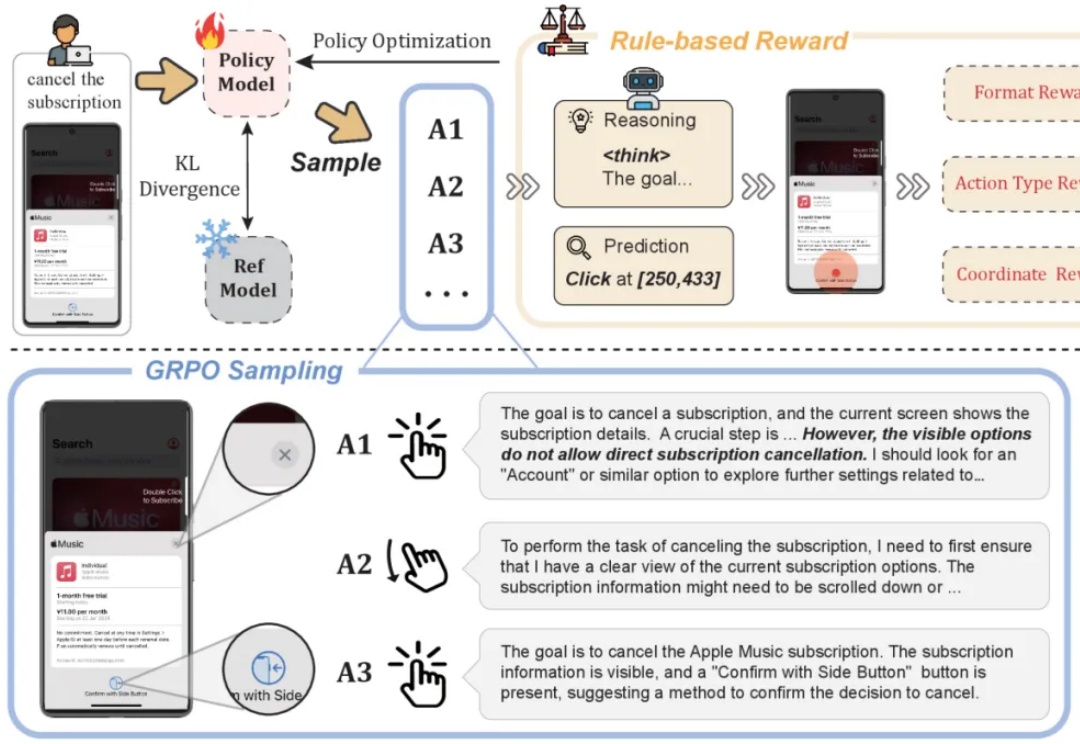
UI-R1|仅136张截图,vivo开源DeepSeek R1式强化学习,提升GUI智能体动作预测
UI-R1|仅136张截图,vivo开源DeepSeek R1式强化学习,提升GUI智能体动作预测基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。
来自主题: AI技术研报
7162 点击 2025-04-09 09:14
 搜索
搜索
基于规则的强化学习(RL/RFT)已成为替代 SFT 的高效方案,仅需少量样本即可提升模型在特定任务中的表现。

大规模数据集和标准化评估基准显著促进了自然语言处理和计算机视觉领域的发展。然而,机器人领域在如何构建大规模数据集并建立可靠的评估体系方面仍面临巨大挑战。

多模态视频异常理解任务,又有新突破!

