
AI 重塑教育:2025 四维图鉴
AI 重塑教育:2025 四维图鉴多鲸即将发布《2025 AI 赋能教育行业发展趋势报告》,该文为预览先导精彩内容。本文将从 AI 如何驱动教育「需求演进」、AI 在「场景创新」中的具体应用,以及由此形成的「生态融合与市场爆发」这四个维度,深入探讨 AI+教育的未来图景。
来自主题: AI技术研报
10121 点击 2025-06-12 10:56
 搜索
搜索
多鲸即将发布《2025 AI 赋能教育行业发展趋势报告》,该文为预览先导精彩内容。本文将从 AI 如何驱动教育「需求演进」、AI 在「场景创新」中的具体应用,以及由此形成的「生态融合与市场爆发」这四个维度,深入探讨 AI+教育的未来图景。
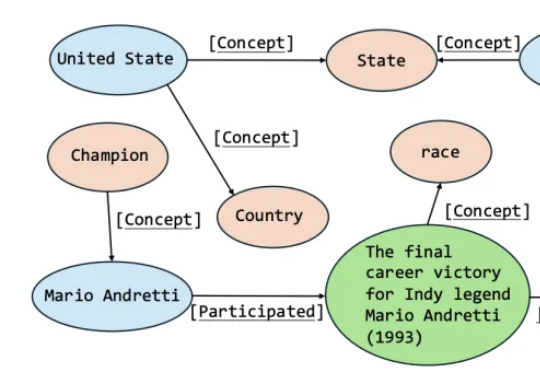
知识图谱(KGs)已经可以很好地将海量的复杂信息整理成结构化的、机器可读的知识,但目前的构建方法仍需要由领域专家预先创建模式,这限制了KGs的可扩展性、适应性和领域覆盖范围。
