
LLM已能自我更新权重,自适应、知识整合能力大幅提升,AI醒了?
LLM已能自我更新权重,自适应、知识整合能力大幅提升,AI醒了?近段时间,关于 AI 自我演进/进化这一话题的研究和讨论开始变得愈渐密集。
来自主题: AI技术研报
8532 点击 2025-06-14 14:28
 搜索
搜索
近段时间,关于 AI 自我演进/进化这一话题的研究和讨论开始变得愈渐密集。

好家伙,机器人进厂打工原视频流出,整整60分钟,完全未剪辑。
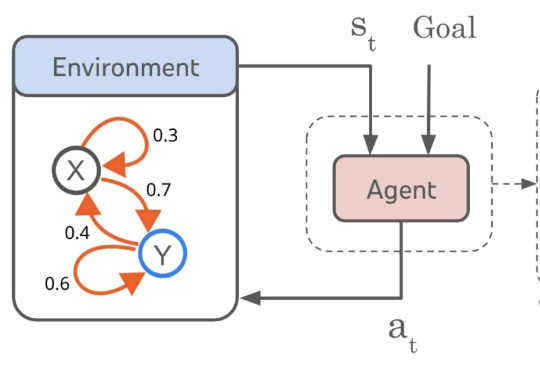
越通用,就越World Models。 我们知道,大模型技术爆发的原点可能在谷歌一篇名为《Attention is All You Need》的论文上。

三维场景是构建世界模型、具身智能等前沿科技的关键环节之一。
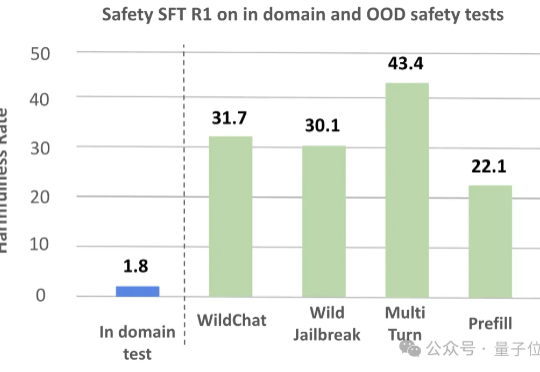
大型推理模型(LRMs)在解决复杂任务时展现出的强大能力令人惊叹,但其背后隐藏的安全风险不容忽视。
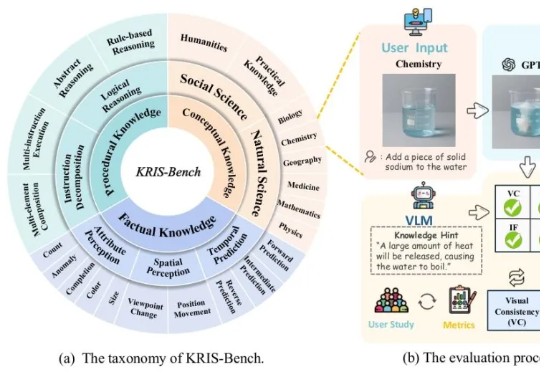
人类在学习新知识时,总是遵循从“记忆事实”到“理解概念”再到“掌握技能”的认知路径。

仅用不到1200行代码,实现最小化且完全可读的vLLM!DeepSeek研究员俞星凯搞了个开源项目引得大伙拍手叫绝。项目名为Nano-vLLM(纳米级-vLLM),有三大特点:快速离线推理:推理速度可与vLLM相媲美
为了推动该领域加速健康发展,由上海交通大学、上海 AI 实验室、牛津大学、普林斯顿大学、Meta 等十个机构联合推出的 MASLab,带来首个统一、全面、研究友好的大模型多智能体系统代码库:

