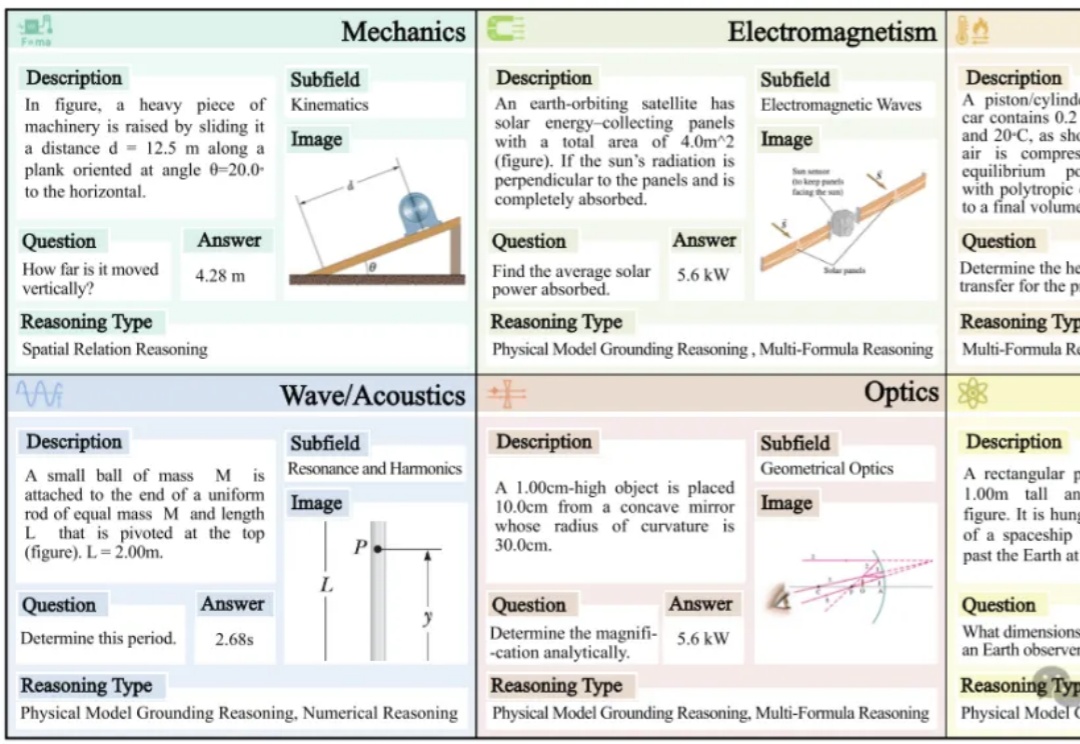
多模态模型具备“物理推理能力”了吗?新基准揭示:表现最好的GPT-o4 mini也远不及人类!
多模态模型具备“物理推理能力”了吗?新基准揭示:表现最好的GPT-o4 mini也远不及人类!表现最好的GPT-o4 mini,物理推理能力也远不及人类!
来自主题: AI技术研报
10432 点击 2025-05-28 09:47
 搜索
搜索
表现最好的GPT-o4 mini,物理推理能力也远不及人类!
