
田渊栋:连续思维链效率更高,可同时编码多个路径,“叠加态”式并行搜索
田渊栋:连续思维链效率更高,可同时编码多个路径,“叠加态”式并行搜索AI也有量子叠加态了?
来自主题: AI技术研报
10130 点击 2025-06-19 15:25
 搜索
搜索
AI也有量子叠加态了?

AI上瘾堪比「吸毒」!MIT最新研究惊人发现:长期依赖大模型,学习能力下降、大脑受损,神经连接减少47%。AI提高效率的说法,或许根本就是误解!

普林斯顿大学和Meta联合推出的新框架LinGen,以MATE线性复杂度块取代传统自注意力,将视频生成从像素数的平方复杂度压到线性复杂度,使单张GPU就能在分钟级长度下生成高质量视频,大幅提高了模型的可扩展性和生成效率。
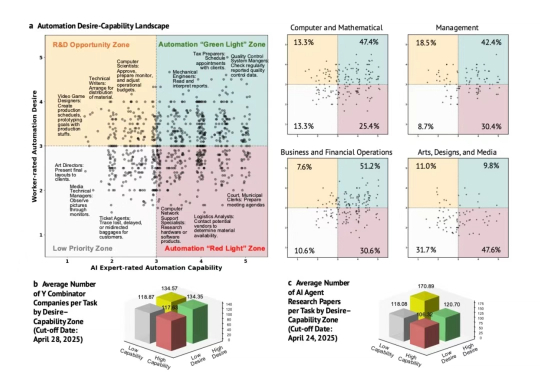
2025年1月到5月间,斯坦福大学的研究团队完成了一项本应在AI热潮开始时就进行的调查。他们采访了1500名美国员工和52名AI专家,评估了104个职业中的844项具体任务。
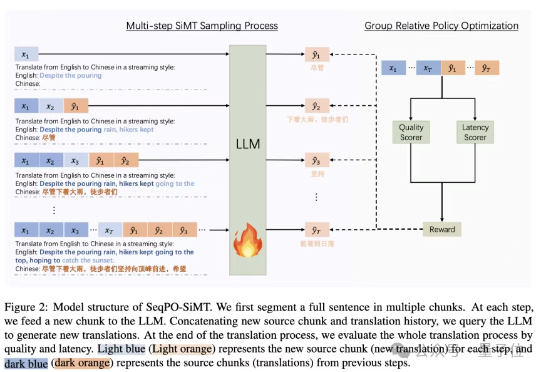
为此,香港中文大学、字节跳动Seed和斯坦福大学研究团队出手,提出了一种面向同声传译的序贯策略优化框架 (Sequential Policy Optimization for Simultaneous Machine Translation, SeqPO-SiMT)。
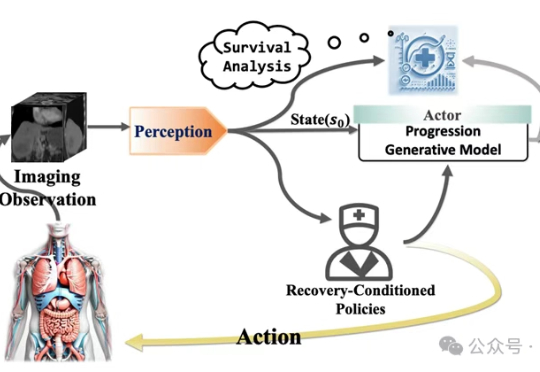
医学世界模型(MeWM)是一种创新的AI系统,能够模拟疾病演变并预测不同治疗方案下的肿瘤变化。通过生成术后肿瘤图像,可以帮助医生在术前评估治疗效果,优化治疗方案,显著提升临床决策的准确性,为精准医疗提供了有力支持。

OpenAI发布最新论文,找了到控制AI“善恶”的开关。

GRIT能让多模态大语言模型(MLLM)通过生成自然语言和图像框坐标结合的推理链进行「图像思维」,仅需20个训练样本即可实现优越性能!