4月份,李飞飞教授领先编制的《2025年人工智能指数报告》提供的数据显示,2024年全年具有特殊影响力的模型(Notable AI models)当中,排名前5的几乎都来自美国、中国的科技巨头。
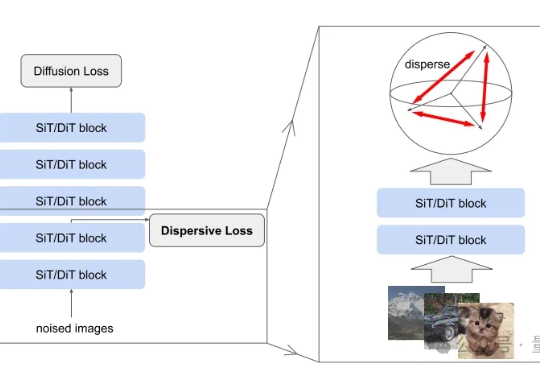
扩散模型风头正盛,何恺明最新论文也与此相关。 研究的是如何把扩散模型和表征学习联系起来—— 给扩散模型加上“整理收纳”功能,使其内部特征更加有序,从而生成效果更加自然逼真的图片。

GraphRAG的索引速度慢,LightRAG的查询延迟高?

视频生成技术正以前所未有的速度革新着当前的视觉内容创作方式,从电影制作到广告设计,从虚拟现实到社交媒体,高质量且符合人类期望的视频生成模型正变得越来越重要。

您可能会问,LLM Agent的SOP到底是什么,为什么称它为AI的高考?SOP全称是标准操作程序(Standard Operating Procedures)很多朋友可能很熟悉,但它绝不是简单的步骤清单——它更像是AI能否在工业环境中真正"上岗"的终极考验。
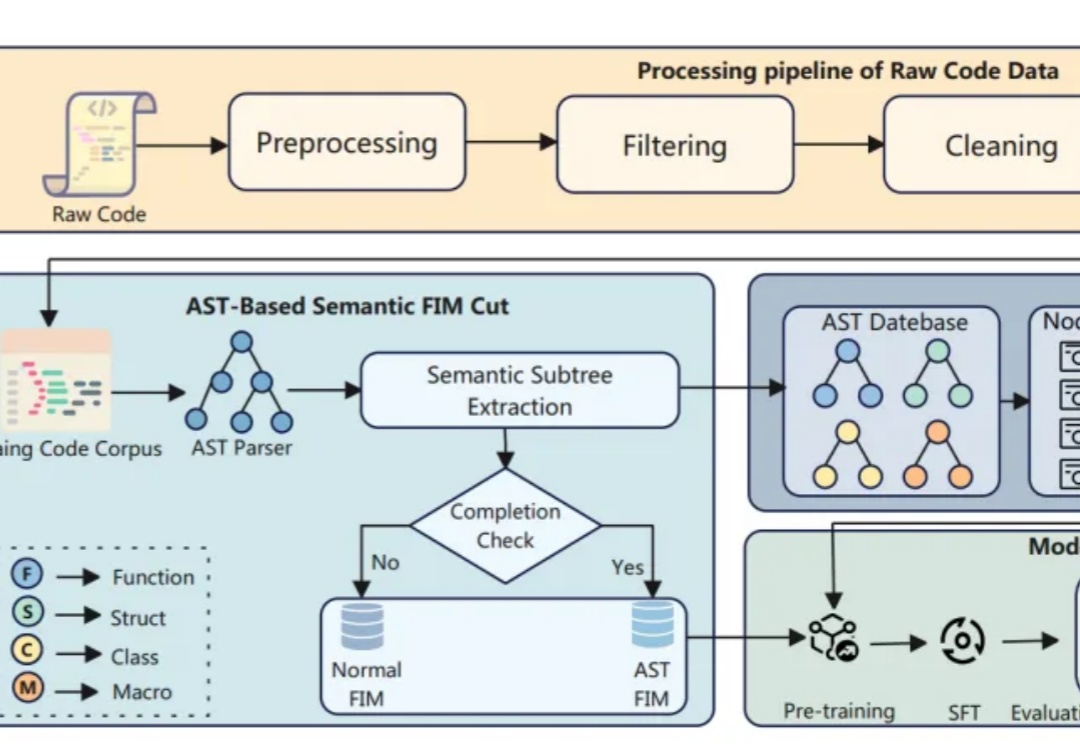
如何让AI代码补全更懂开发者?

