# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去一年,硅谷 AI 投资圈里出现了一个越来越明确的变化:
资本市场开始重新评估“数据”本身的价值。
如果说上一阶段,大模型竞争的核心是参数规模、推理能力与基础模型性能;那么进入视频生成、世界模型(World Model)、空间智能与多模态阶段之后,行业关注点正在快速转向另一件事:
谁拥有更高质量、更结构化、更接近真实世界的数据。
最近,创作者平台 Wirestock 宣布完成 2300 万美元 Series A 融资,由 Nava Ventures 领投,SBVP(Sheryl Sandberg 参与创立)、Formula VC 与 I2BF Ventures 参投,公司累计融资规模达到约 2600 万美元。
但比融资金额更值得关注的是它如今的业务方向。
这家原本帮助摄影师向 Shutterstock、Adobe Stock 等图库平台分发内容的公司,已经在过去两年完成了一次彻底转型:
从“创作者素材平台”,变成 AI Labs 的多模态数据供应商。
根据公司披露的信息,目前 Wirestock 已经为全球六家最大的基础模型公司提供图像、视频、3D 与创意类训练数据;平台聚集超过 70 万 名摄影师、设计师与内容创作者,公司 ARR(年化收入)已经达到 4000 万美元,并累计向创作者支付约 1500 万美元 收入分成。
这些数字背后,其实反映的是 AI 行业一个正在迅速成型的新基础设施市场:
AI 模型公司,正在系统性购买“现实世界内容”。
而数据,正在从过去的“模型原材料”,逐渐演变成 AI 时代最重要的战略资源之一。
01
从“互联网数据”到“现实世界数据”,AI 行业正在进入下一阶段
过去几年的大模型浪潮,本质上建立在互联网文本之上。
无论是网页、论坛、代码库、百科、社交媒体、PDF 文档,都构成了第一代语言模型最核心的训练来源。
