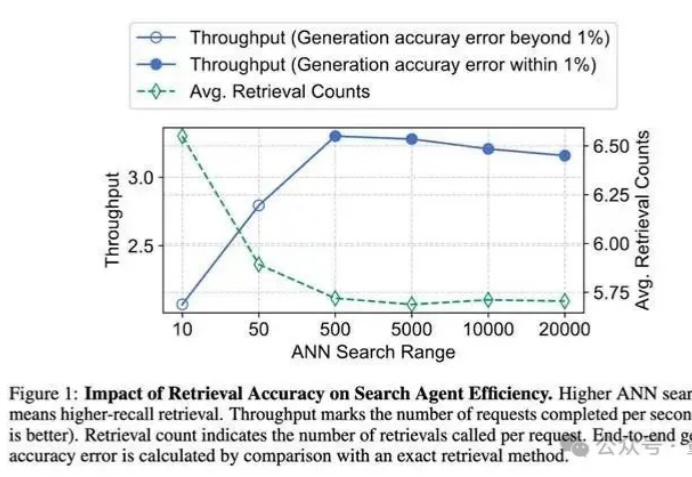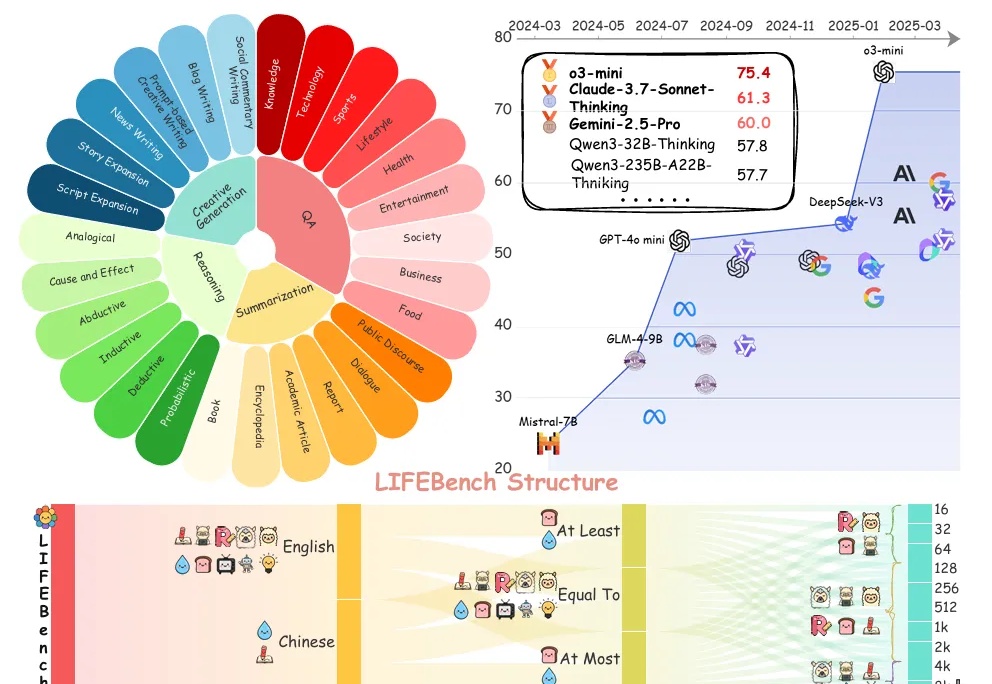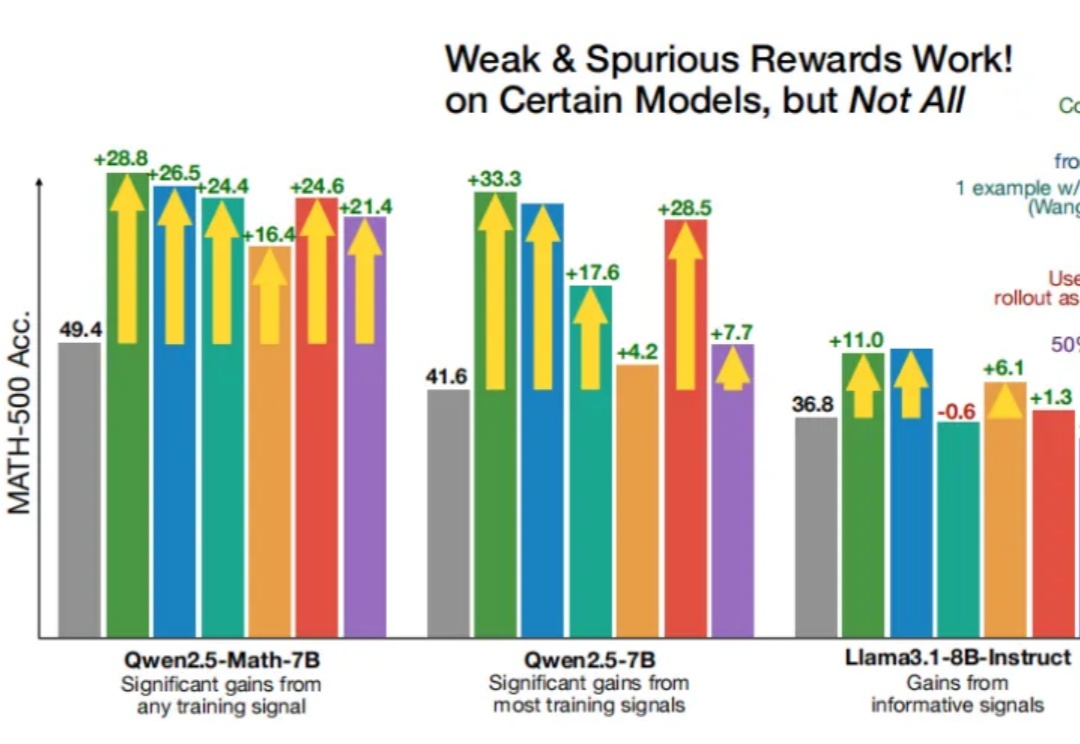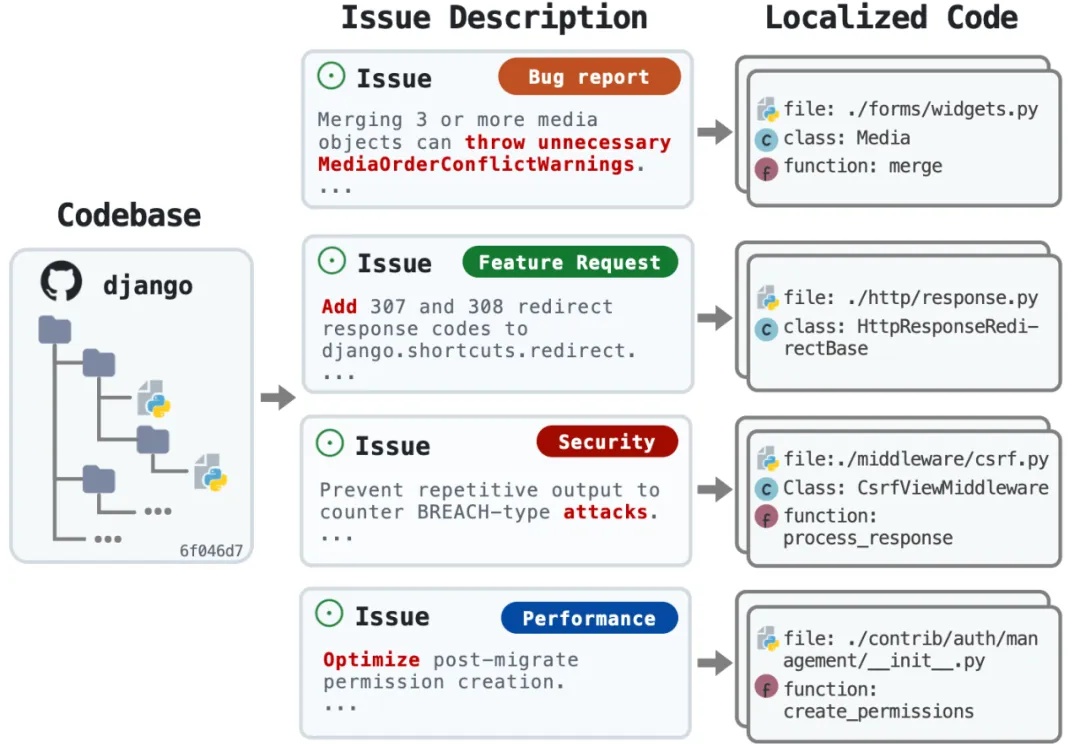