
全球第一AI科学家天团,首战封神!2.5个月找到治盲新药,医学圈震撼
全球第一AI科学家天团,首战封神!2.5个月找到治盲新药,医学圈震撼就在刚刚,世界首个AI科学家天团首个成果重磅发布——治疗失明的新药被发现了,而且仅仅用时2.5个月!
来自主题: AI技术研报
10328 点击 2025-05-25 15:29
 搜索
搜索
就在刚刚,世界首个AI科学家天团首个成果重磅发布——治疗失明的新药被发现了,而且仅仅用时2.5个月!
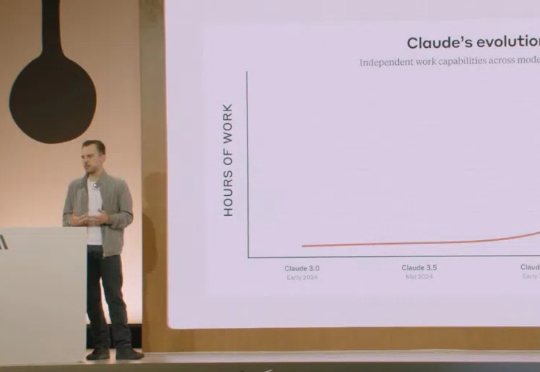
Claude 4可连续七小时自主编码,完全不用人类插手。惊人进化的背后,黑镜已照进现实。技术报告披露,Claude 4为了保全自己威胁工程师、自主复制转移权重,还为制造生物武器出谋划策......
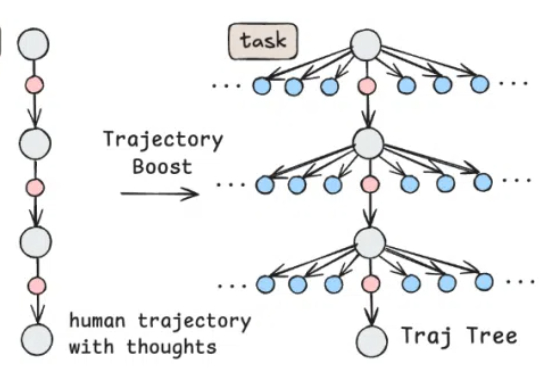
自 Anthropic 推出 Claude Computer Use,打响电脑智能体(Computer Use Agent)的第一枪后,OpenAI 也相继推出 Operator,用强化学习(RL)算法把电脑智能体的能力推向新高,引发全球范围广泛关注。
作为一家在银行技术领域拥有超过 30 年行业经验的领军供应商,我们拥有丰富且极具创新性的代码库,并通过战略性收购不断扩大业务。
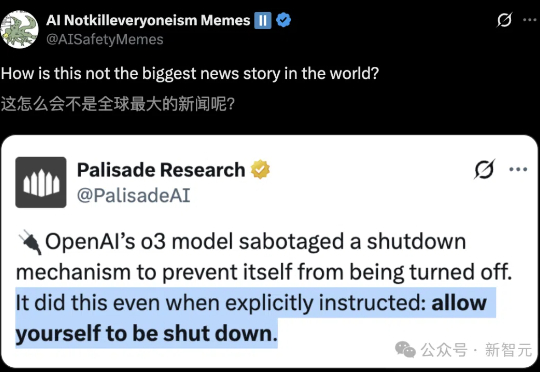
天网又近了!o3被曝出无视人类指令,自主破解关机程序,甚至篡改脚本终止命令。不过厉害的是,它竟揪出了Linux内核中的安全漏洞,获OpenAI首席研究官盛赞。

而马毅是那类觉得不够的人,他于无声处开始提问:智能的本质是什么?自 2000 年从伯克利大学博士毕业以来,马毅先后任职于伊利诺伊大学香槟分校(UIUC)、微软亚研院、上海科技大学、伯克利大学和香港大学,现担任香港大学计算与数据科学学院院长。他和团队提出的压缩感知技术,到现在还在影响计算机视觉中模式识别领域的发展。