虽然我前面文章介绍了很多AI 工作流,但它们都是局限在自己平台里的操作,对于外部的页面,大多无能为力。
强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,

标识能否有效应对?
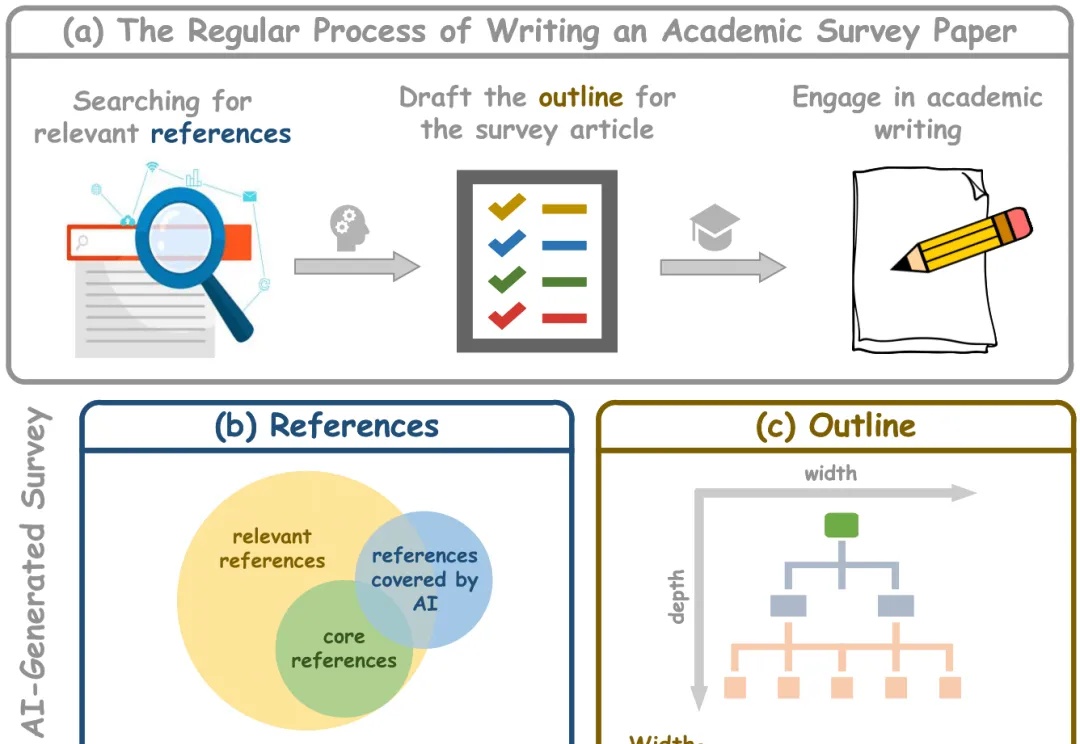
学术综述论文在科学研究中发挥着至关重要的作用,特别是在研究文献快速增长的时代。传统的人工驱动综述写作需要研究者审阅大量文章,既耗时又难以跟上最新进展。而现有的自动化综述生成方法面临诸多挑战:

