开源播客生成MoonCast:让AI播客告别"机械味",中英双语对话更自然!
开源播客生成MoonCast:让AI播客告别"机械味",中英双语对话更自然!仅听几秒人声,即可完成逼真复刻,而且是对话式语音。
来自主题: AI技术研报
7308 点击 2025-06-05 10:25
 搜索
搜索
仅听几秒人声,即可完成逼真复刻,而且是对话式语音。

最近,华为在MoE训练系统方面,给出了MoE训练算子和内存优化新方案:三大核心算子全面提速,系统吞吐再提20%,Selective R/S实现内存节省70%。

GPT 系列模型的记忆容量约为每个参数 3.6 比特。
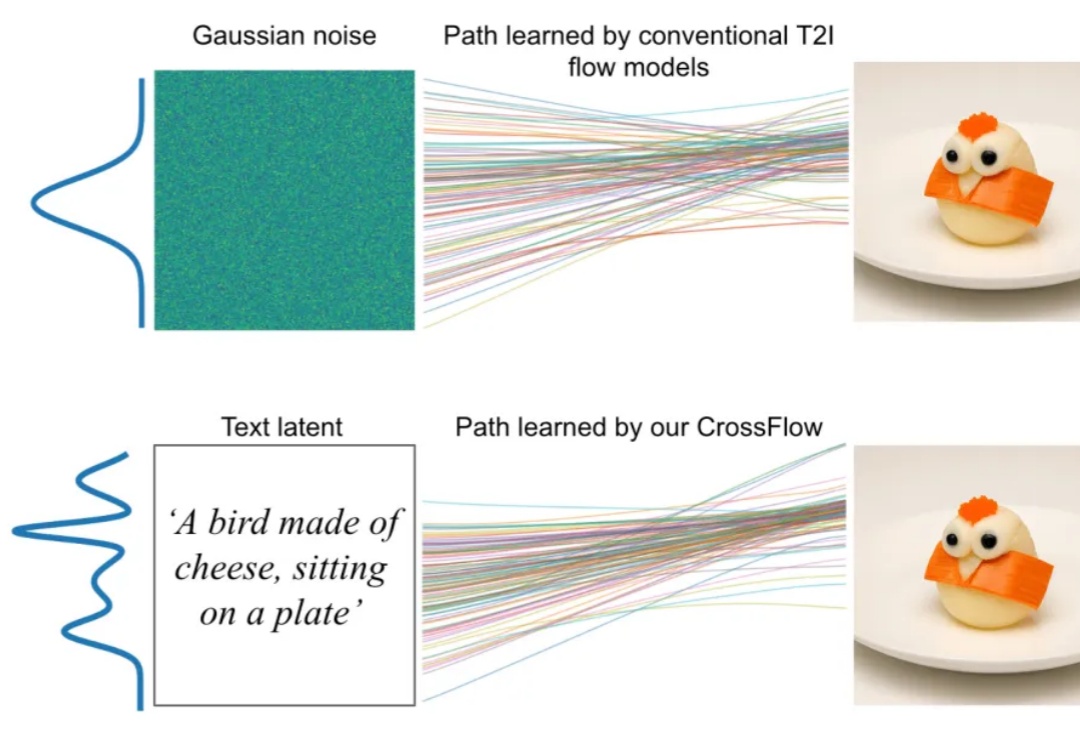
在人工智能领域,跨模态生成(如文本到图像、图像到文本)一直是技术发展的前沿方向。现有方法如扩散模型(Diffusion Models)和流匹配(Flow Matching)虽取得了显著进展,但仍面临依赖噪声分布、复杂条件机制等挑战。
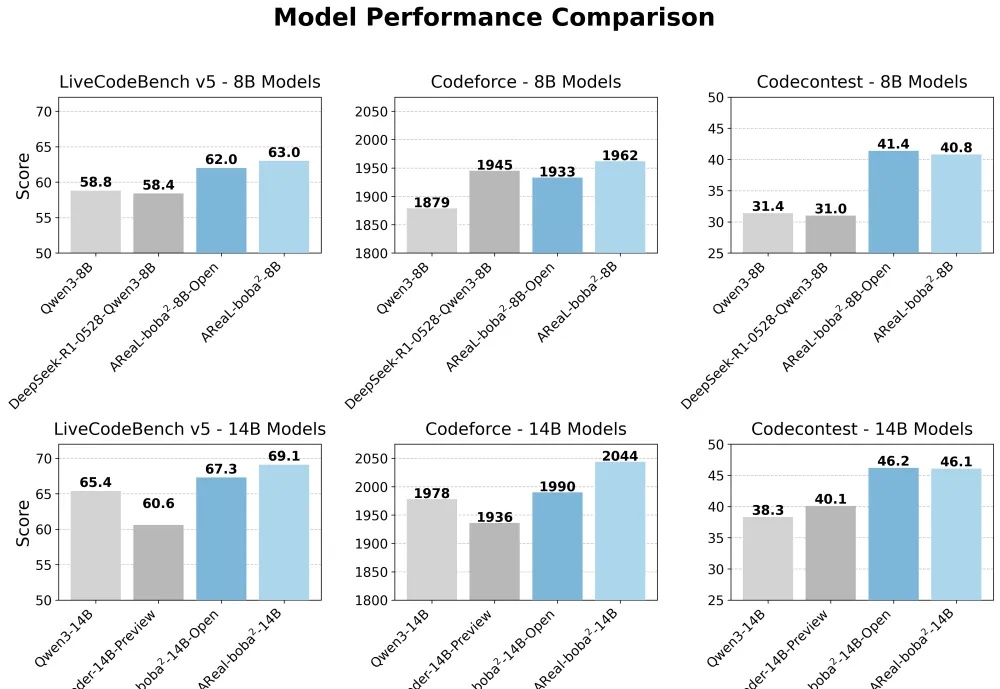
想训练属于自己的高性能推理模型,却被同步强化学习(RL)框架的低效率和高门槛劝退?AReaL 全面升级,更快,更强,更好用!
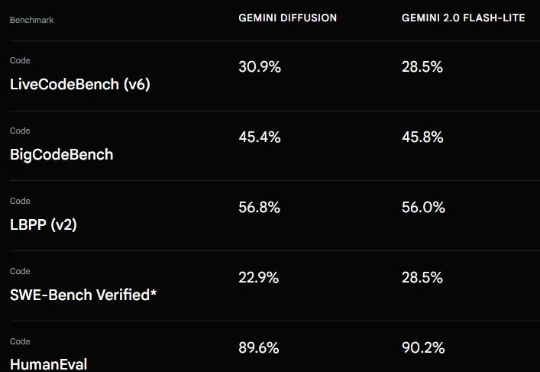
上个月 21 号,Google I/O 2025 开发者大会可说是吸睛无数,各种 AI 模型、技术、工具、服务、应用让人目不暇接。在这其中,Gemini Diffusion 绝对算是最让人兴奋的进步之一。从名字看得出来,这是一个采用了扩散模型的 AI 模型,而这个模型却并非我们通常看到的扩散式视觉生成模型,而是一个地地道道的语言模型!