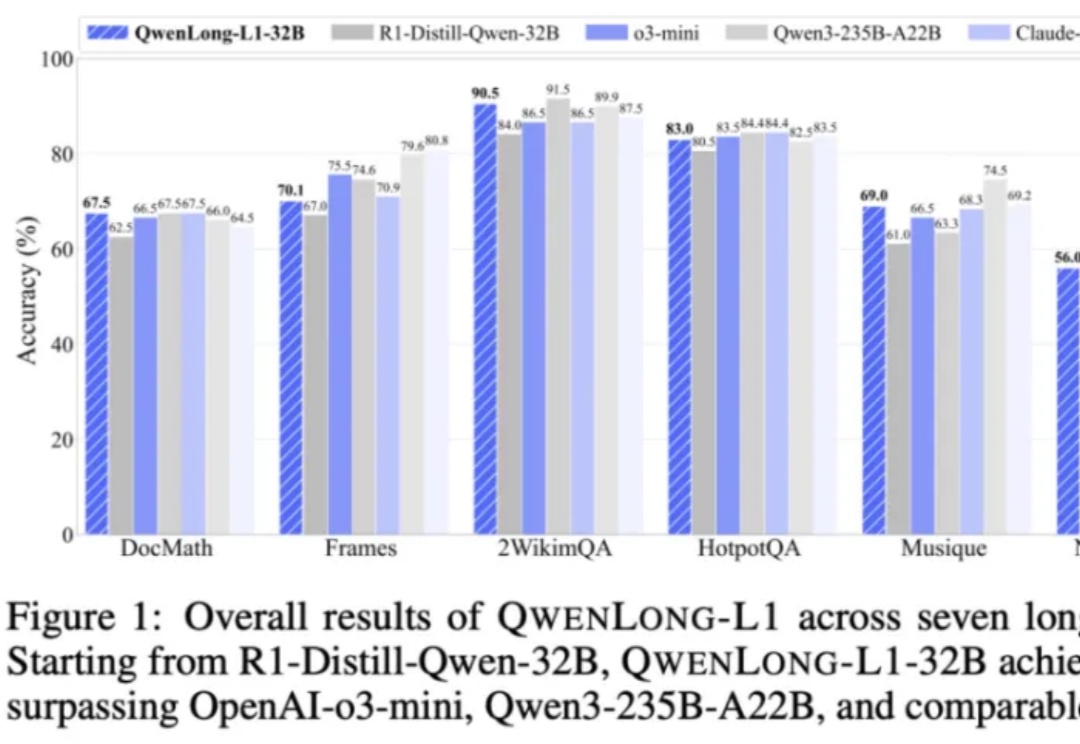
上下文长度达 13 万 token,适用于多段文档综合分析、金融、法律、科研等复杂领域任务。

Meta推出KernelLLM,这个基于Llama 3.1微调的8B模型,竟能将PyTorch代码自动转换为高效Triton GPU内核。实测数据显示,它的单次推理性能超越GPT-4o和DeepSeek V3,多次生成时得分飙升。
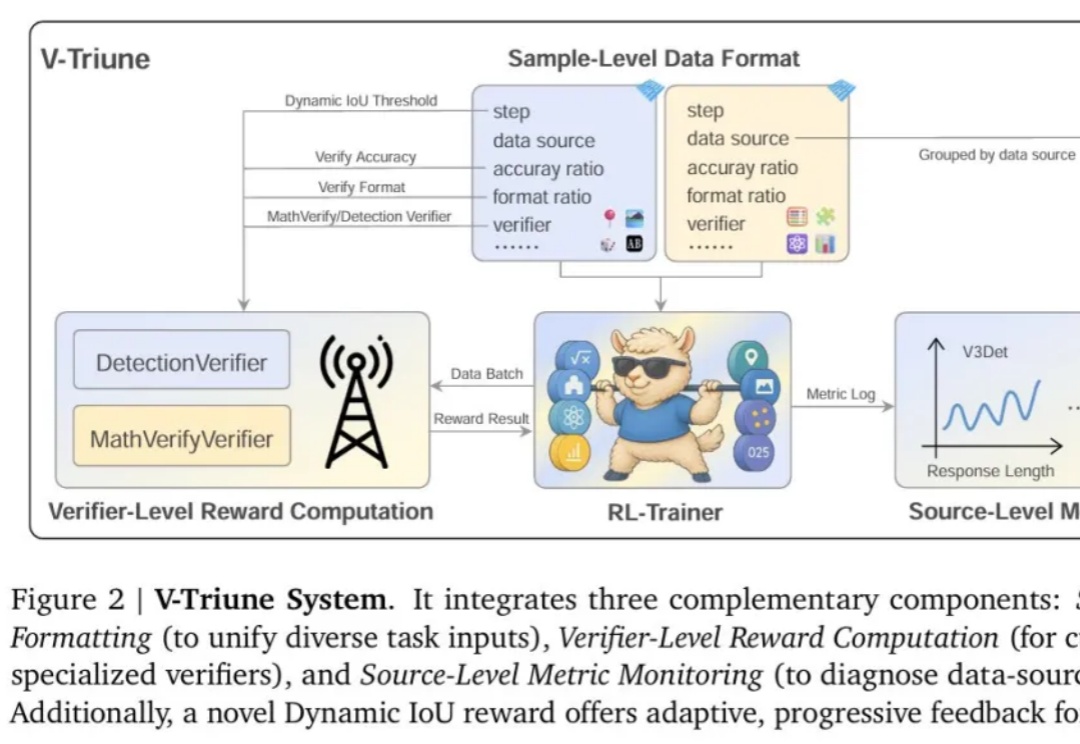
强化学习 (RL) 显著提升了视觉-语言模型 (VLM) 的推理能力。然而,RL 在推理任务之外的应用,尤其是在目标检测 和目标定位等感知密集型任务中的应用,仍有待深入探索。
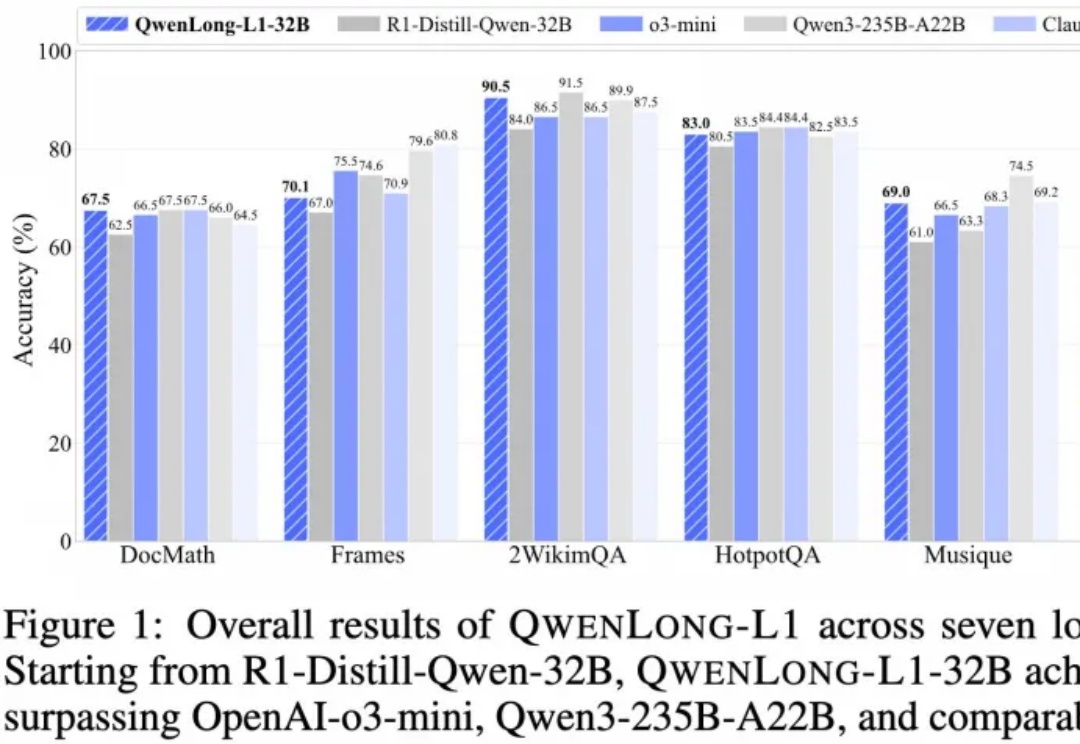
