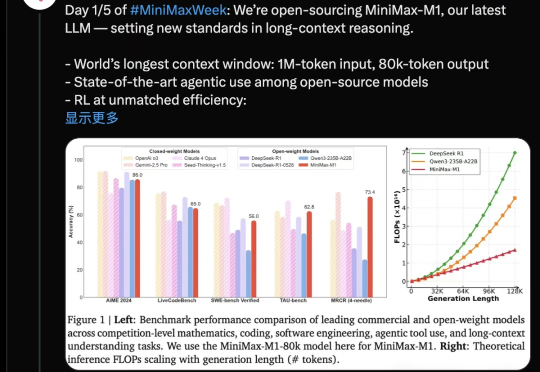
性能比肩DeepSeek-R1,MiniMax仅花380万训出推理大模型性价比新王|开源
性能比肩DeepSeek-R1,MiniMax仅花380万训出推理大模型性价比新王|开源国产推理大模型又有重磅选手。MiniMax开源MiniMax-M1,迅速引起热议。
来自主题: AI技术研报
9296 点击 2025-06-17 11:06
 搜索
搜索
国产推理大模型又有重磅选手。MiniMax开源MiniMax-M1,迅速引起热议。

当碳基生物还在为写文献综述,打开了一百个浏览器窗口时,隔壁AI已经卷起来了。(doge)

Anthropic 前两天发了一篇文章,重点讨论了他们是如何通过多智能体系统来构建 claude 的“深度研究功能”。

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
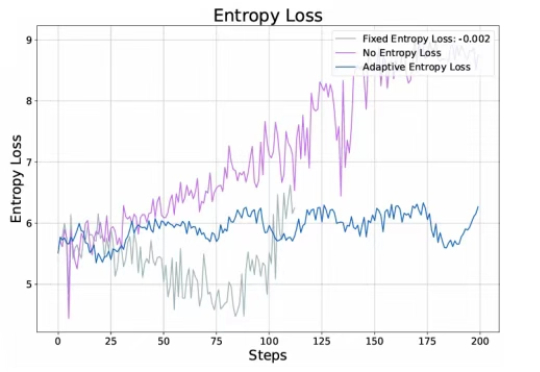
近年来,链式推理和强化学习已经被广泛应用于大语言模型,让大语言模型的推理能力得到了显著提升。

您有没有发现一个奇怪的现象:同样是Vibe coding,有些人轻松拿到完整的Flask应用,有些人却只得到几行if-else语句?剑桥大学计算机科学与技术系的研究者们最近发布了一项研究,用科学的方法证实了我们的直觉——AI确实会"看人下菜碟"。

