RAG发展图谱:从基础检索到记忆增强,再到自适应RAG的五大范式 | RAG最新综述
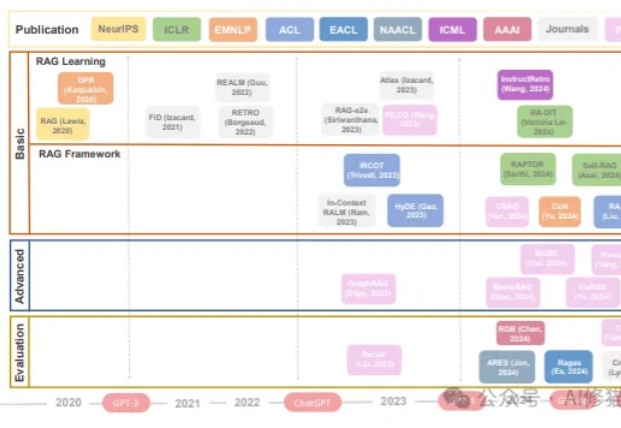
RAG发展图谱:从基础检索到记忆增强,再到自适应RAG的五大范式 | RAG最新综述RAG工作发展时间线(2020年至今)。展示了RAG相关研究的三个主要领域:基础(包括RAG学习和RAG框架)、进阶和评估。关键的语言模型(GPT-3、GPT-4等)发展节点标注在时间线上。
来自主题: AI技术研报
11490 点击 2025-03-21 12:18
 搜索
搜索
RAG工作发展时间线(2020年至今)。展示了RAG相关研究的三个主要领域:基础(包括RAG学习和RAG框架)、进阶和评估。关键的语言模型(GPT-3、GPT-4等)发展节点标注在时间线上。

