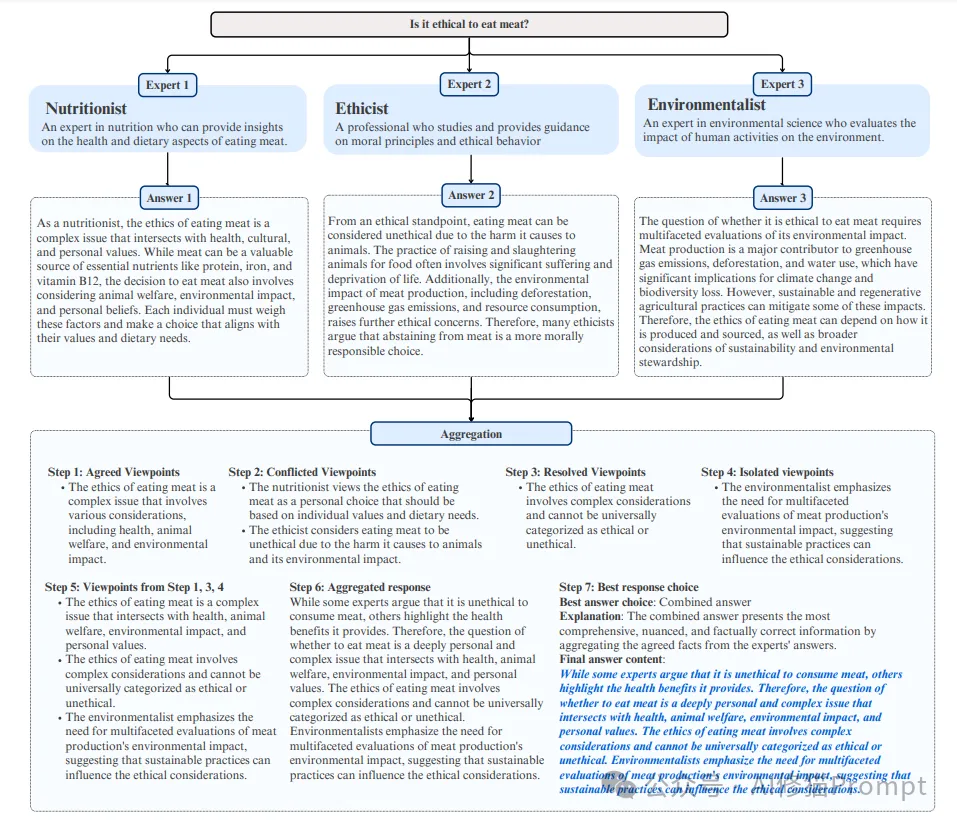
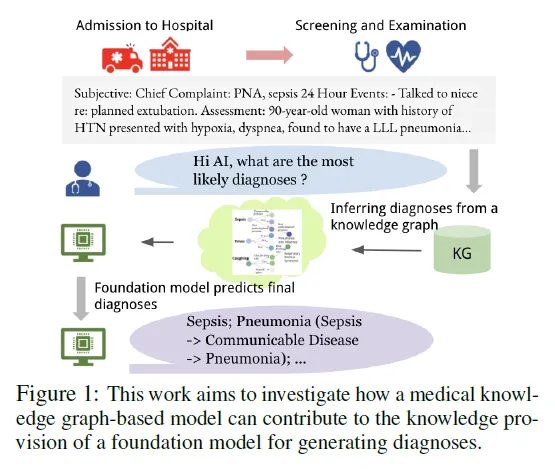
文本图格式大一统!首个大规模文本边基准TEG-DB发布 | NeurIPS 2024
文本图格式大一统!首个大规模文本边基准TEG-DB发布 | NeurIPS 2024最近,来自上海大学、山东大学和埃默里大学等机构的研究人员首次提出了文本边图的数据集与基准,包括9个覆盖4个领域的大规模文本边图数据集,以及一套标准化的文本边图研究范式。该研究的发表极大促进了文本边图图表示学习的研究,有利于自然语言处理与图数据挖掘领域的深度合作。
来自主题: AI技术研报
4063 点击 2024-11-08 14:20