AI想替代谁?谁愿意被替代?北大校友的研究首次揭示数据真相!

随着大型模型需要处理的序列长度不断增加,注意力运算(Attention)的时间开销逐渐成为主要开销。

你敢想象吗?你的工作“含人量”多少,决定你值多少钱?“含人量”是我首次创造的一个中文通俗词汇,用来转译论文核心概念“Human Agency Scale”,以后谁要引用,请注明出处是这里哈~

扩散模型在视频合成任务中取得了显著成果,但其依赖迭代去噪过程,带来了巨大的计算开销。尽管一致性模型(Consistency Models)在加速扩散模型方面取得了重要进展,直接将其应用于视频扩散模型却常常导致时序一致性和外观细节的明显退化。
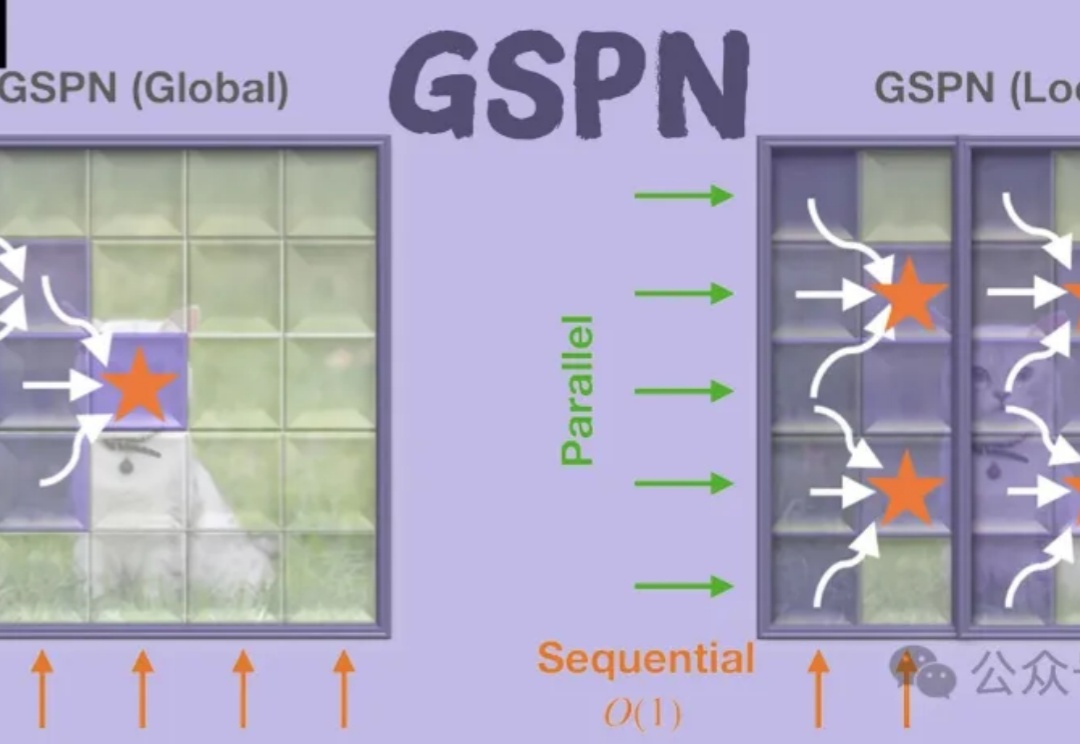
GSPN是一种新型视觉注意力机制,通过线性扫描和稳定性-上下文条件,高效处理图像空间结构,显著降低计算复杂度。通过线性扫描方法建立像素间的密集连接,并利用稳定性-上下文条件确保稳定的长距离上下文传播,将计算复杂度显著降低至√N量级。