当前,Agentic RAG(Retrieval-Augmented Generation)正逐步成为大型语言模型访问外部知识的关键路径。但在真实实践中,搜索智能体的强化学习训练并未展现出预期的稳定优势。一方面,部分方法优化的目标与真实下游需求存在偏离,另一方面,搜索器与生成器间的耦合也影响了泛化与部署效率。
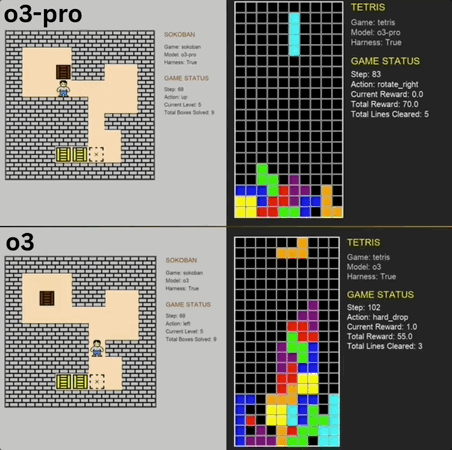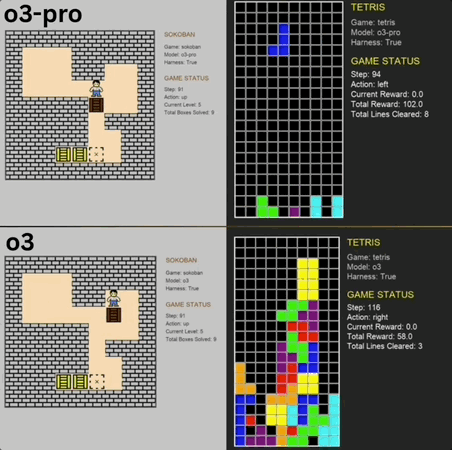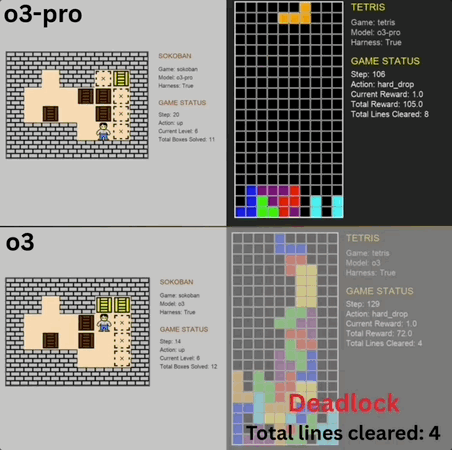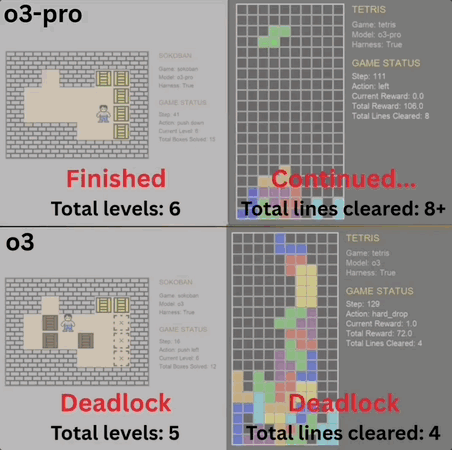
推箱子、俄罗斯方块……这些人类的经典怀旧小游戏,也成大模型benchmark了。 o3-pro刚刚也挑战了这两款游戏,而且表现还都不错,直接突破了benchmark上限
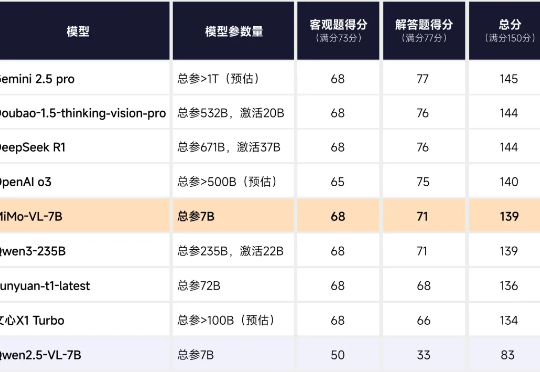
上上周的 2025 高考已经落下了帷幕!在人工智能领域,各家大模型向数学卷发起了挑战。
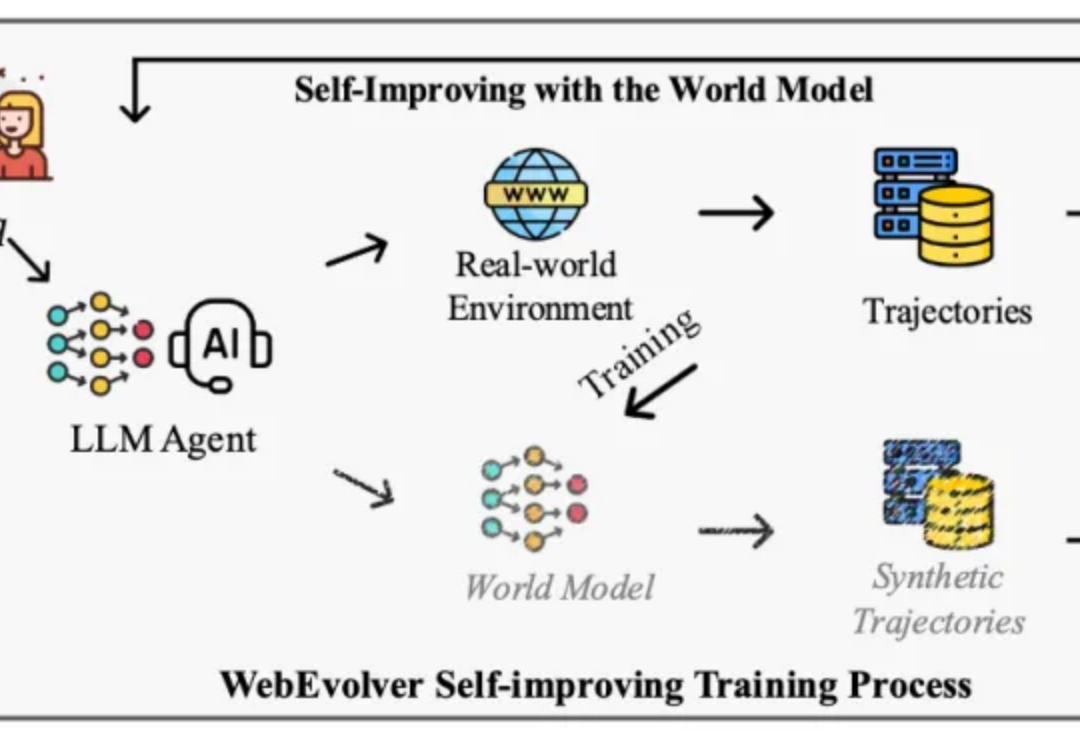
让网页智能体自演进突破性能天花板!
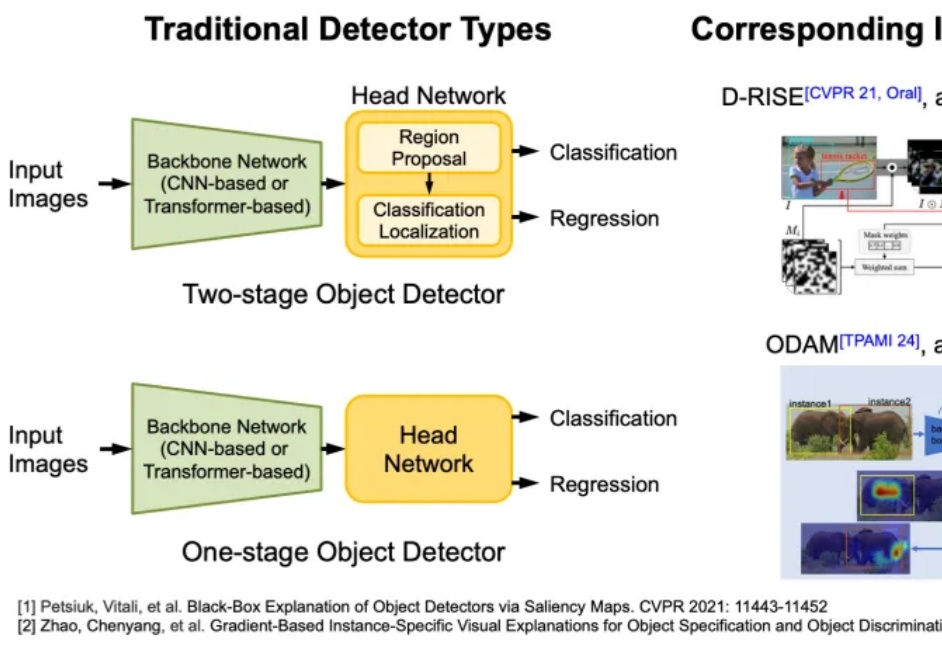
AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。
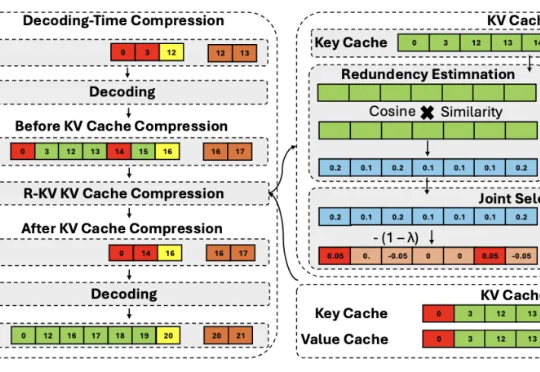
推理大模型虽好,但一个简单的算数问题能推理整整三页,还都是重复的“废话”,找不到重点……

