

MPDS:提升电影海报生成效率的新型数据集
MPDS:提升电影海报生成效率的新型数据集MPDS(Movie Posters Dataset)是一个创新的电影海报数据集,旨在解决现有图像生成模型在制作电影海报时面临的挑战。
来自主题: AI技术研报
11606 点击 2024-11-02 17:21
MPDS(Movie Posters Dataset)是一个创新的电影海报数据集,旨在解决现有图像生成模型在制作电影海报时面临的挑战。

Allegro 是一款先进的商业级视频生成模型,由Rhymes AI团队开发。它通过将描述性文本转换为动态视觉内容,为用户提供了一种灵活且可控的视频创作方法。

随着扩散生成模型的发展,人工智能步入了属于 AIGC 的新纪元。扩散生成模型可以对初始高斯噪声进行逐步去噪而得到高质量的采样。当前,许多应用都涉及扩散模型的反演,即找到一个生成样本对应的初始噪声。当前的采样器不能兼顾反演的准确性和采样的质量。

多图像场景也能用DPO方法来对齐了! 由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。 这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。
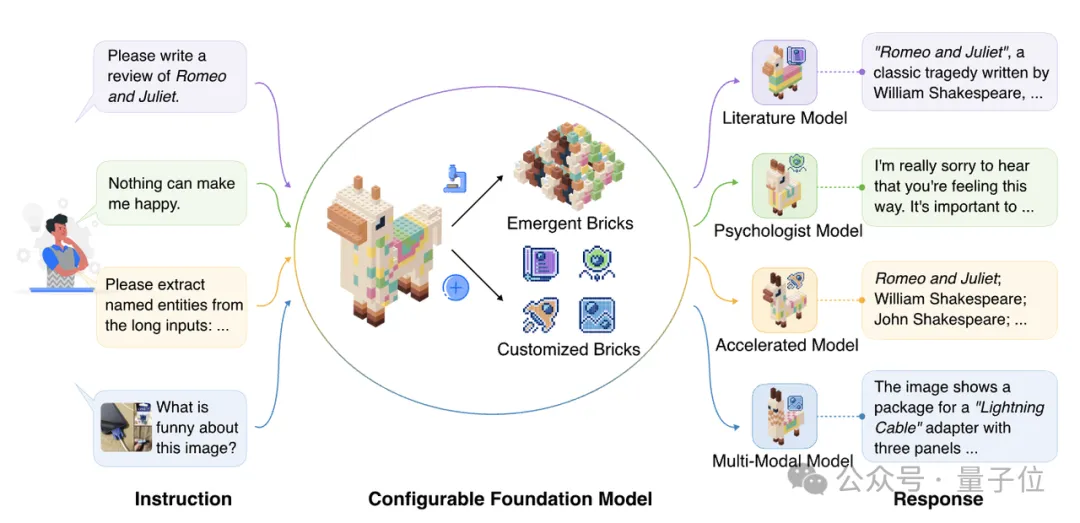
探索更高效的模型架构, MoE是最具代表性的方向之一。 MoE架构的主要优势是利用稀疏激活的性质,将大模型拆解成若干功能模块,每次计算仅激活其中一小部分,而保持其余模块不被使用,从而大大降低了模型的计算与学习成本,能够在同等计算量的情况下产生性能优势。

本文介绍了一种自动化故事可视化系统,可以生成多样化、高质量、一致性强的故事图像,且需要最少的人工干预。

CGPO框架通过混合评审机制和约束优化器,有效解决了RLHF在多任务学习中的奖励欺骗和多目标优化问题,显著提升了语言模型在多任务环境中的表现。CGPO的设计为未来多任务学习提供了新的优化路径,有望进一步提升大型语言模型的效能和稳定性。

强化学习(RL)对大模型复杂推理能力提升有关键作用,然而,RL 复杂的计算流程以及现有系统局限性,也给训练和部署带来了挑战。

对于人类而言,一旦掌握了 “打开瓶盖” 的动作,面对 “拧紧螺丝” 这样的任务通常也能游刃有余,因为这两者依赖于相似的手部动作。然而,对于机器人来说,即使是这样看似简单的任务转换依然充满挑战。例如,换成另一种类型的瓶盖,机器人可能无法成功打开。这表明,目前的机器人方法尚未充分让模型学习到任务的内在执行逻辑,而只是单纯的依赖于数据拟合。

在奖励中减去平均奖励

Unbounded 是由 Google 研发的一个创新的角色模拟生成性无限游戏,它通过采用最新的生成模型技术,突破了传统视频游戏的局限。

Ferret-UI 2 是苹果研究团队最新发表的一款先进的多模态大型语言模型(MLLM),旨在实现跨多个平台的通用用户界面(UI)理解。

Agent-to-Sim (ATS) 是一个创新的三维模拟系统,能够从日常视频集合中学习三维代理的交互行为模型,由 Meta Codec Avatar 实验室主导研发。

OmniParser 是由微软研究院提出的一个创新性工具,旨在通过解析用户界面截图来增强基于视觉的图形用户界面(GUI)代理的性能。

来自华东师范大学、南洋理工和中科院等高校的联合研究团队提出了一种新颖的人工智能教育框架“场景-对象-评估”(SOE),旨在利用大型语言模型(LLMs)构建能够模拟人类学生行为和个体差异的虚拟学生代理(LVSA)。

一个简单但具有挑战性的基准

近年来,大语言模型(Large Language Models, LLMs)的研究取得了重大进展,并对各个领域产生了深远影响。然而,LLMs的卓越性能来源于海量数据的大规模训练,这导致LLMs的训练成本明显高于传统模型。