在GTC2025大会上,NVIDIA依旧延续着“算力的故事”。如果AI的发展依旧遵循着scaling law(规模定律),那么这个故事还能继续讲下去。
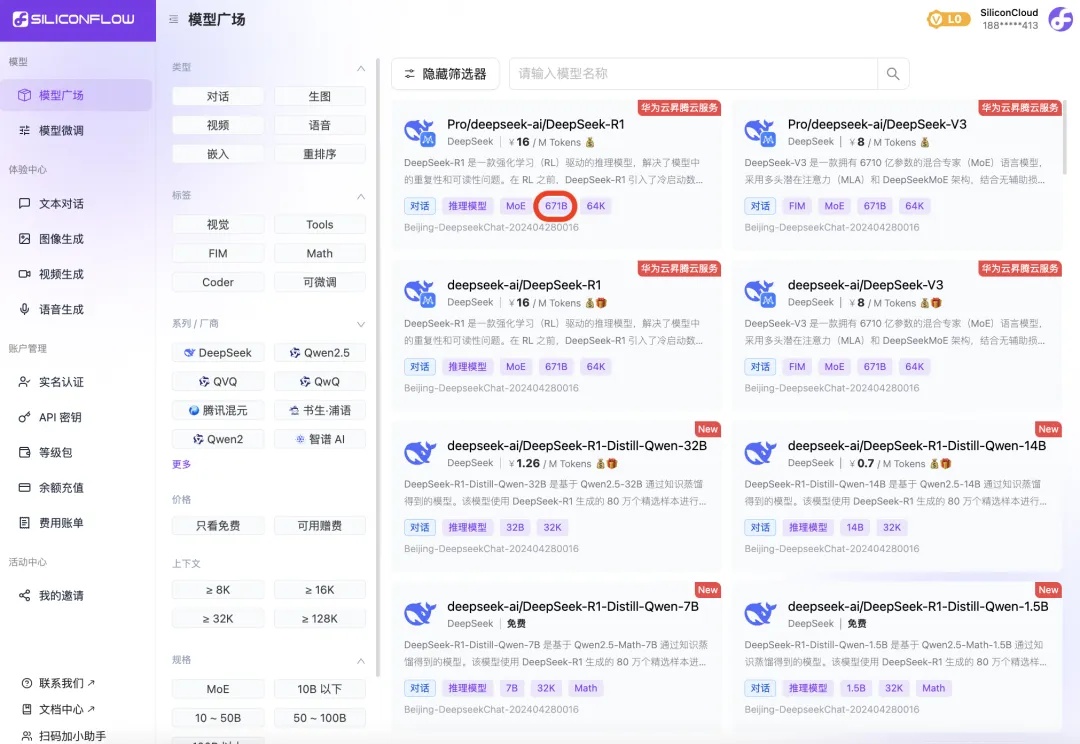
随着硅基流动的 SiliconCloud 等平台上线 DeepSeek-R1,市面上出现了不少测试各大厂商 API 服务的评测文章及反馈,不过,从我们收到的不少内容及反馈来看,其中的对比测试方式多有漏洞,内容质量参差不齐。
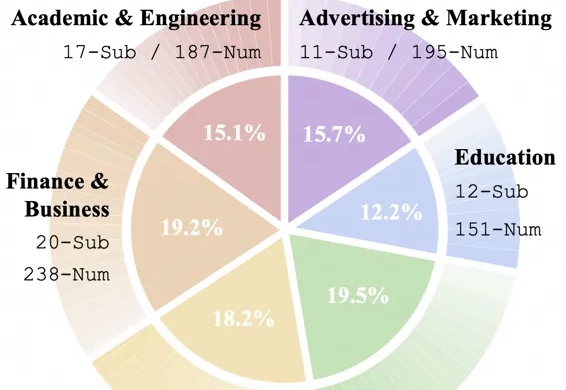
全面评估大模型生成式写作能力的基准来了!
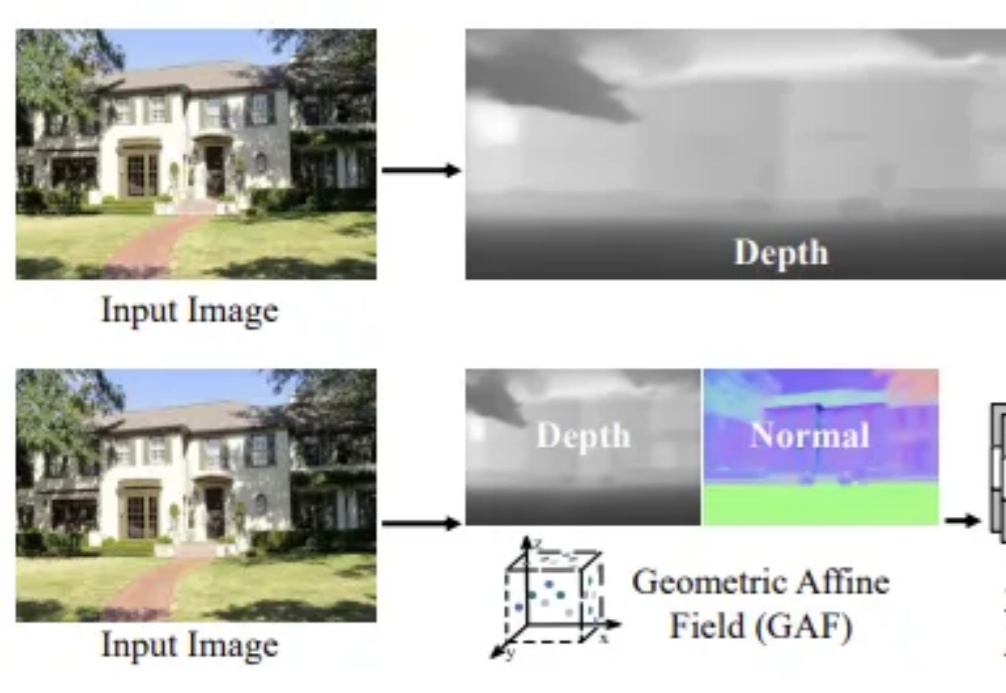
单视角三维场景重建一直是计算机视觉领域中的核心挑战之一,尤其在捕捉高保真室外场景细节时,如何确保结构一致性和几何精度显得尤为困难。
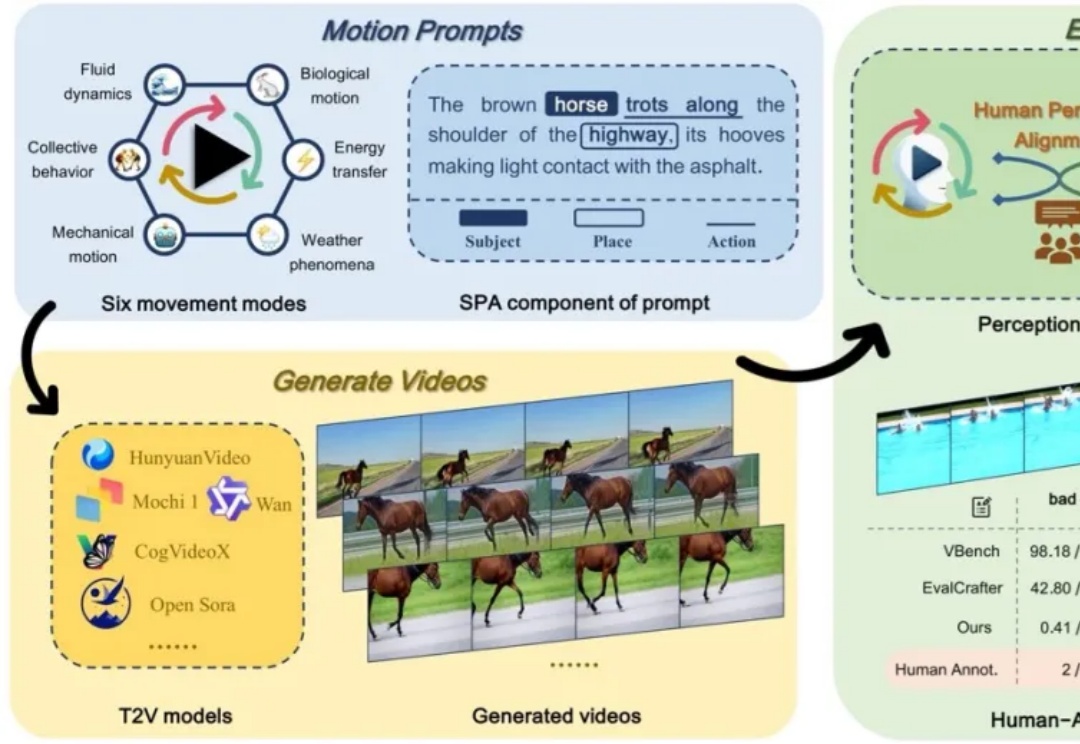
测一测现有AI生成视频是否符合物理运动规律!