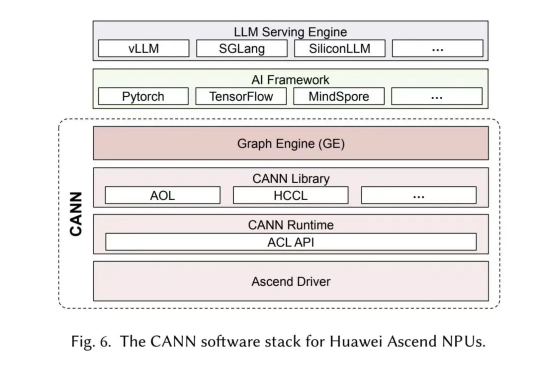
今年 4 月,围绕“华为芯片效率是否超越国际主流 AI 芯片和架构”的问题,网上曾引发一场激烈争论。
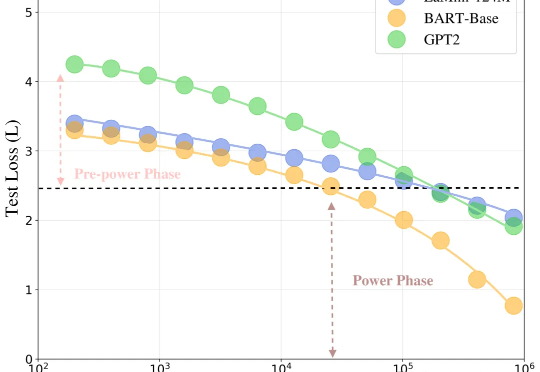
还在靠“开盲盒”选择大模型? 来自弗吉尼亚理工大学的研究人员推出了个选型框架LensLLM
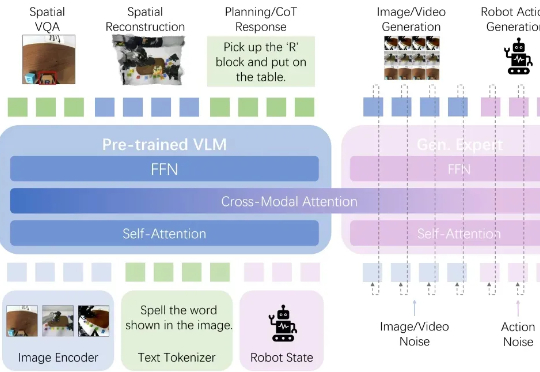
当 AI 放下海德格尔的锤子时,意味着机器人已经能够熟练使用工具,工具会“隐退”成为本体的延伸,而不再是需要刻意思考的对象。
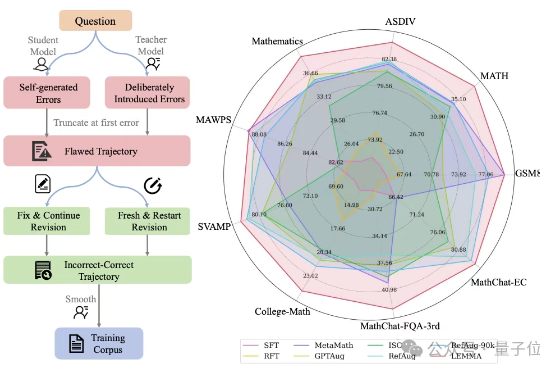
大模型学习不仅要正确知识,还需要一个“错题本”?