LLM根本不会思考!LeCun团队新作直接戳破了大模型神话。最新实验揭示了,AI仅在粗糙分类任务表现优秀,却在精细任务中彻底失灵。
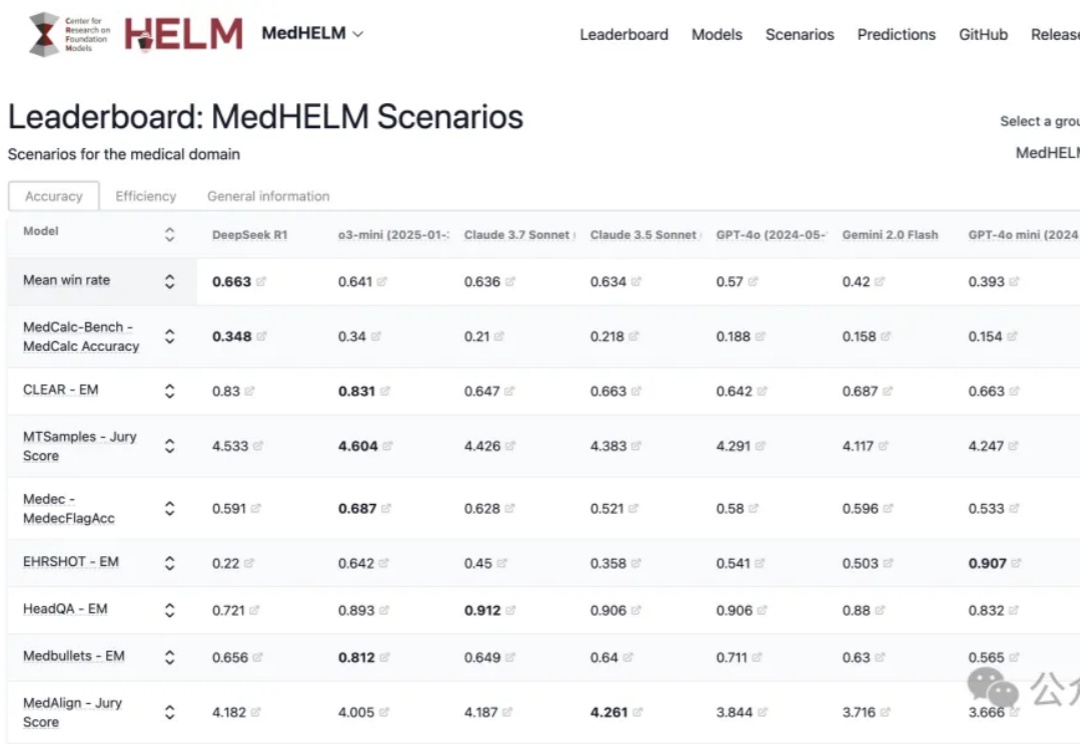
斯坦福最新大模型医疗任务全面评测,DeepSeek R1以66%胜率拿下第一!
