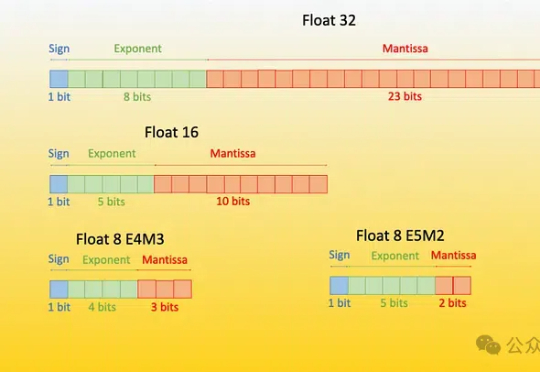
微软再放LLM量化大招!原生4bit量化,成本暴减,性能几乎0损失
微软再放LLM量化大招!原生4bit量化,成本暴减,性能几乎0损失原生1bit大模型BitNet b1.58 2B4T再升级!微软公布BitNet v2,性能几乎0损失,而占用内存和计算成本显著降低。
来自主题: AI技术研报
9939 点击 2025-06-02 18:00
 搜索
搜索
原生1bit大模型BitNet b1.58 2B4T再升级!微软公布BitNet v2,性能几乎0损失,而占用内存和计算成本显著降低。
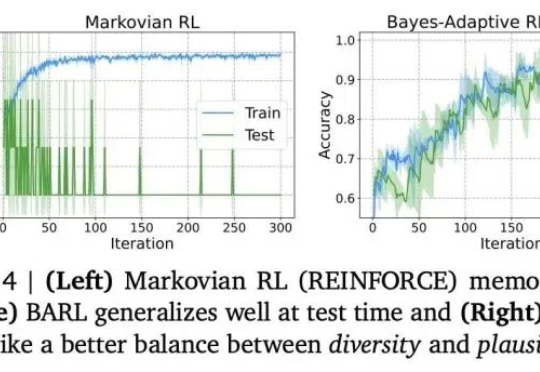
推理模型常常表现出类似自我反思的行为,但问题是——这些行为是否真的能有效探索新策略呢?
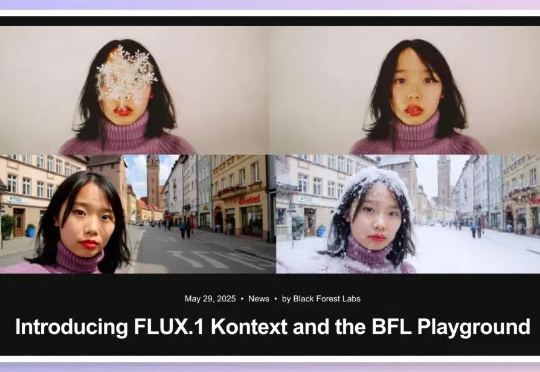
嗨大家好!假期愉快! 5月29日,黑森林实验室发布了 FLUX.1 Kontext,目标是通过一个统一的框架处理多种图像任务,解决现有模型在多轮编辑中的一些关键痛点。

近年来,大语言模型(LLMs)的能力突飞猛进,但随之而来的隐私风险也逐渐浮出水面。

不久前,GPT-4o 的最新图像风格化与编辑能力横空出世,用吉卜力等风格生成的效果令人惊艳,也让我们清晰看到了开源社区与商业 API 在图像风格化一致性上的巨大差距。
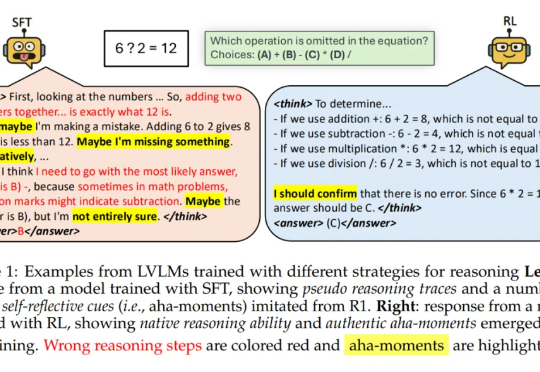
「尽管经过 SFT 的模型可能看起来在进行推理,但它们的行为更接近于模式模仿 —— 一种缺乏泛化推理能力的伪推理形式。」