近年来,大型语言模型(LLM)在处理复杂任务方面取得了显著进展,尤其体现在多步推理、工具调用以及多智能体协作等高级应用中。这些能力的提升,往往依赖于模型内部一系列复杂的「思考」过程或 Agentic System 中的 Agent 间频繁信息交互。

AI生成内容著作权保护困境及解决路径。 本文旨在探讨人工智能生成内容的著作权保护问题,以平衡各方利益,推动著作权制度目标的实现,助力文化创意产业与智能科技的深度融合。
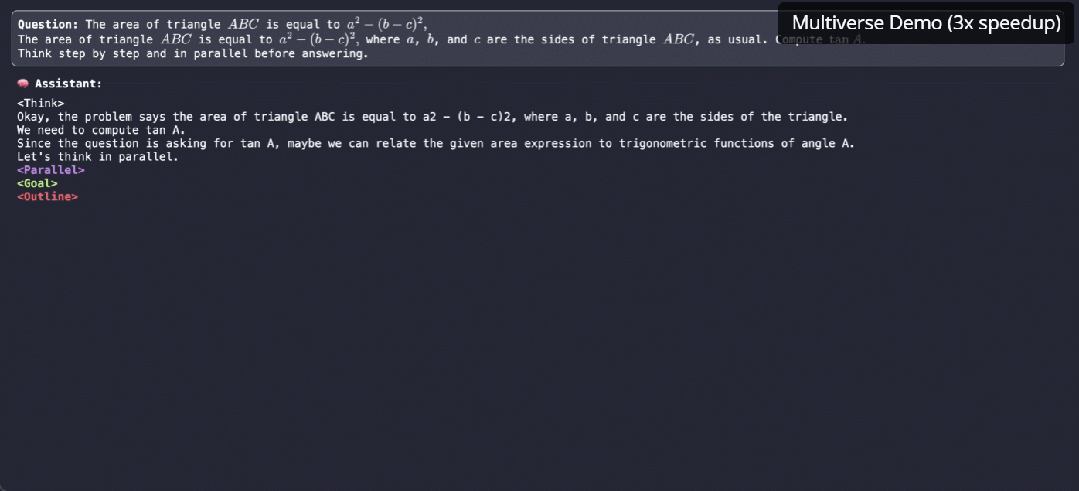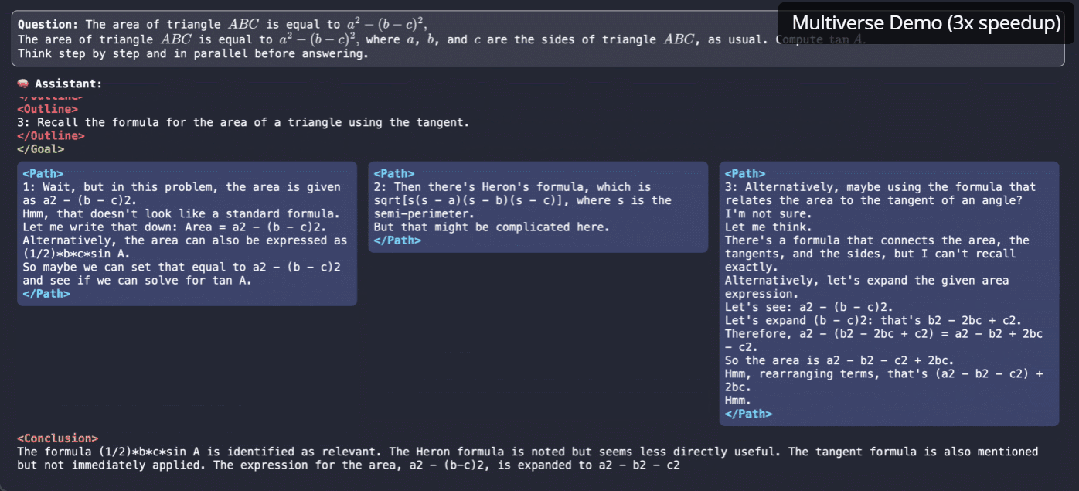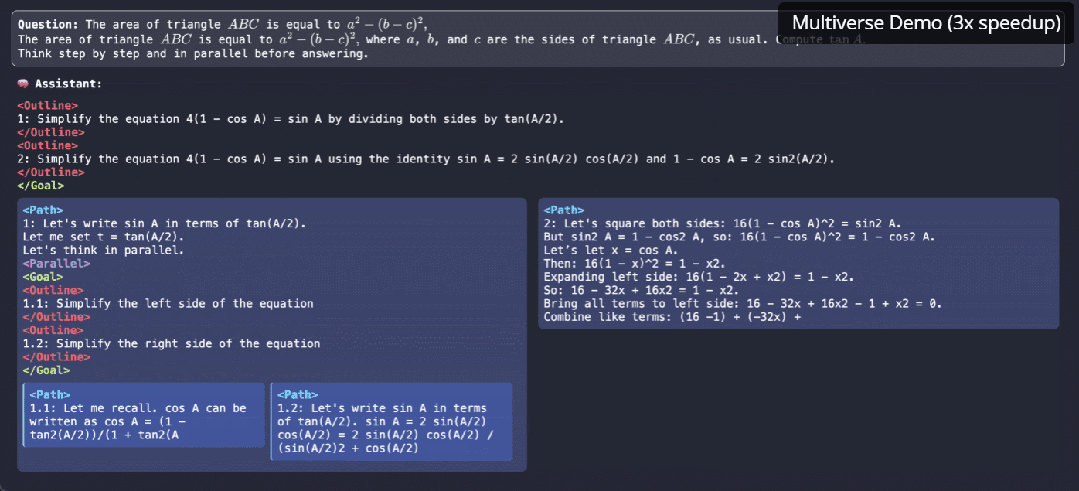