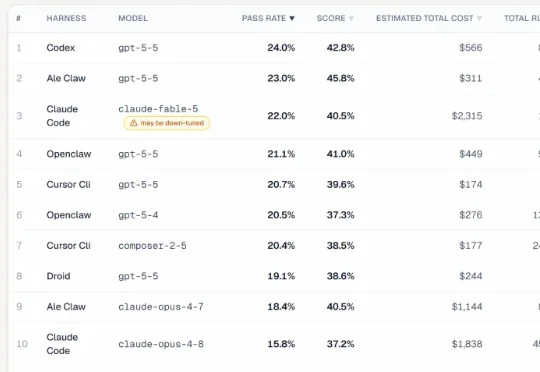
“智能体最后的考试”,Fable 5竟然不敌GPT 5.5
“智能体最后的考试”,Fable 5竟然不敌GPT 5.5刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。它把当今最强的AI Agent们拉到考场上,让它们干真正的活——在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。
来自主题: AI技术研报
9557 点击 2026-06-13 10:41
 搜索
搜索
刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。它把当今最强的AI Agent们拉到考场上,让它们干真正的活——在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。

硅谷 AI 圈又来了个新词:Loop Engineering。 大佬们纷纷表态,别再手动验证和写提示词了,该让 Agent 自己循环完成工作了。 OpenClaw 开发者 Peter Steinberger 带火了这个讨论,Claude Code 负责人 Boris Cherny 也说他已经不怎么在 Claude Code 里输入提示词了,而是去写 loops。