AI绘画总「翻车」,不是抓不住重点,就是细节崩坏?别愁!微软和港中文学者带来ImageGen-CoT技术,让AI像人一样思考推理,生成超惊艳画作,性能提升高达80%。
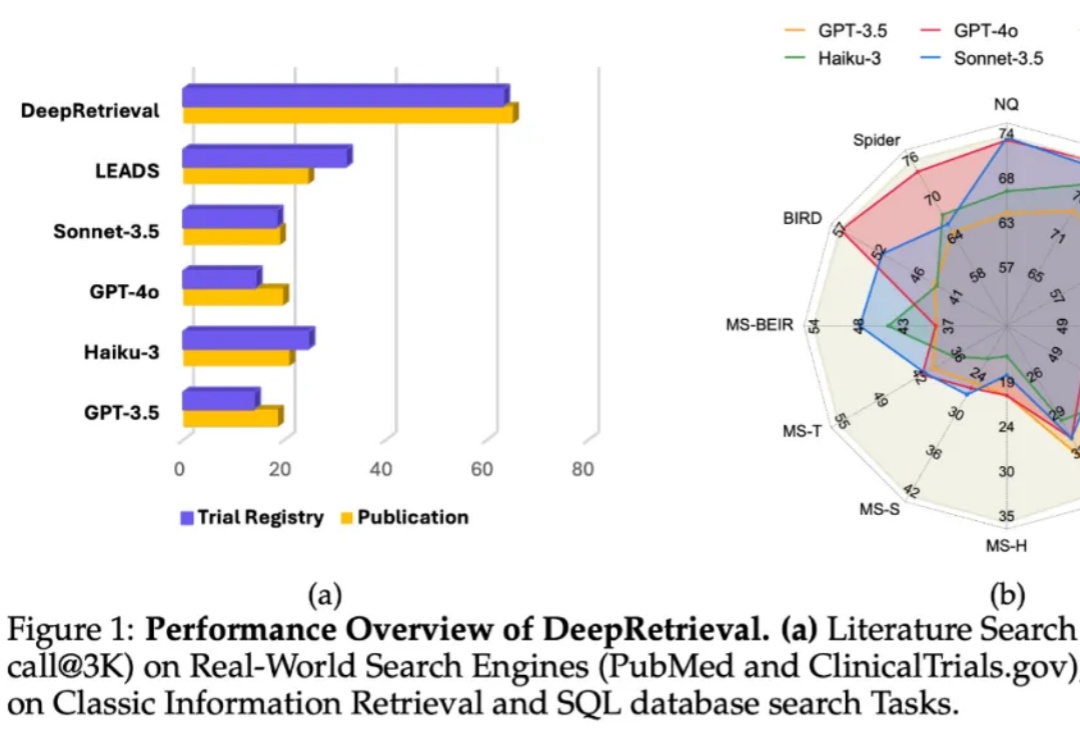
在信息检索系统中,搜索引擎的能力只是影响结果的一个方面,真正的瓶颈往往在于:用户的原始 query 本身不够好。
Q-Insight不再简单地让模型拟合人眼打分,而是将评分视作一种引导信号,促使模型深度思考图像质量的本质原因。有了会思考的“大脑”,视频云技术栈不仅得以重塑也让用户体验有了跃迁。
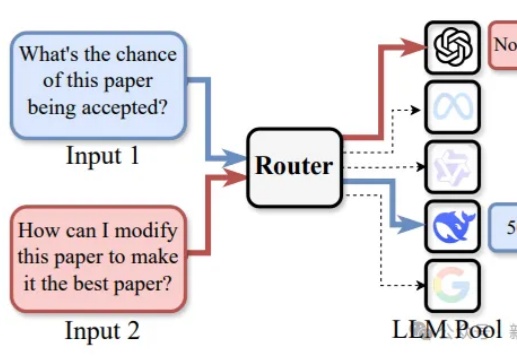