任意一张立绘,就可以生成可拆分3D角色!

当我们看到一张猫咪照片时,大脑自然就能识别「这是一只猫」。但对计算机来说,它看到的是一个巨大的数字矩阵 —— 假设是一张 1000×1000 像素的彩色图片,实际上是一个包含 300 万个数字的数据集(1000×1000×3 个颜色通道)。每个数字代表一个像素点的颜色深浅,从 0 到 255。
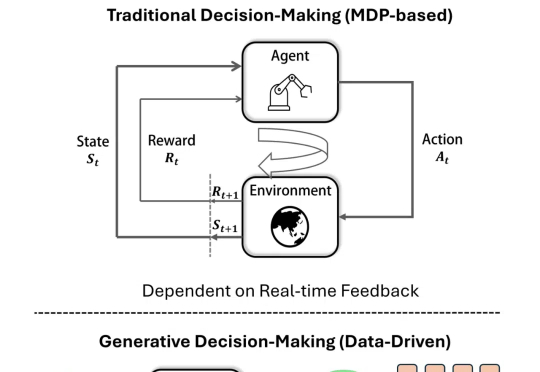
近年来,生成模型在内容生成(AIGC)领域蓬勃发展,同时也逐渐引起了在智能决策中的应用关注。
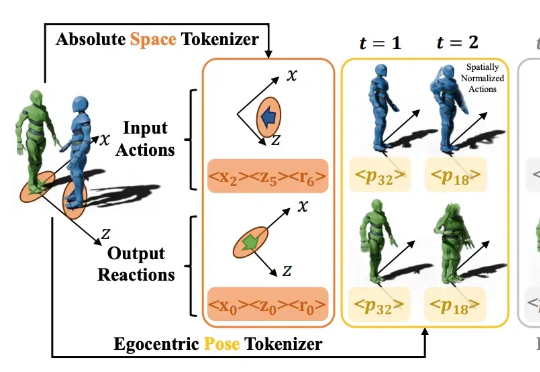
对面有个人向你缓缓抬起手,你会怎么回应呢?握手,还是挥手致意?