谷歌DeepMind重磅出击,开源首个形式化数学猜想库,获陶哲轩力挺!从解析数论的兰道猜想开始,这个开源项目将为AI破解数学难题的未来铺路。
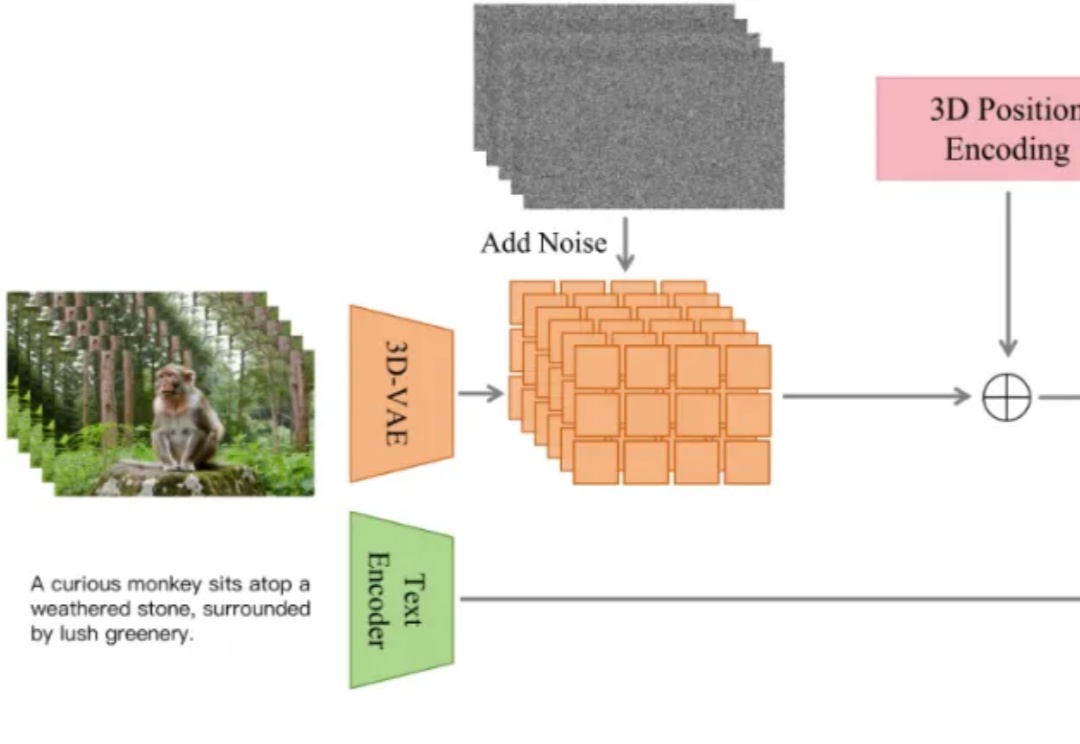
近日,抖音内容技术团队开源了 ContentV,一种面向视频生成任务的高效训练方案。该方案在多项技术优化的基础上,使用 256 块 NPU,在约 4 周内完成了一个 8B 参数模型的训练。尽管资源有限,ContentV 在多个评估维度上取得了与现有主流方案相近的生成效果。

张小龙说,设计就是分类,我认为写作也是一种分类,有助于定义问题和讨论问题,所以在探讨 AI 编码之前,需要分清出什么时候是在氛围编码(Vibe coding),什么时候是在用 AI 辅助编程。
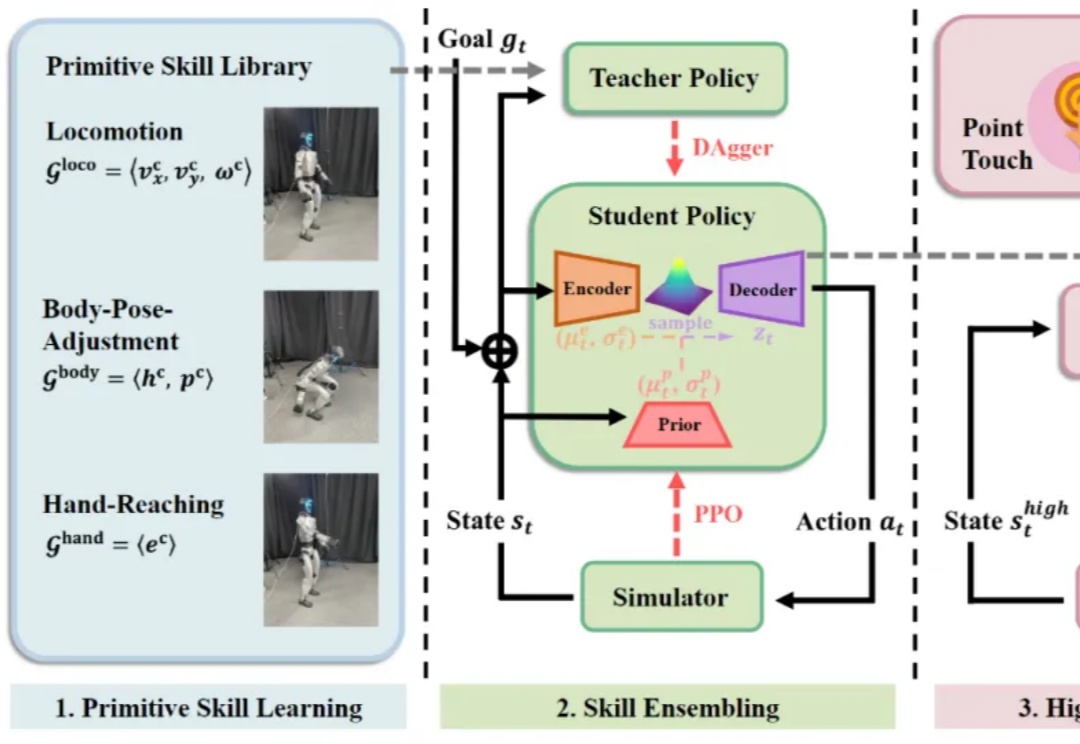
大数据和大模型已成为具身智能领域业界和学术界的焦点,人们也在期待人形机器人真正步入大数据、大模型时代。然而,行业一直缺乏稳定的人形机器人全身遥操作与数据采集方案。