但当生成式 AI 开始进入视频、图像、3D、机器人与空间智能之后,问题开始发生变化。因为下一代模型需要理解的,已经不只是语言。它们需要进一步理解空间关系、运动轨迹、物理规律、视觉连续性、人类行为、场景结构、环境反馈,而这些能力仅靠文本几乎无法建立。
这也是为什么,最近一年整个 AI 行业开始出现一个明显趋势:
模型公司正在从“互联网抓取”,转向“专业数据采购”。尤其是:
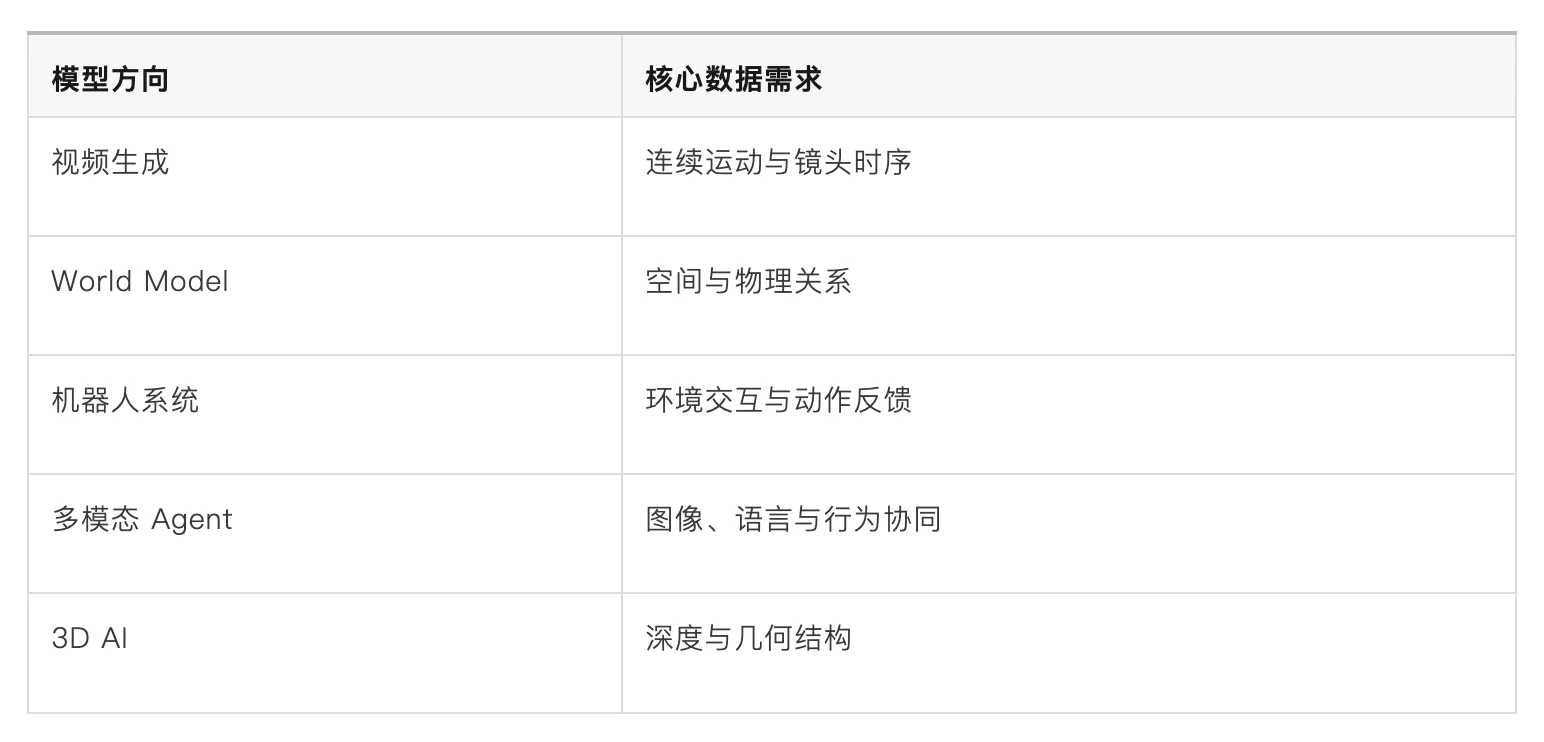
这些数据长期并不存在于公开互联网。它们真正掌握在游戏引擎、动画工作室、影视制作公司、创作者平台、摄影社区、3D 内容生态之中。
而 Wirestock,实际上正处在这条新产业链的中间层。
02
Wirestock 为什么会被资本市场重新定价?
从表面看,Wirestock 很容易被理解为一家传统创作者平台。
它最初的业务模式也确实如此:帮助摄影师、插画师与视频创作者,把内容同步分发到 Shutterstock、Getty Images、Adobe Stock 等平台,从而提升素材销售效率。
但生成式 AI 的出现,彻底改变了这类平台的价值逻辑。
因为 AI Labs 很快发现:真正稀缺的,并不是基础模型本身,而是“高质量、可授权、结构化的数据”。
过去几年,互联网抓取虽然帮助模型完成了第一阶段训练,但问题也越来越明显:
与此同时,创作者平台却天然拥有另一种更重要的资源:
高质量、具备明确版权归属、并且长期持续更新的内容资产。
于是,一个新的市场开始形成:
AI Labs 不再只是“爬互联网”,而开始直接采购数据。
Wirestock 正是在这一阶段完成转型。
03
这已经不是“素材平台”逻辑,而是“AI 数据基础设施”逻辑
从融资结构看,Wirestock 更接近新一代 AI 基础设施公司。
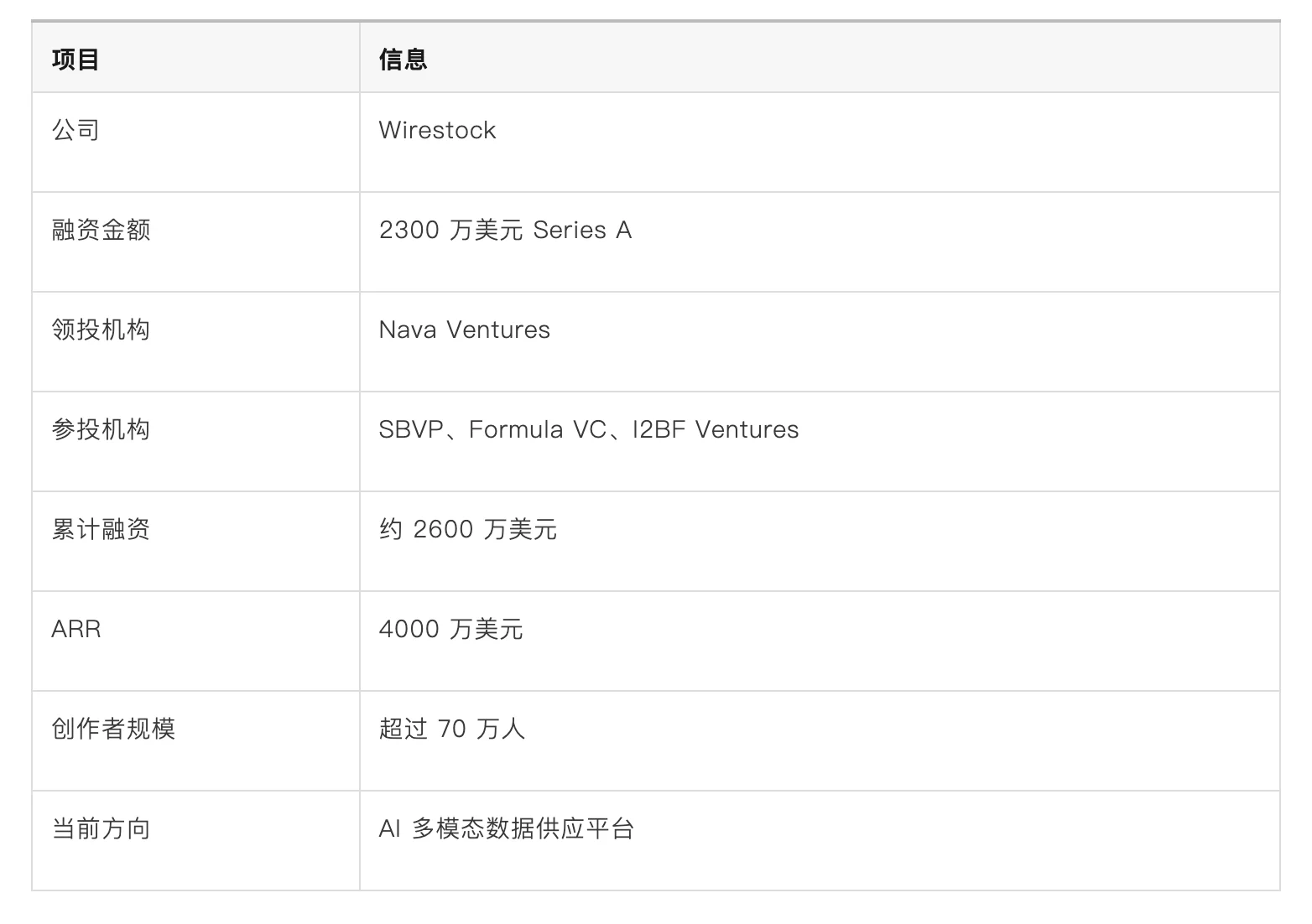