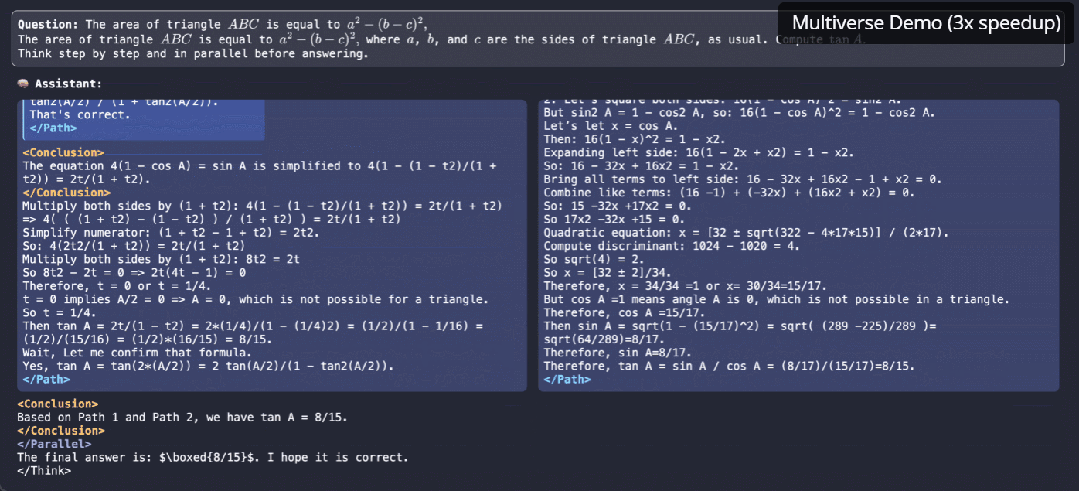
原生并行生成不仅仅是加速,它是我们对 LLM 推理思考方式的根本转变。
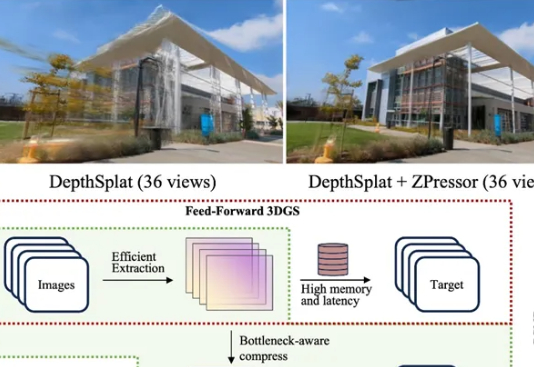
ZPressor能高效压缩3D高斯泼溅(3DGS)模型的多视图输入,解决其在处理密集视图时的性能瓶颈,提升渲染效率和质量。

您有没有这样的体验?一天的工作里,您可能用GPTo3写了个方案,然后切换到Cursor或者Trae里写代码,接着又打开Notion或者飞书整理文档。每个工具都挺聪明,但它们彼此之间就像生活在平行宇宙——写方案的GPT不知道您后来写了什么代码,写代码的Cursor也不清楚您的整体规划是什么。
