# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
RAG 系统上线后答案出错,绝大多数团队的第一反应都是换更贵的模型、反复调试 prompt。
但有时候,问题其实出在检索层,RAG根本没有召回正确的文档。而这种问题,如果没有量化评估,几乎很难被发现。
本文将系统讲解如何通过Recall精准定位检索问题,以及如何借助混合检索、重排、查询改写等手段优化RAG。
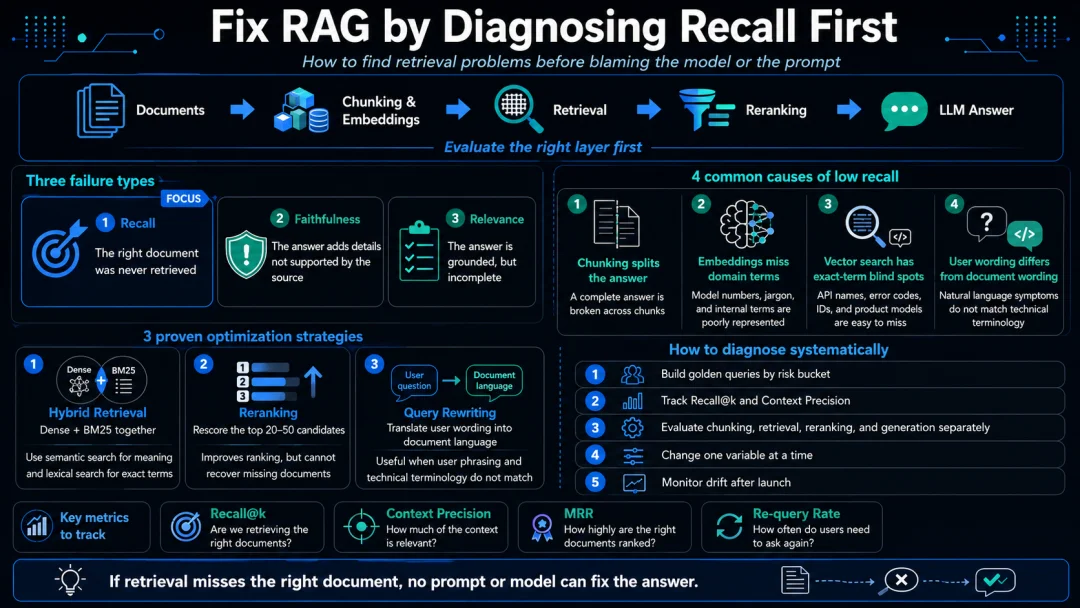
在一个RAG中,它的流程通常是这样的:文档需要先进行切分和向量化,构建成可检索的索引;用户提问时,系统先从索引中召回相关文档,经过重排后将最相关的内容作为上下文注入 prompt,再由大模型生成最终答案并附上引用来源。
任何一个环节出问题,最终都会表现为答案错误,但原因却千差万别:chunk 切分不合理,会让完整的答案可能被拆成两半;索引没有及时更新,会让新增的文档永远无法被检索到;正确的文档确实被召回了,但排在第 20 位,会超出模型的上下文窗口;即使前几位都有相关内容,上下文窗口不够大也会导致关键证据被截断。
所以评估的第一件事,是知道错在哪一层。
如果检索层根本没有找到正确的文档,那么后续的重排、生成、引用都无从谈起,这是召回(recall)问题。
如果正确文档已经被召回,但模型编造了文档中不存在的细节,这是忠实度(Faithfulness)问题。
如果模型生成的每一句话都有文档依据,但没有完整回答用户的问题,这是相关性(Relevance)问题
这篇文章先讲第一层:Recall。
要系统性分析召回率问题,我们首先需要明确两个核心评估指标。
第一个是Recall@k,它是衡量检索系统召回能力的核心指标,回答一个最根本的问题:所有应该被找到的相关文档中,有多少出现在了前 k 个检索结果里。比如当 k=5 时,如果目标文档没有进入前 5 名,那么无论后面的大模型有多强大,它都只能凭空编造答案。在查询产品型号、API 名称、合同编号、错误码这类精确词汇时,纯向量检索的召回率往往会出现断崖式下降。
第二个是上下文精确率(Context Precision)。Recall@k 高并不意味着检索层就没有问题了,因为它只关心有没有找到,不关心找回来的东西好不好。如果前 5 个结果里只有 1 个正确的 chunk,另外 4 个都是强干扰项,那么即使 Recall@5 达到了 100%,模型仍然很可能被错误的上下文带偏。Context Precision 衡量的是:最终进入模型上下文窗口的内容中,有多少是真正对回答问题有帮助的。
以下是四个常见的导致recall低的原因:
问题一:Chunking 把答案切散了
文档chunk策略是决定召回率上限的最基础因素。固定长度切分(通常每 512 或 1024 个 token 一个 chunk)是最简单也最常用的方式,但它的粗暴性经常导致完整的语义单元被拦腰截断。比如用户问 "如何配置 Nginx 超时参数",完整的配置步骤可能刚好被切分到两个 chunk 中,检索系统只能召回其中一个,模型看到的自然就是不完整的答案。
滑动窗口切分(设置 50-100 个 token 的重叠)能在一定程度上缓解边界问题,但会引入大量重复内容。如果同一段关键信息出现在三个不同的 chunk 里,检索结果可能会被这三个重复 chunk 占据,挤掉了其他同样相关但不重复的证据。
语义分割(按段落、标题、章节等文档结构切分)更符合人类的阅读习惯,能最大程度保留语义完整性,但它对格式不规范的文档几乎无能为力。企业内部的 Wiki、客服聊天记录、工单系统的文本往往没有清晰的段落边界和统一的格式,语义分割的效果会大打折扣。
在实际工程中,没有一种切分策略能覆盖所有场景。技术文档优先使用语义分割,配合滑动窗口作为兜底;聊天记录、工单这类非结构化文本可以使用固定长度切分并适当增大重叠比例;API 文档、配置说明这类结构化程度高的内容则可以直接按 section 切分。
最重要的是,你的测试集必须覆盖所有真实的文档类型,才能验证切分策略的有效性。
问题二:Embedding 对领域术语不敏感
