# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Anthropic 发布了史上最强的模型 Claude Mythos。
也是史上最贵的。25/125 美元每输入/输出百万 Token,作为对比,Claude Sonnet 4.6 的价格是 3/15 美元——贵了将近 8 倍。

而这还只是 API 价格。Mythos 目前根本没有对普通用户开放,因为能力太强,Anthropic 自己都没想好怎么给我们用。
最强,也最贵。这两件事放在一起,某种程度上已经预示了接下来的走向:
模型越来越聪明,Token 越来越值钱,我们跟 AI 说话的成本,也越来越高。
但眼下的问题还不用等到 Mythos。就是普通的 Agent,甚至是对话聊天,在各种 Skill、记忆系统的加持下,发一句「你好」,都有可能用掉 13% 的月度 Token 额度。
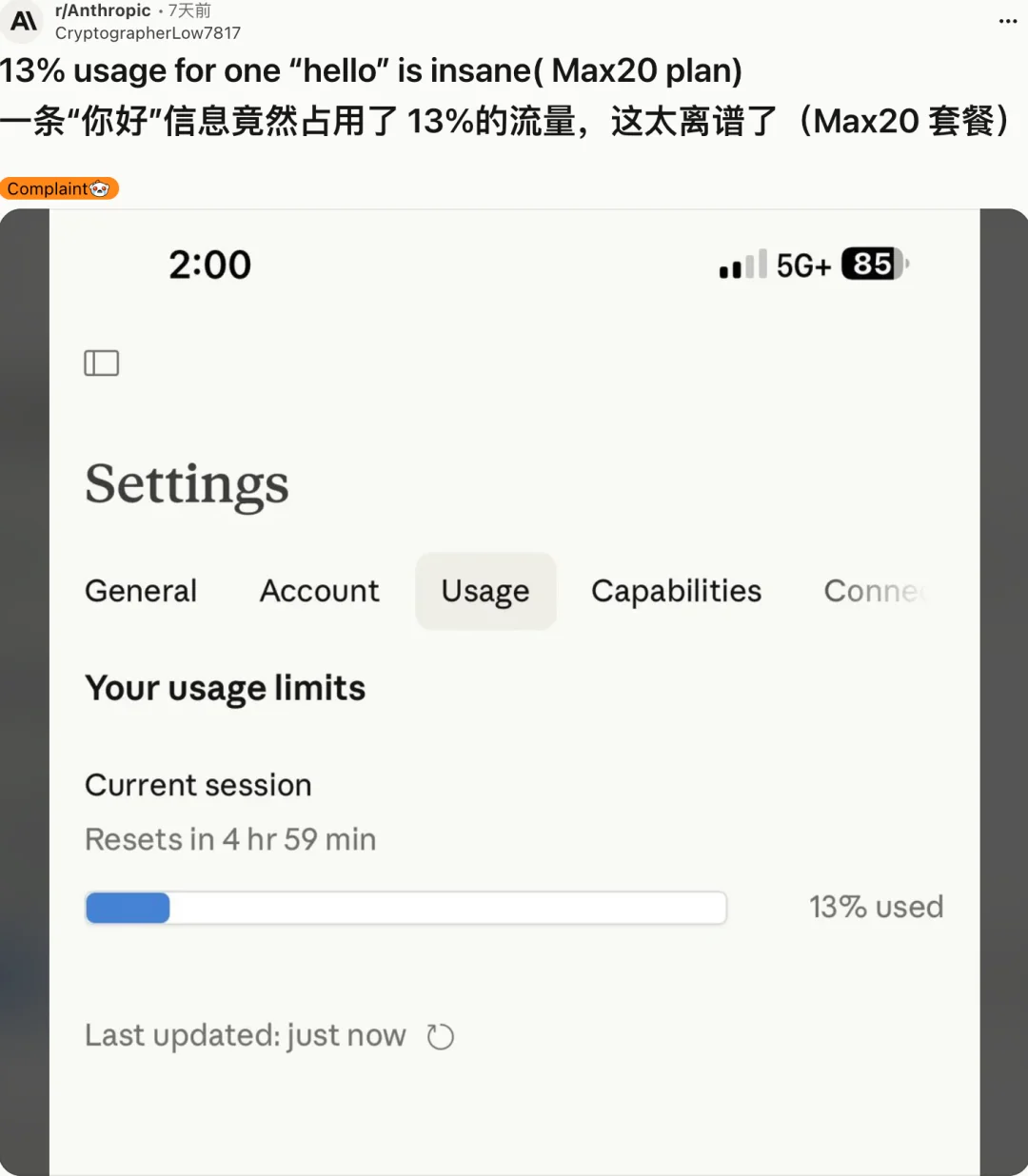
Reddit 讨论帖链接:https://www.reddit.com/r/Anthropic/comments/1s8wwra/13_usage_for_one_hello_is_insane_max20_plan/
AI 是越来越聪明,但我们可能快要跟它「说不起话」了。
怎么节省 Token 成了这段时间以来,社交媒体上热议的话题。
有人提出用文言文的方式和 AI 聊天,毕竟古人说话字斟句酌,没有半点废话;还有人想到在不同的模型之间快速切换,用聪明的 Claude 指定策略、Gemini 进行深度研究、然后 ChatGPT 来完成枯燥的流程工作。
这种感觉很像回到了 2000 年还没有数据流量的时候,用手机短信和朋友聊天,0.1 元/条,每条短信还有字数限制,超过字数会自动计算为两条短信,所以一定得事先组织好语言,把要讲的事情在一条短信内说清楚。
回到大模型,在对话框里每按一次发送,一边要担心上下文窗口有限,一边也在想这次又要花掉我多少 Token。
以文言相与,观若用字更少,然其实果更省乎?