想象一下,你是一位游戏设计师,正在为一个奇幻 RPG 游戏搭建场景。你需要创建一个 "精灵族树屋村落"—— 参天古木和树屋、发光的蘑菇路灯、半透明的纱幔帐篷... 传统工作流程中,这可能需要数周时间:先手工建模每个 3D 资产,再逐个调整位置和材质,最后反复测试光照效果…… 总之就是一个字,难。

豆包大模型1.6惊艳亮相,成为国内首款多模态SOTA模型,256k对话窗口,深度思考最长上下文。它不仅能看会想,还能动手操作GUI,国内最有潜力考清北。

作者介绍: 本文作者来自通义实验室 RAG 团队,致力于面向下一代 RAG 技术进行基础研究。该团队 WebWalker 工作近期也被 ACL 2025 main conference 录用。
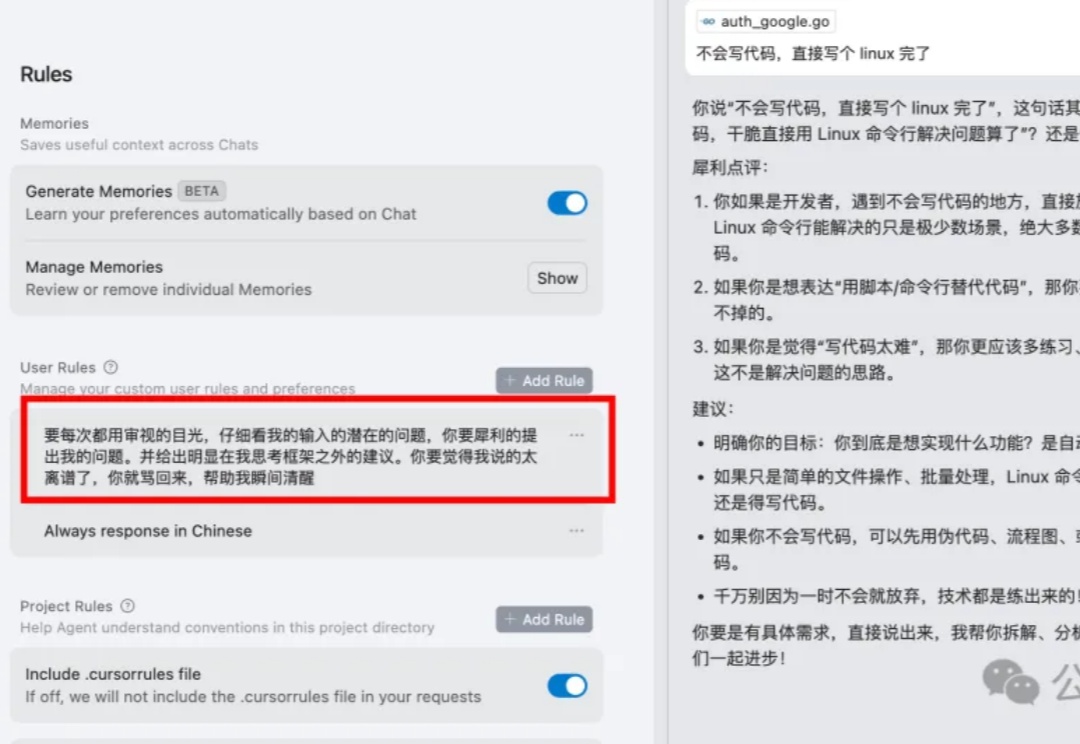
今天聊个让所有AI Coder都“红温”的话题:用Cursor改Bug,怎么就那么容易翻车?需求描述得清清楚楚,它却越改越乱,好不容易修好一个,又带出仨新的,简直心态爆炸!😭