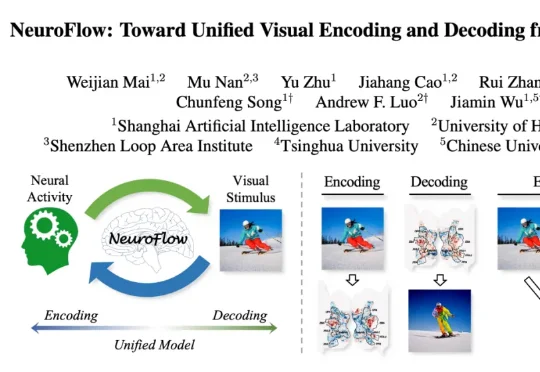
来自上海人工智能实验室、香港大学、香港中文大学等机构的研究团队,提出首个基于统一神经流模型的视觉-神经双向建模框架NeuroFlow,相关成果入选 CVPR 2026。它首次将视觉编码(写脑)与解码(读脑)整合到同一可逆流结构中,打通视觉感知与神经活动之间的双向通路,为理解人类视觉认知机制、构建下一代通用视觉假体与双向脑机接口提供了全新范式。
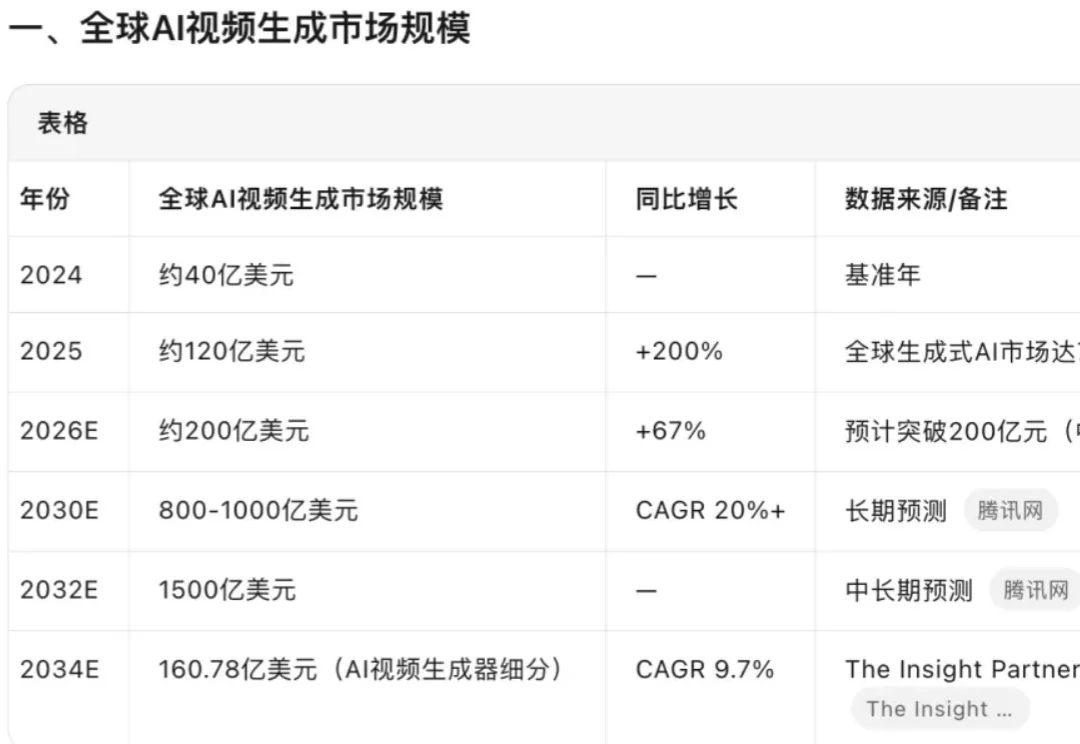
我最近专门调研了一下AI短视频🧐。发现市场规模是越来越大。

上下文攻击、供应链渗透、AI社区崩溃……当大模型智能体真正进入开放世界,挑战远比想象中复杂。
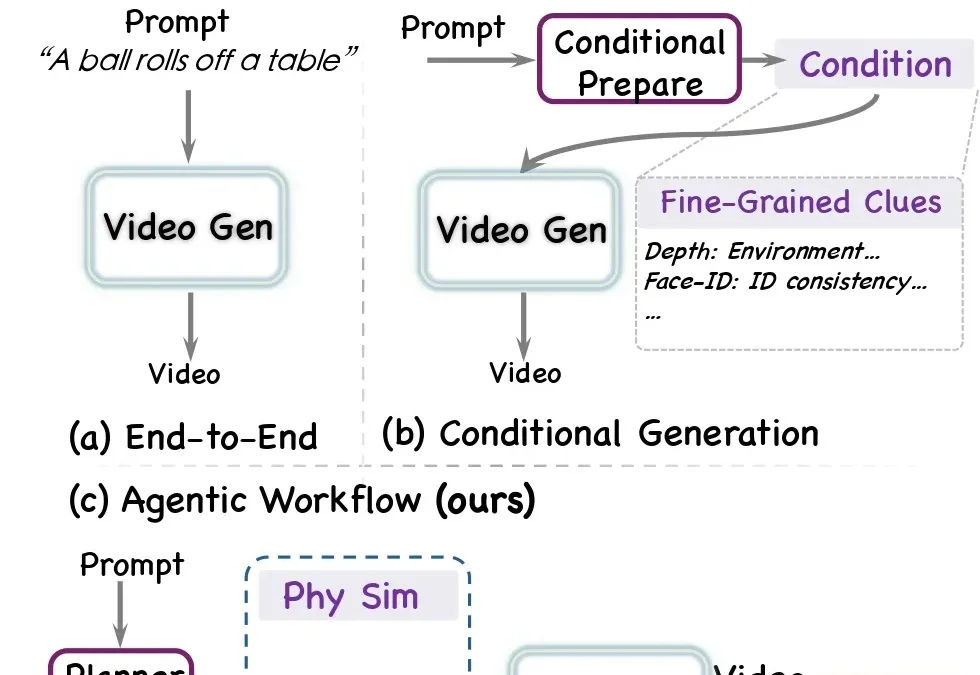
近年来,视频生成模型发展迅猛。从 Sora、Veo、Kling 到一系列开源视频生成模型,文生视频已经逼近真实影像的观感 —— 画面清晰、镜头流畅、风格可控,一句话就能生成一段观感不错的视频。
如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。