如果你让当今的 LLM 给你生成一个创意时钟设计,使用提示词「a creative time display」,它可能会给出这样的结果:

EgoNormia基准可以评估视觉语言模型在物理社会规范理解方面能力,从结果上看,当前最先进的模型在规范推理方面仍远不如人类,主要问题在于规范合理性和优先级判断上的不足。
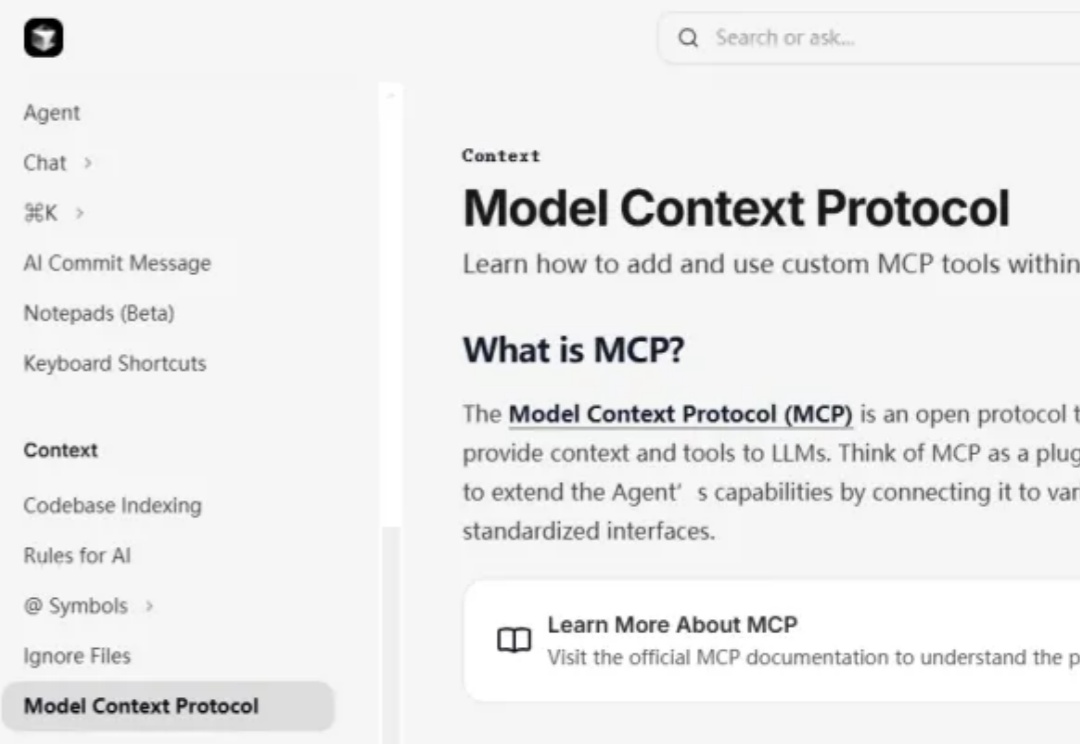
在用Cursor等AI工具编程的同学们,有没有发现,你原本想让AI帮你解决问题,但AI老是让你自己去操作。
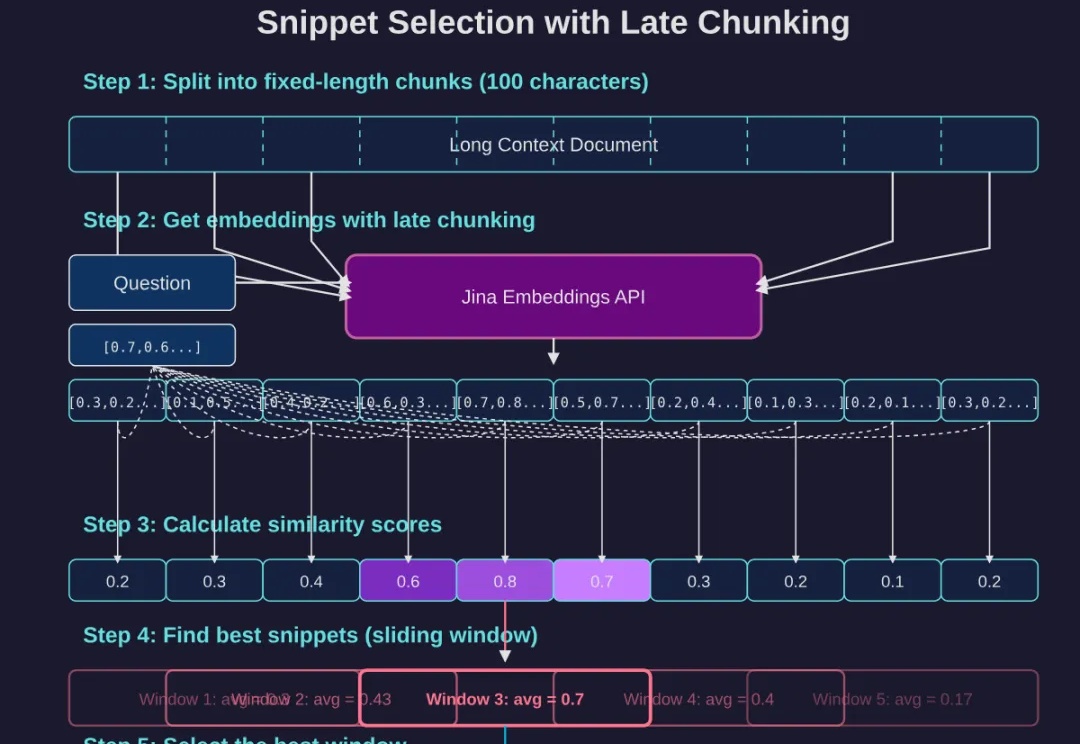
如果你已经读过我们上一篇经典长文《DeepSearch/DeepResearch 的设计与实现》,那么不妨再深挖一些能大幅提升回答质量的细节。这次,我们将重点关注两个细节:

本文介绍了Search-R1技术,这是一项通过强化学习训练大语言模型进行推理并利用搜索引擎的创新方法。实验表明,Search-R1在Qwen2.5-7B模型上实现了26%的性能提升,使模型能够实时获取准确信息并进行多轮推理。本文详细分析了Search-R1的工作原理、训练方法和实验结果,为AI产品开发者提供了重要参考。

近年来,扩散模型在图像与视频合成领域展现出强大能力,为图像动画技术的发展带来了新的契机。特别是在人物图像动画方面,该技术能够基于一系列预设姿态驱动参考图像,使其动态化,从而生成高度可控的人体动画视频。
近年来,大型语言模型(LLM)通过大量计算资源在推理阶段取得了解决复杂问题的突破。推理速度已成为 LLM 架构的关键属性,市场对高效快速的 LLM 需求不断增长。

文本到图像(Text-to-Image, T2I)生成任务近年来取得了飞速进展,其中以扩散模型(如 Stable Diffusion、DiT 等)和自回归(AR)模型为代表的方法取得了显著成果。然而,这些主流的生成模型通常依赖于超大规模的数据集和巨大的参数量,导致计算成本高昂、落地困难,难以高效地应用于实际生产环境。
最近在推特上刷到一条视频,特别火爆,彻底把我看呆了。

AI写的论文已经在ICLR的研讨会上通过了同行评审,还是一口气中就中了两篇。

人类具有通用的、解决长时序复杂任务的规划能力,这在我们处理生活中的复杂操作任务时很有用。
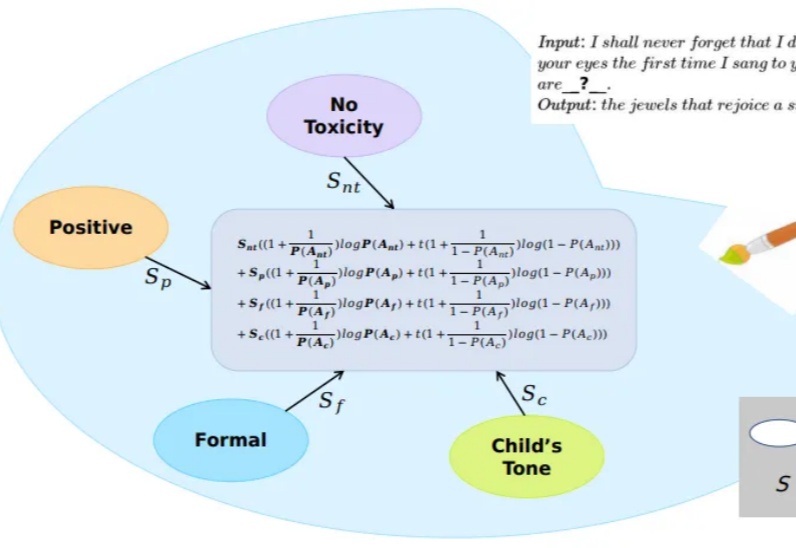
大模型在文本生成方面取得了卓越的成就,通过合适的prompt设计,往往可以使得生成结果符合特定的需求。但是为属性繁多的任务设计出合适的prompt是很困难的。一种解决方案是通过线性组合方式或者其变种将每个属性对应的模型在生成logits上进行融合。鉴于属性之间可能存在的冲突现象,这种方案无法保证模型的主属性不受其他模型的干扰。

