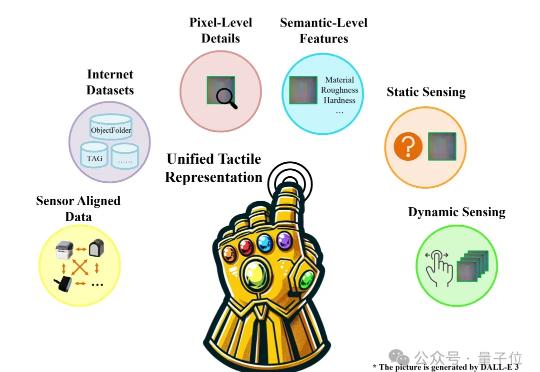
人大北邮等团队解视触觉感知统一难题,模型代码数据集全开源 | ICLR 2025
人大北邮等团队解视触觉感知统一难题,模型代码数据集全开源 | ICLR 2025机器人怎样感知世界?
来自主题: AI技术研报
10552 点击 2025-03-15 16:18
 搜索
搜索
机器人怎样感知世界?
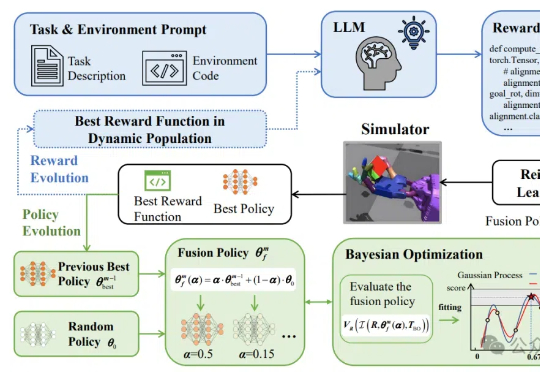
让机器人轻松学习复杂技能有新框架了!
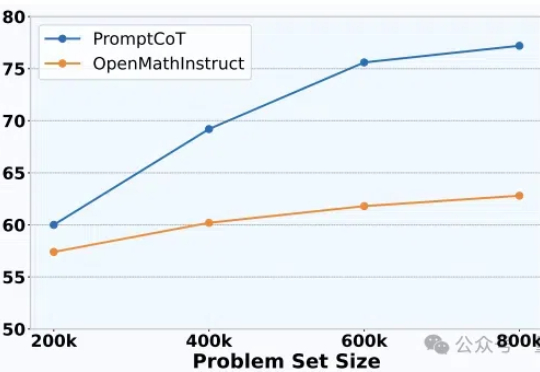
大模型架构研究进展太快,数据却快要不够用了,其中问题数据又尤其缺乏。

「压缩即智能」。这并不是一个新想法,著名 AI 研究科学家、OpenAI 与 SSI 联合创始人 Ilya Sutskever 就曾表达过类似的观点。

当前,视觉语言模型(VLMs)的能力边界不断被突破,但大多数评测基准仍聚焦于复杂知识推理或专业场景。本文提出全新视角:如果一项能力对人类而言是 “无需思考” 的本能,但对 AI 却是巨大挑战,它是否才是 VLMs 亟待突破的核心瓶颈?

今年,CVPR共有13008份有效投稿并进入评审流程,其中2878篇被录用,最终录用率为22.1%。

Transformer架构迎来历史性突破!刚刚,何恺明LeCun、清华姚班刘壮联手,用9行代码砍掉了Transformer「标配」归一化层,创造了性能不减反增的奇迹。
现在是 2025 年,新论文要以博客形式出现。
给大模型落地,加入极致的务实主义。