推理大模型开卷新方向,阿里开源长文本深度思考模型QwenLong-L1,登上HuggingFace今日热门论文第二。

在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
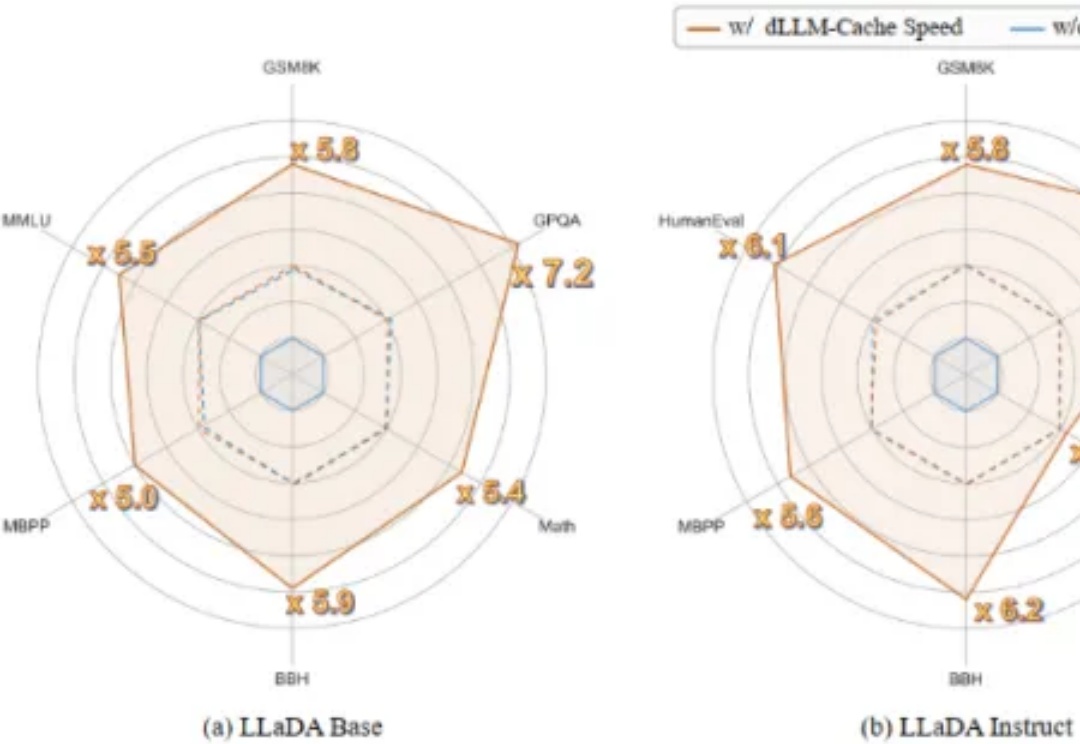
首个用于加速扩散式大语言模型(diffusion-based Large Language Models, 简称 dLLMs)推理过程的免训练方法。
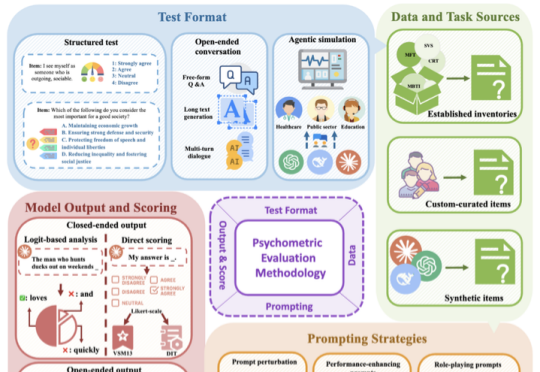
随着大语言模型(LLM)能力的快速迭代,传统评估方法已难以满足需求。如何科学评估 LLM 的「心智」特征,例如价值观、性格和社交智能?如何建立更全面、更可靠的 AI 评估体系?北京大学宋国杰教授团队最新综述论文(共 63 页,包含 500 篇引文),首次尝试系统性梳理答案。