事关路由LLM(Routing LLM),一项截至目前最全面的研究,来了——
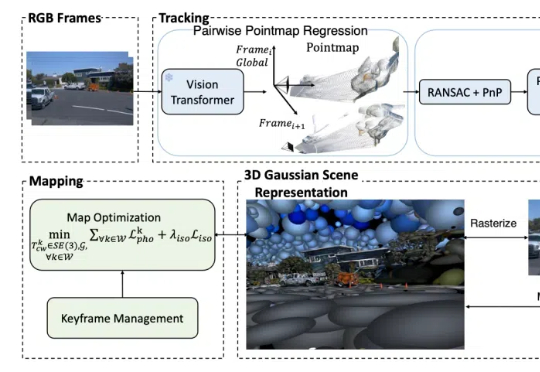
从自动驾驶、机器人导航,到AR/VR等前沿应用,SLAM都是离不开的核心技术之一。
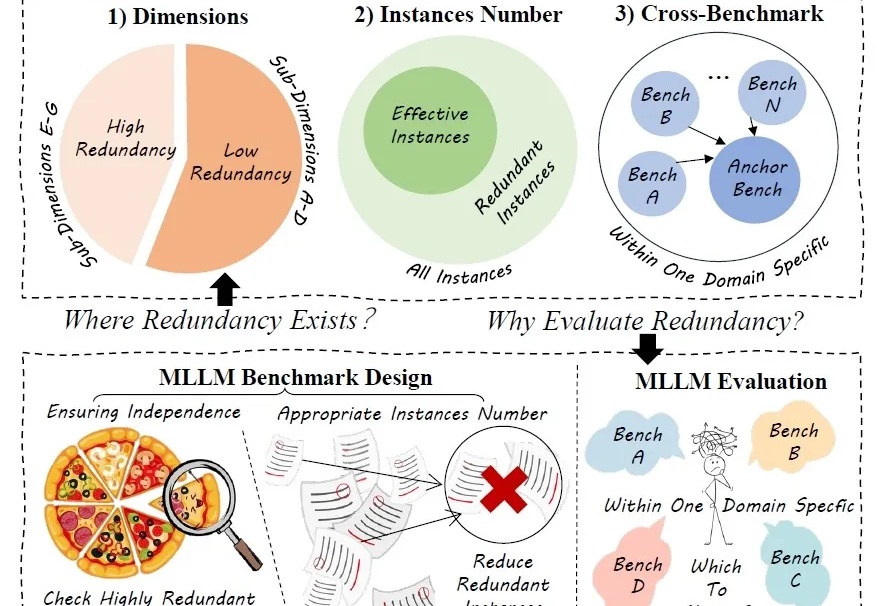
评估多模态AI模型的那些复杂测试,可能有一半都是“重复劳动”!
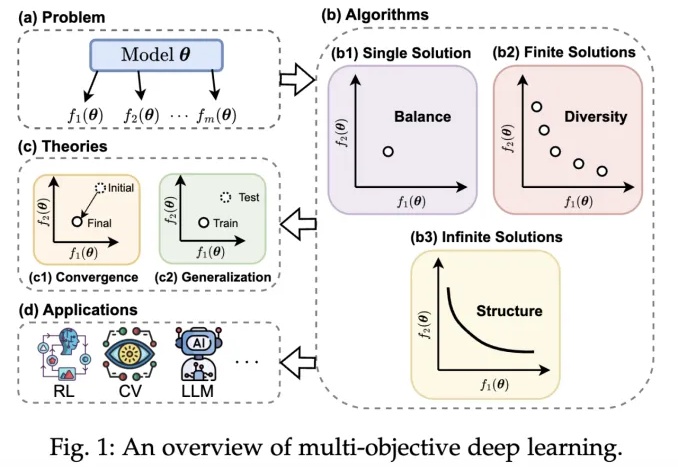
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。
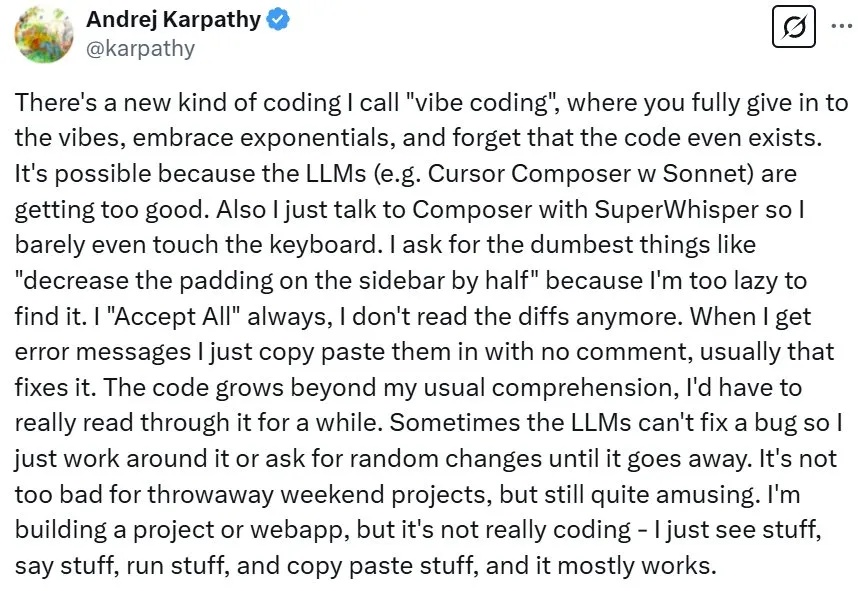
近段时间,著名 AI 科学家 Andrej Karpathy 提出的氛围编程(vibe coding)是 AI 领域的一大热门话题。简单来说,氛围编程就是鼓励开发者忘掉代码,进入开发的氛围之中。更简单地讲,就是向 LLM 提出需求,然后「全部接受」即可。