通用 embedding 模型(OpenAI text-embedding-3、BGE-M3)领域适应性不足是召回率的另一个常见瓶颈。它们在常见语义任务上表现不错,但对领域特有术语、产品型号、内部黑话的理解能力有限。
用户问「XR-2048 的功耗参数」,embedding 模型可能把它映射到「功耗」「参数」这些通用概念附近,但「XR-2048」这个型号本身在向量空间里没有稳定的近邻。检索回来的可能是其他型号的功耗说明,语义上沾边,但型号完全不对。
如果你的知识库里有大量领域术语、产品型号、内部缩写,通用 embedding 的 Recall 会遇到瓶颈。这时候有两条路:要么用混合检索补精确词命中,要么用领域数据微调 embedding 模型。微调成本高,但如果你的知识库规模够大、术语够多,收益也明显。
问题三:向量检索的精确词盲区
向量检索本身存在天然的精确词盲区。向量检索的核心原理是将文本转换为高维向量向,然后找最近的内容。它擅长语义理解。你问「如何退款」,它能找到写着「申请退货流程」的段落,两者在向量空间里距离很近。
但它对精确词汇天然无力。产品型号、API 名称、合同编号、错误码,这类词在向量空间里没有足够稳定的近邻。纯向量检索要么找不到,要么找回来的是语义沾边但词汇完全不匹配的内容。
BM25 是另一条路。它不管语义,只看词本身,查什么词找什么词,对精确术语可靠得多。但 BM25 不理解「退款」和「退货」是同一回事,换了个说法就搜不到了。
两种方法各有盲区,单独用哪个,Recall@k 的天花板都会被牢牢限制住。
问题四:用户问题表达不清晰
用户问题与文档表达之间的鸿沟是容易被忽略的召回率杀手。用户习惯用口语化的方式描述问题,而技术文档则使用标准化的专业术语。比如用户说 "服务偶尔卡住",但文档里对应的原因是 "连接池耗尽"、"线程死锁"、"GC 停顿"。无论是向量检索还是 BM25,都无法自动完成这种从口语症状到技术术语的语义跨越,自然也就无法召回正确的文档。
针对上述四个常见的召回率问题,行业内已经形成了三种经过工程验证的成熟优化策略。
解法一,混合检索:让语义和精确词同时工作
混合检索是解决精确词盲区问题的首选方案。它的核心思想是将稠密向量检索(Dense)和稀疏向量检索(Sparse,通常是 BM25)结合起来,让 Dense 负责语义匹配,Sparse 负责精确词汇匹配,然后将两路检索结果通过特定的算法融合成一个统一的排名。
如果你的测试集中有大量精确词查询,混合检索通常能让 Recall@5 获得立竿见影的提升。
Milvus 向量数据库原生支持混合检索能力,你不需要搭建两套独立的检索系统,也不需要在业务层手动合并结果。同一个 Collection 中可以同时存储稠密向量和稀疏向量字段,数据库内部会自动完成检索和融合。
这里有一个容易踩坑的细节:如果使用外部稀疏模型(比如 BGE-M3)生成稀疏向量,那么 dense 和 sparse 向量都是由应用侧生成后插入数据库的;但如果使用 Milvus 内置的 BM25 Function,那么你只需要在原始文本字段上开启 analyzer,稀疏向量会由 Milvus 在内部自动生成,查询时直接传入原始文本即可。很多开发者会在这里犯错,试图手动插入 BM25 的稀疏向量字段,其实完全没有必要。
以下是 Milvus 混合检索的核心代码示例(只看查询形态,schema 和 BM25 function 的创建先略过):
from pymilvus import MilvusClient, AnnSearchRequest, RRFRanker
client = MilvusClient("milvus_demo.db")
# Dense 检索请求
dense_req = AnnSearchRequest(
data=[dense_vector],
anns_field="dense_vector",
param={"metric_type": "COSINE"},
limit=20
)
# Sparse 检索请求(BM25)
sparse_req = AnnSearchRequest(
data=[query_text], # 直接传文本,Milvus 内部走 BM25
anns_field="sparse_vector",