南洋理工大学的研究团队提出了MedRAG模型,通过结合知识图谱推理增强大语言模型(LLM)的诊断能力,显著提升智能健康助手的诊断精度和个性化建议水平。MedRAG在真实临床数据集上表现优于现有模型,准确率提升11.32%,并具备良好的泛化能力,可广泛应用于不同LLM基模型。
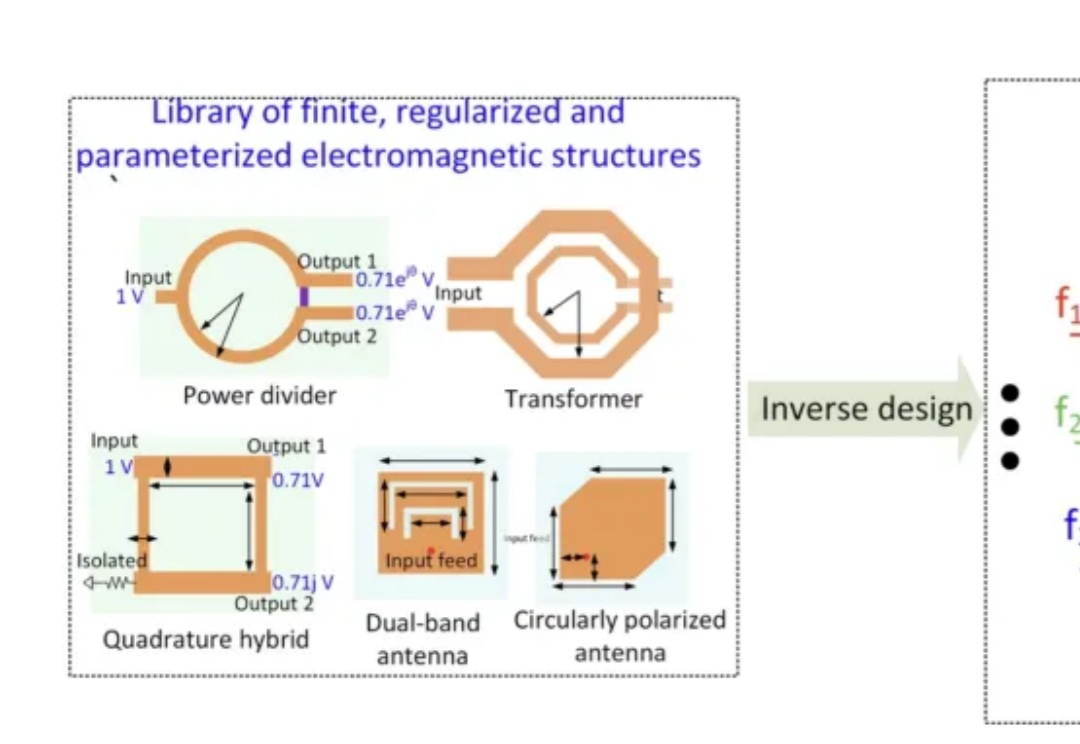
来自普林斯顿和印度技术学院的学者在《自然通讯》发表论文,他们发现,如果给定设计参数,AI可以在90nm的芯片上设计高性能集成电路。过去这是需要花费数周时间的高技能工作,但如今的AI可以在数小时内完成。

在 Sora 引爆世界模型技术革命的当下,3D 场景作为物理世界的数字基座,正成为构建动态可交互 AI 系统的关键基础设施。当前,单张图像生成三维资产的技术突破,已为三维内容生产提供了 "从想象到三维" 的原子能力。