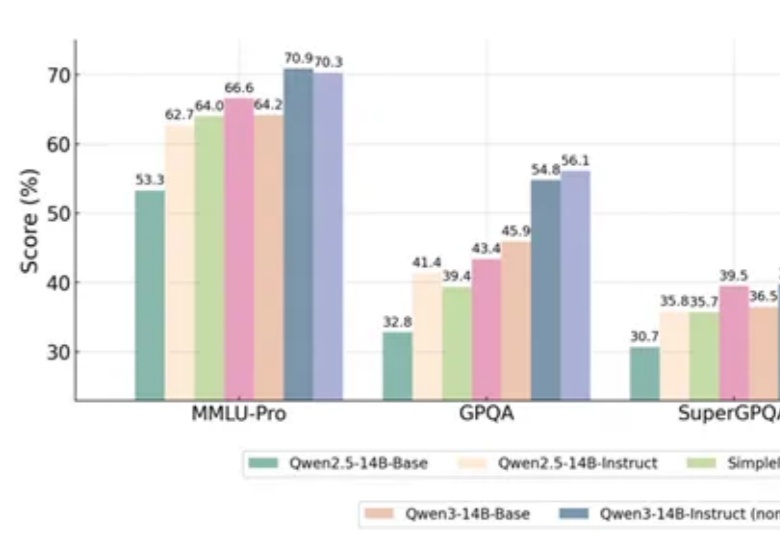
一项新的强化学习方法,直接让Qwen性能大增,GPT-4o被赶超!
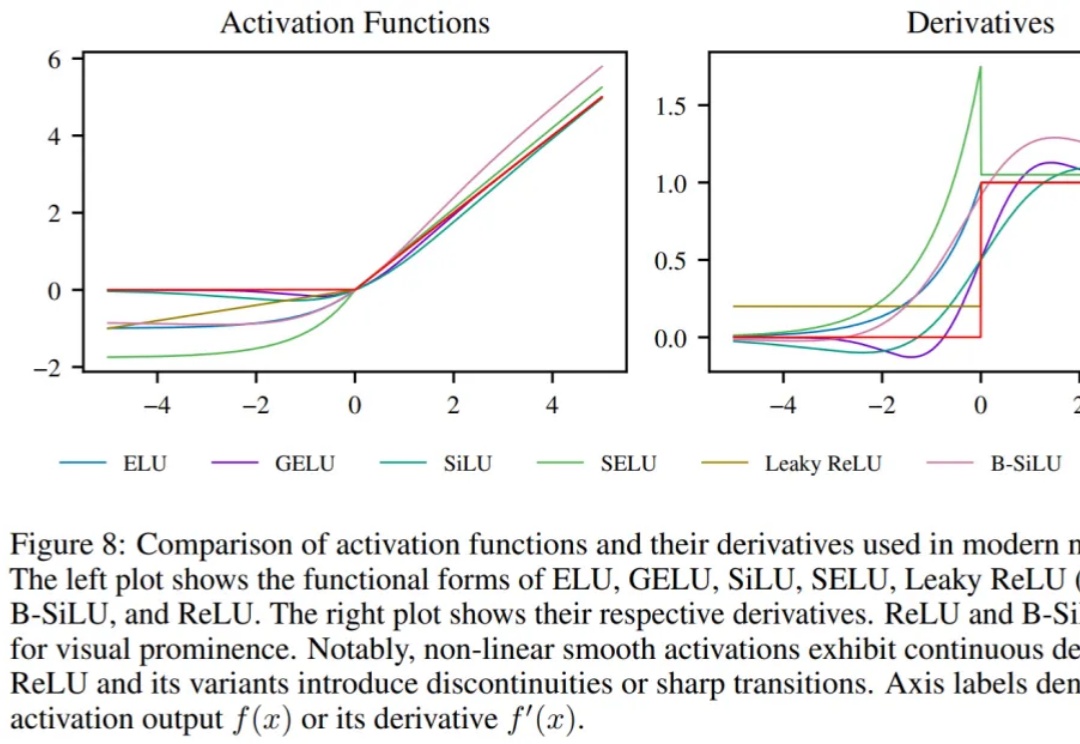
不用换模型、不用堆参数,靠 SUGAR 模型性能大增!