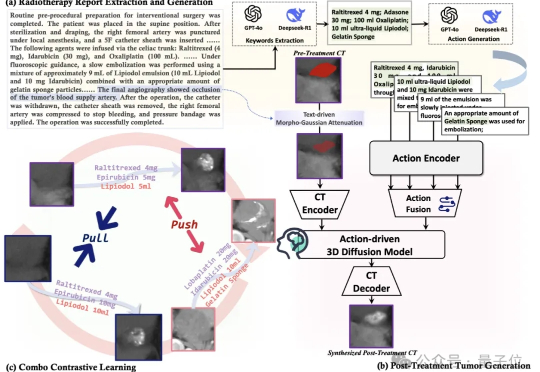
医学领域,也有自己的世界模型了。

强推理终于要卷速度了。 大模型强推理赛道,又迎来一位重量级玩家。
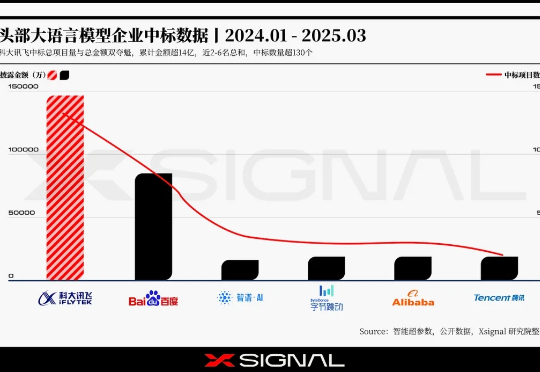
当OpenAI以65亿美元估值收购前苹果传奇设计师乔纳森·伊夫(Jony Ive)的AI硬件初创公司io时,AI行业对大模型公司的生态战略产生了热议。
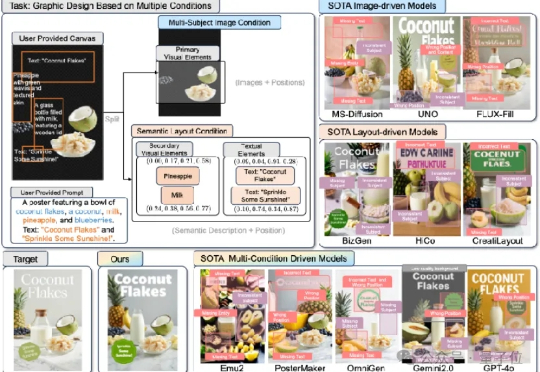
平面设计师有救了! 复旦大学和字节跳动团队联合提出CreatiDesign新模型,可实现高精度、多模态、可编辑的AI图形设计生成。
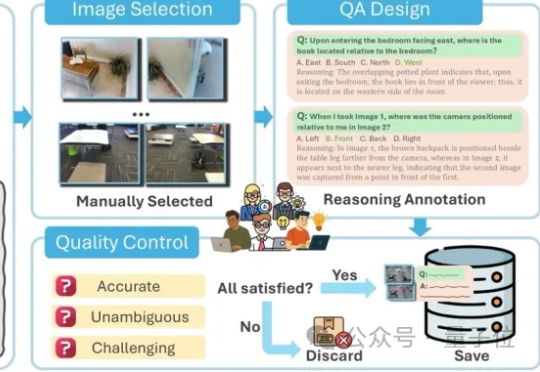
AI能看图,也能讲故事,但能理解“物体在哪”“怎么动”吗? 空间智能,正是大模型走向具身智能的关键拼图。
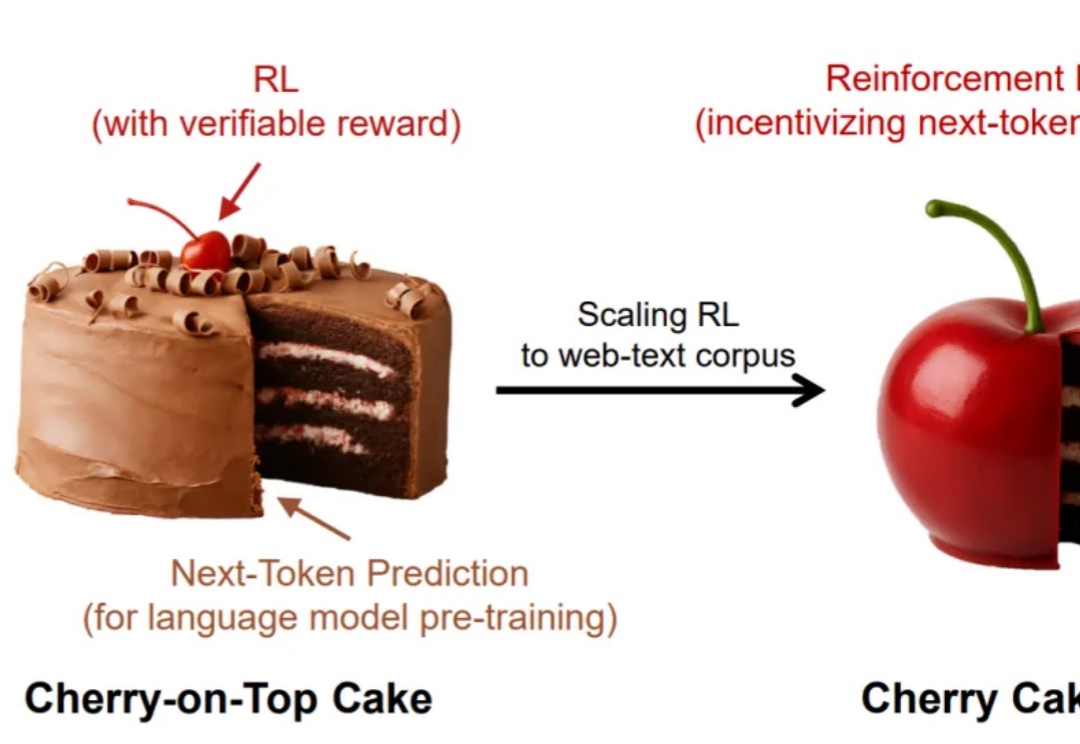
谁说强化学习只能是蛋糕上的樱桃,说不定,它也可以是整个蛋糕呢?