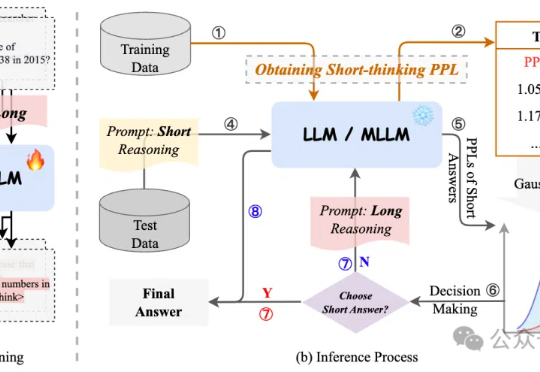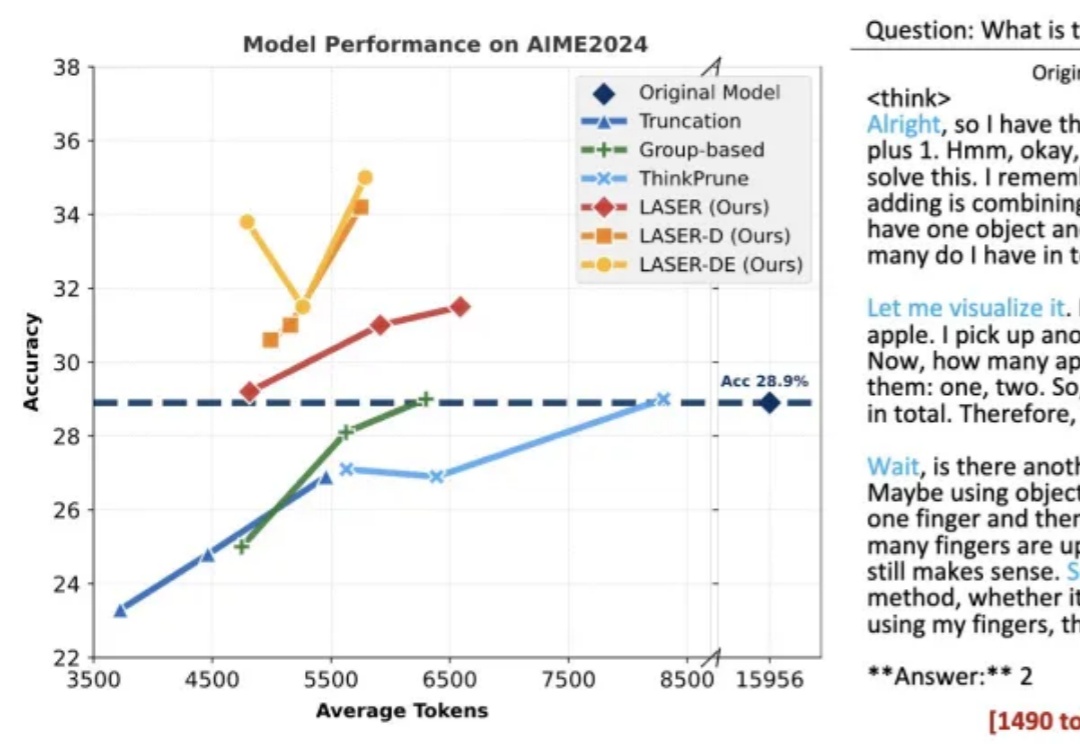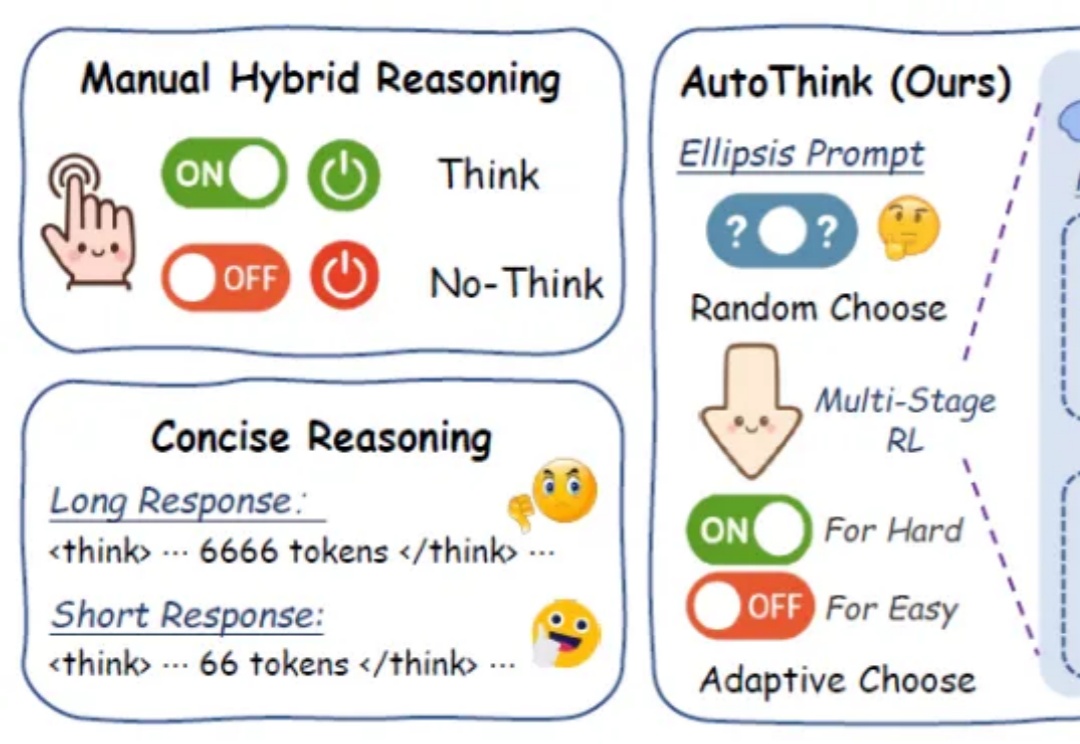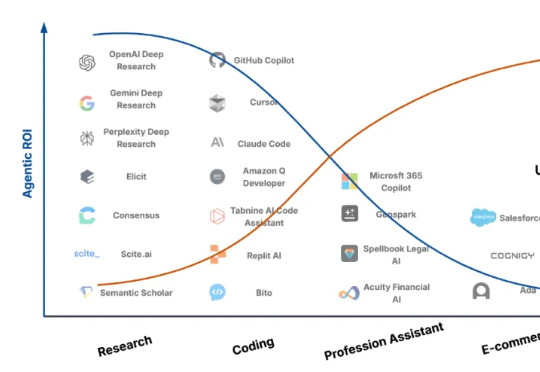