路由LLM是指一种通过router动态分配请求到若干候选LLM的机制。论文提出且开源了针对router设计的全面RouterEval基准,通过整合8500+个LLM在12个主流Benchmark上的2亿条性能记录。将大模型路由问题转化为标准的分类任务,使研究者可在单卡甚至笔记本电脑上开展前沿研究。
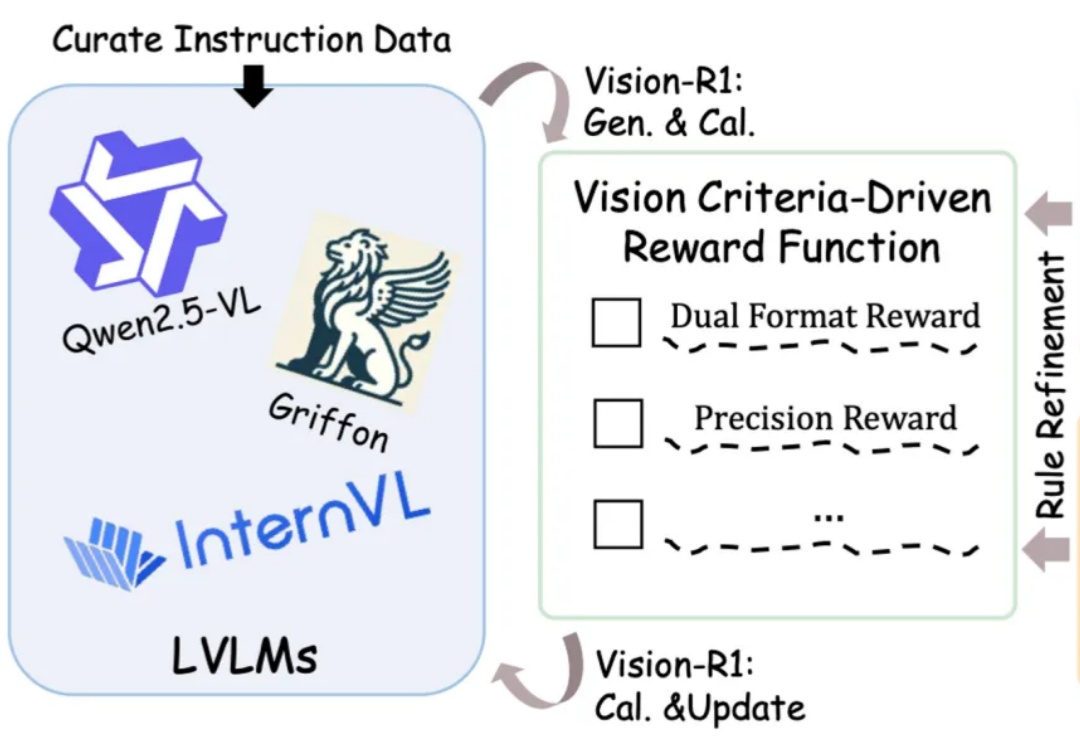
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。

Agentic AI 的 3 要素是:tool use,memory 和 context,围绕这三个场景会出现 agent-native Infra 的机会。
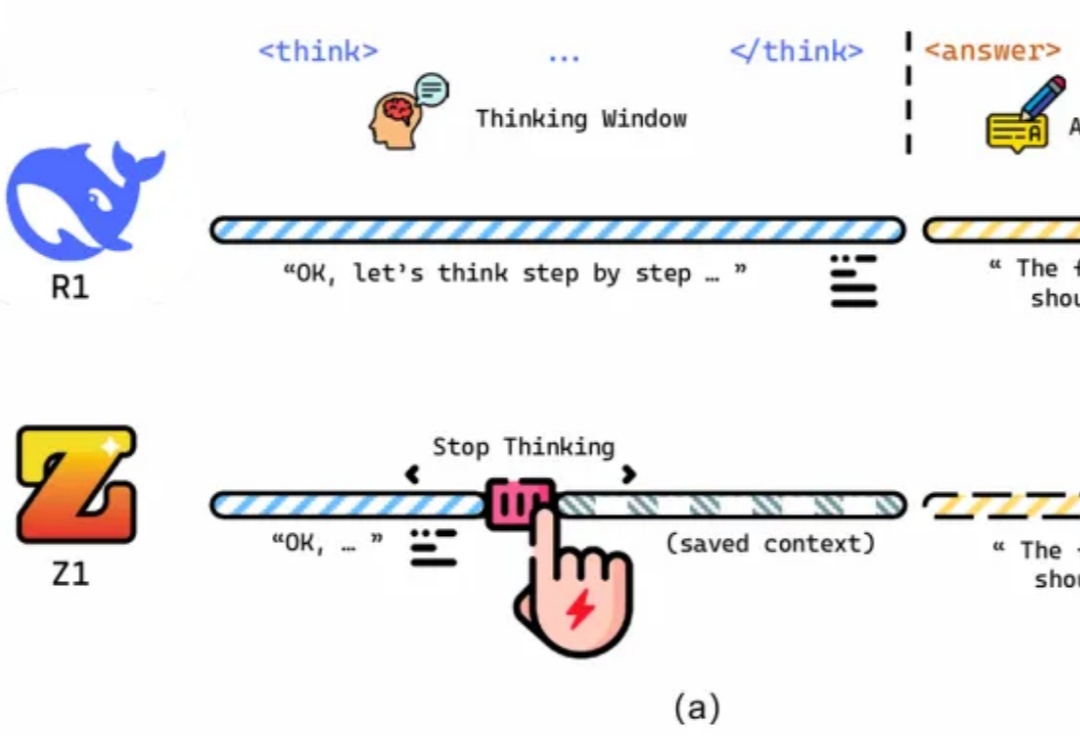
推理性能提升的同时,还大大减少Token消耗!
如何让大模型更懂「人」?