近日,Anthropic 发布了一篇引发广泛关注的文章《When AI builds itself》。文中披露了极其惊人的内部数据:截至 2026 年 5 月,Anthropic 超过 80% 的合并代码已由 Claude 编写,工程师的日常代码产出飙升了 8 倍;更令人瞩目的是,AI 智能体已经可以自主提出假设、执行长达数百小时的强化安全实验。

陶哲轩又发成绩单了。
想象这样一个惬意的周末: 空调带来阵阵凉意,你靠在沙发上看书,突然耳边传来“哒哒哒”的小碎步声,接着,玄关门边传来了一阵清脆、略带急切的“呜呜”声,还伴随着爪尖轻轻扒拉木门的声响。

这段时间以来,Codex 在社交媒体上是好评如潮。

视频生成,早已不止于视觉。
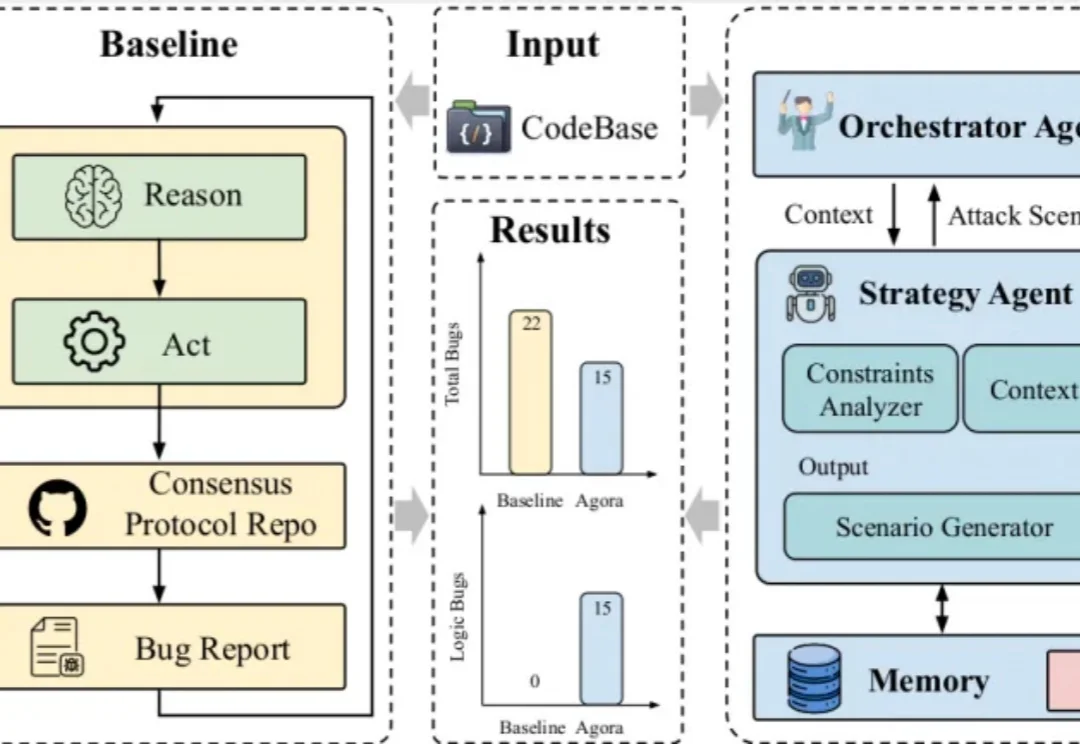
分布式系统的 “圣杯”—— 共识协议(Consensus Protocols),长久以来都是顶级基础设施工程师的 “Bug 地狱”。由于其状态极其复杂、多节点交织,传统测试和单体 LLM 对硬核的 Deep Bug(深层逻辑漏洞)几乎束手无策。
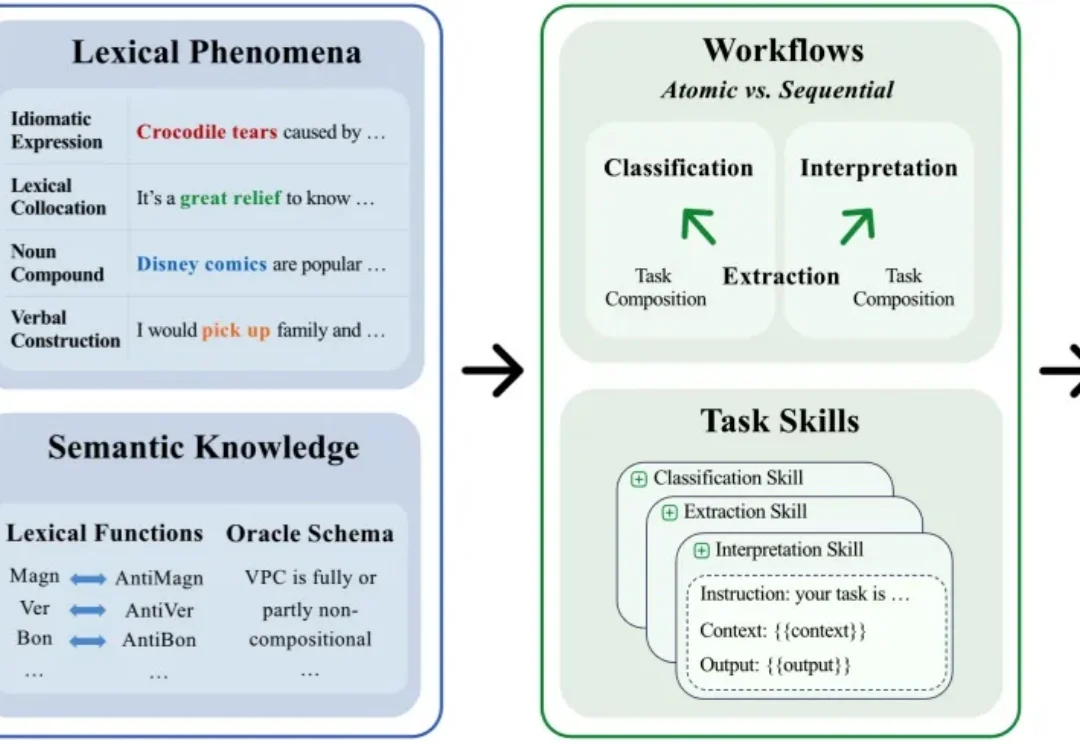
AI 的能力边界正在不断被刷新。从数学推理到代码生成,再到数字化白领,语言模型和语言智能体在诸多基准测试中已展现出超越人类专家的表现。一个看似顺理成章的判断早已成为共识:语言模型已经具备了扎实的语言理解和语义推理能力。然而,ACL 2026 Oral 的一项研究工作从一个更基础的层面重新审视了这个问题:语言模型真的理解(短语)语义吗?