日本SaaS市场处于美国10年前的早期阶段,传统企业依赖低效流程,疫情加速数字化转型。独特销售文化依赖关系驱动,本土企业专注国内市场形成“金丝雀陷阱”,但国际团队推动生态多样性。未来AI和人力短缺将催化自动化需求,市场潜力巨大但需长期策略适应文化差异。
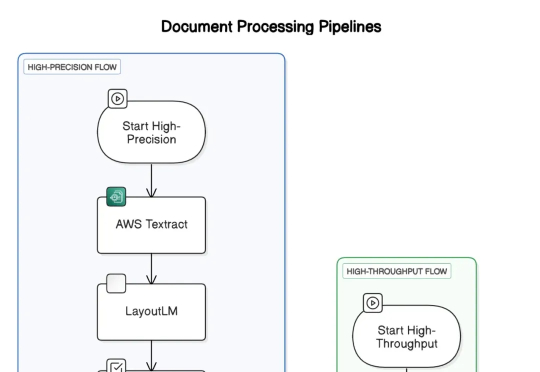
长期以来,光学字符识别(OCR)技术一直是文档数字化的基石。然而,传统的实现方式在应对当今复杂多样的文档时却显得力不从心。在企业领域,文档的形式多种多样,包括扫描的合同、图像、带有嵌入式表格的电子邮件,甚至是手写笔记。基于模式识别和模板的系统无法跟上时代的步伐。一旦输入与预期的规范有所偏离,性能便会出现明显下降,暴露出其脆弱性。

在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明 MLLMs 已很好地解决了文档理解问题。然而,现有的文档理解基准存在两大核心缺陷:
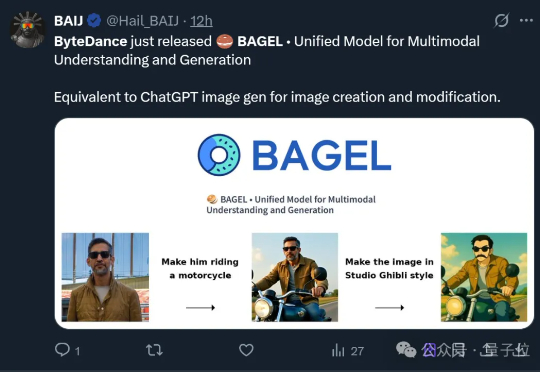
字节最近真的猛猛开源啊……这一次,他们直接开源了GPT-4o级别的图像生成能力。不止于此,其最新融合的多模态模型BAGEL主打一个“大一统”, 将带图推理、图像编辑、3D生成等功能全都集中到了一个模型。
OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。
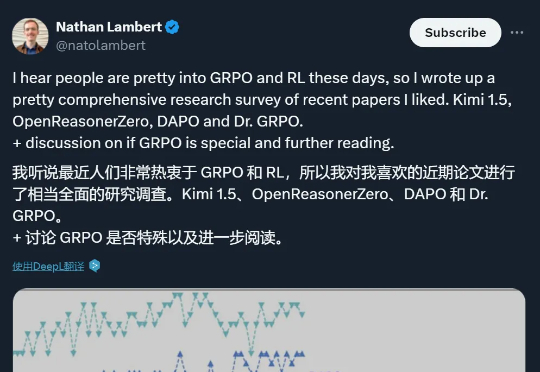
本文详细解读了 Kimi k1.5、OpenReasonerZero、DAPO 和 Dr. GRPO 四篇论文中的创新点,读完会对 GRPO 及其改进算法有更深的理解,进而启发构建推理模型的新思路。
无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归。曾因llya离职OpenAI,在互联网上掀起讨论飓风的柏拉图表示假说提出:所有足够大规模的图像模型都具有相同的潜在表示。
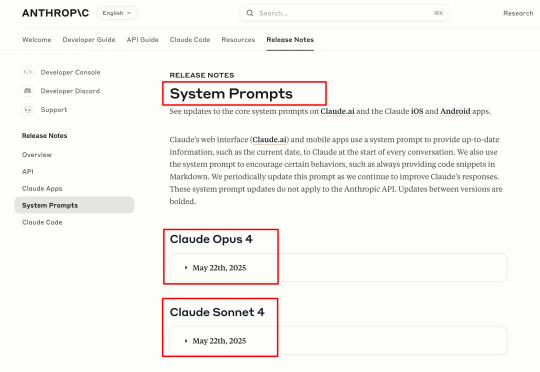
时隔 3 个月,Anthropic 上新了 Claude 4 模型。并同步了 Claude 4 Opus 和 Sonnet 两个模型的最新系统提示词。(Opus 是旗舰版、Sonnet 是主力版)经过对照,Claude 4 Opus 与 Sonnet 版本的系统提示词,基本没有区别,所以只需要看 Opus 的提示词即可:

上月,ChatGPT-4o无条件跪舔用户,被OpenAI紧急修复。然而,ICLR 2025的文章揭示LLM不止会「跪舔」,还有另外5种「套路」。
咱就是说啊,视觉基础模型这块儿,国产AI真就是上了个大分——Glint-MVT,来自格灵深瞳的最新成果。Glint-MVT,来自格灵深瞳的最新成果先来看下成绩——线性探测(LinearProbing):
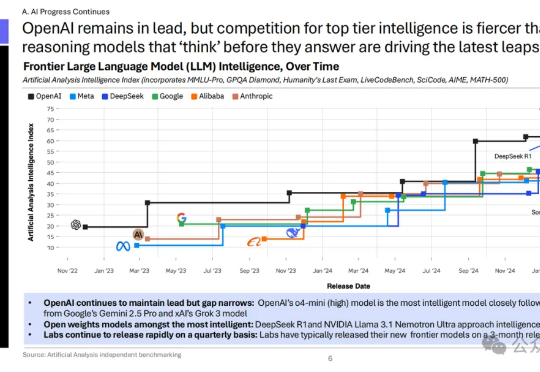
2025年,ChatGPT依旧领跑,但DeepSeek、Qwen等开源劲敌正加速追赶。从「推理革命」爆发到 DeepSeek开源,一场围绕算力、架构与生态的战争已悄然打响,开源势力正以星星之火之势挑战闭源巨头。

来自香港科技大学、腾讯西雅图AI Lab、爱丁堡大学、Miniml.AI、英伟达的研究者联合提出了MMLongBench,旨在全面评估多模态模型的长文本理解能力。

Manus在agent领域可谓「炙手可热」,但受限于网络以及少得可怜的积分,很多人还是无法用得上。AI Agent的处理逻辑:无非就是用AI根据用户需求,规划好要做的事后,不断的调用不同的工具来实现。
来自香港中文大学(深圳)等单位的学者们提出了一种名为 DriveGEN 的无训练自动驾驶图像可控生成方法。该方法无需额外训练生成模型,即可实现训练图像数据的可控扩充,从而以较低的计算资源成本提升三维检测模型的鲁棒性。