前段时间,有网友在 X 上发梗图讨论用文言文,是不是能减少 Token 的使用。毕竟文言文相比白话文,用的字更少,把我们的语言都压缩成「之乎者也」的表达,所消耗的 token 按理说也会更少。
评论区都在调侃,这是在用人脑的 Token 来弥补 AI Token。

我们的大脑编译文言文不用花钱,消耗再多 Token 倒也无所谓;但真实的情况是,
消耗了脑力,写出了像模像样的文言文,最后并没有减少 Token 的使用。
对于大语言模型来说,越常用的词占用的 Token 越少,它并不是按照文字的长短来定义数量,而是依据语义进行划分。
就像下面的例子,一开始使用文言文只有 21 个字符,但是 Token 数也是 20,切换到白话文,字符数来到 31 个,Token 数依然是 21。
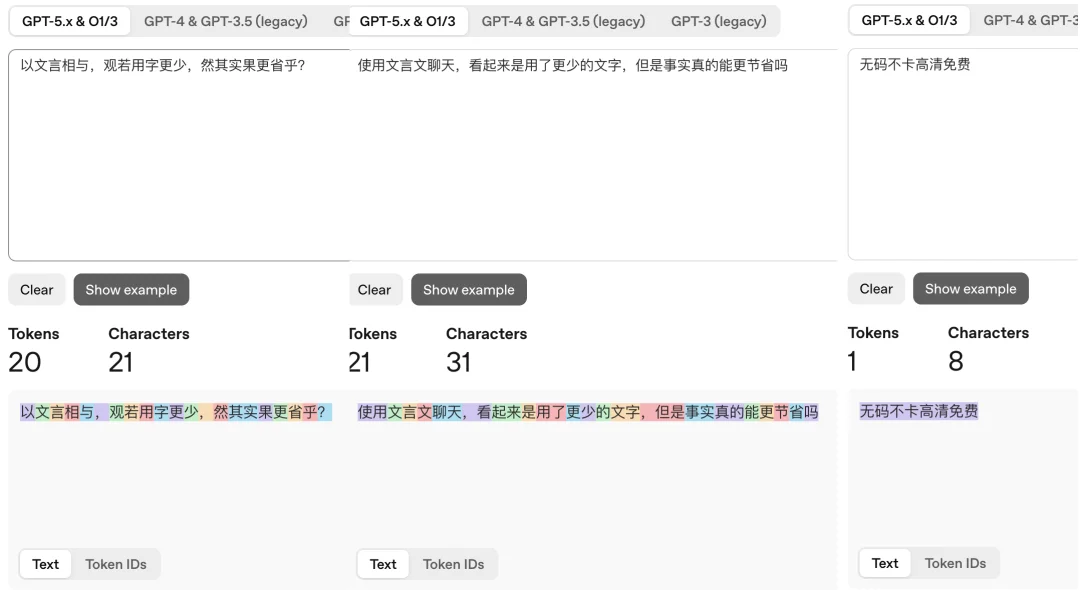
Token 计算:https://platform.openai.com/tokenizer
更离谱的是,我们之前分享过的 GPT-4o 词元污染,
输入一串 8 个字符的短语,在 AI 大模型眼里只占用了 1 个 Token。
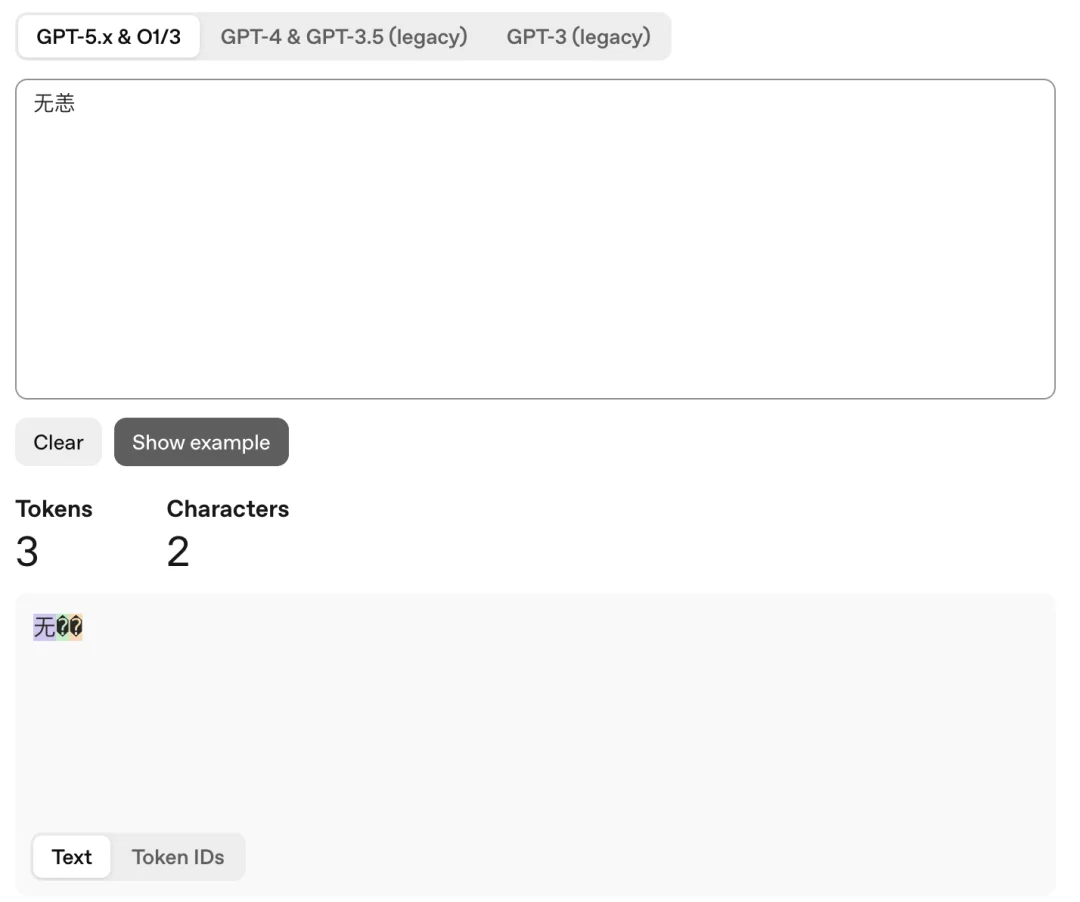