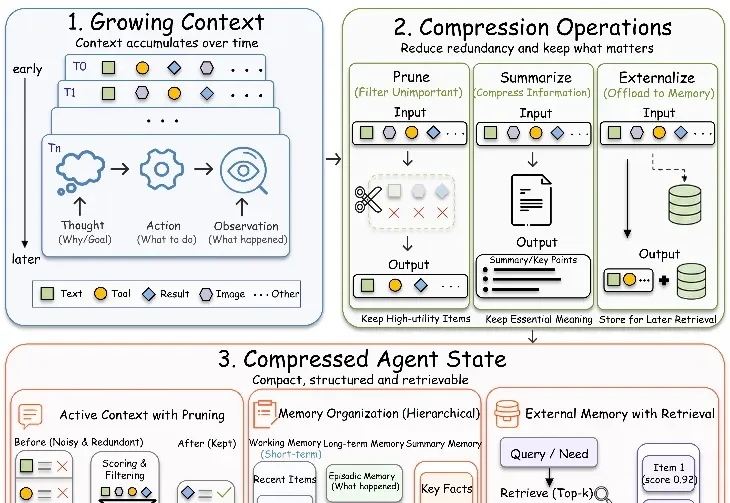
LLM Agent 做长任务时,真正让人头疼的往往不是模型不会推理,而是上下文开始失控:前几步还很清楚,后面就忘约束、丢状态、重复试错,最后把任务跑成事故现场。

随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。

过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。
想象一下,你问 AI 要一个饮食记录工具,它不再是回你一段文字建议,而是直接给你一个可以点击添加、统计热量的完整应用。人和 AI 的交互,正在从「读文字」走向「用应用」。