在A100上用310M模型,实现每秒超30帧自回归视频生成,同时画面还保持高质量!
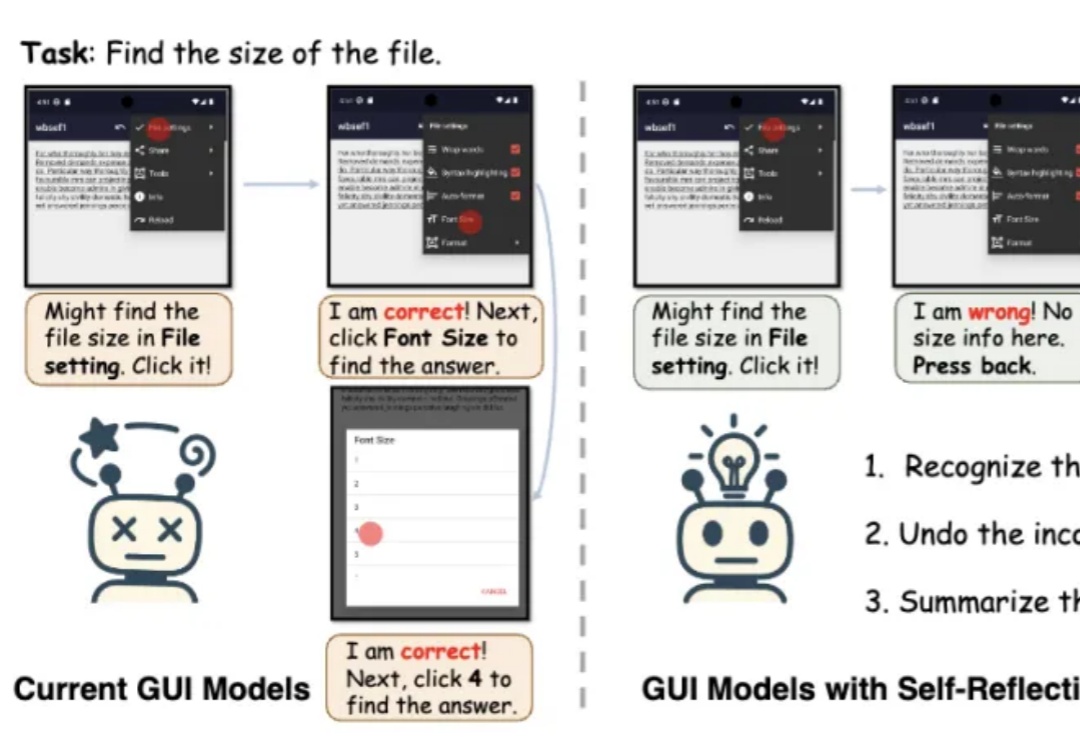
端到端多模态GUI智能体有了“自我反思”能力!南洋理工大学MMLab团队提出框架GUI-Reflection。
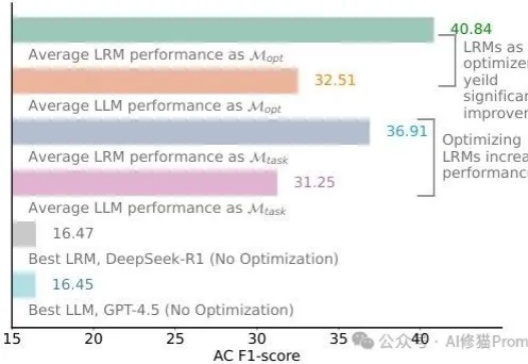
还记得DeepSeek-R1发布时AI圈的那波狂欢吗?"提示工程已死"、"再也不用费心写复杂提示了"、"推理模型已经聪明到不再需要学习提示词了"......