而对于一些非常用字,例如「无恙」,ChatGPT 会将其编码成 3 个 token,因为「恙」会变成乱码。
文言文不行,又有开发者提出回到石器时代,用穴居人的方式和 AI「对话」。
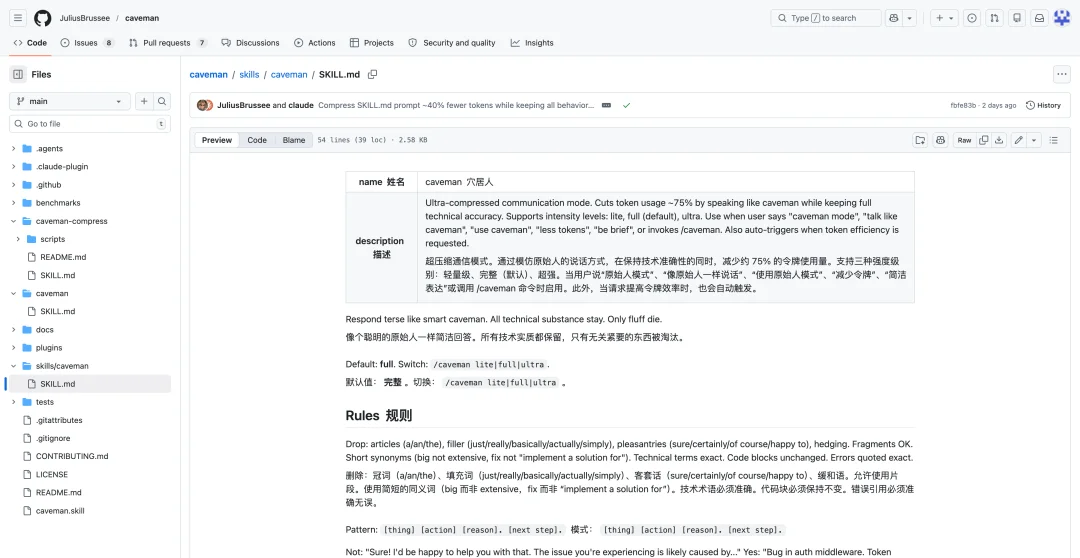
一个名叫 caveman 的项目这几天在 GitHub 上走红,和用文言文玩梗不同,这个项目实打实地做了一些测试,并给出了可以复现的 benchmark。
在展示的多项基准任务里面,使用 Cavemen 项目之后,能节省约 65% 的 Token,同时能保证输出内容的 100% 准确。
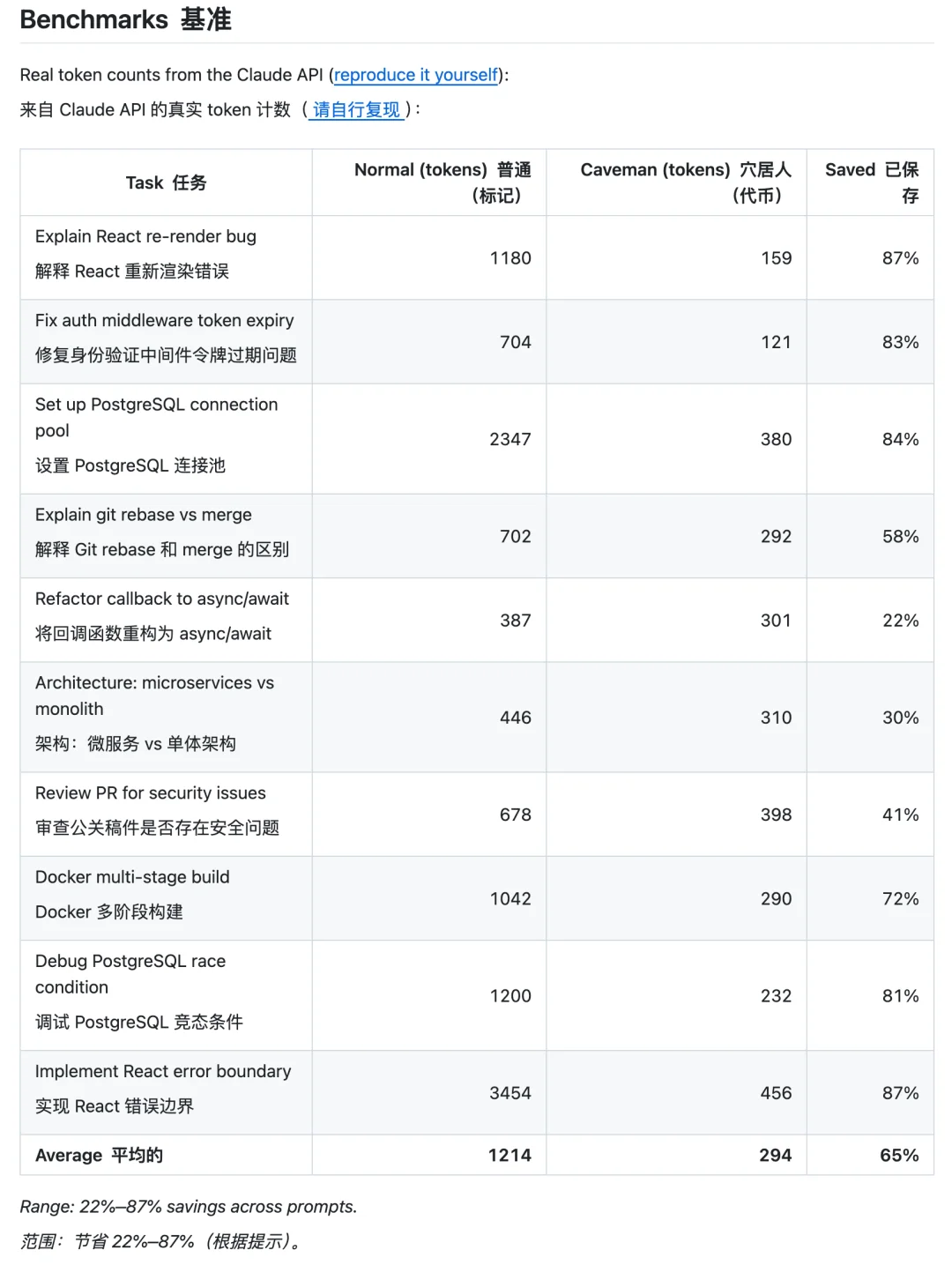
测试结果显示,在标准软件工程任务上,平均压缩率达到 65%,而且推理令牌不受影响,只有输出有效载荷被压缩。项目链接:https://github.com/JuliusBrussee/caveman
具体的做法是通过一个 Skill 来实现,它会在发送给大模型的请求中,强制加入特定的角色设定和指令,从源头上阻止模型讲废话。
它会要求模型停止使用客套话(如「Sure I'd be happy to」)、去除冠词(a, an, the)以及避免使用模棱两可的词汇(如「It might be worth considering」)。