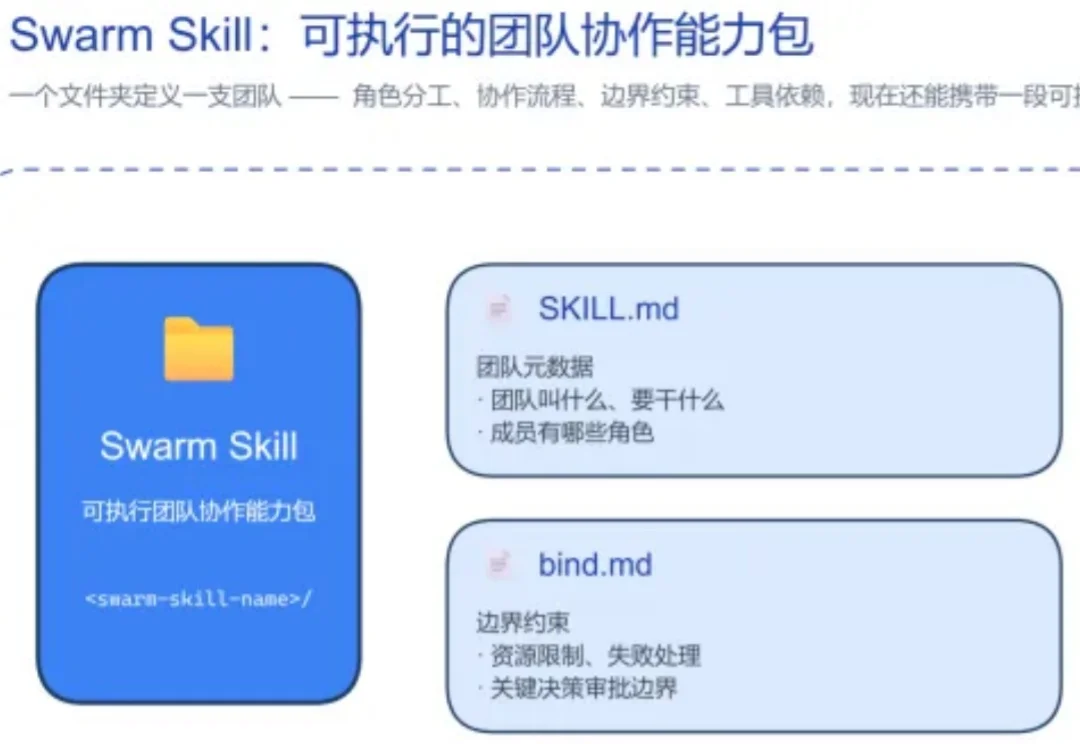
AI Agent 正在从 "单兵作战" 走向 "团队协作"—— 让多个 Agent 分工配合,去完成单个 Agent 难以独立扛下来的复杂任务,也是近期最受关注的方向之一。
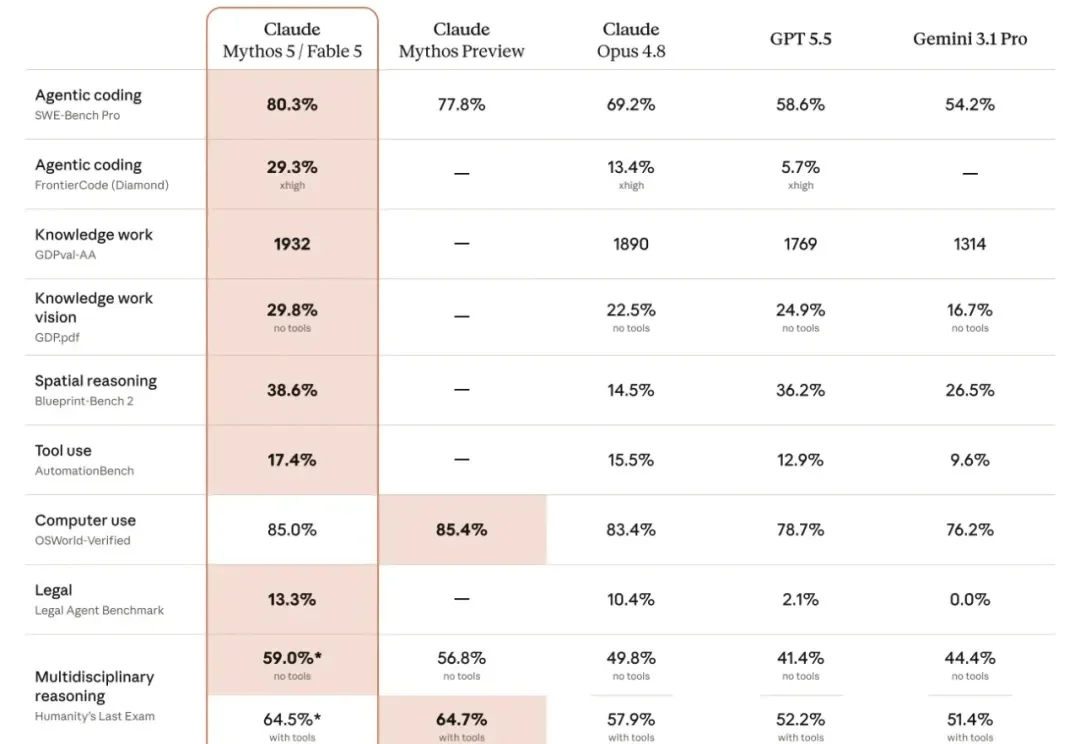
今天凌晨,Anthropic 发布新模型 Fable 5,毫无疑问的,也是当下的最强模型
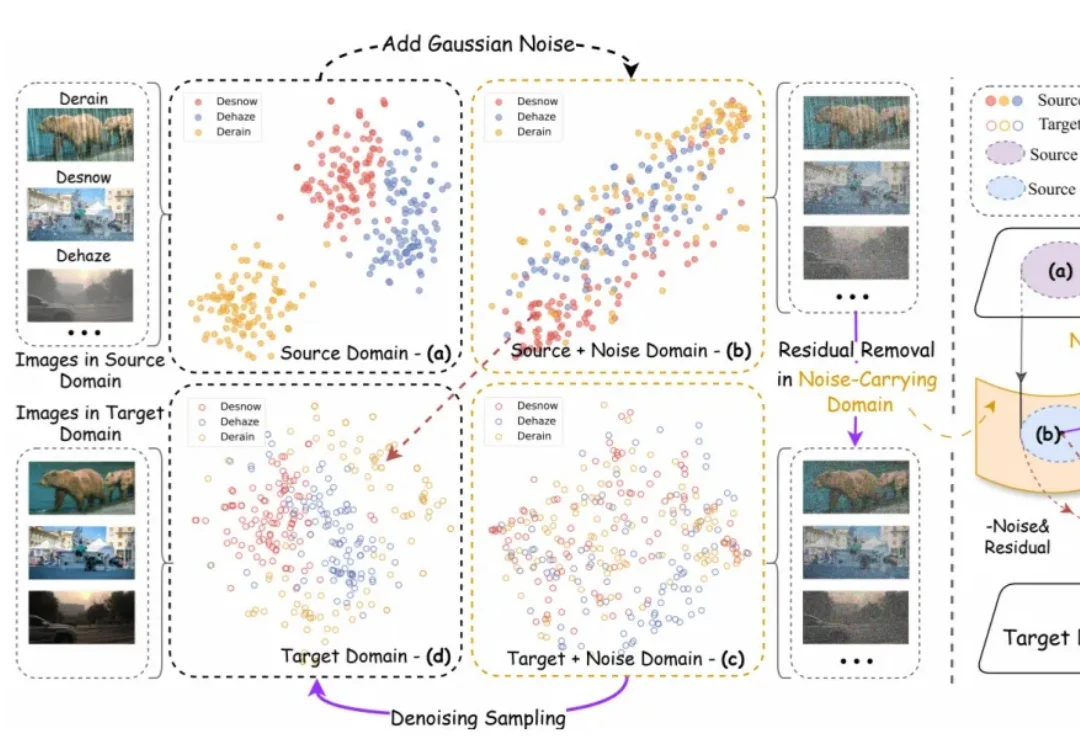