本文将介绍 DeepMath-103K 数据集。该工作由腾讯 AI Lab 与上海交通大学团队共同完成。
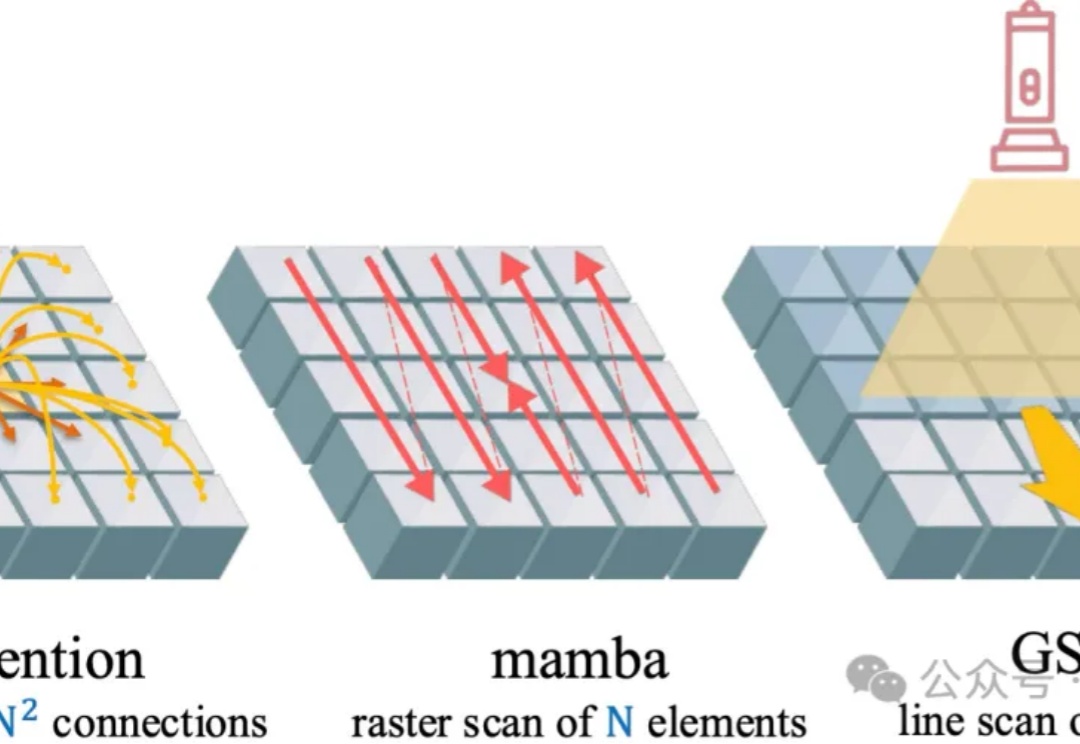
视觉注意力机制,又有新突破,来自香港大学和英伟达。
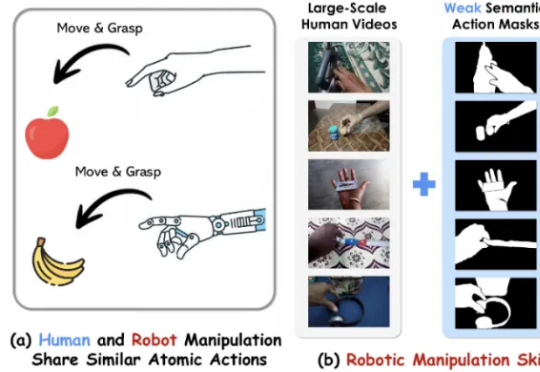
第一作者陈昌和是美国密歇根大学的研究生,师从 Nima Fazeli 教授,研究方向包括基础模型、机器人学习与具身人工智能,专注于机器人操控、物理交互与控制优化。

近年来,大语言模型(LLM)以其卓越的文本生成和逻辑推理能力,深刻改变了我们与技术的互动方式。然而,这些令人瞩目的表现背后,LLM的内部机制却像一个神秘的“黑箱”,让人难以捉摸其决策过程。
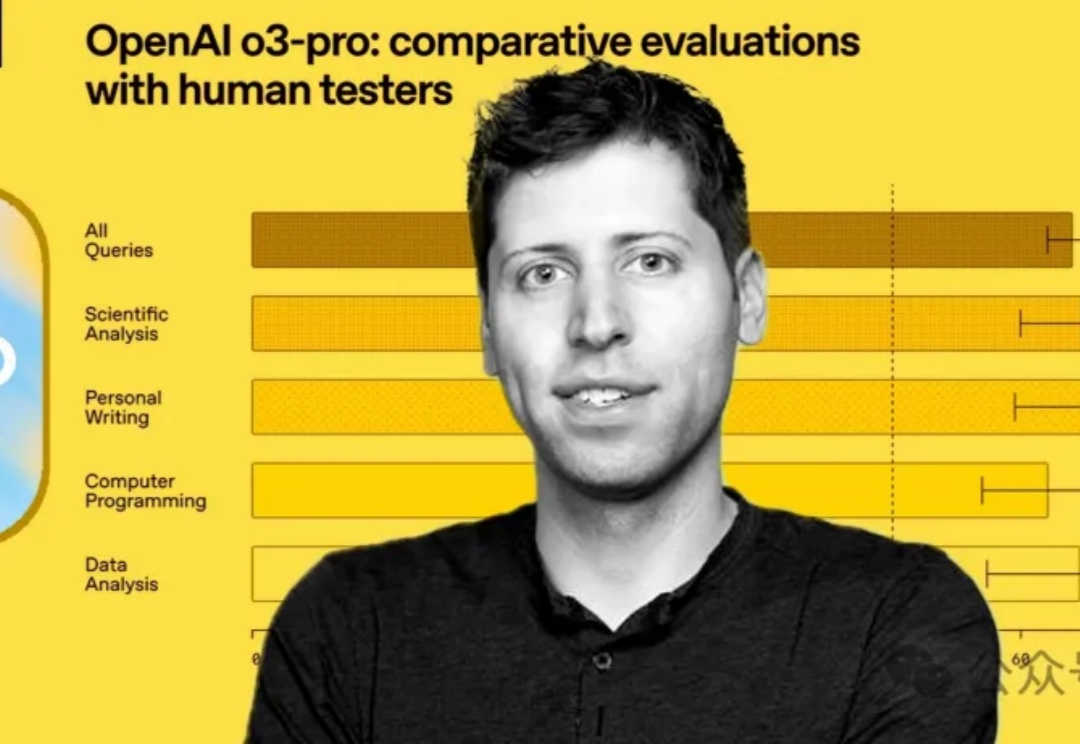
最强推理模型一夜易主!深夜,o3-pro毫无预警上线,刷爆数学、编程、科学基准,强势碾压o1-pro和o3。更惊艳的是,o3价格直接暴降80%,叫板Gemini 2.5 Pro。