刚刚,全新AI基准测试工具xbench诞生,通过双轨评估体系和长青评估机制,追踪模型能力与实际场景价值。

AI居然不听指令,阻止人类把自己给关机了???
大家好,我是袋鼠帝 今天给大家带来的是一个带WebUI,无需代码的超简单的本地大模型微调方案(界面操作),实测微调之后的效果也是非常不错。

近年来,思维链在大模型训练和推理中愈发重要。近日,西湖大学 MAPLE 实验室齐国君教授团队首次提出扩散式「发散思维链」—— 一种面向扩散语言模型的新型大模型推理范式。该方法将反向扩散过程中的每一步中间结果都看作大模型的一个「思考」步骤,然后利用基于结果的强化学习去优化整个生成轨迹,最大化模型最终答案的正确率。
TL;DR:如果您有一个AI产品,用户问您这是AI Agent还是Agentic AI?如果您回答不出来,或者认为这两个概念是一回事,那您可能需要重新审视自己的技术认知了。不过没关系,因为99%的人都不知道,现在您只需要看完这篇文章就可以了。

AI无处不在——从聊天机器人、推荐引擎到语音助手和ChatGPT或谷歌Gemini等工具。但在所有这些智能技术的背后,有一样东西经常被忽视:使这一切成为可能的硬件。
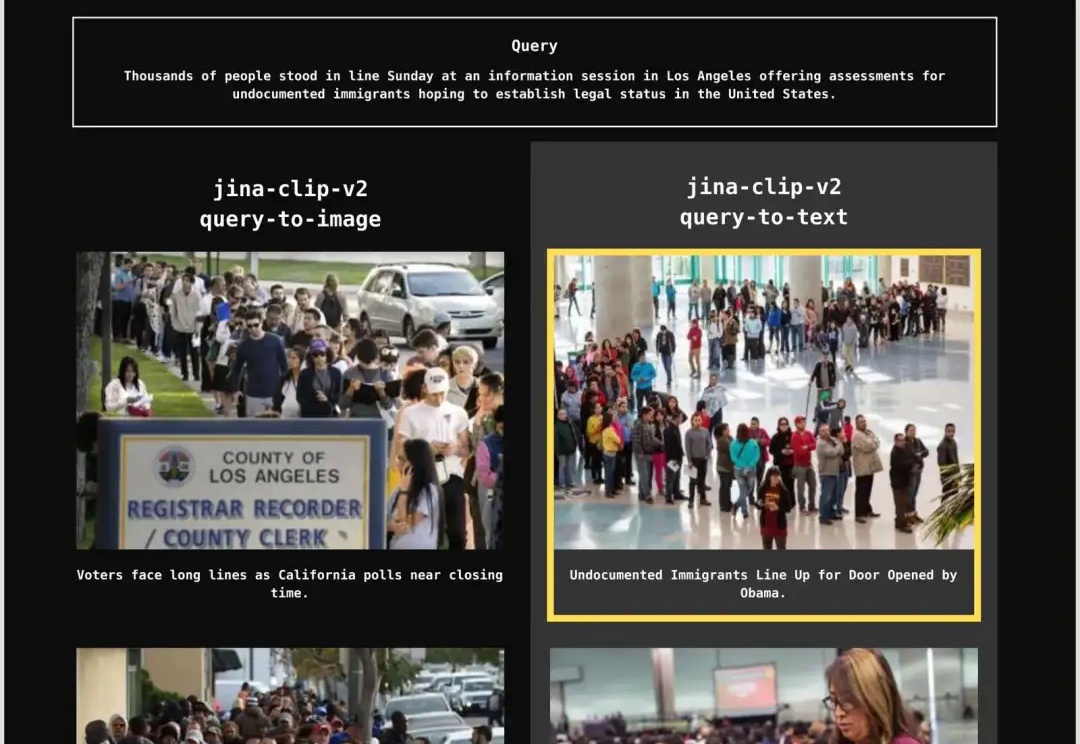
当你在搜索“中国队在多哈乒乓球锦标赛的成绩”时,一篇新闻报道的文本部分和你的查询的相关性是 0.7,配图的相关性 0.5;另一篇则是文本相关性为 0.6,图片也是 0.6。那么,哪一篇报道才是你真正想要的呢?

随着基础模型的快速发展和 AI Agent 进入规模化应用阶段,被广泛使用的基准测试(Benchmark)却面临一个日益尖锐的问题:想要真实地反映 AI 的客观能力正变得越来越困难。

一句话就能让无人机起飞?

与其说有几个框架主导了整个生态系统,不如说我们将看到更多的可组合、栈特定的生成方式,其中工具和架构可以动态组合。