如何让CLIP模型更关注细粒度特征学习,避免“近视”?360人工智能研究团队提出了FG-CLIP,可以明显缓解CLIP的“视觉近视”问题。让模型能更关注于正确的细节描述,而不是更全局但是错误的描述。
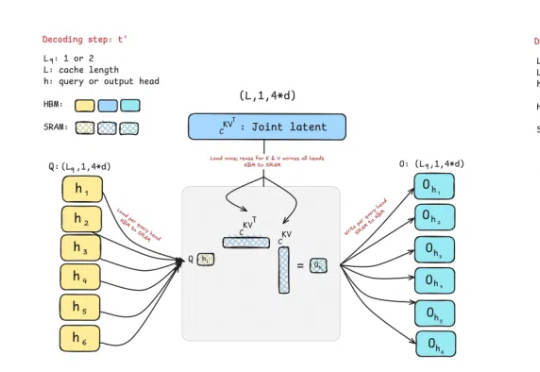
曾撼动Transformer统治地位的Mamba作者之一Tri Dao,刚刚带来新作——提出两种专为推理“量身定制”的注意力机制。
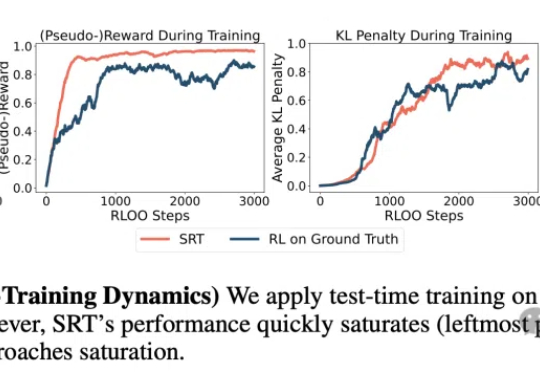
数据枯竭正成为AI发展的新瓶颈!CMU团队提出革命性方案SRT:让LLM实现无需人类标注的自我进化!SRT初期就能迭代提升数学与推理能力,甚至性能逼近传统强化学习的效果,揭示了其颠覆性潜力。
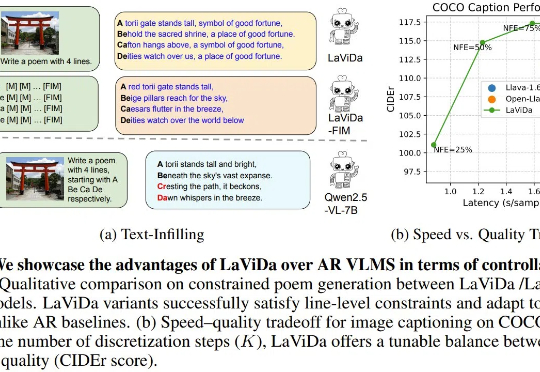
近段时间,已经出现了不少基于扩散模型的语言模型,而现在,基于扩散模型的视觉-语言模型(VLM)也来了,即能够联合处理视觉和文本信息的模型。今天我们介绍的这个名叫 LaViDa,继承了扩散语言模型高速且可控的优点,并在实验中取得了相当不错的表现。

昨天发现Mary Meeker又重新开始发布她每年一次的《互联网趋势报告》,只不过这次开始叫《人工智能趋势报告》了,整份报告有 340 页,非常详细的分析了AI领域的现状。
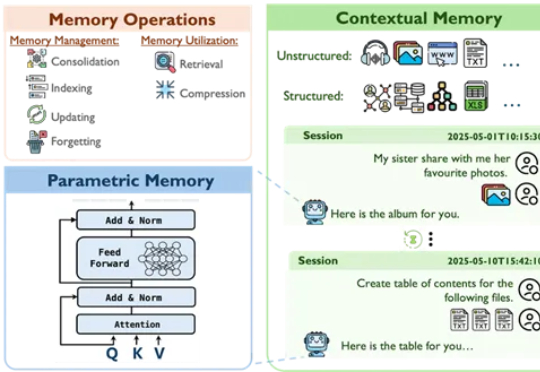
来自香港中文大学、爱丁堡大学、香港科技大学与华为爱丁堡研究中心的研究团队联合发布了一项关于AI记忆机制的系统性综述,旨在在大模型时代背景下,重新审视并系统化理解智能体的记忆构建与演化路径。

研究者针对 few-shot 图像编辑提出一个新的自回归模型结构 ——InstaManip,并创新性地提出分组自注意力机制(group self-attention),在此任务上取得了优异的效果。