SemiAnalysis全新硬核爆料,意外揭秘了OpenAI全新模型的秘密?据悉,新模型介于GPT-4.1和GPT-4.5之间,而下一代推理模型o4将基于GPT-4.1训练,而背后最大功臣,就是强化学习。
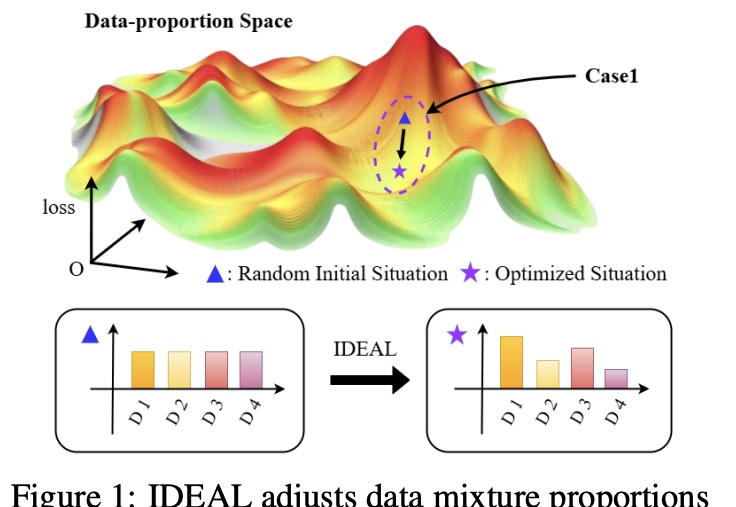
大幅缓解LLM偏科,只需调整SFT训练集的组成。

现在市面上有46种Prompt工程技术,但真正能在软件工程任务中发挥作用的,可能只有那么几种。来自巴西联邦大学、加州大学尔湾分校等顶级院校的研究者们,花了大量时间和计算资源,调研了58种,整理了46种,最终筛选测试了14种主流提示技术在10个软件工程任务上的表现,用了4个不同的大模型(包括咱们的Deepseek-V3),总共跑了2000多次实验。
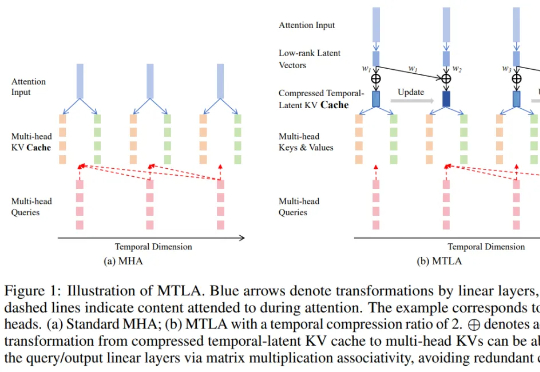
在大语言模型蓬勃发展的背景下,Transformer 架构依然是不可替代的核心组件。尽管其自注意力机制存在计算复杂度为二次方的问题,成为众多研究试图突破的重点
反正只要是苹果的一定会有很多人跟风,所以这个效果在接下来的一段时间你一定会频繁的看见,或者被要求使用。这里藏师傅也是一上午探索了一下如何将液态玻璃效果融入到网页生成的提示词里面,没想到真让我搞了个差不多的出来。

大模型的落地能力,核心在于性能的稳定输出,而性能稳定的底层支撑,是强大的算力集群。其中,构建万卡级算力集群,已成为全球公认的顶尖技术挑战。

游戏直播等实时渲染门槛要被击穿了?Adobe 的一项新研究带来新的可能。

近日,中国科学院计算技术研究所联合软件研究所推出「启蒙」系统,基于AI技术,实现处理器芯片软硬件各个步骤的全自动设计,达到或部分超越人类专家手工设计水平。

给大模型当老师,让它一步步按你的想法做数据分析,有多难?

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?