大模型智能体如何突破规模化应用瓶颈,核心在于Agentic ROI
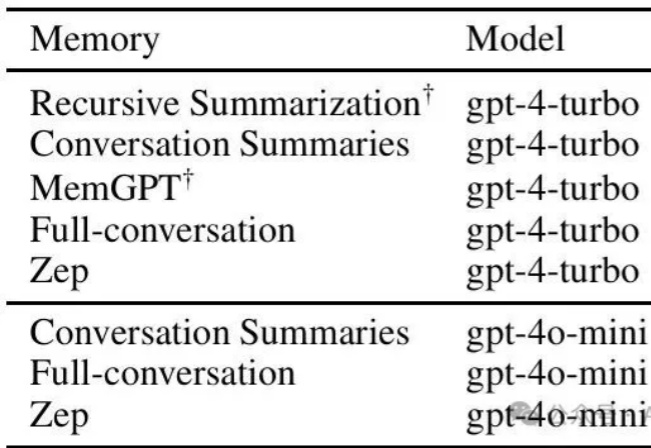
大模型智能体如何突破规模化应用瓶颈,核心在于Agentic ROI上海交通大学联合中科大在本文中指出:现阶段大模型智能体的主要障碍不在于模型能力不足,而在于其「Agentic ROI」尚未达到实用化门槛。研究团队提出 Agentic ROI(Agentic Return on Investment)这一核心指标,用于衡量一个大模型智能体在真实使用场景中所带来的「信息收益」与其「使用成本」之间的比值:
来自主题: AI技术研报
9105 点击 2025-05-30 15:06