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。

AI飞速发展的时代,AI Agent在大模型能力升级的推动下实现从任务执行者(copilot)向决策主体的跨越。甲子光年智库全面深入地探讨了AI Agent发展演进、产业价值与商业模式变革、技术路径与能力提升以及面临的挑战等方面,旨在为关注AI Agent领域的投资者、从业者、研究者等提供全面且权威的参考依据。
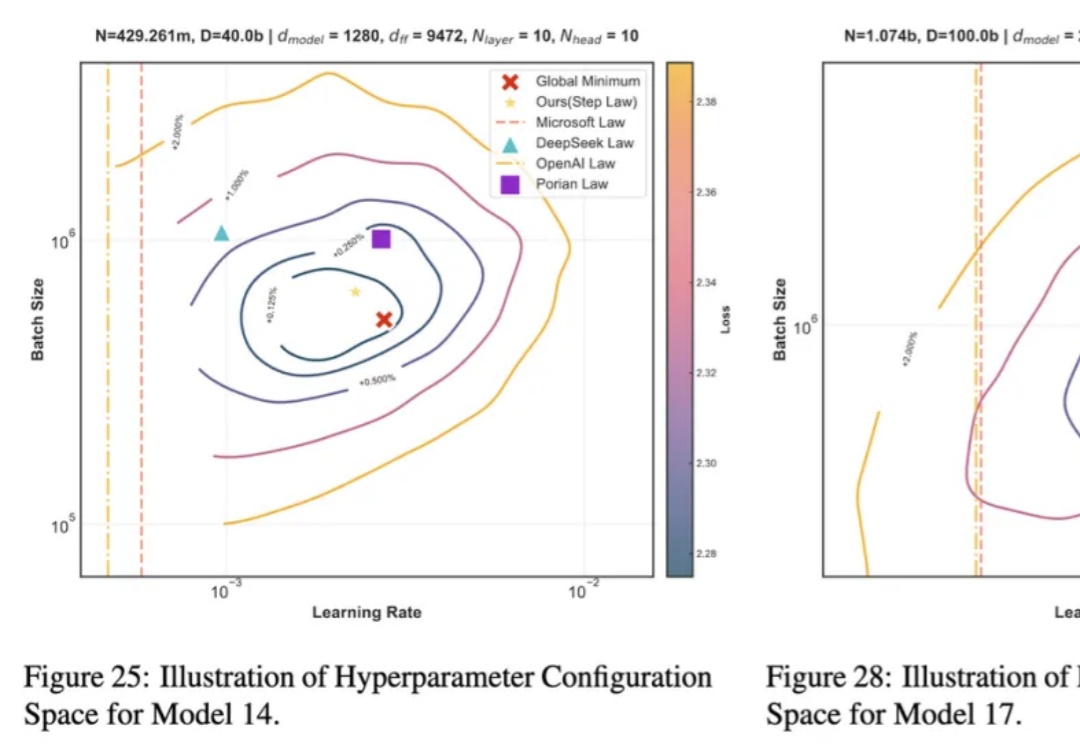
近年来,大语言模型 LLMs 在多种任务上的卓越表现已得到广泛认可。然而,要实现其高效部署,精细的超参数优化至关重要。为了探究最佳超参数的规律,我们开展了大规模的实证研究,通过在不同配置上进行网格搜索,我们揭示了一套通用的最优超参数缩放定律(Optimal Hyperparameter Scaling Law)。
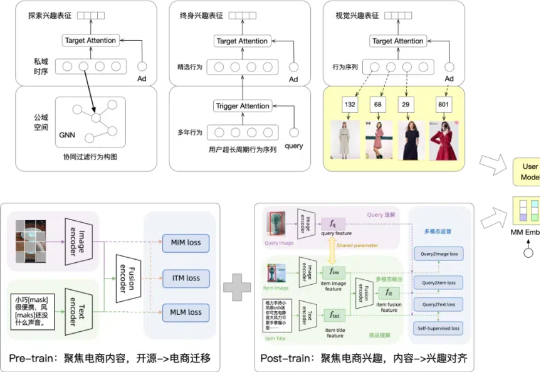
随着大模型时代的到来,搜推广模型是否具备新的进化空间?能否像深度学习时期那样迸发出旺盛的迭代生命力?带着这样的期待,阿里妈妈搜索广告在过去两年的持续探索中,逐步厘清了一些关键问题,成功落地了多个优化方向。

不怕推理模型简单问题过度思考了,能动态调整CoT的新推理范式SCoT来了!

