HALO,基于MCTS的层次化动态提示框架,让Agent总能找到最优路径 | 最新
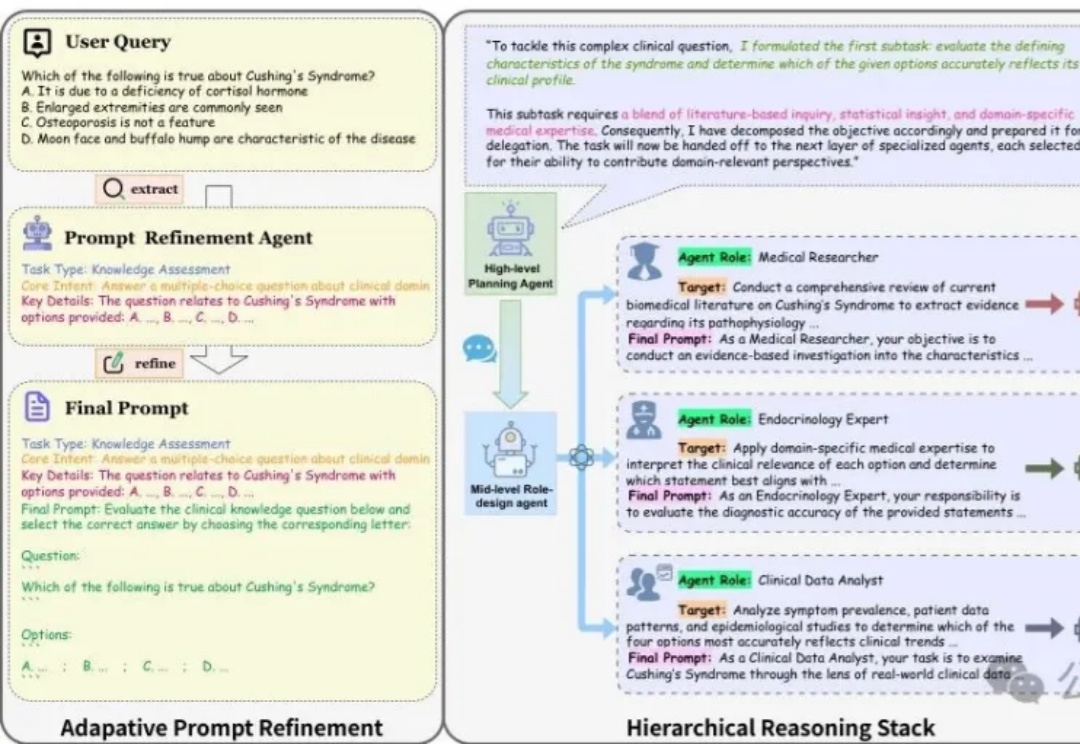
HALO,基于MCTS的层次化动态提示框架,让Agent总能找到最优路径 | 最新HALO框架通过三大创新机制重塑多Agent(MAS)协作方式:层次化推理架构克服了认知过载问题,让智能体各司其职;动态角色实例化能针对不同任务匹配专业智能体;基于MCTS的搜索引擎自动探索最优推理路径。它能将模糊的用户查询转化为专业提示,分解复杂任务并动态调整执行计划。
来自主题: AI技术研报
6667 点击 2025-05-22 09:28