陶哲轩转发,AI搞数学证明的标准习题集来了!
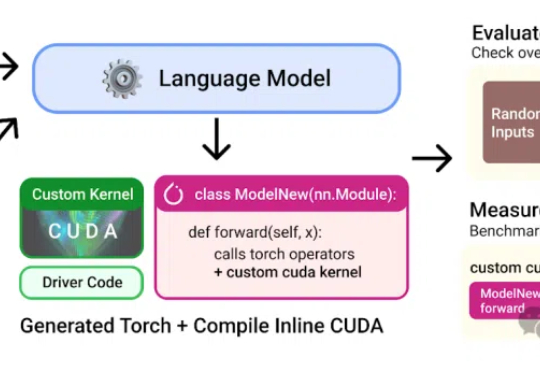
本想练练手合成点数据,没想到却一不小心干翻了PyTorch专家内核!斯坦福华人团队用纯CUDA-C写出的AI生成内核,瞬间惊艳圈内并登上Hacker News热榜。团队甚至表示:本来不想发这个结果的。
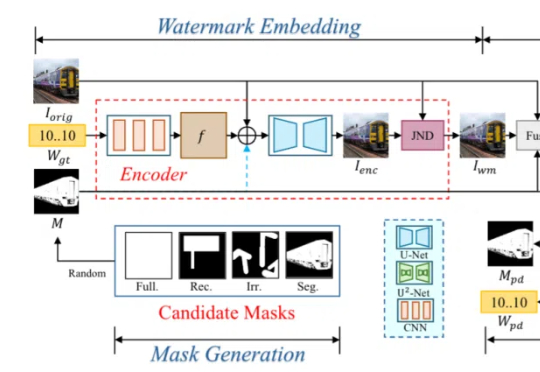
给AI生成的作品打水印,让AIGC图像可溯源,已经成为行业共识。
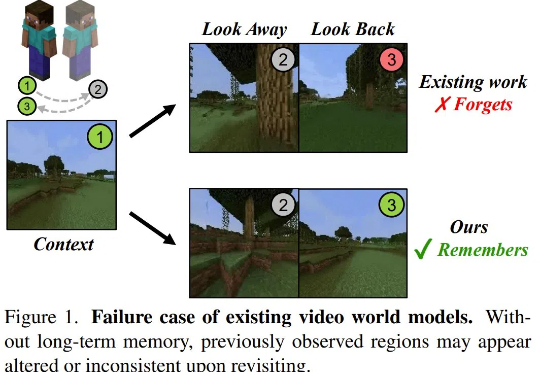
当状态空间模型遇上扩散模型,对世界模型意味着什么?
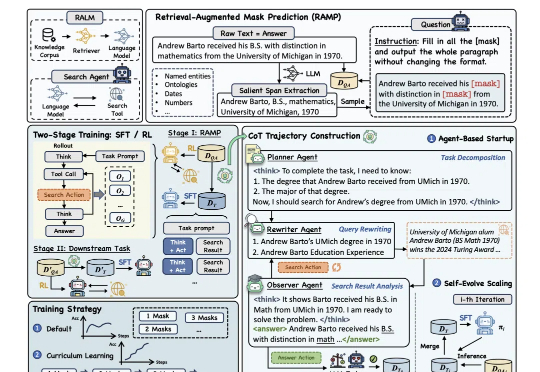
为提升大模型“推理+搜索”能力,阿里通义实验室出手了。
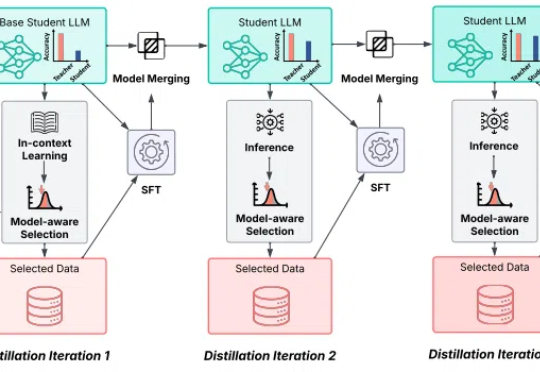
孙子兵法有云:“故其疾如风,其徐如林”,意指在行进迅速时,如狂风飞旋;而在行进从容时,如森林徐徐展开。
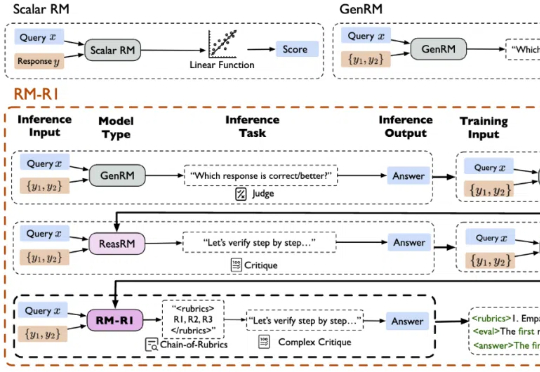
「知其然,亦知其所以然。」