DeepMind 公布其正在开发一套创新的音频生成技术细节,也就是NotebookLM背后使用的语音技术。使 AI 能够生成更加自然的对话和高质量的音频。这些技术不仅提升了语音助手的交互性,还帮助多种应用在语音合成和对话生成上取得更大进展。

自去年底以来,时序预测领域正在经历重大转型,从传统的「单一数据集训练单一模型」的模式逐步转向「通用预测基础模型」。

个性化精品数字人(Personalized Talking Face Generation)强调合成的数字人视频在感官上与真人具有极高的相似性(不管是说话人的外表还是神态)。

大模型固然性能强大,但限制也颇多。如果想在端侧塞进 405B 这种级别的大模型,那真是小庙供不起大菩萨。近段时间,小模型正在逐渐赢得人们更多关注。这一趋势不仅出现在语言模型领域,也出现在了机器人领域。

清华大学推出的SonicSim平台和SonicSet数据集针对动态声源的语音处理研究提供了强有力的工具和数据支持,有效降低了数据采集成本,实验证明这些工具能有效提升模型在真实环境中的性能。
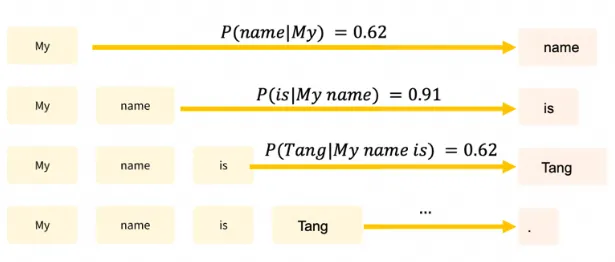
文章详细讨论了如何确保大型语言模型(LLMs)输出结构化的JSON格式,这对于提高数据处理的自动化程度和系统的互操作性至关重要。

在当前大语言模型(LLM)蓬勃发展的环境下,Prompt工程师们面临着一个两难困境:要么使用像LangChain这样功能强大但学习曲线陡峭的框架,要么选择自动化程度更高DSPy但牺牲了对提示词精确控制的工具。IBM研究院和UC Davis大学最近推出的PDL(Prompt Declaration Language,提示词声明语言)或许打破了这个困境,让AI开发者能真正拿回Prompt的控制权。

这两天Github上有一个项目火了。可用于生产环境GraphRAG的开源UI项目kotaemon,更新不到两天后已经有6.6KStar,昨日新增1.3KStar已位居Github Trending榜首。周末抽空部署了一下,还挺简单,推荐给大家。

Max Tegmark团队又出神作了!他们发现,LLM中居然存在人类大脑结构一样的脑叶分区,分为数学/代码、短文本、长篇科学论文等部分。这项重磅的研究揭示了:大脑构造并非人类独有,硅基生命也从属这一法则。

GPT-4o 四月发布会掀起了视频理解的热潮,而开源领军者Qwen2也对视频毫不手软,在各个视频评测基准上狠狠秀了一把肌肉。

近期,港中大(深圳)联手趣丸科技联合推出了新一代大规模声音克隆 TTS 模型 ——MaskGCT。该模型在包含 10 万小时多语言数据的 Emilia 数据集上进行训练,展现出超自然的语音克隆、风格迁移以及跨语言生成能力,同时保持了较强的稳定性。MaskGCT 已在香港中文大学(深圳)与上海人工智能实验室联合开发的开源系统 Amphion 发布。
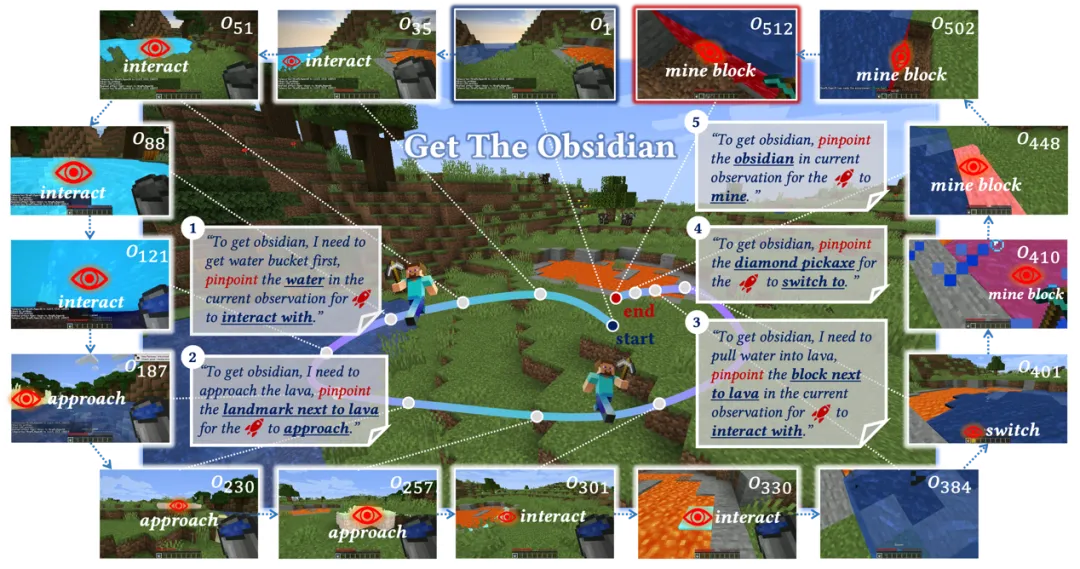
在游戏和机器人研究领域,让智能体在开放世界环境中实现有效的交互,一直是令人兴奋却困难重重的挑战。
Open-Sora-Plan迎来又一次升级。新的Open-Sora-Plan v1.3.0版本引入了五个新特性:性能更强、成本更低的WFVAE;Prompt refiner;高质量数据清洗策略;全新稀疏注意力的DiT,以及动态分辨率、动态时长的支持。