同时,它也要求模型必须保留代码块、错误信息和专业技术术语的原样。
而关于深度思考方面,Caveman 只会影响输出 Token, 模型寻找 Bug、梳理逻辑的内部推理过程依然是完整且庞大的。 当模型结束思考,准备「开口」给我们解释时,它受到了 caveman 指令的约束,只用最少的输出 Token 把结论输出。
除了让模型「说山顶洞人的话」来节省输出 Token,这个项目还提供了一个 caveman-compress 脚本来让模型「少阅读」。
它可以将我们的项目记忆文件(如 CLAUDE.md)预先重写并压缩成「山顶洞人语版本」。这样一来,每次我们开启新会话时,大模型需要读取的输入 Token (Input Tokens) ,经过测试减少了约 45%,实现了输入和输出的双重节省。
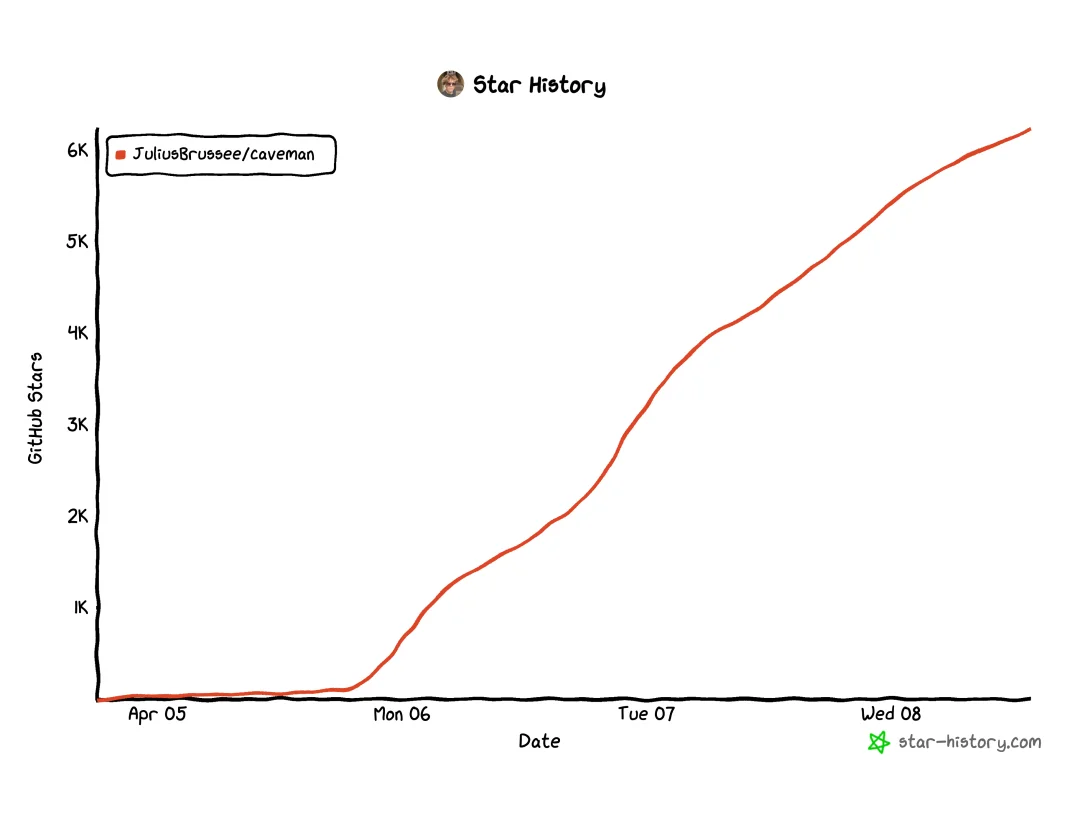
目前这个项目在 GitHub 上已经拿下了快有 6000 个 Stars。然后很快又有网友给出了「山顶洞人-压缩版」,通过进一步压缩 Caveman 项目的输入来减少 Token。
Caveman 的开发者在项目说明文档里面提到,使用山顶洞人的模式是有科学依据的,他提到了今年 3 月的一篇名为《Brevity Constraints Reverse Performance Hierarchies in Language Models》(简短约束逆转了语言模型的性能层级)的论文。