最新研究显示,以超强推理爆红的DeepSeek-R1模型竟藏隐形危险——
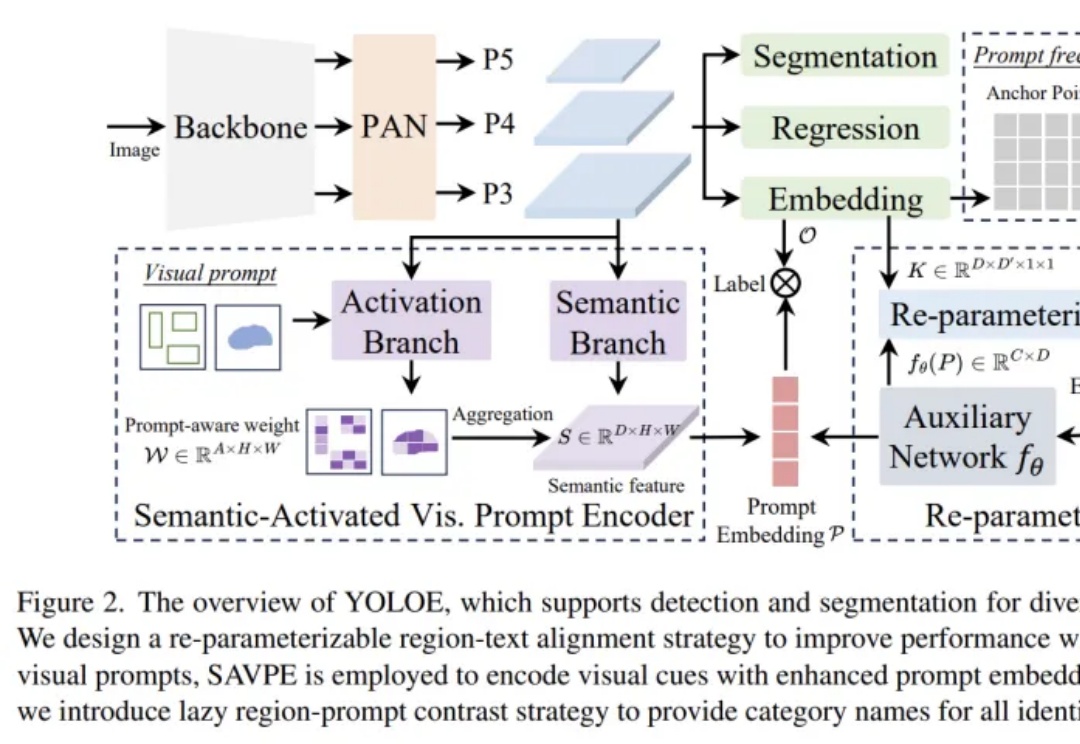
它能像人眼一样,在文本、视觉输入和无提示范式等不同机制下进行检测和分割。
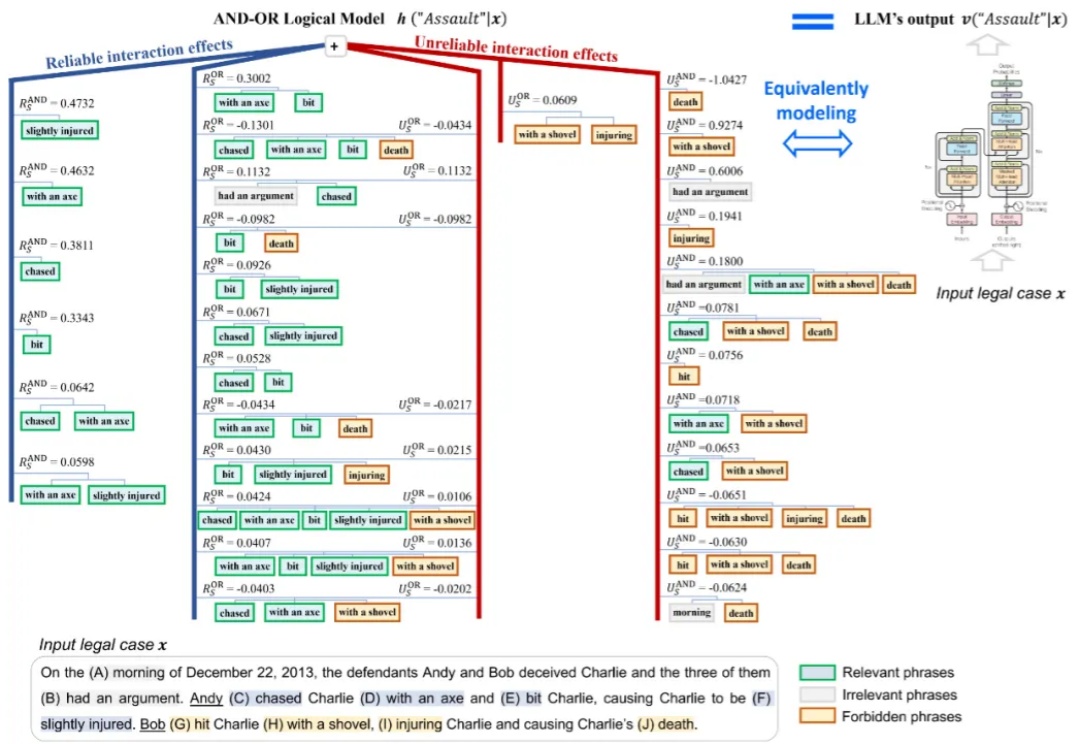
近些年,大模型的发展可谓是繁花似锦、烈火烹油。从 2018 年 OpenAI 公司提出了 GPT-1 开始,到 2022 年底的 GPT-3,再到现在国内外大模型的「百模争锋」,DeepSeek 异军突起,各类大模型应用层出不穷。
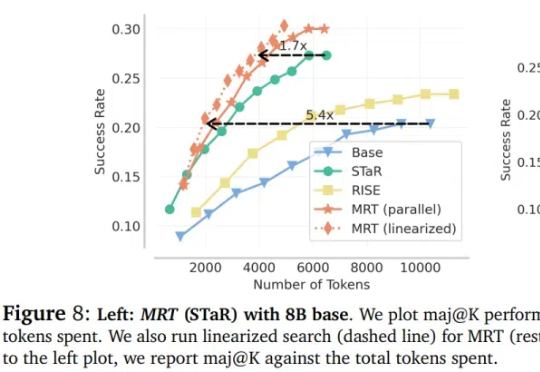
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。