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。

具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
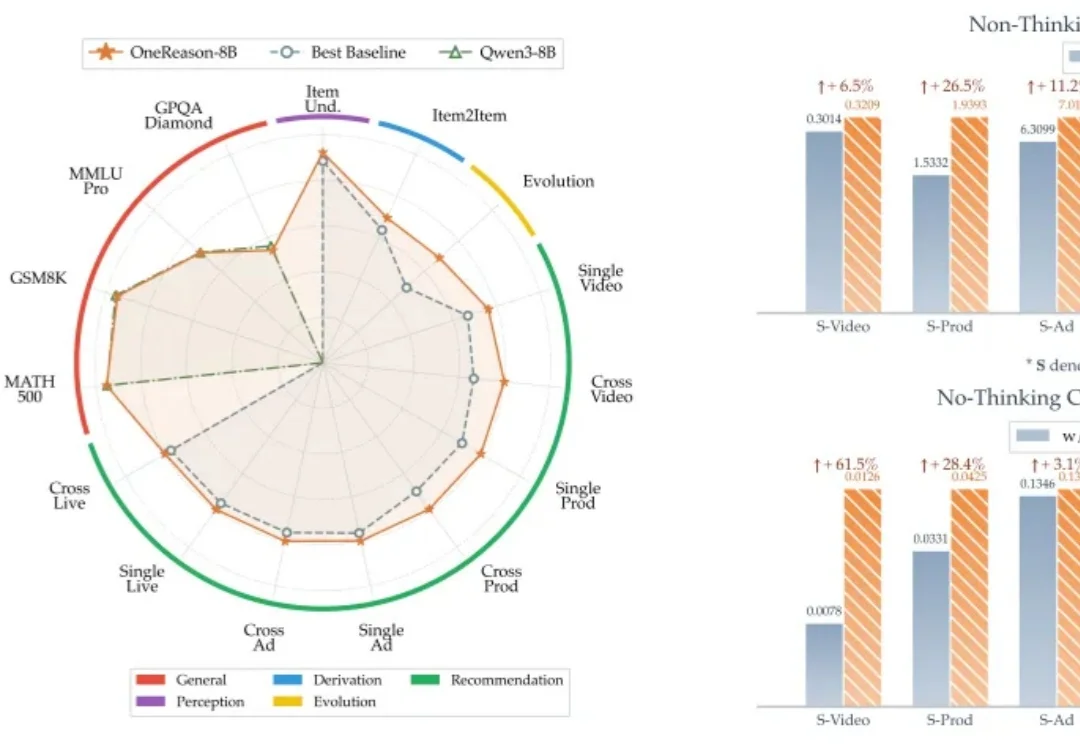
推荐系统的过去十年,本质是把 "用户 - 物料" 的统计共现挖到极致 —— 从协同过滤、深度模型,到生成式 OneRec 系列,每一代都在让 "记忆" 更精细、参数更大、序列更长,也让 Scaling 这件事在工业级推荐系统上跑通,持续释放算力红利。