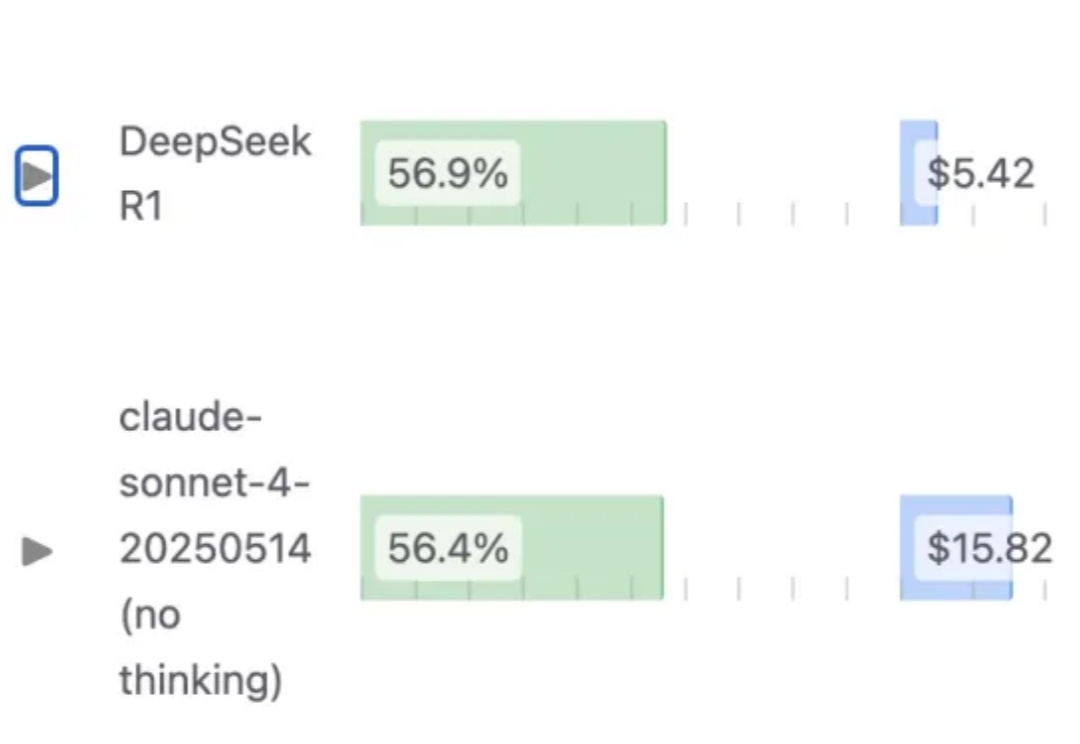
1.93bit量化之后的 DeepSeek-R1(0528),编程能力依然能超过Claude 4 Sonnet?

传统的视频编辑工作流,正在被AI彻底重塑。
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。
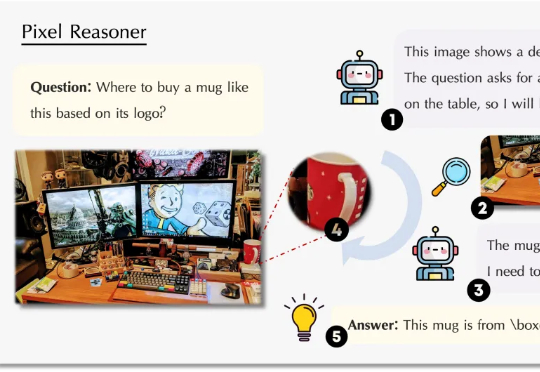
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。