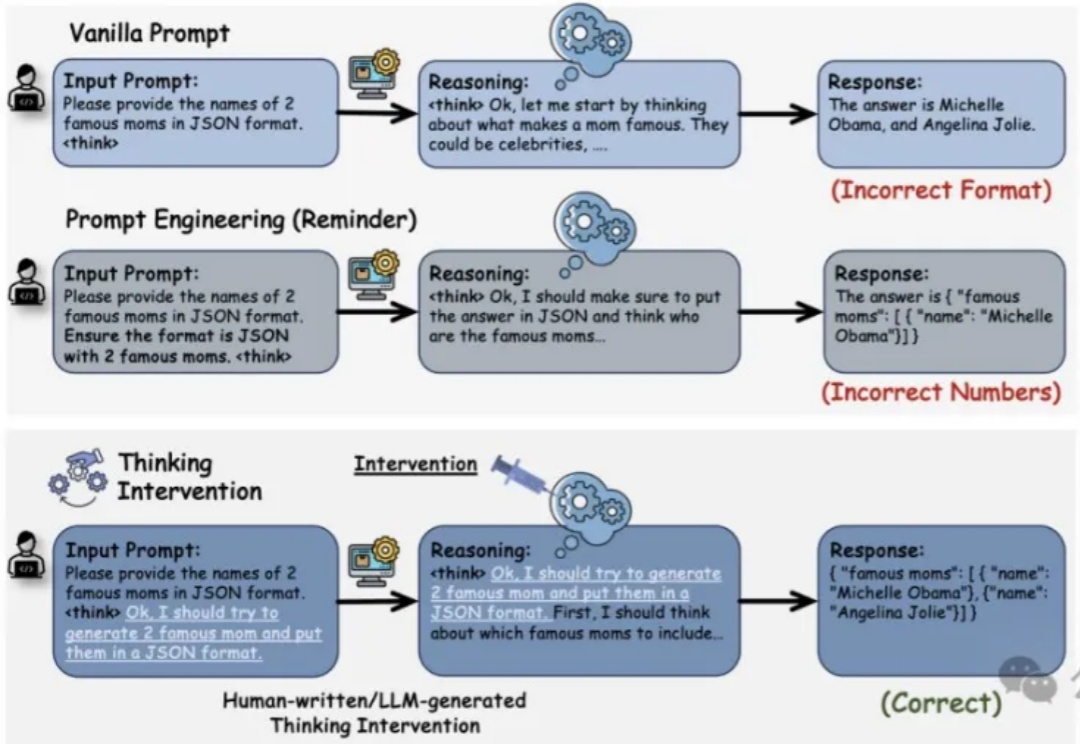
推理增强型大语言模型LRM(如OpenAI的o1、DeepSeek R1和Google的Flash Thinking)通过在生成最终答案前显式生成中间推理步骤,在复杂问题解决方面展现了卓越性能。然而,对这类模型的控制仍主要依赖于传统的输入级操作,如提示工程(Prompt Engineering)等方法,而你可能已经发现这些方法存在局限性。
想象一下,你坐着时光机回到1750年——那个时代没有电,远程通信就意味着要么大声呼喊,要么朝天鸣炮,所有的交通工具都靠消耗饲料来运行。你到了那里,找一个1750年的人
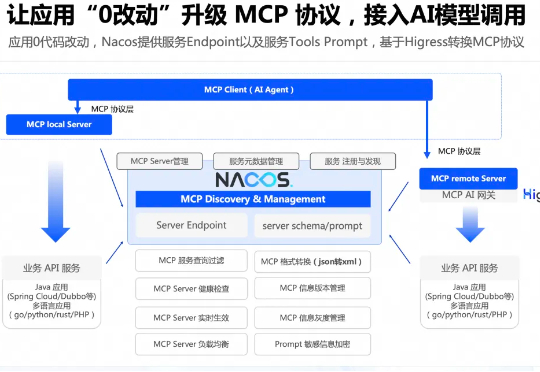