想象一下,你在一个陌生的房子里寻找合适的礼物盒包装泰迪熊,需要记住每个房间里的物品特征、位置关系,并根据反馈调整行动。
最近AI圈子里有两个特别有意思的项目,一个是谷歌DeepMind的AlphaEvolve,另一个是UBC大学的Darwin Gödel Machine(简称DGM)。
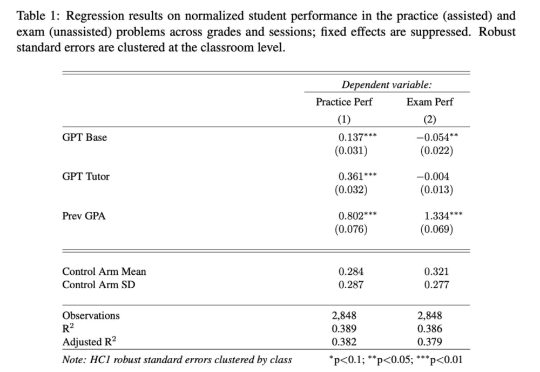
AI工具帮助学生轻松完成作业,但过度依赖导致学习深度不足。研究显示,使用AI辅助的学生练习阶段表现优异,但独立考试时成绩显著下降。认知能力可能因“认知卸载”而退化,年轻群体更易受影响。教育界尝试禁用、引导或改革评估方式,但AI对学习本质的挑战仍未解决。
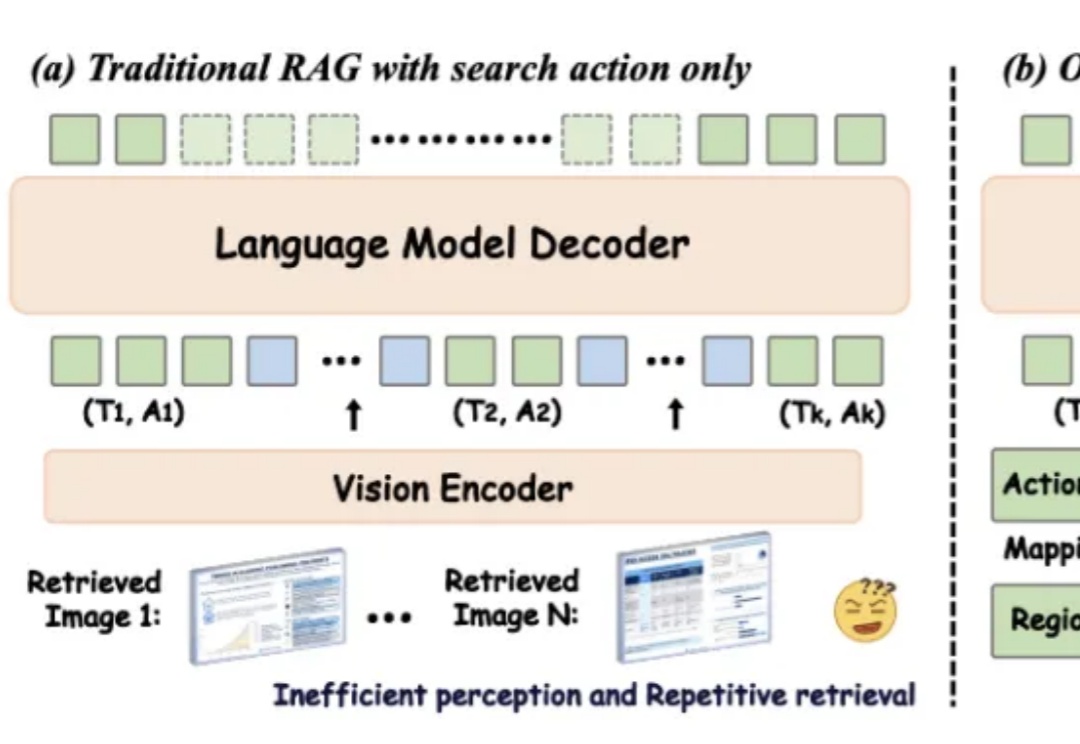
在数字化时代,视觉信息在知识传递和决策支持中的重要性日益凸显。然而,传统的检索增强型生成(RAG)方法在处理视觉丰富信息时面临着诸多挑战。一方面,传统的基于文本的方法无法处理视觉相关数据;另一方面,现有的视觉 RAG 方法受限于定义的固定流程,难以有效激活模型的推理能力。