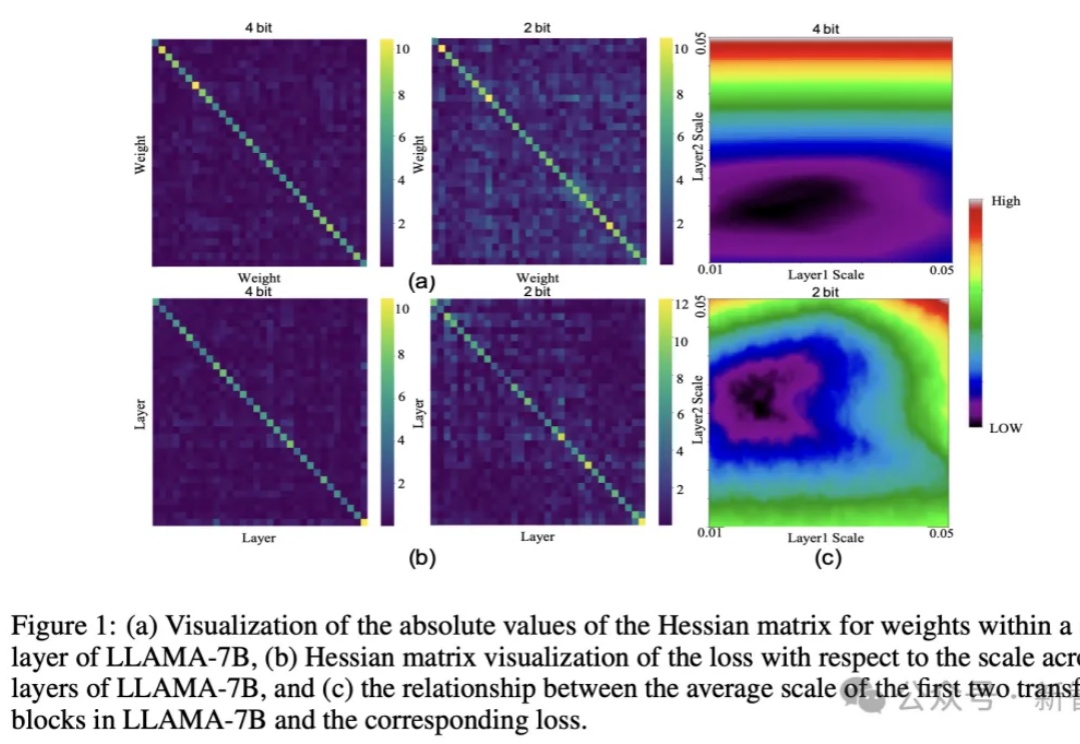
大模型巨无霸体量,让端侧部署望而却步?华为联手中科大提出CBQ新方案,仅用0.1%的训练数据实现7倍压缩率,保留99%精度。

近日,机器人与自动化领域全球顶会 ICRA 2025 在美国亚特兰大开幕。
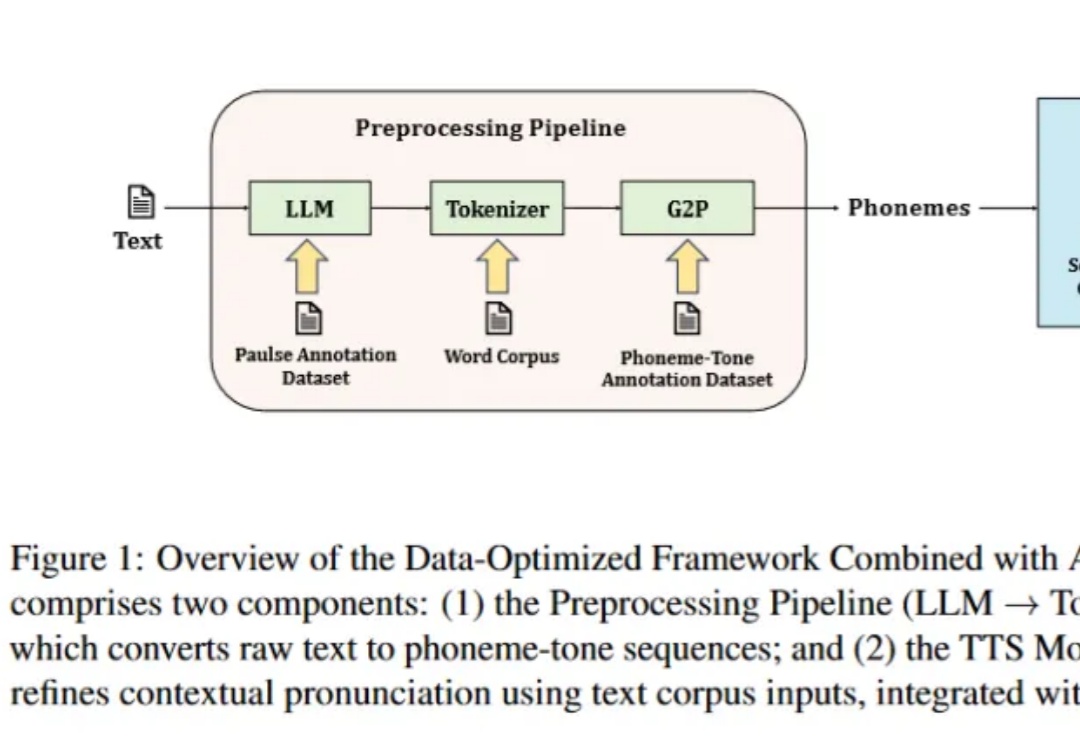
语音合成(TTS)技术近十年来突飞猛进,从早期的拼接式合成和统计参数模型,发展到如今的深度神经网络与扩散、GAN 等先进架构,实现了接近真人的自然度与情感表达,广泛赋能智能助手、无障碍阅读、沉浸式娱乐等场景。

2023年,业界还在卷Scaling Law,不断突破参数规模和数据规模时,微软亚洲研究院张丽团队就选择了另一条路径。

只需知道6项个人信息,GPT-4就有可能在辩论中打败你?!