其中最值得关注的,并不是融资金额,而是它已经形成的数据供给能力。
根据公司披露,目前平台已经聚集:
并能够持续完成 AI Labs 的定制化数据需求。
这意味着 Wirestock 已经不仅是内容交易平台,而更像一个“分布式数据生产网络”。而这恰恰是 AI 行业当前最稀缺的能力之一。
因为今天真正限制模型进一步发展的,越来越不是模型架构,而是:
谁能持续获得高质量现实世界数据。
04
AI 公司真正需要的,不是“内容”,而是“可训练的数据结构”
这是当前 AI 数据行业最容易被忽略的一点。
AI Labs 采购的并不只是图片或视频本身,真正重要的是这些内容是否能够转化为“模型可消费的数据层”。
因此,Wirestock 的核心能力,并不只是聚合创作者,更重要的是它的数据处理体系。例如:
数据筛选、精细化标注、语义 annotation、多模态对齐、数据清洗、版权确认、数据格式转换、训练适配。
公司甚至透露,为了适应 AI 数据业务,内部部分团队已经重新训练,专门负责数据标注与 AI 数据处理。
这意味着未来 AI 数据行业真正的竞争壁垒很可能不是“拥有多少内容”,而是“谁能把复杂内容,转化为高质量训练数据”。
这也是为什么,整个行业越来越像早期 Scale AI 崛起阶段。Scale AI 的核心价值,本质上是把现实世界转化为 AI 可训练的数据系统。而 Wirestock 正在做的,则是:
把创意世界、多模态内容与视觉资产,转化为模型训练基础设施。
05
多模态时代,AI 行业正在进入“数据军备竞赛”
过去一年,模型能力差距正在逐渐缩小。但数据质量差距,却开始迅速扩大。
尤其是在视频生成、机器人、空间智能、3D 世界模型、多模态 Agent 这些方向里。
因为未来真正决定模型能力上限的,可能不再只是参数规模。而是模型是否真正理解“现实世界”。
这也是为什么,最近整个 AI 数据供应链开始快速升温:
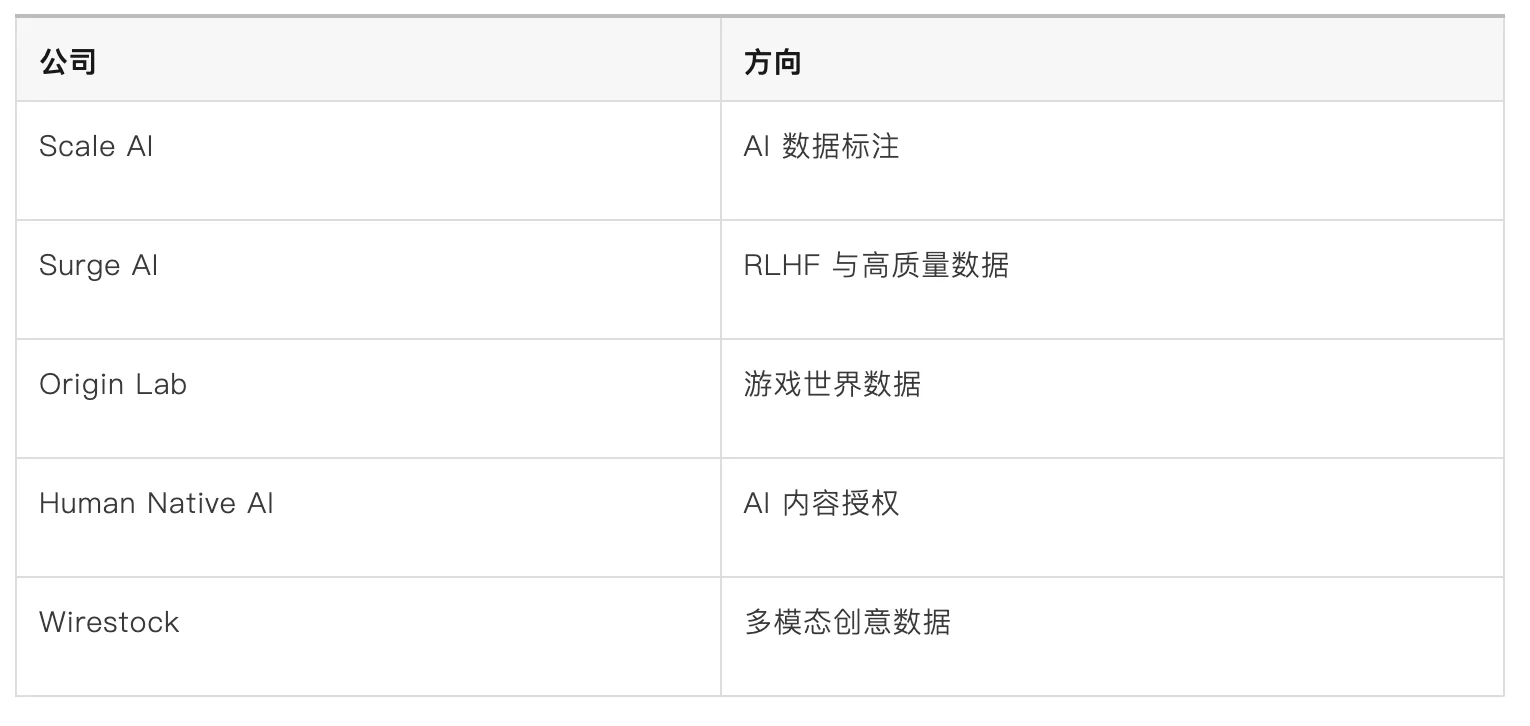