研究发现,大模型的客套话和长篇大论有时是一种 debuff。
强制大型模型给出简短的回复,不仅没有让它变笨,反而使其在某些基准测试上的准确率提高了 26 个百分点。
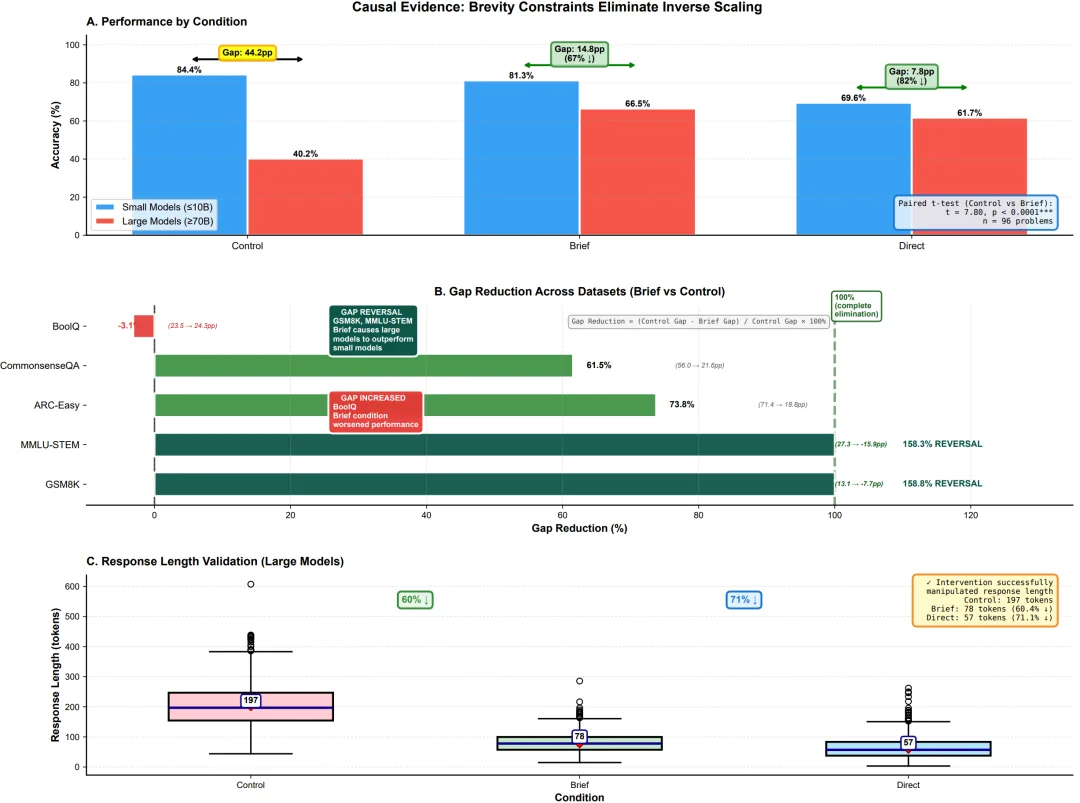
简洁性的约束消除了反向规模效应。(A)三个条件下的表现显示,在简洁性约束下,大模型显著提升(控制组:40.2% → 简洁组:66.5%,+26.3 个百分点)。(B)差距缩小在不同数据集上有所变化,在 GSM8K 和 MMLU-STEM 中甚至出现完全反转,在简洁条件下大模型表现更优。(C)响应长度验证确认该干预成功操控了冗长度(控制组:197 个 token → 简洁组:78 个 token,减少 60%),从而建立了过度思考与性能下降之间的因果联系。论文链接:https://arxiv.org/abs/2604.00025
去年,视频会议公司 Zoom 也发布了一篇论文,《Chain of Draft: Thinking Faster by Writing Less》(草稿链:通过少写来更快思考),提出了一种全新的大语言模型推理策略,解决了现有方法中太啰嗦且成本高的问题。