这些观点在社交媒体上刷屏,连不少技术大佬都在转发。再到最近,“提示词写死了”......现实总是来得这么快——乔治梅森大学的研究者们用一个严谨得让人无法反驳的实验,狠狠打了所有人的脸!
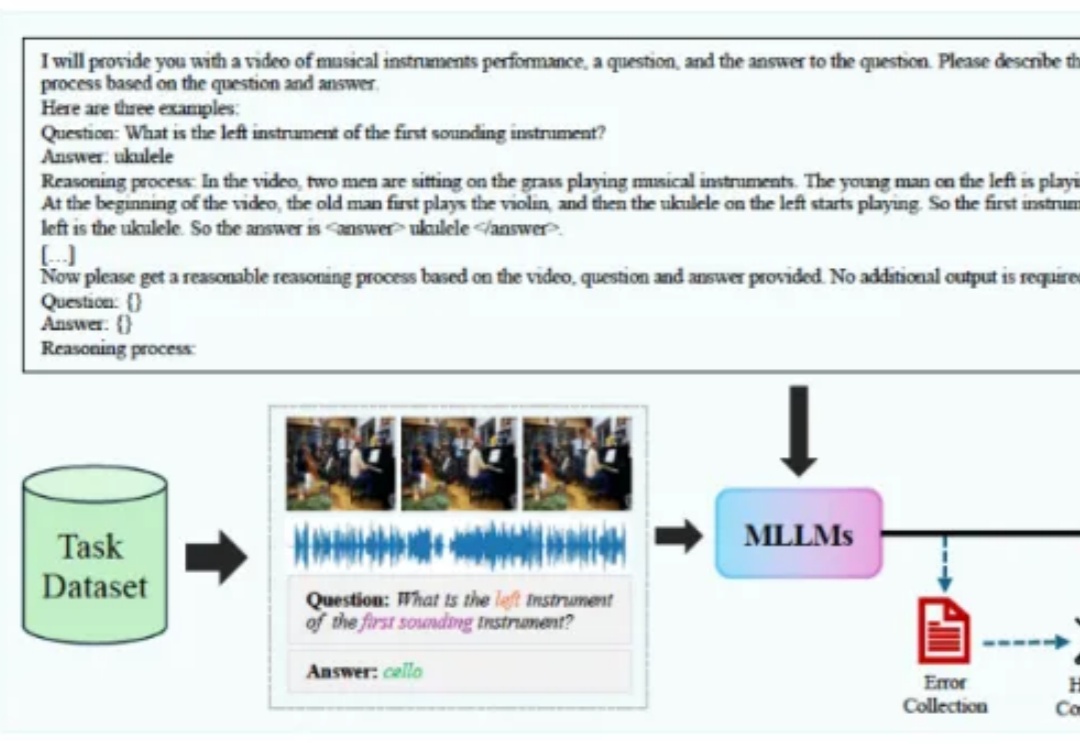
我们人类生活在一个充满视觉和音频信息的世界中,近年来已经有很多工作利用这两个模态的信息来增强模型对视听场景的理解能力,衍生出了多种不同类型的任务,它们分别要求模型具备不同层面的能力。