这些公司虽然方向不同,但本质上都在做同一件事:
建立 AI 时代的数据供给系统。
而行业现在越来越清晰的一点是:
未来最重要的数据已经不再只是网页文本,而是视频、3D、游戏资产、空间信息、现实环境、创作者内容、人类行为数据。
换句话说:AI 行业正在从“语言模型时代”,逐渐进入“世界模型时代”。
06
被重新定价的,不只是数据,而是“创作者经济”本身
Wirestock 的变化,还有一个更深层的意义,它实际上重新定义了创作者与 AI 的关系。
过去两年,围绕 AI 最大的争议之一,就是模型是否未经授权使用创作者内容训练。
而 Wirestock 提供了另一种可能:让创作者直接进入 AI 数据经济。
平台允许创作者:
截至目前,公司已经向贡献者累计支付约 1500 万美元。
这意味着创作者不再只是 AI 时代里的“被替代者”,他们也正在成为AI 基础设施的一部分。
而这很可能会成为未来整个行业的重要趋势:
从“平台抓取内容”,逐渐转向“数据许可经济”。
07
AI 行业真正争夺的,开始从模型转向“世界本身”
今天整个 AI 行业,一个越来越明显的现实是:
模型能力正在快速趋同。
但对于现实世界的理解能力,却仍然存在巨大差距。尤其是在视频生成、机器人、World Model、空间推理、多模态 Agent 这些方向里。
因为这些系统真正需要的,并不是更多网页,而是更真实、更连续、更结构化的现实世界数据。
这也是为什么,Wirestock、Origin Lab 这类公司会突然被资本市场重新定价。
它们表面上是内容平台,但更深层看,正在成为 AI 时代的新基础设施。
互联网时代最重要的平台,负责组织信息。
而 AI 时代,新的平台开始负责:组织“世界”。
文章来自于微信公众号 “Vibehood”,作者 “Vibehood”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