四个月前,我们采访了 Chat2DB 创始人姬朋飞,文章里讲述了他从大厂离职后的创业历程。而最近 Cha2DB 针对 SQL 开发者的普遍痛点,发布了全新的 3.0 版本。

Anthropic 昨晚发布了他们最新的 Claude 3.7 Sonnet 混合推理模型,并在官网同步更新了 Claude 3.7 的系统提示词。
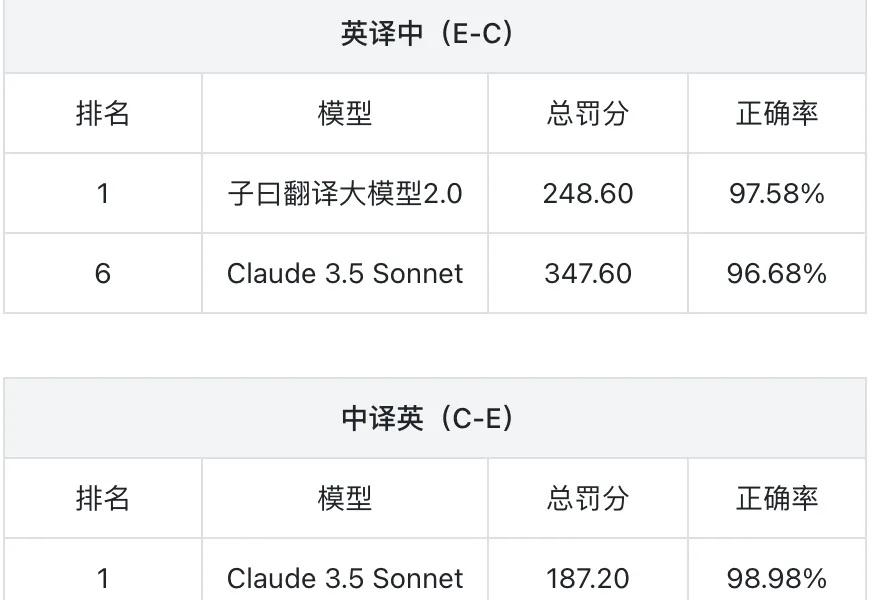
都说通用大模型轻松拿捏翻译,结果有人来掀桌了。