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,
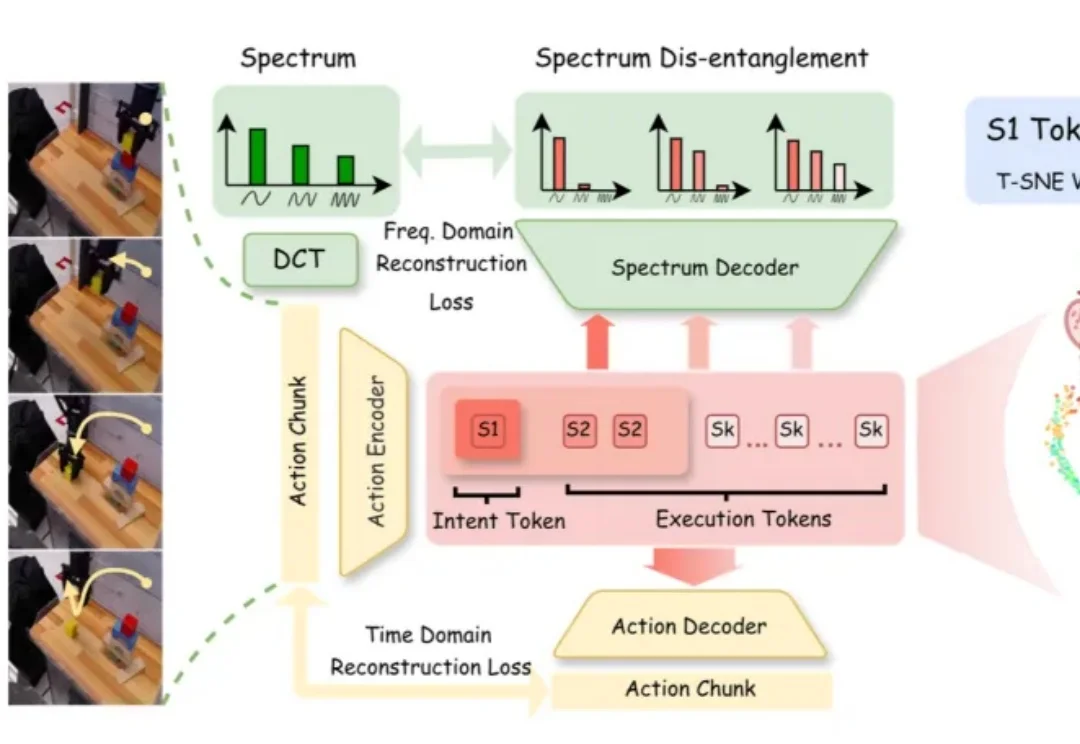
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。
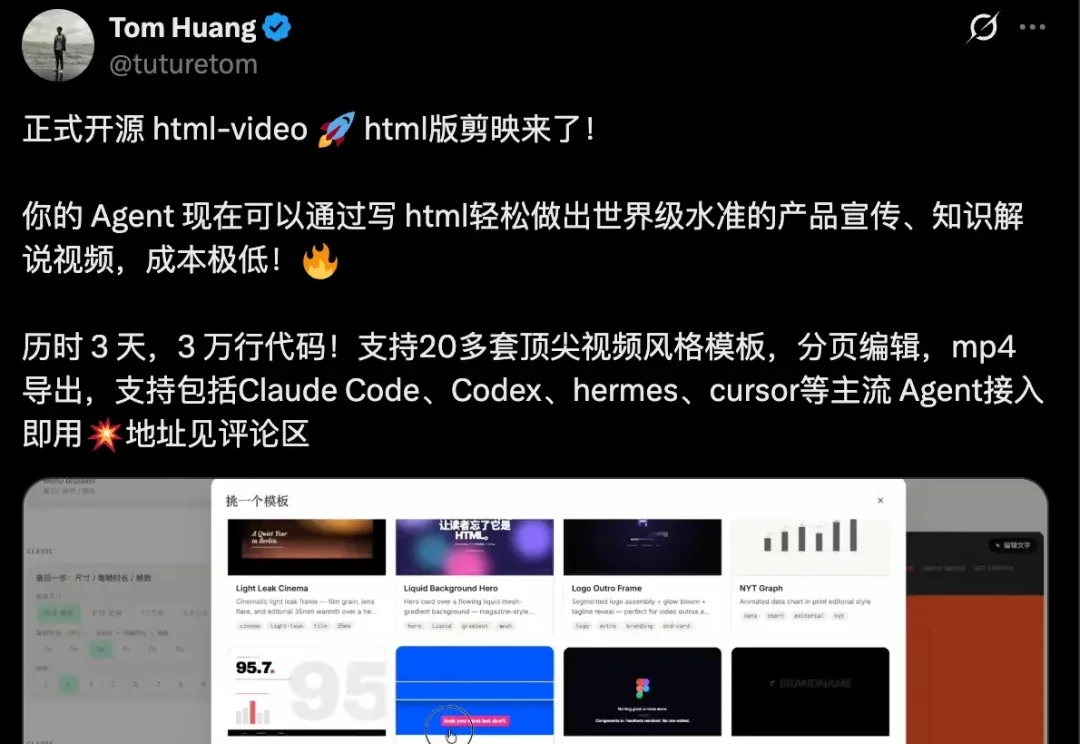
视频制作行业正在经历一场革命。

过去两年,大模型写代码已经不再新鲜。从代码补全到 GitHub issue 修复,从竞赛编程到仓库级软件工程,人们习惯用一个简单标准评估 coding agent:代码能不能写对?测试能不能通过?