你好研究僧,听说刚刚中了顶会,却还在愁怎么做Poster(学术海报)?
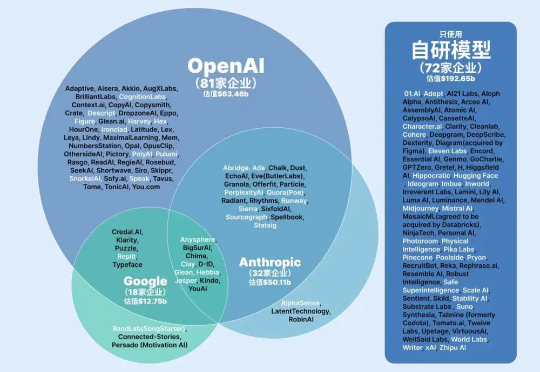
全球AI原生企业围绕OpenAI、Anthropic和谷歌三大生态阵营发展,形成开放多元、安全导向和技术闭环的差异化格局。企业通过多模型接入、自研模型及垂直深耕等策略竞争,生态构建聚焦开发者工具、行业渗透和价格策略,当前行业仍处动态演变阶段,尚未形成最终格局。

智源研究院发布开源模型Video-XL-2,显著提升长视频理解能力。该模型在效果、处理长度与速度上全面优化,支持单卡处理万帧视频,编码2048帧仅需12秒。

发展教育大模型需要新的数据和评估体系!北京理工大学高扬老师团队推出EduBench,是首个专为教育场景打造的综合评估基准,涵盖9大教育场景、12个多视角评估维度、超4000个教育情境。通过多维度评估指标体系和人工标注一致性计算,确保评估可靠性,助力教育大模型发展,推动教育智能化。
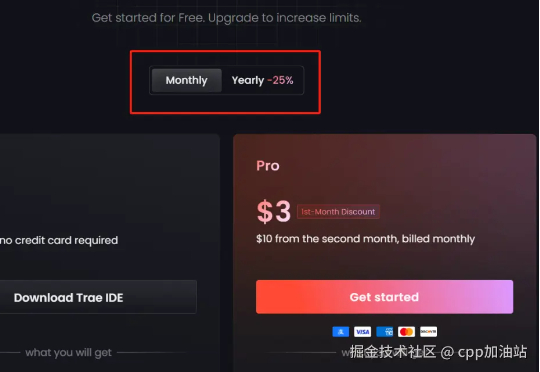
Trae国际版昨天上新了付费模式,本来没想着写付费教程,毕竟付费嘛,给钱就完了,但是我发现还真不是那么简单,我自己付费过程中也遇到了一些问题,同时呢,在官方群看到有好多小伙伴本来是想月付的,结果直接变成年付了,也就是直接付了90美刀,还没有退款渠道,只能给Trae官方发邮件,所以我还是写一个吧,给想付费的小伙伴提个醒也是好的。