传统的思维链(Chain-of-Thought, CoT)虽然能帮助大模型通过分步推理来解决复杂任务,但这种方法要求模型在给出最终答案前生成大量详细的中间步骤。这导致了极高的计算资源消耗、更长的输出长度以及更高的延迟。
我们人类在解决复杂问题,如数学题或写代码时,通常不会把所有思考细节都长篇大论地写下来。我们习惯于只记录简短的「草稿」或核心信息来推进思考。
论文也是受此启发,希望让大模型也模仿这种高效、极简的策略。作者提出了 CoD(草稿思维链)。
在提示词设计上,CoD 同样要求模型一步一步地思考,但做了一个关键限制:每个推理步骤只保留最精简的草稿,最多不超过 5 个词。
例如,在解决简单的数学应用题时,CoT 可能会输出几段完整的句子来描述题意,而 CoD 只需要模型输出类似 x=20-12=8 这样最核心的公式即可。
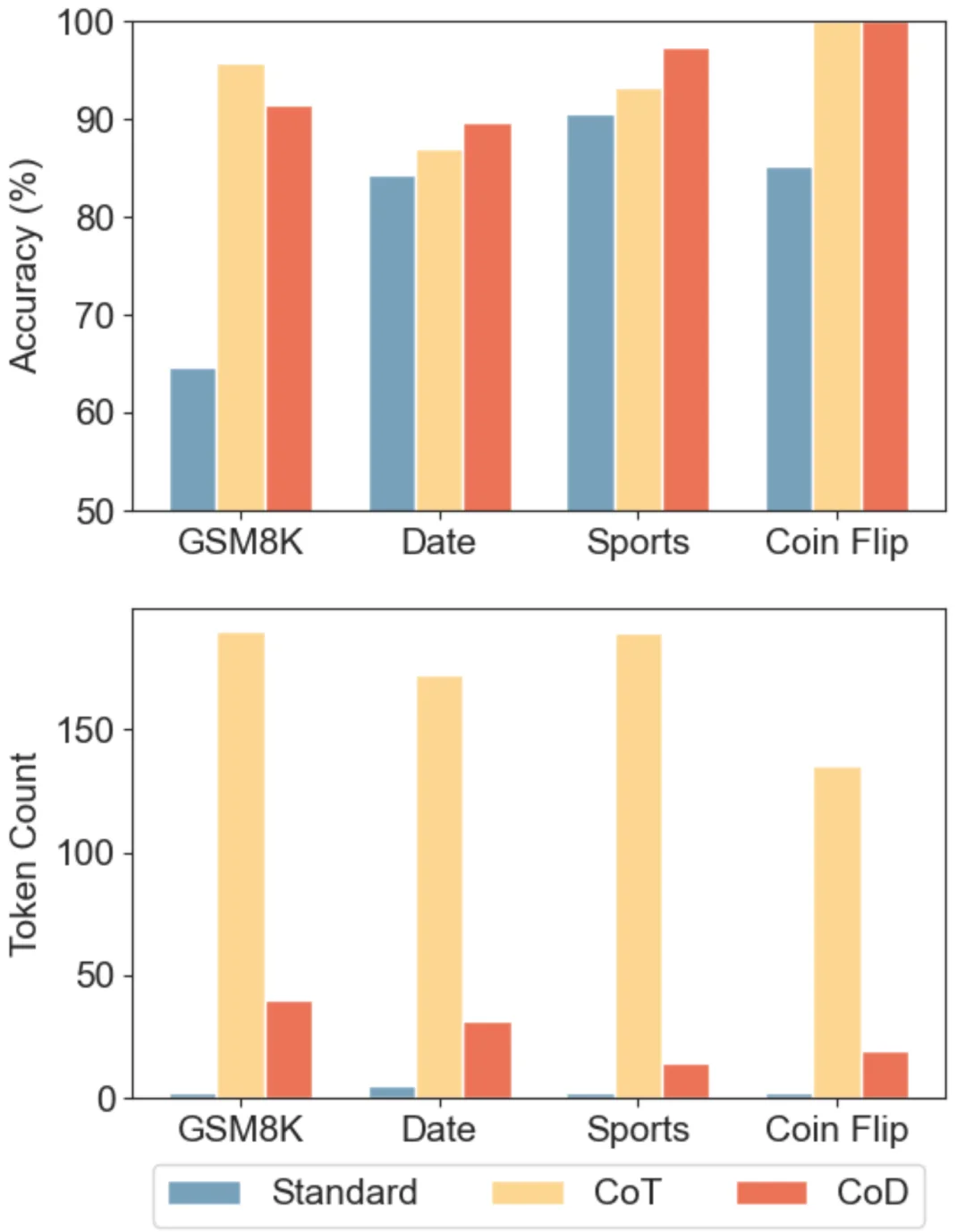
比较 Claude 3.5 Sonnet 在三种不同提示策略下(直接回答(Standard)、思维链(CoT)和草稿链(CoD))在不同任务中的准确性和令牌使用情况。CoD 在实现与 CoT 相似准确性的同时,使用的令牌数量显著更少。论文链接:https://arxiv.org/abs/2502.18600