Nacos 可以帮助应用快速把业务已有的 API 接口,转换成 MCP 协议接口,结合 Higress AI 网关,实现 MCP 协议和存量协议的转换。其中,Nacos 提供存量的服务管理和动态的服务信息定义,帮助业务在存量接口不改动的情况下,通过 Nacos 的服务管理动态生效 Higress 网关所生成的 MCP Server 协议。
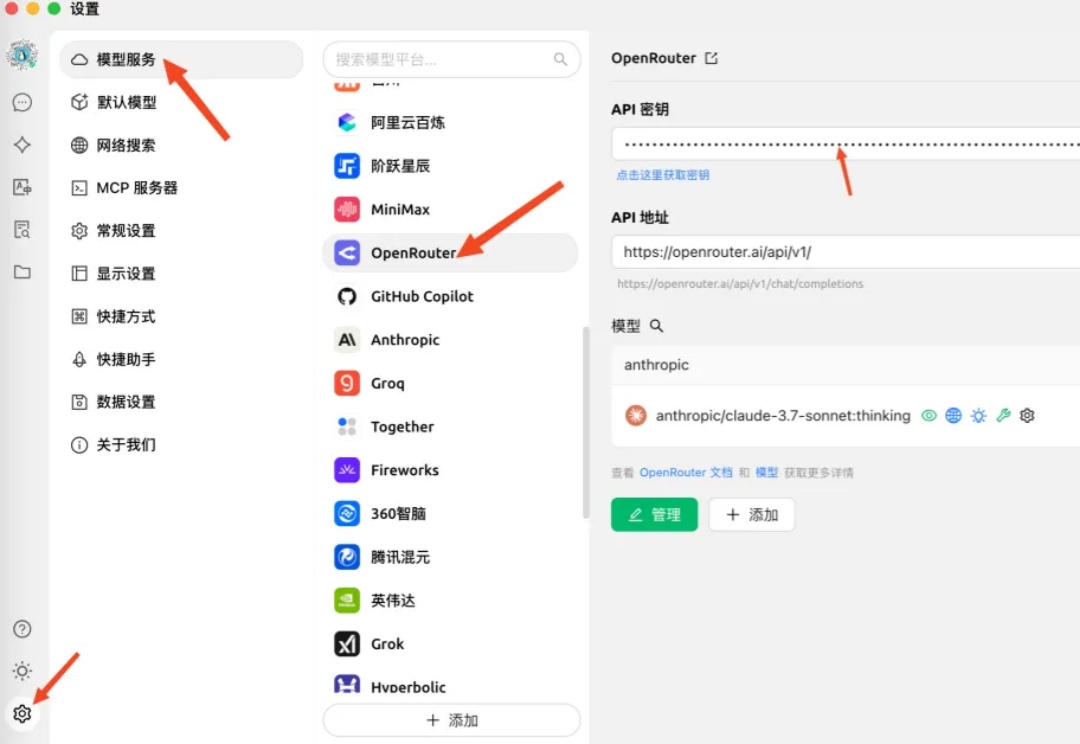
AI菩萨OpenRouter连发两大招宣布推出两项重大更新。

Noprop:没有反向传播或前向传播,也能训练神经网络。
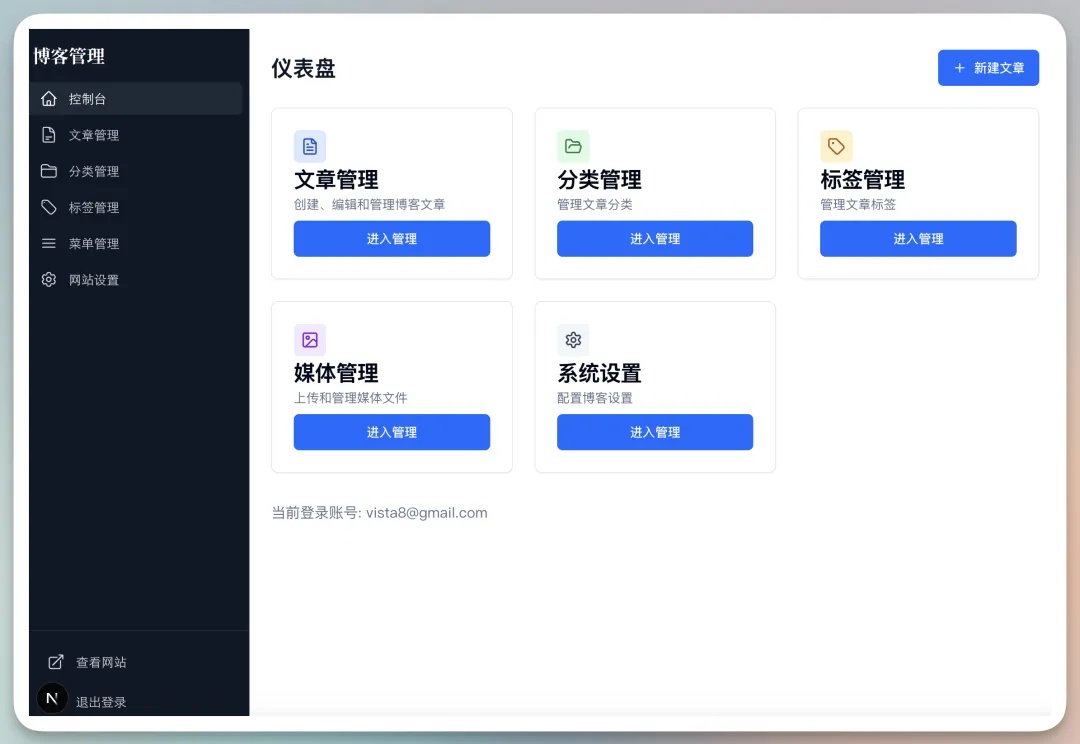
最近计划用AI编程重写自己的网站,后台功能已开发差不多。

让大语言模型更懂特定领域知识,有新招了!