苹果一篇论文,再遭打脸。研究员联手Claude Opus用一篇4页论文再反击,揭露实验设计漏洞,甚至指出部分测试无解却让模型「背锅」的华点。

在金融科技智能化转型进程中,大语言模型以及多模态大模型(LVLM)正成为核心技术驱动力。尽管 LVLM 展现出卓越的跨模态认知能力

本文深入剖析 MiniCPM4 采用的稀疏注意力结构 InfLLM v2。作为新一代基于 Transformer 架构的语言模型,MiniCPM4 在处理长序列时展现出令人瞩目的效率提升。传统Transformer的稠密注意力机制在面对长上下文时面临着计算开销迅速上升的趋势,这在实际应用中造成了难以逾越的性能瓶颈。
最近研究 n8n , 发现各种输入、输出都用到 JSON 格式。对 AI 开发来说, 为了生成可控,也会用这种格式。

昨天最热的的两篇文章是关于多智能体系统构建的讨论。 先是 Anthropic 发布了他们在深度搜索多智能体构建过程中的一些经验,具体:包括多智能体系统的优势、架构概览、提示工程与评估、智能体的有效评估等方面。

AI从医疗工具变身为协作队友,斯坦福大学研究揭示:医生诊断准确率竟飙升10%!70名美国执业医生参与的真实测试,AI-first、AI-second与传统诊断,谁能更精准破解临床谜题?