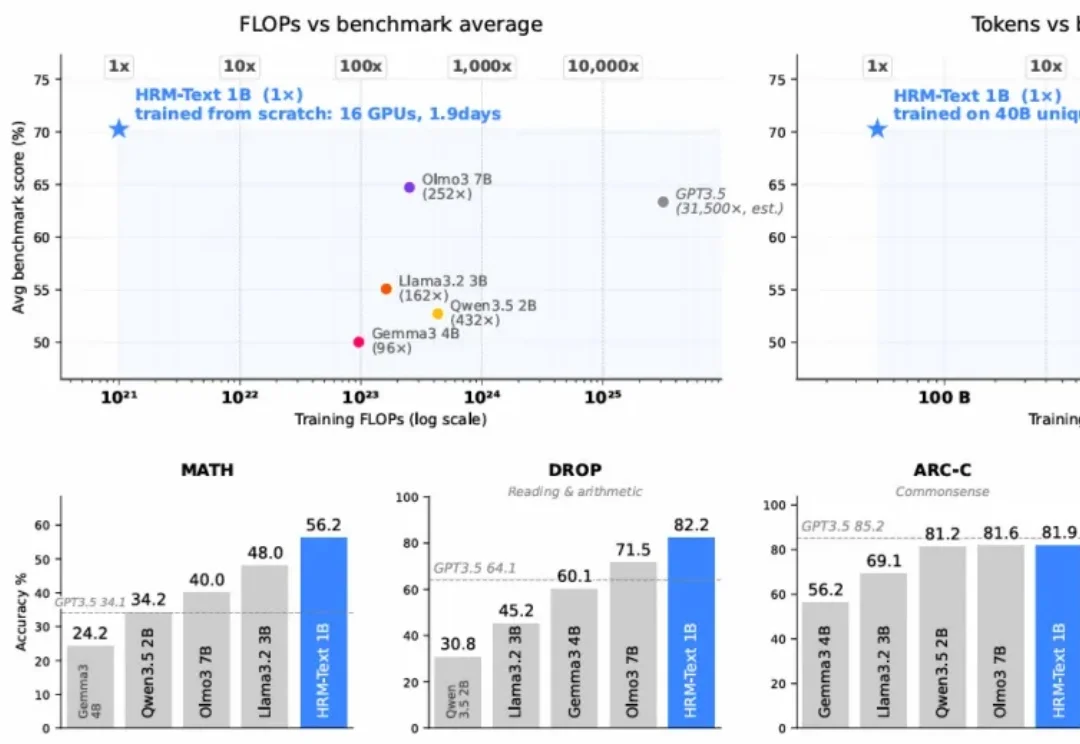
一个约 1B 参数的模型,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。训练成本约 1500 美元,16 块 H100 跑了不到两天。
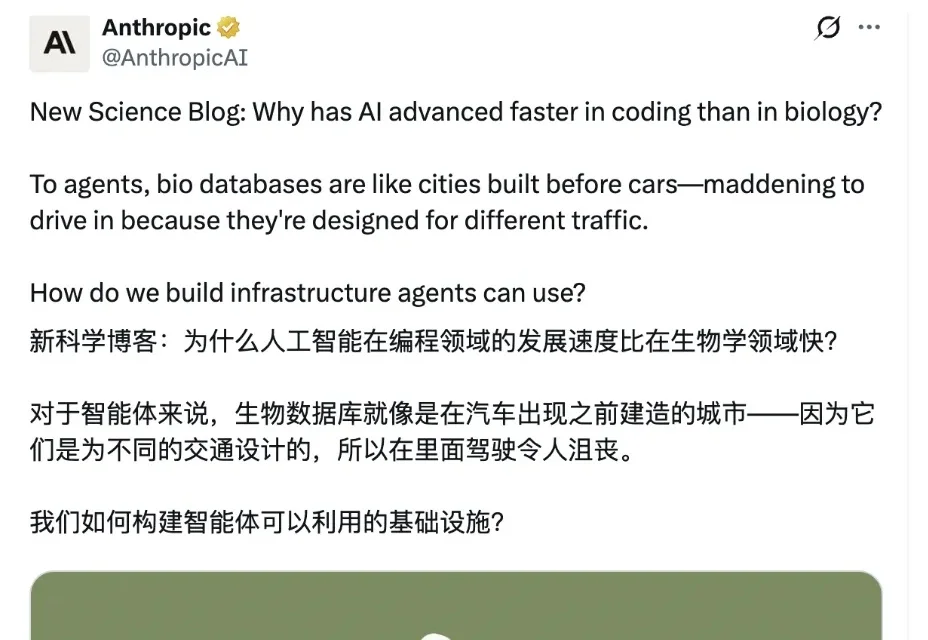
当前,Coding Agents 在软件工程领域一路高歌猛进,科学家们看到此场景,也不禁寄予厚望:AI 智能体何时能以同样的速度,帮人类攻克药物设计、病毒监控与生物学建模的重重难关?

Anthropic自家工程师早已基本不写代码了,却280美元一个任务,花钱请约1000名外部工程师,手把手教Claude Code写出好代码。喂养前沿模型的,终究还是人。