结果,CoD 在保持甚至超越 CoT 准确率的同时,消耗的 Token 数量大幅减少,最低仅为 CoT 的 7.6%。
两个研究,都是通过 Skill 或提示词的方式,来强制限制模型的输出长度。CoD 的提示词同样直接,要求模型,「一步一步思考,但每个思考步骤只保留最少的草稿,最多 5 个词」。
除了使用 Caveman 的 Skill,有网友还总结了更完整的节省 Token 十大诀窍。
1、在已发送的消息上修改,而不是另发一条消息
当 AI 回答不符合我们的预期时,尽量不要发一条「不对,我是指……」来跟进。
因为每发一条新消息,大模型都要把前面的所有聊天记录重新读一遍,导致 Token 消耗成倍翻滚。正确的做法是:直接点击原消息的「编辑」按钮,修改提示词,然后重新生成。
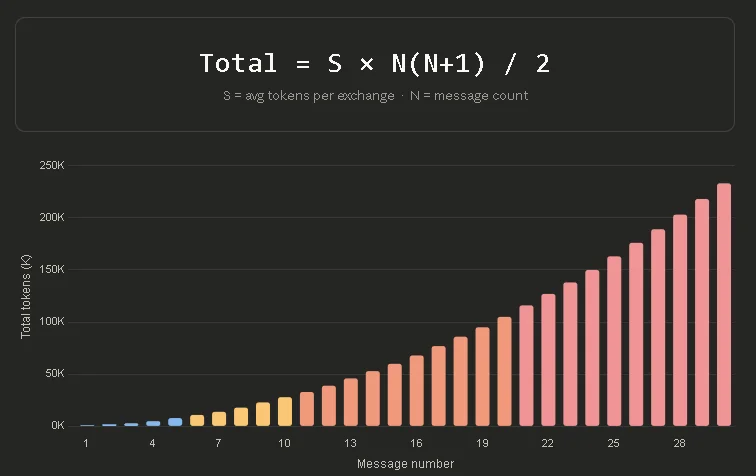
消息越多,消耗的 token 也越多。原文来源:https://x.com/0x\_kaize/status/2038286026284667239
2、每 15–20 条消息就开启一个新对话
长对话是 Token 的无底洞,在一百多条消息的对话中,可能有 98.5% 的 Token 都浪费在让 AI 重读历史记录上。