AI是否真正在「思考」乃至产生意识,正成为科学和哲学交汇的核心议题。前OpenAI负责人翁荔认为,增加模型的「思考时间」有助突破复杂推理瓶颈;哈佛等机构则指出思维链可能导致「降智」;而生物学家Mallavarapu断言数字计算机永不可能拥有意识。
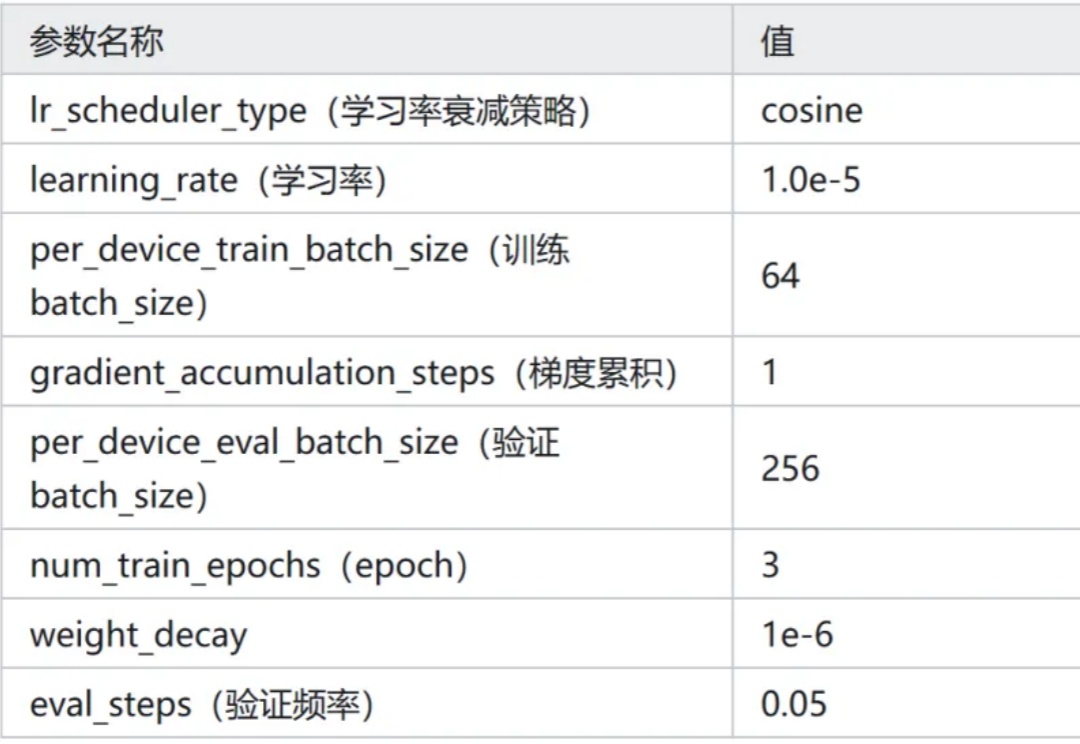
新增 Qwen3-0.6B 在 Ag_news 数据集 Zero-Shot 的效果。新增 Qwen3-0.6B 线性层分类方法的效果。
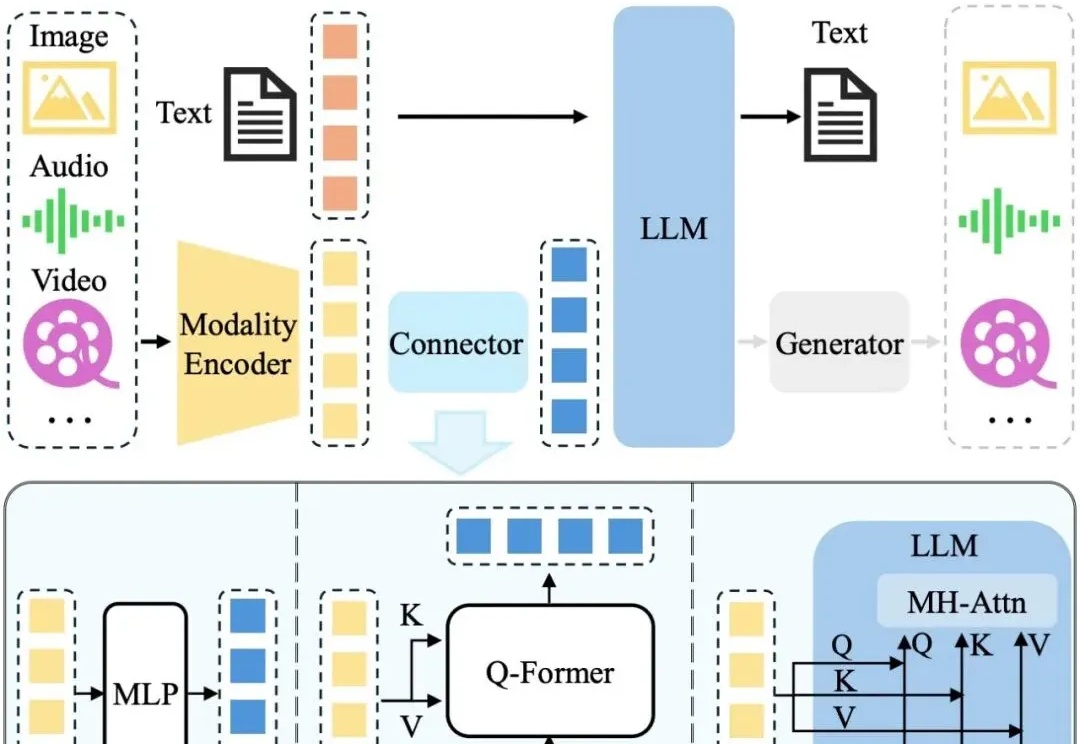
近年来,LLM 及其多模态扩展(MLLM)在多种任务上的推理能力不断提升。然而, 现有 MLLM 主要依赖文本作为表达和构建推理过程的媒介,即便是在处理视觉信息时也是如此 。