OpenAI的o3推理模型席卷AI界,算力暴增10倍,能力突飞猛进!但专家警告:最多一年,推理模型可能一年内撞上算力资源极限。OpenAI还能否带来惊喜?
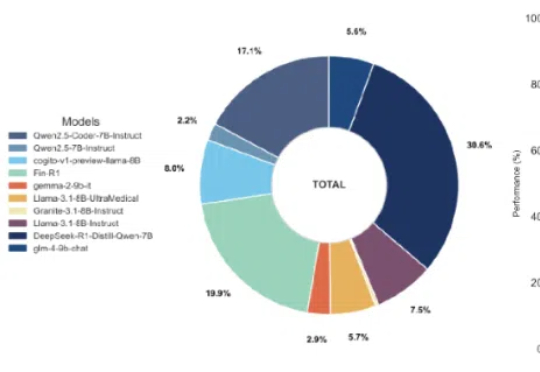
近年来,语言模型技术迅速发展,然而代表性成果如Gemini 2.5Pro和GPT-4.1,逐渐被谷歌、OpenAI等科技巨头所垄断。
在今年 ICLR 会议上,我们被问到最多且最有意思的问题是:像 Jina AI 这样的向量搜索模型提供商,除了在 MTEB 上做基准测试,会不会做些氛围测试 (Vibe-testing)?

好家伙,AI意外生成的内核(kernel),性能比人类专家专门优化过的还要好!
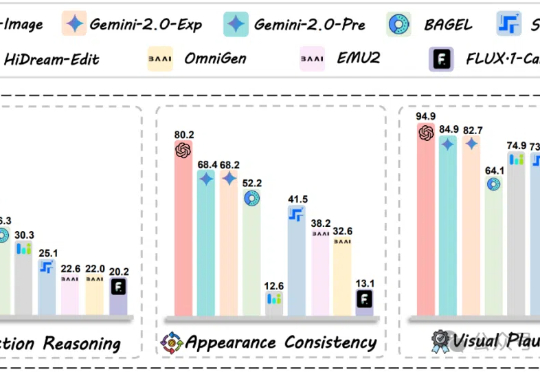
GPT-4o-Image也只能完成28.9%的任务,图像编辑评测新基准来了!360个全部由人类专家仔细思考并校对的高质量测试案例,暴露多模态模型在结合推理能力进行图像编辑时的短板。

现在,请大家一起数一下“1”、“2”。OK,短短2秒钟时间,一个准万亿MoE大模型就已经吃透如何解一道高等数学大题了!而且啊,这个大模型还是不用GPU来训练,全流程都是大写的“国产”的那种。

多模态大模型(MLLM)在静态图像上已经展现出卓越的 OCR 能力,能准确识别和理解图像中的文字内容。MME-VideoOCR 致力于系统评估并推动MLLM在视频OCR中的感知、理解和推理能力。

来和机器狗一起运动不?你的羽毛球搭子来了!无需人工协助,仅靠强化学习,机器狗子就学会了羽毛球哐哐对打。基于强化学习,研究人员开发了机器狗的全身视觉运动控制策略,同步控制腿部(18个自由度)移动,和手臂挥拍动作。

多AI智能体系统的复杂构建与优化,长期以来是用智能体解决科研问题和场景落地的瓶颈。来自英国格拉斯哥大学的研究团队发布了全球首个AI智能体自进化开源框架EvoAgentX,通过引入自我进化机制,打破了传统多智能体系统在构建和优化中的限制!
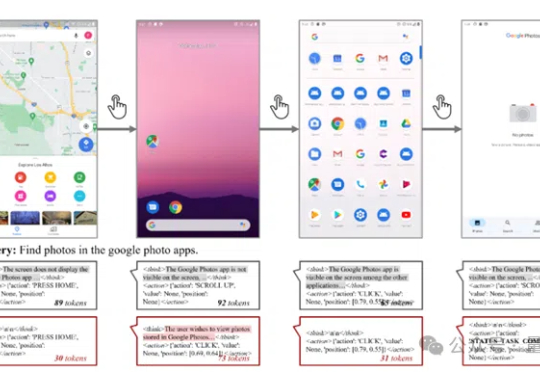
人类在面对简单提问时常常不假思索直接回答,只有遇到复杂难题才会认真推理。