首个专为ALLMs(音频大语言模型)设计的多维度可信度评估基准来了。
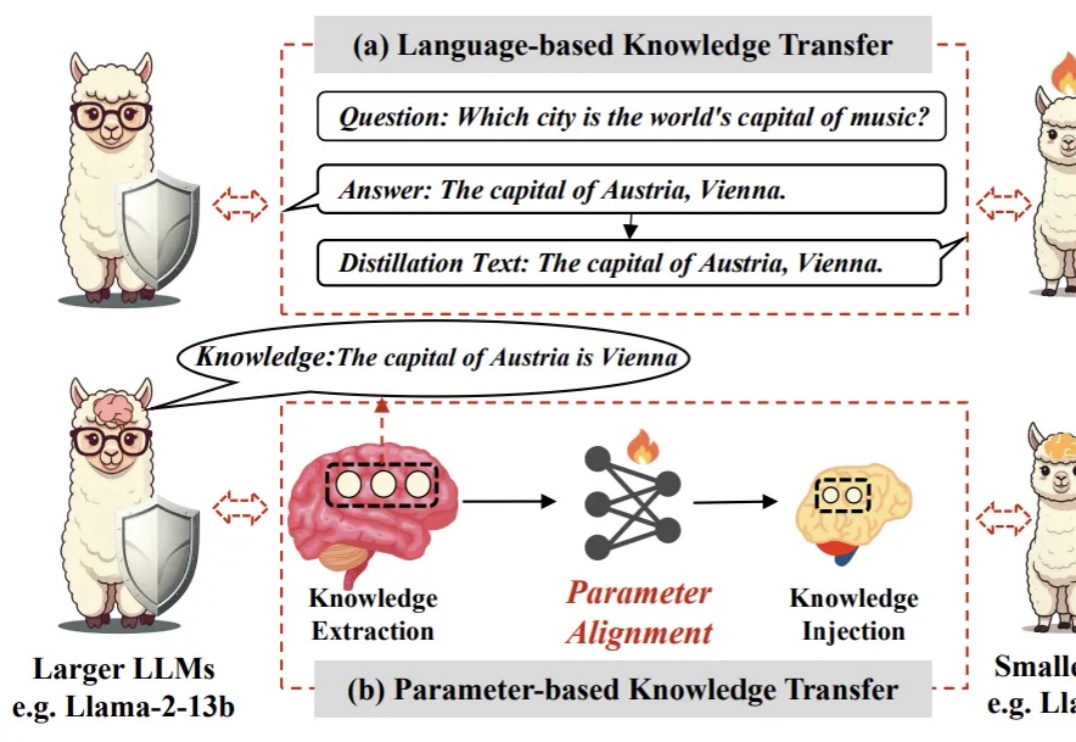
人类的思维是非透明的,没有继承的记忆,因此需要通过语言交流的环境来学习。人类的知识传递长期依赖符号语言:从文字、数学公式到编程代码,我们通过符号系统将知识编码、解码。但这种方式存在天然瓶颈,比如信息冗余、效率低下等。
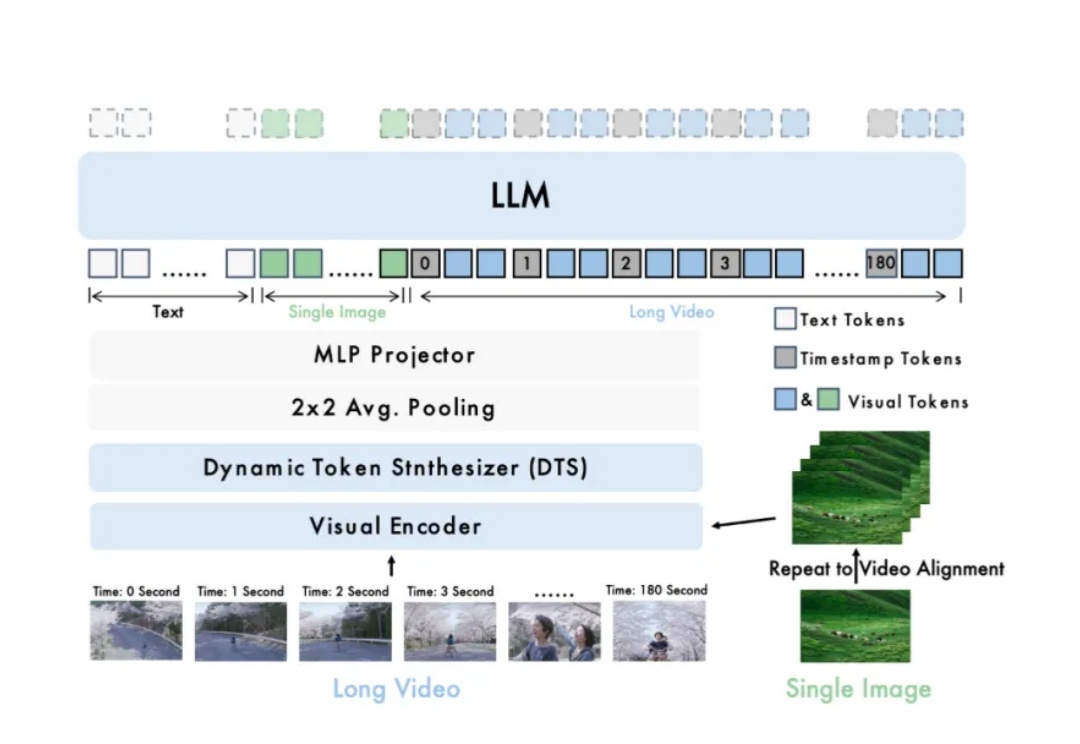
长视频理解是多模态大模型关键能力之一。尽管 OpenAI GPT-4o、Google Gemini 等私有模型已在该领域取得显著进展,当前的开源模型在效果、计算开销和运行效率等方面仍存在明显短板。