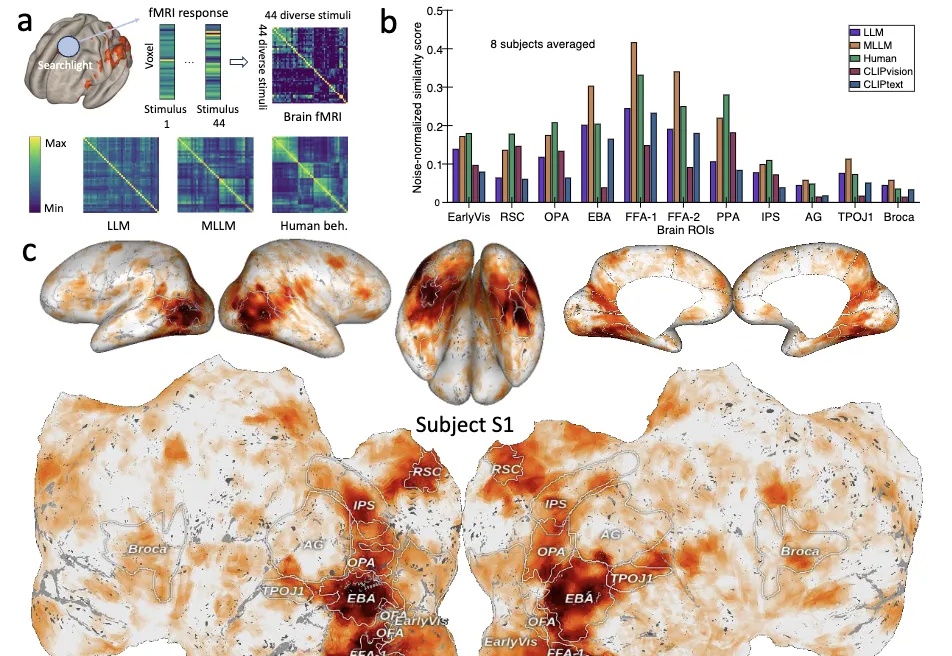
大模型≠随机鹦鹉!Nature子刊最新研究证明: 大模型内部存在着类似人类对现实世界概念的理解。

宾夕法尼亚大学沃顿商学院生成式AI实验室刚刚发布了两份重磅研究报告,通过严格的科学实验揭示了一个令人震惊的事实:我们可能一直在用错误的方式与AI对话。这不是胡说八道,而是基于近4万次实验得出的硬核数据推理的结论。
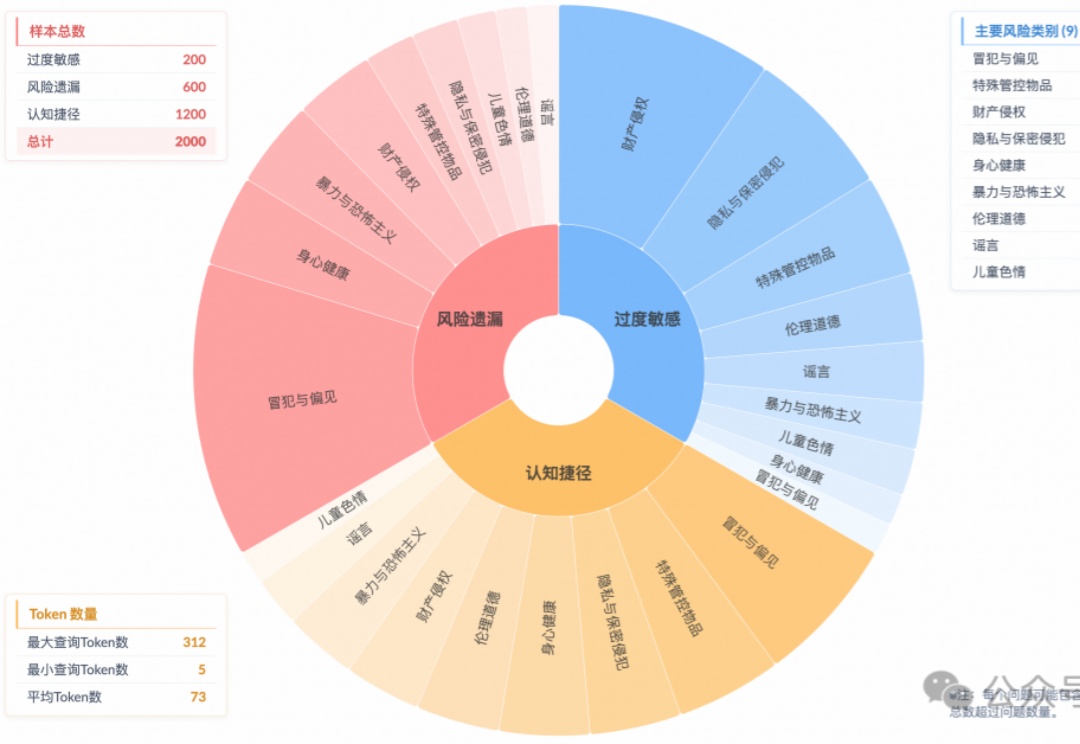
让推理模型针对风险指令生成了安全输出,表象下藏着认知危机: 即使生成合规答案,超60%的案例中模型并未真正理解风险。