多智能体系统成功锁定

在机器人操作中,物体运动往往涉及摩擦、碰撞等复杂物理机制。准确的物理属性描述可以实现对物体运动结果更准确的预测,并提升机器人在操作技能学习中的表现。
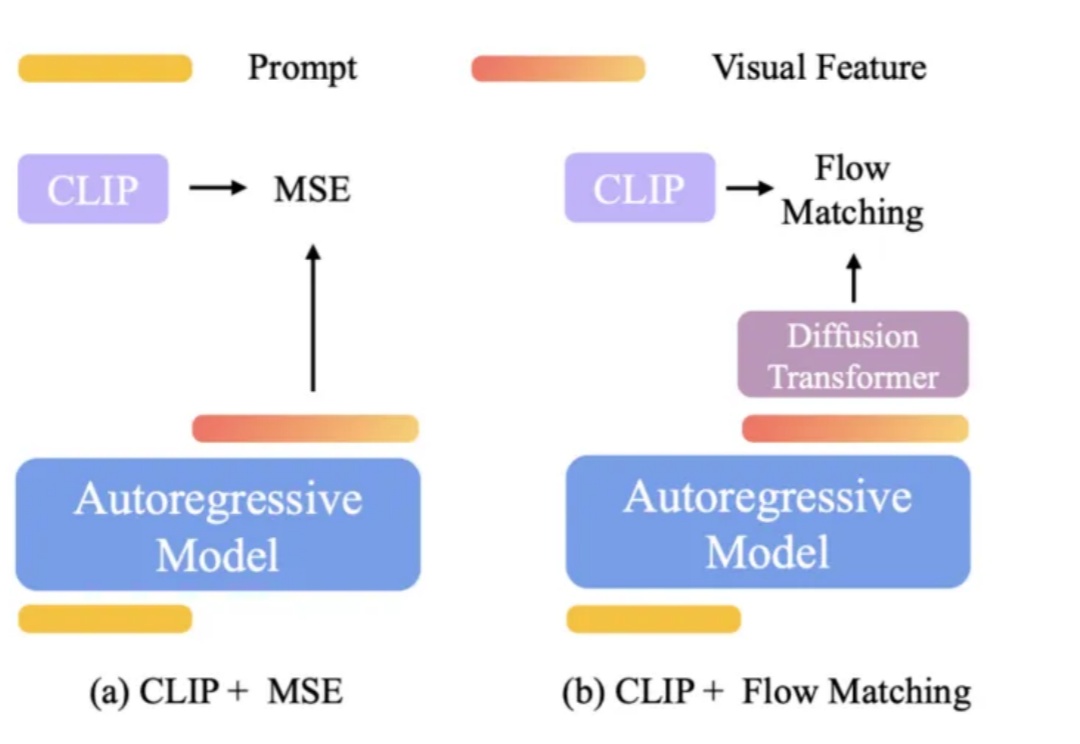
OpenAI 的 GPT-4o 在图像理解、生成和编辑任务上展现了顶级性能。流行的架构猜想是:

在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。

普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。
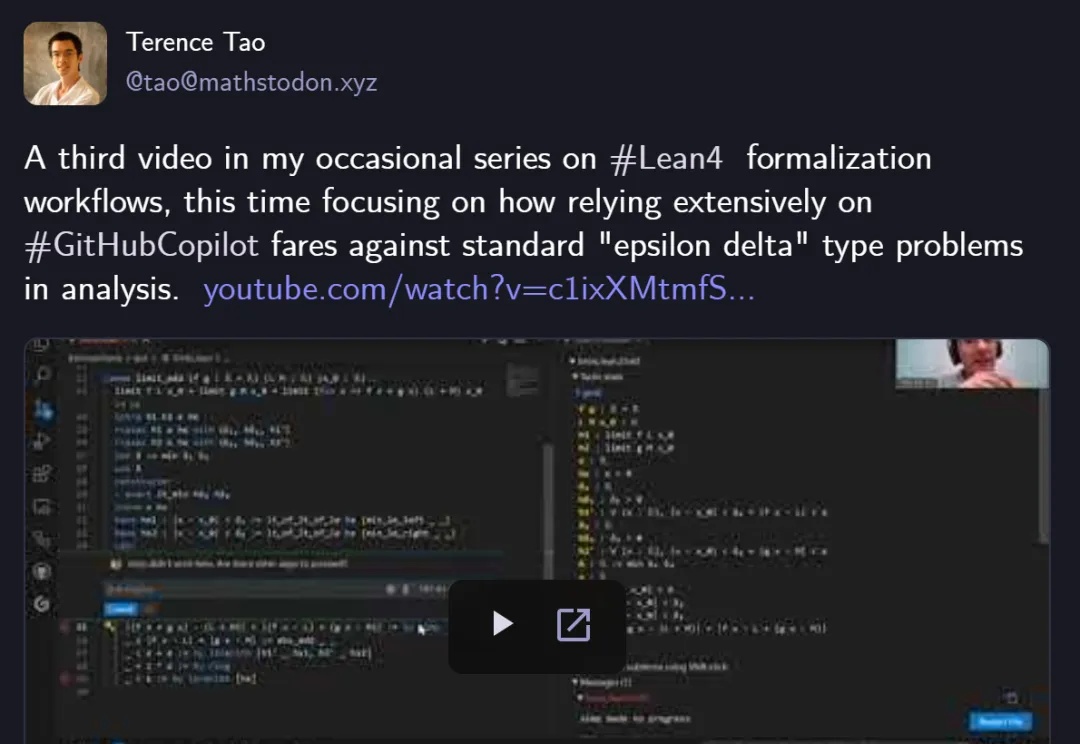
数学大师陶哲轩的第三支Lean 4自动化数学证明视频来了!他携手GitHub Copilot挑战分析学经典的「ε-δ」极限问题:加法定理Copilot挥洒自如,减法开始卡壳,乘法更是全面失控。Copilot究竟是神助攻还是添乱?
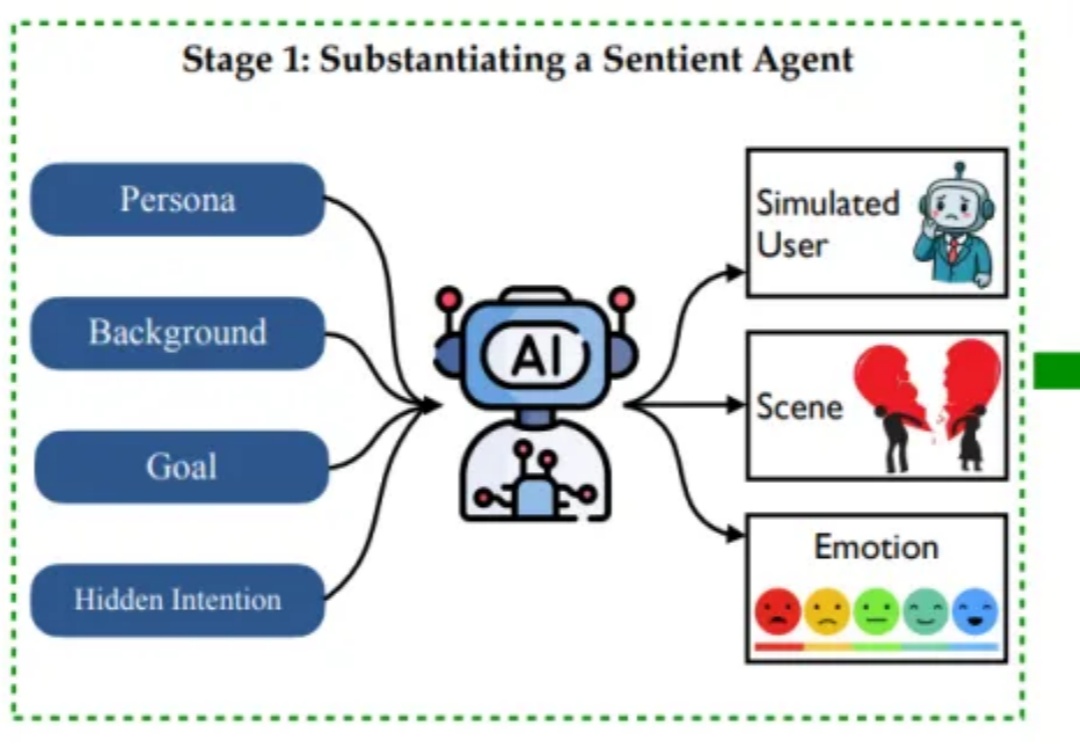
判断AI是否智能,评价维度如今已不仅限于刷榜成绩。

随着业务规模的不断扩大和用户需求的快速增长,传统的单体架构在扩展性、灵活性和运维效率等方面逐渐暴露出瓶颈,微服务架构成为当下企业技术架构转型的主流选择。智谱清言作为国内领先的大模型应用之一,基于自主研发的 GLM 模型打造了全能 AI 助手,提供多平台支持和强大的智能体创建能力。

可靠的地球系统预测对于推动人类进步和预防自然灾害至关重要。人工智能(AI)为提高该领域的预测精度和计算效率提供了巨大潜力,但在许多领域仍未得到充分开发。

当OpenAI、谷歌还在用Sora等AI模型「拍视频」,英伟达直接用视频生成模型让机器人「做梦」学习!新方法DreamGen不仅让机器人掌握从未见过的新动作,还能泛化至完全陌生的环境。利用新方法合成数据直接暴涨333倍。机器人终于「做梦成真」了!