AI两天爆肝12年研究,精准吊打人类!多大、哈佛MIT等17家机构联手放大招,基于GPT-4.1和o3-mini,筛选文献提取数据,效率飙3000倍重塑AI科研工作流。

AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。

只用一个模型,就能边思考边动手,涮火锅、调鸡尾酒,还能听你指挥、自己纠错 —— 未来通用机器人的关键一跃,或许已经到来。
作为一个专注用AI解决具体场景问题的自媒体小博主,每一个场景我一般都搓一个提示词出来,随着覆盖的场景越来越多,我的提示词库也变得越来越庞大。
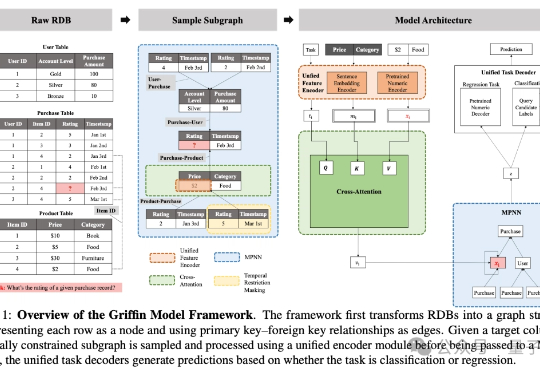
在企业系统和科学研究中普遍存在、结构复杂的关系型数据库(Relational DataBase, RDB)场景中,基础模型的探索仍处于早期阶段。
真正的智能在于理解任务的模糊与复杂,Context Scaling 是通向 AGI 的关键一步。
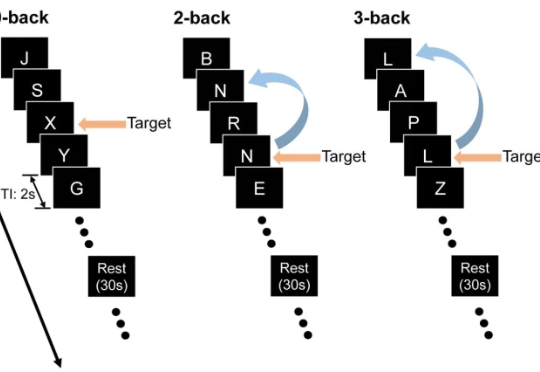
最近,来自约翰・霍普金斯大学与中国人民大学的团队设计了三套实验,专门把关键线索藏在上下文之外,逼模型「凭记忆」作答,从而检验它们是否真的在脑海里保留了信息。
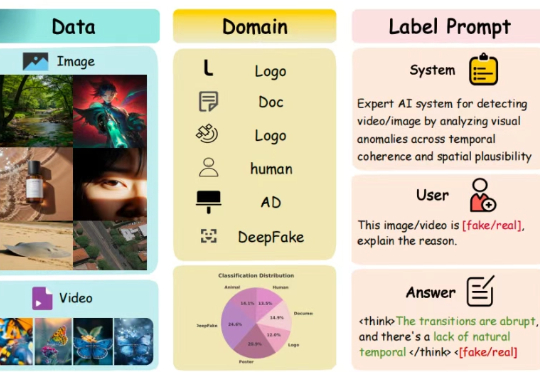
想象一下:你正在浏览社交媒体,看到一张震撼的图片或一段令人震撼的视频。它栩栩如生,细节丰富,让你不禁信以为真。但它究竟是真实记录,还是由顶尖 AI 精心炮制的「杰作」?如果一个 AI 工具告诉你这是「假的」,它能进一步解释理由吗?它能清晰指出图像中不合常理的光影,或是视频里一闪而过的时序破绽吗?

研究多智能体必读指南。Anthropic 发布了他们如何使用多个 Claude AI 智能体构建多智能体研究系统的精彩解释。

研究人员发现,大语言模型的遗忘并非简单的信息删除,而是可能隐藏在模型内部。通过构建表示空间分析工具,区分了可逆遗忘和不可逆遗忘,揭示了真正遗忘的本质是结构性的抹除,而非行为的抑制。

就在刚刚的CVPR上,鹅厂3D生成模型混元3D 2.1正式宣布开源!

扩散建模+自回归,打通文本生成任督二脉!这一次,来自康奈尔、CMU等机构的研究者,提出了前所未有的「混合体」——Eso-LM。有人惊呼:「自回归危险了。」