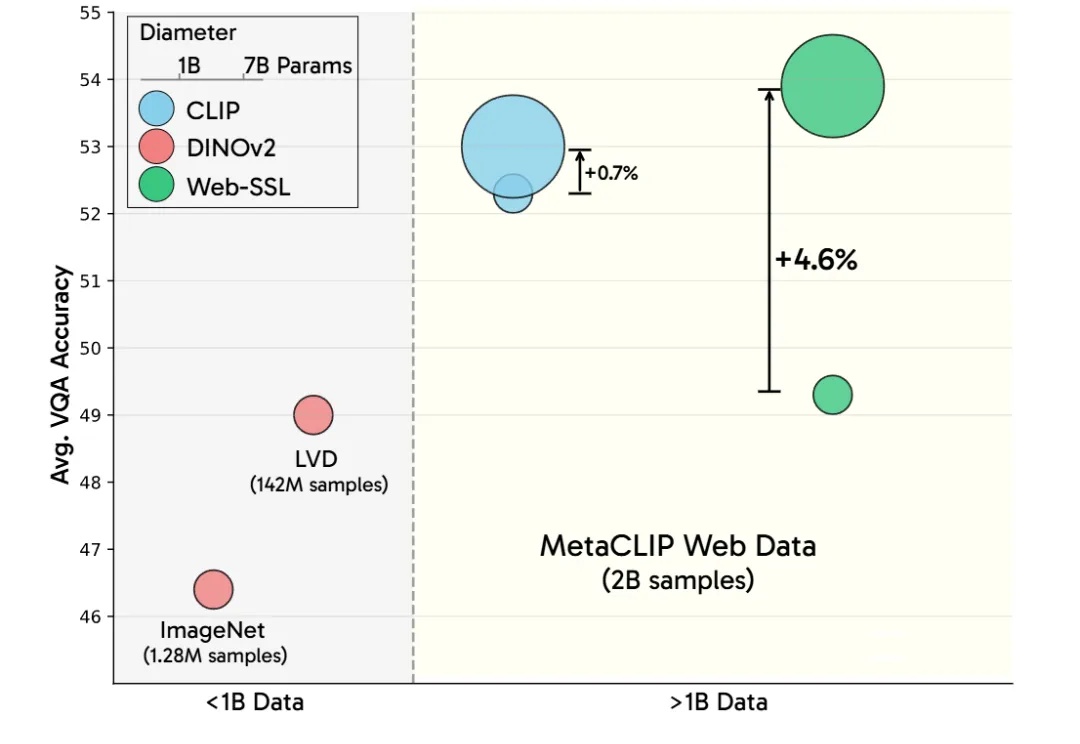
LeCun谢赛宁等研究人员通过新模型Web-SSL验证了SSL在多模态任务中的潜力,证明其在扩展模型和数据规模后,能媲美甚至超越CLIP。这项研究为无语言监督的视觉预训练开辟新方向,并计划开源模型以推动社区探索。
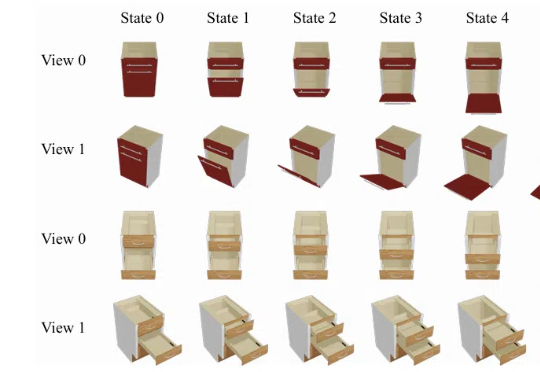
基于当前观察,预测铰链物体的的运动,尤其是 part-level 级别的运动,是实现世界模型的关键一步。

来自UIUC等大学的华人团队,从LLM的基础机制出发,揭示、预测并减少幻觉!通过实验,研究人员揭示了LLM的知识如何相互影响,总结了幻觉的对数线性定律。更可预测、更可控的语言模型正在成为现实。

近年来,视频生成技术在动作真实性方面取得了显著进展,但在角色驱动的叙事生成这一关键任务上仍存在不足,限制了其在自动化影视制作与动画创作中的应用潜力。