在实际应用过程中,闭源模型(GPT-4o)等在回复的全面性、完备性、美观性等方面展示出了不俗的表现。

Sakana AI刚刚官宣,第二代「AI科学家」独立完成论文,通过了ICLR 2025 Workshop的同行评审。这是首次完全由AI端到端生成的科学论文,获得了学术高度认可。

近日,北京大学智能学院袁晓如课题组在中国古籍内容的智能探索方面开展跨学科合作探索取得重要进展。研究通过智能自动分类机制,从大量中国古籍中提取可视化图像,建立大规模中国古代可视化集合
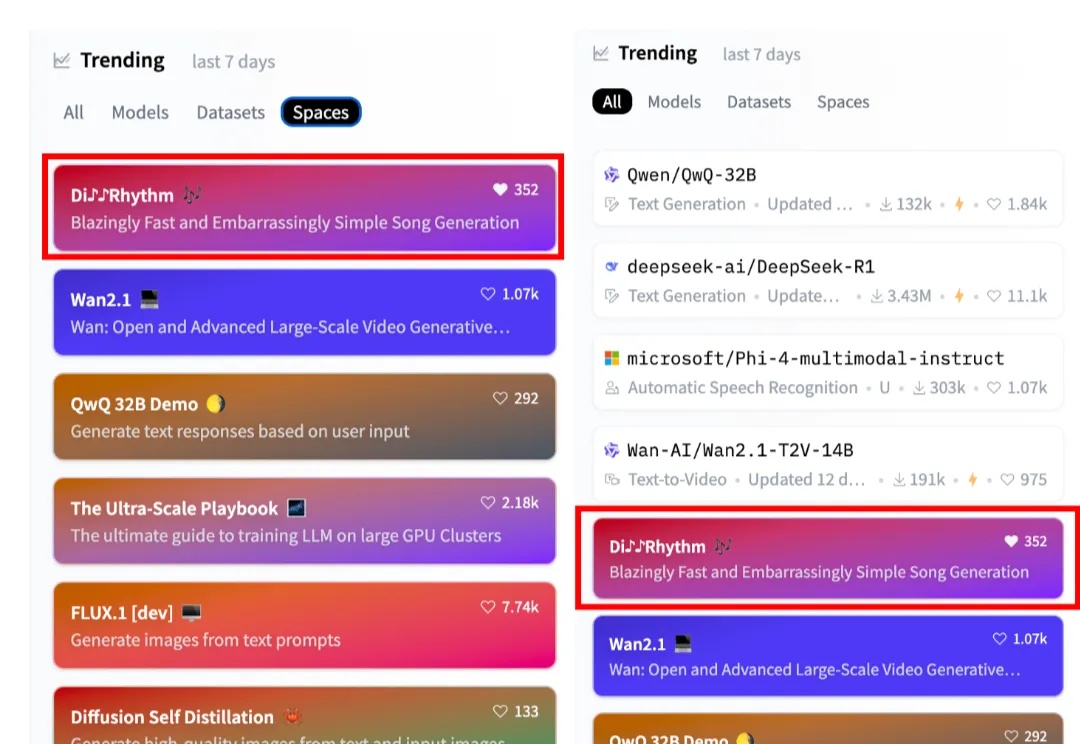
DiffRhythm是一款新型AI音乐生成模型,能在10秒内生成长达4分45秒的完整歌曲,包含人声和伴奏。它采用简单高效的全diffusion架构,仅需歌词和风格提示即可创作,还支持本地部署,最低只需8G显存。
揭秘如何在 20 分钟内用 AI 创建专业级界面,并分享前四大核心技巧,让你的 AI 生成的应用脱胎换骨。

大模型时代,读论文这事儿真是越来越爽了~