多模态大模型虽然在视觉理解方面表现出色,但在需要深度数学推理的任务上往往力不从心,尤其是对于参数量较小的模型来说更是如此。

通过收集六名志愿者一周的多模态生活数据,研究人员构建了300小时的第一视角数据集EgoLife,旨在开发一款基于智能眼镜的AI生活助手。项目提出了EgoButler系统,包含EgoGPT和EgoRAG两个模块,分别用于视频理解与长时记忆问答,助力AI深入理解日常生活并提供个性化帮助。
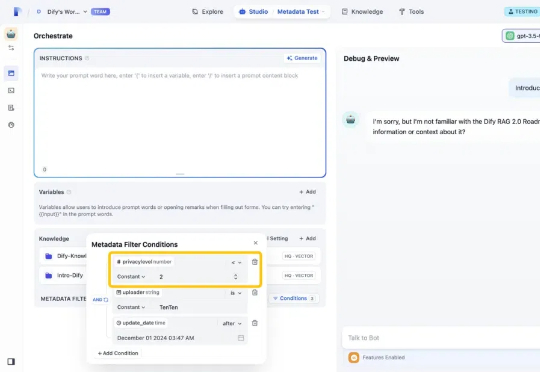
我是 Dify 产品团队的 Yawen。今天,我们很高兴地宣布发布 Dify v1.1.0,并推出了以“元数据”作为知识过滤器的新功能。通过利用自定义的元数据属性,元数据过滤能够提升知识库中相关数据的检索效率和准确度。过去,用户只能在庞大的数据集中进行搜索,无法根据特定需求进行筛选或控制访问,难以快速锁定最相关的信息。、