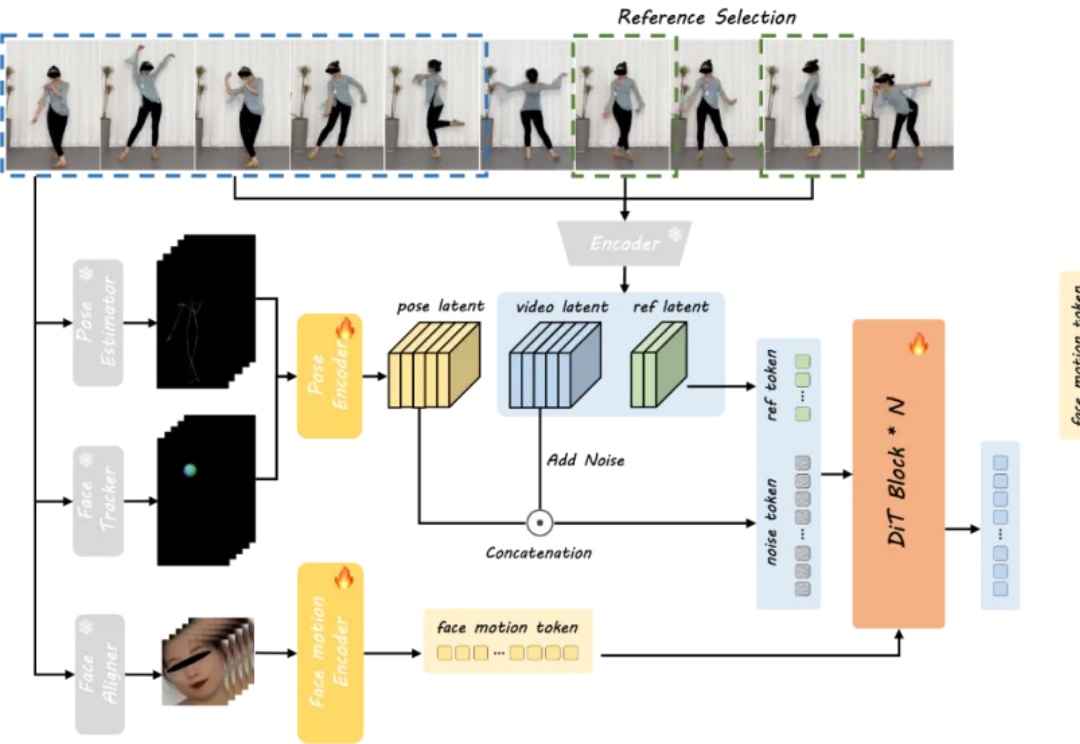
动作捕捉,刚刚发生了革命。
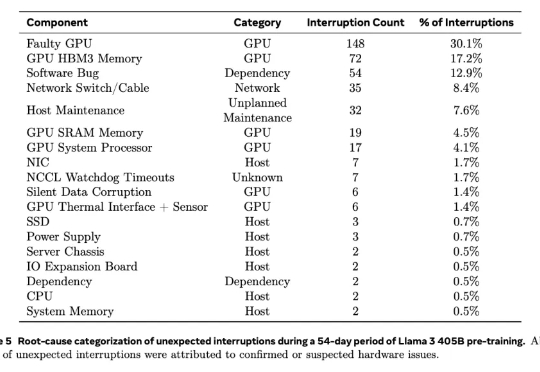
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:
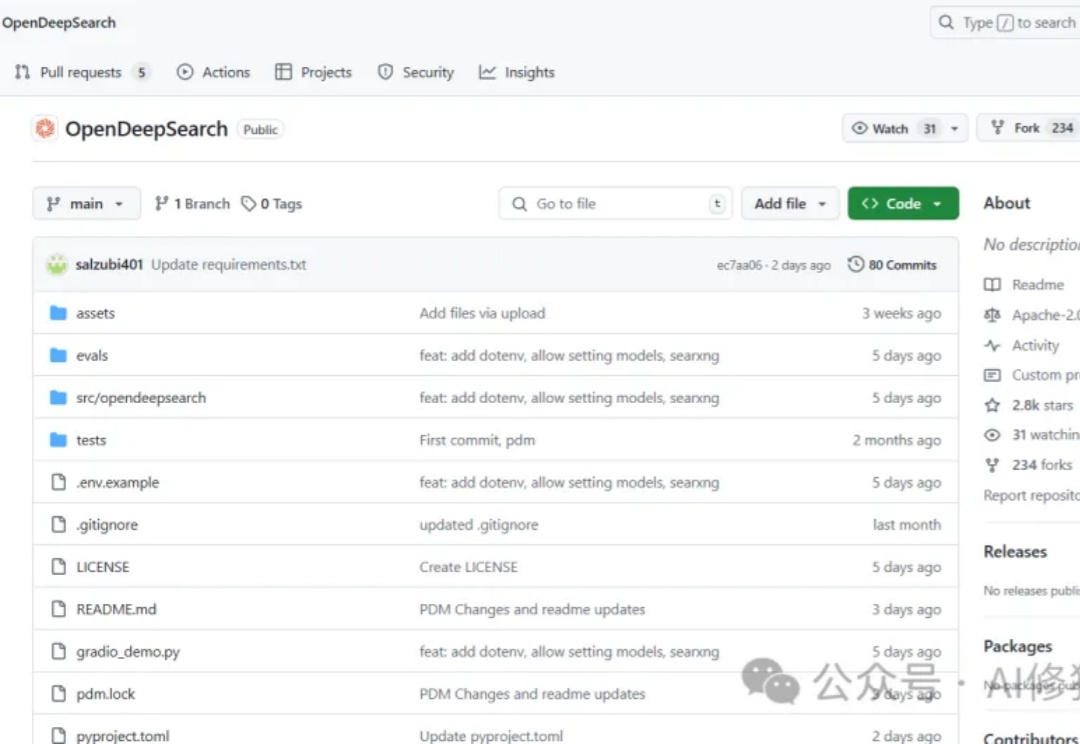
当前搜索AI市场面临着一个显著的断层:Perplexity的Sonar Reasoning Pro和OpenAI的GPT-4o Search Preview等专有解决方案与开源替代品之间存在巨大差距。这些封闭式系统虽然表现优异,但却限制了透明度、创新和创业自由。作为一名正在开发Agent产品的工程师,你是否曾经渴望拥有一个功能强大且完全开放的搜索框架?