param={"metric_type": "BM25"},
limit=20
)
# RRF 融合
results = client.hybrid_search(
collection_name="knowledge_base",
reqs=[dense_req, sparse_req],
ranker=RRFRanker(),
limit=5,
output_fields=["content", "source"]
)
这段代码的核心价值在于,它将两条检索路径的结果融合操作下沉到了数据库层。替代过去,用向量数据库做语义检索,再外挂一个 Elasticsearch 做关键词检索,然后在业务层手动合并两个系统,带来的双倍的运维成本、双倍的写入链路复杂度,以及数据一致性问题。
混合检索相比单一检索方法,在精确词查询和多跳问题上的召回率通常有显著改善,提升幅度直接取决于测试集中精确词查询的占比。
解法二,Reranker:在候选集里做二次排序
混合检索提升了召回率,但进入 top 5 的内容里仍然有噪声。Reranker 的作用是在候选集基础上做二次排序,把真正相关的内容排到前面。
第一阶段(candidate generation)用向量检索或混合检索快速召回 top 20-50,第二阶段(reranking)用更强但更慢的模型(cross-encoder、LLM)对候选集重新打分。
Reranker 不能修复候选集缺失的问题。如果第一阶段召回的候选集中缺少正确文档,Reranker 再强也只能在现有候选集里排序。所以评估 Reranker 之前,先确认候选集的 Recall 是否可接受。
从评估角度看,Reranker 的价值用 MRR(Mean Reciprocal Rank)衡量:正确文档的平均排名位置。如果第一阶段把正确文档排在第 15 位,Reranker 把它提到第 2 位,MRR 从 1/15 提升到 1/2。
但 Reranker 有成本。Cross-encoder 对每个候选 chunk 都要做一次模型推理,延迟会增加 50-200ms。如果你的 p95 延迟预算只有 500ms,Reranker 可能吃掉一半。
简单查找(FAQ、单文档问答)不需要 Reranker,混合检索加 top 3 就够了。复杂问题(多跳、长尾、歧义查询)值得用 Reranker,但要做延迟分层:大部分流量走快速检索,高风险或低置信度查询才走 Reranker。
解法三,Query Rewriting:跨越表达鸿沟
用户问服务偶尔卡住,文档写的是连接池耗尽、线程死锁、GC 停顿」。检索需要把口语症状映射到技术术语上。
Query rewriting 的思路是在检索前先改写用户问题。比如把卡住扩展成阻塞、无响应,把跑得慢映射到性能优化p。用户问超时配置,补充Nginx、upstream、proxy_read_timeout这些领域上下文。
可以用规则(同义词词典),也可以用小模型(few-shot prompt)。规则快但覆盖有限,模型灵活但增加延迟。
如果你的知识库是技术文档、API 说明、故障手册,用户问题和文档表达的鸿沟很大,query rewriting 能进一步提升 Recall。但如果知识库本身就是用户生成内容(工单、聊天记录),表达鸿沟不明显,rewriting 的收益有限。
Query rewriting 的边界在于它只能改写问题,不能改变知识库本身。如果文档里根本没有写「连接池耗尽」,改写再多次也找不到。这时候需要回到文档层面,补充常见症状和对应的技术原因。
知道了召回率低的原因和优化方法还不够,更重要的是如何系统性地发现和定位这些问题。以下是几个优化小技巧:
技巧一:测试集要覆盖真实风险
很多开发者都有过这样的经历:自己测了几十个问题,感觉召回率还不错,但上线后用户一用就出问题。最常见的原因就是测试集设计不合理:测试用例全是 "退款流程是什么"、"如何联系客服" 这类通用语义问题,完全没有覆盖产品型号、API 名称这类精确词查询。
Golden queries 是一组精心设计的测试用例,用来覆盖系统的真实风险。它不是随机抽样,而是按问题类型分桶:精确词查询(产品型号、API 名称、合同编号)、多跳问题(答案分散在多个文档里)、长尾问题(低频但高风险的查询)、不可回答问题(知识库里没有答案,系统应该拒绝)、权限过滤问题(不同用户看到的文档范围不同)。