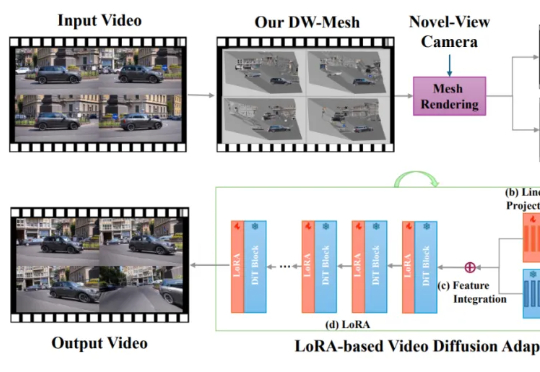
本文主要作者是 Bytedance Pico 北美高级研究员胡涛博士,近年来研究领域包括3D 重建与 4D 场景和视频生成,致力于得到一种最佳的物理世界表示模型。
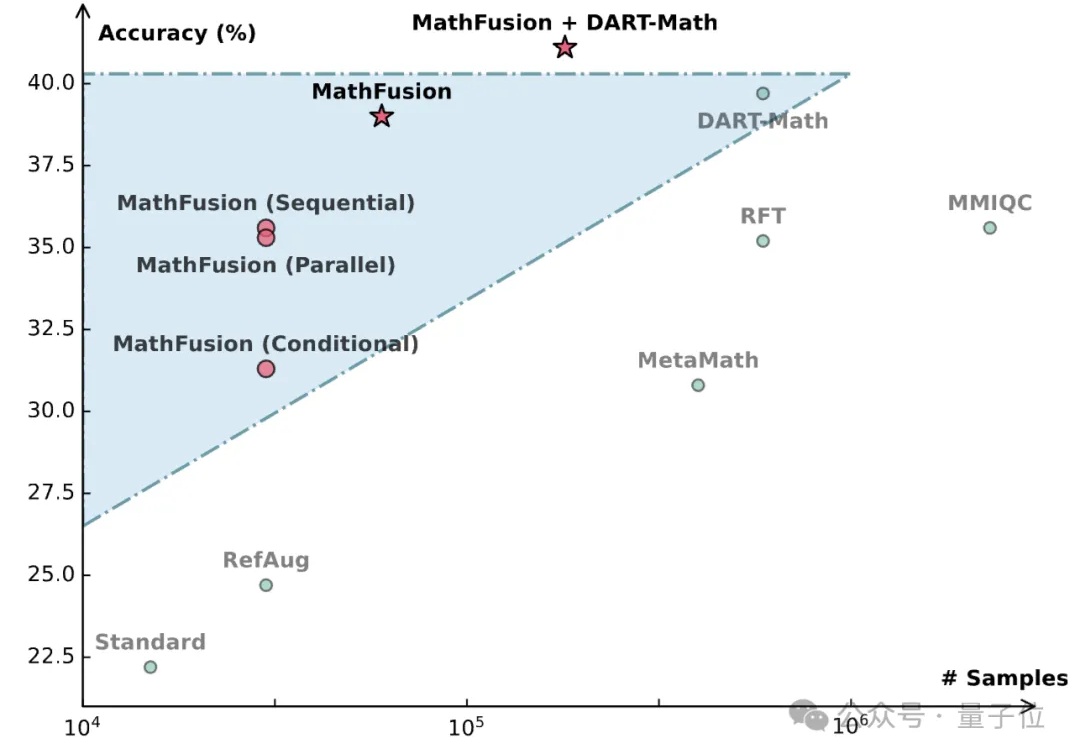
当前数学领域的数据生成方法常常局限于对单个问题进行改写或变换,好比是让学生反复做同一道题的变种,却忽略了数学题目之间内在的关联性。
编程智能体确实厉害!Transformer作者Llion Jones初创公司,专门收集了NP难题并测试了AI智能体,结果竟在上千人竞赛中排第 21!这意味着,它已经比绝大多数人写得好了。