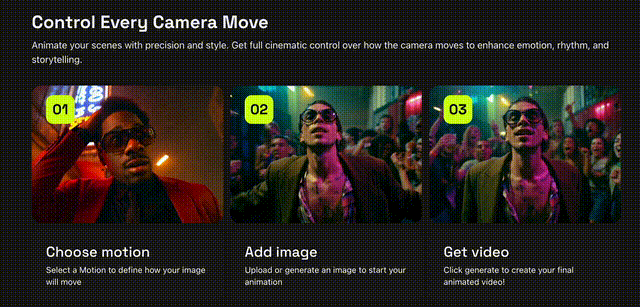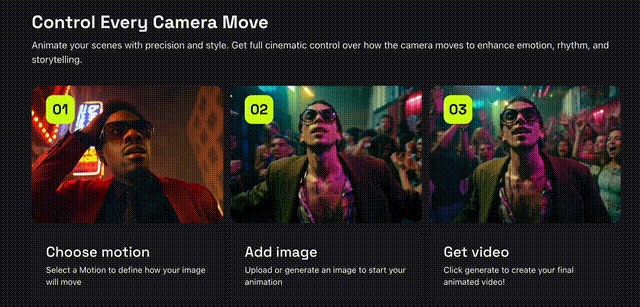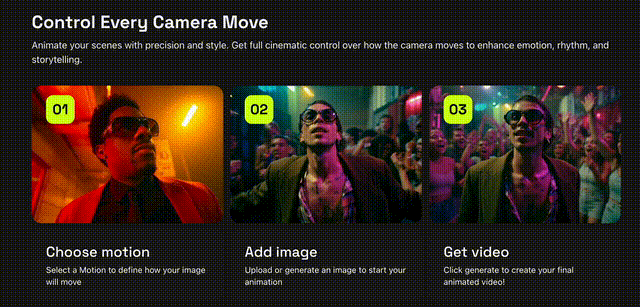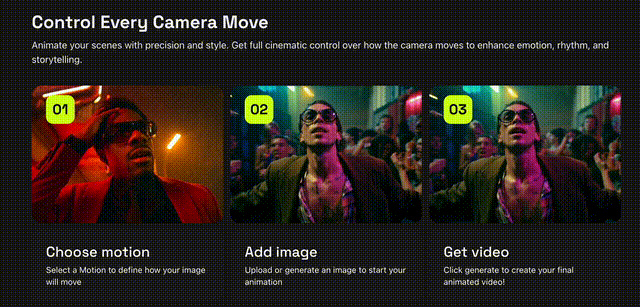
就在刚刚,Higgsfiled AI推出Motion Controls AI视频生成,在模仿电影级别的动作捕捉删上取得了新进展!不论是是360度环绕拍摄还是子弹时间都是信手拈来,从此就像口袋里装着一个「摄影组」,电影级别的画面也可以由AI代劳。

原生多模态Llama 4终于问世,开源王座一夜易主!首批共有两款模型Scout和Maverick,前者业界首款支持1000万上下文单H100可跑,后者更是一举击败了DeepSeek V3。目前,2万亿参数巨兽还在训练中。

想象一下,一座生机勃勃的 3D 城市在你眼前瞬间成型 —— 没有漫长的计算,没有庞大的存储需求,只有极速的生成和惊人的细节。
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
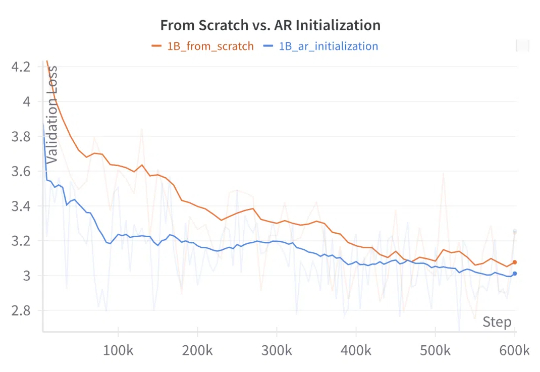
语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。