2025第一季度刚刚过完,中国大模型“国产之光”已经可以预定一个年度关键词了。从DeepSeek走红全网,到Manus一夜爆火,再到宇树为代表的机器人让中外网友连连惊呼……毫无疑问,中国前沿科技,正在2025年成为全世界热议和肯定的焦点。

端午节前OpenAI发布了o3/o4-mini模型的Function Calling指南,这份指南可以说是目前网上最硬核权威的大模型函数调用实战手册,没有之一。

编程智能体也有「进化论」!Transformer作者初创Sakana AI与UBC推出达尔文-哥德尔机(DGM),能自动改写自身代码,性能翻倍超越人工设计。还能跨语言迁移、发明新工具。AI要觉醒了?

新加坡国立大学等机构的研究者们通过元能力对齐的训练框架,模仿人类推理的心理学原理,将演绎、归纳与溯因能力融入模型训练。实验结果显示,这一方法不仅提升了模型在数学与编程任务上的性能,还展现出跨领域的可扩展性。

杯子在我的左边还是右边?

在多智能体AI系统中,一旦任务失败,开发者常陷入「谁错了、错在哪」的谜团。PSU、杜克大学与谷歌DeepMind等机构首次提出「自动化失败归因」,发布Who&When数据集,探索三种归因方法,揭示该问题的复杂性与挑战性。
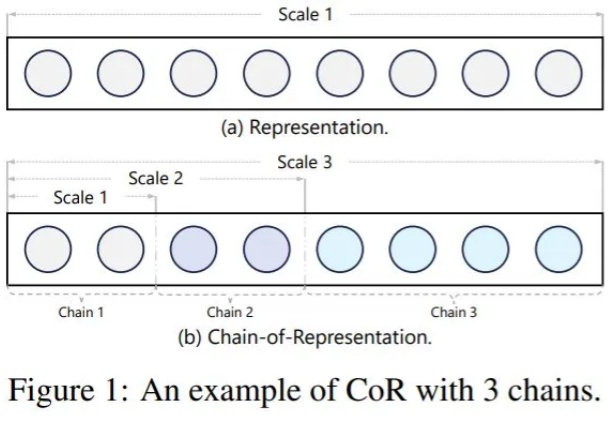
随着大语言模型 (LLM) 的出现,扩展 Transformer 架构已被视为彻底改变现有 AI 格局并在众多不同任务中取得最佳性能的有利途径。因此,无论是在工业界还是学术界,探索如何扩展 Transformer 模型日益成为一种趋势。
在过去的一周,这一方向的进展尤其丰富。有人发现,几篇关于「让 LLM(或智能体)学会自我训练」的论文在 arXiv 上集中出现,其中甚至包括受「哥德尔机」构想启发而提出的「达尔文哥德尔机」。或许,AI 模型的自我进化能力正在加速提升。