团队的最新研究中,提出了Agent-as-a-Judge框架,证实了智能体系统能够以类人的方式评估。它不仅减少97%成本和时间,还提供丰富的中间反馈。

科幻中的贾维斯,已经离我们不远了。Claude 3.5接管人类电脑掀起了人机交互全新范式,爆料称谷歌同类Project Jarvis预计年底亮相。AI操控电脑已成为微软、苹果等巨头,下一个发力的战场。

时隔近70年,那个用来解决最短路径问题的经典算法——Dijkstra,现在有了新突破:被证明具有普遍最优性(Universal Optimality)。

斯坦福吴佳俊团队与MIT携手打造的最新研究成果,让我们离实时生成开放世界游戏又近了一大步。

在这个信息爆炸的时代,如何让AI生成的视频更具创意,又符合特定需求?

现在,大模型能生成RPG角色扮演游戏了。