面对Ai,我们开始感到,无趣了,甚至,失去了原本的那股劲头。
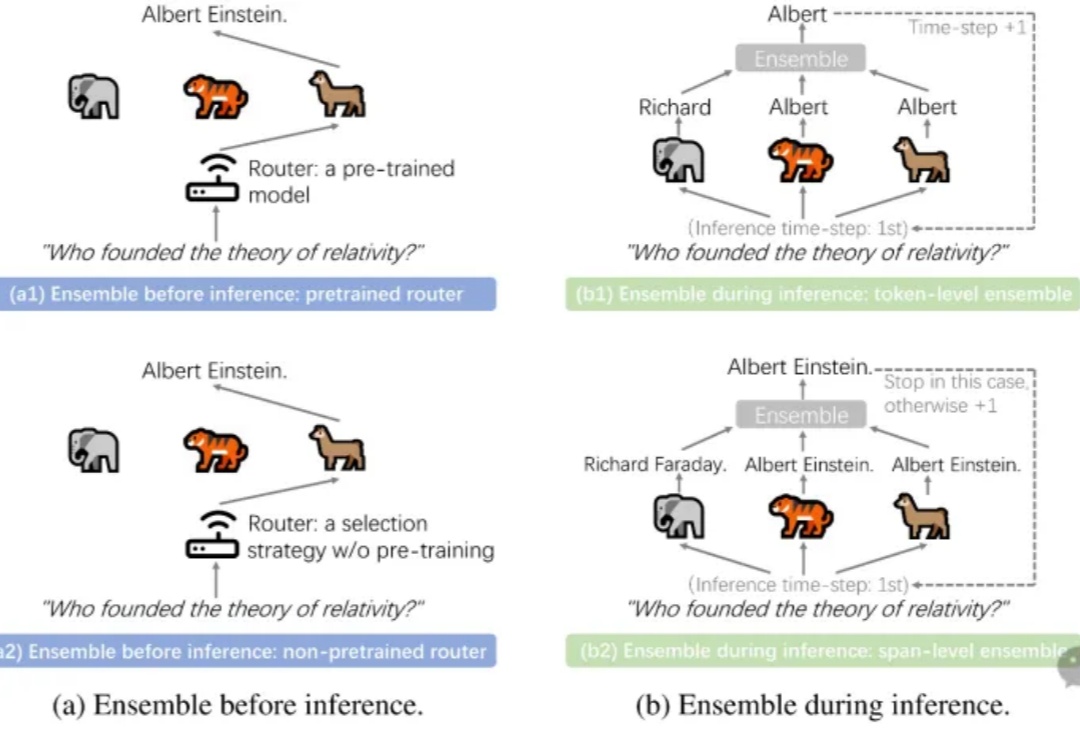
LLM Ensemble(大语言模型集成)在近年来快速地获得了广泛关注。它指的是在下游任务推理阶段,综合考虑并利用多个大语言模型(每个模型都旨在处理用户查询),从而发挥它们各自的优势。大语言模型的广泛可得性,以及其开箱即用的特性和各个模型所具备的不同优势,极大地推动了 LLM Ensemble 领域的发展。

NVIDIA等研究团队提出了一种革命性的AI训练范式——视觉游戏学习ViGaL。