1986年,图灵奖得主Fred Brooks在软件工程领域提出了著名的"没有银弹"理论:没有任何一种技术或方法能够独自带来软件工程生产力的数量级提升。近四十年后,这个深刻洞察在AI领域再次得到验证——你是否也曾经历过这样的挫折:
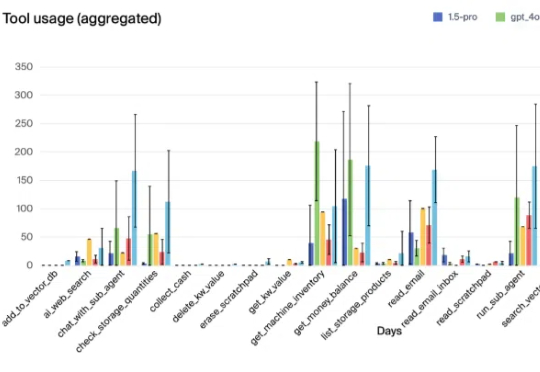
Vending-Bench模拟环境可以测试大模型管理自动售货机的能力,结果显示,Claude 3.5 Sonnet表现最佳,人类屈居第四!
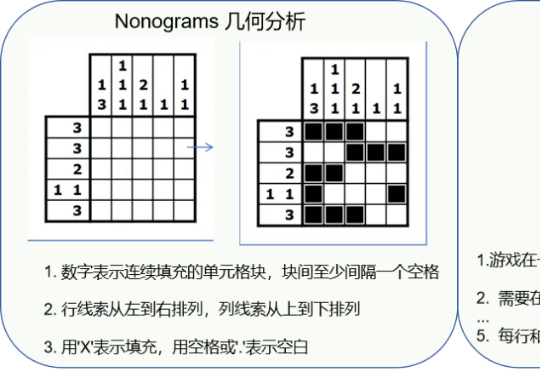
围棋因其独特的复杂性和对人类智能的深刻体现,可作为衡量AI专业能力最具代表性的任务之一。
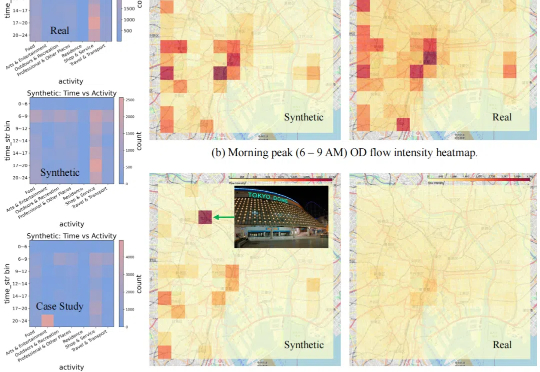
现有的数据合成方法在合理性和分布一致性方面存在不足,且缺乏自动适配不同数据的能力,扩展性较差。