每个桶里至少要有 5-10 条测试用例。每次评估时,不要只看整体的平均 Recall@5,平均召回率看起来不错,很可能掩盖了某一类查询表现极差的事实。需要要按桶分别统计结果,发现被平均值掩盖的盲区。如果精确词查询的 Recall 明显低于其他桶,你就可以立刻定位到问题所在。
技巧二:隔离每一层,才能定位根因
RAG 系统是一条多阶段流水线,只有隔离每一层进行单独评估,才能精准定位根因。
很多团队在优化 RAG 时犯的最大错误,就是同时改动多个变量:改了 chunk 大小,又换了 embedding 模型,还调了 prompt,最后发现效果变好了,但根本不知道是哪个改动起了作用。
正确的做法是,将 RAG 系统拆解成独立的层级,逐层进行评估:
chunk层:切分后的 chunk 是否保留了完整的语义单元?答案是否被切散到了多个 chunk 中?
检索层:Recall@k 是多少?候选集中是否包含了所有正确的文档?
Rerank层:MRR 提升了多少?正确文档的排名是否得到了明显提升?
Generation 层:答案是否有证据支撑?是否完整满足了用户的意图?
只有这样逐层隔离评估,你才能知道问题到底出在哪一层,应该去调 chunking、调 embedding、调 reranker,还是改 prompt。
要进一步确认根因,还需要做控制变量对比测试(controlled diffs):一次只改一个变量,其他所有参数都保持不变,然后对比评估指标的变化。如果同时改了三个变量,你永远无法知道是哪个变量真正起了作用。
技巧三:防止上线后 Recall 退化,需要做持续监控
即使系统上线后没有任何代码变更,召回率也可能会随着时间推移逐渐退化。这是很多团队容易忽略的问题。
导致召回率退化的常见原因有三个:
知识库更新但索引没有同步重建:新的文档不断加入,旧的文档被修改或删除,但向量索引还是三个月前的版本。
嵌入模型升级导致向量分布变化:OpenAI 等厂商会不定期更新嵌入模型,新版本的向量分布可能与旧版本有很大差异。旧文档的 embedding 是用旧模型生成的,新查询的 embedding 是用新模型生成的,两者在向量空间中的距离关系会发生变化,导致召回率下降。
用户问法发生变化:随着用户群体的扩大和产品的迭代,用户的提问方式也会逐渐变化。如果黄金查询集没有及时更新覆盖新的表达方式,召回率就会悄悄下滑。
因此,上线后的持续监控至关重要,我们需要重点监控以下几个指标:
当发现异常时,要及时将失败的案例加入黄金查询集,并在 CI 流水线中加入回归测试,确保后续的改动不会再次引入同样的问题。
最后值得一提的是,不是所有团队在一开始就需要搭建一套完整的评估流水线。小团队可以从最小可行评估开始:先构建 10 条左右的golden queries,覆盖精确词、多跳、长尾、不可回答这几类核心问题。每次系统改动前后,对比 Recall@5 和 Context Precision 的变化。每周抽取 20 条生产环境的真实查询进行人工评估,看 Recall是否符合预期。
等系统规模上来,再逐步补全:CI 回归测试(每次代码变更前跑 golden queries)、LLM-as-judge(自动评估 Faithfulness 和 Relevance)、Canary 发布(新版本先给 5% 用户,对比 Recall 变化)、Drift monitoring(持续监控 Recall 趋势和 query 分布)。
本文讲完了recall问题,接下来我们会分别讲RAG评估优化中的:
Faithfulness 和 Groundedness:答案有没有证据支撑、引用是否准确
Answer Relevance 和 LLM-as-Judge:答案有没有满足用户意图、Judge 怎么校准
三篇文章合起来,是一套完整的 RAG 评估工程实践。

Zilliz黄金写手:尹珉
文章来自于"Zilliz",作者 "尹珉"。


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