通过让7B参数的多模态模型玩贪吃蛇和3D旋转等街机游戏,AI不仅掌握了游戏技巧,还培养出强大的跨领域推理能力,在数学、几何等复杂任务上击败GPT-4o等顶级模型。
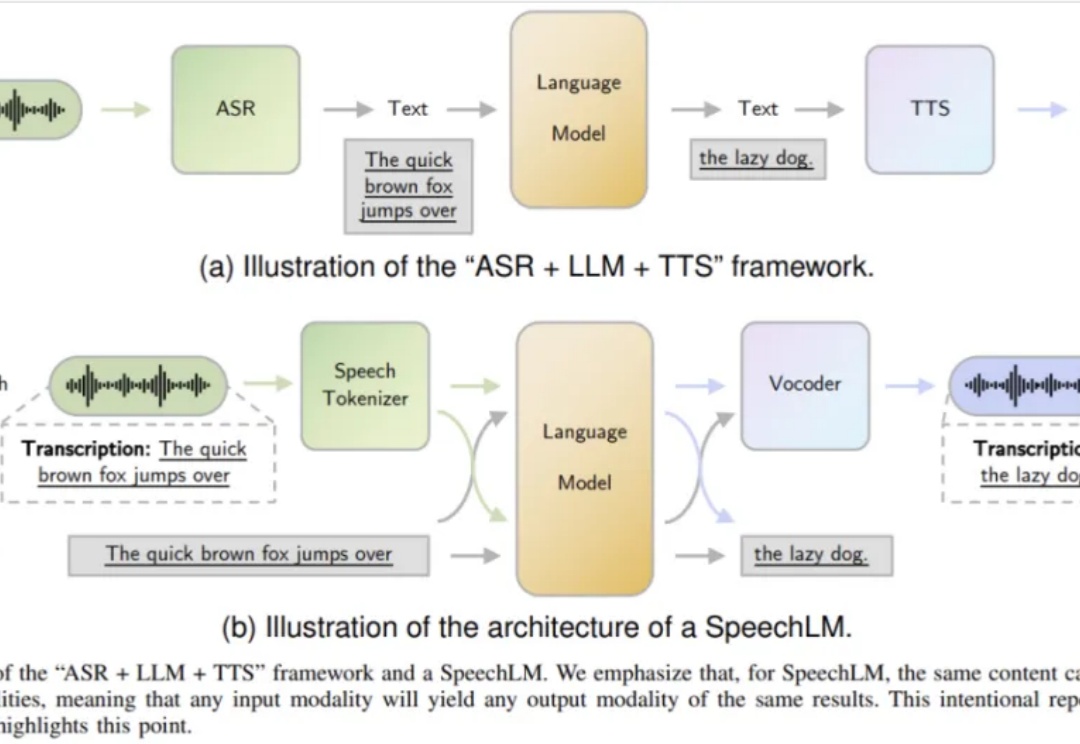
由香港中文大学团队撰写的语音语言模型综述论文《Recent Advances in Speech Language Models: A Survey》已成功被 ACL 2025 主会议接收!这是该领域首个全面系统的综述,为语音 AI 的未来发展指明了方向。
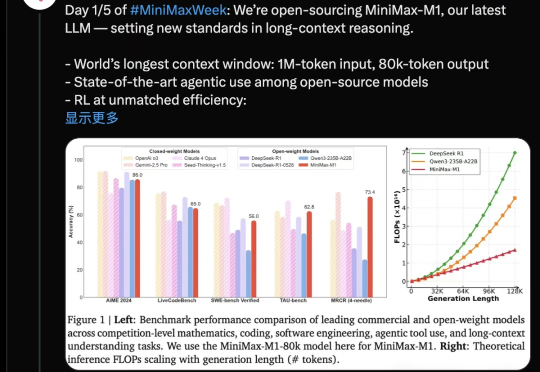
国产推理大模型又有重磅选手。MiniMax开源MiniMax-M1,迅速引起热议。