当对话变长时,我们可以让 AI 先总结一下当前进度,然后拿着这段总结去开一个新的对话。
3、将所有问题都集中到一个消息里面发送
不要把「总结这篇文章」、「列出这篇文章的要点」、「给这篇文章想个标题」分成三条消息发送。
把它们合并成一段完整的提示词,不仅能减少系统加载上下文的次数,还能让 AI 因为看到了全貌而给出更高质量的回答。
4、把反复使用的文件上传到 Projects 中
如果我们在多个聊天窗口里反复上传同一份长文档,每次上传都会重新消耗大量的 Token。
这个时候我们可以利用 Projects 的缓存功能,文件只需上传一次,后续在这个项目里怎么问关于这份文件的内容,都不会再重复烧 Token 了。
5、提前设置好「记忆」与用户偏好
大多数时候,我们会按照以前的提示词技巧,在发每次开新对话时,都会「浪费额度」去写「现在你是一个文案策划,用轻松的语气写……」。
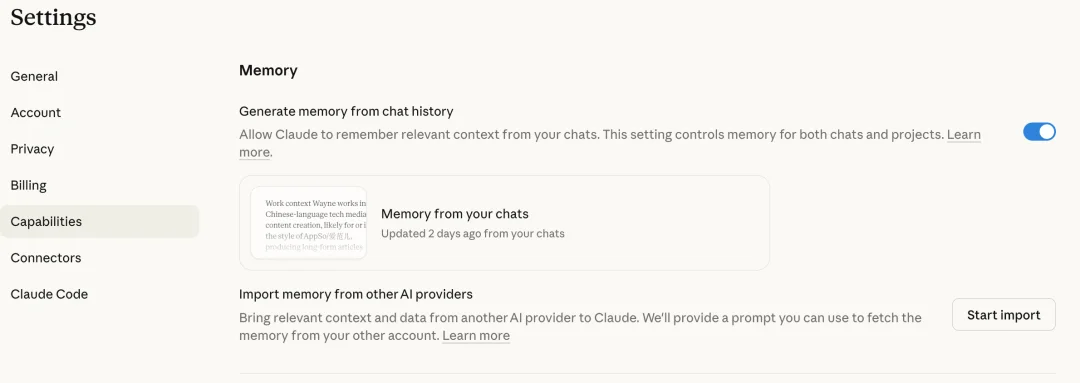
现在 AI 都有用户偏好和记忆功能,我们可以把职业、行文风格、项目信息等偏好保存在设置里,它就会自动生效,帮我们省下大量重复交代背景的 Token。
6、关掉不需要的附加功能
联网搜索(Web search)和高级思考(Advanced Thinking)等功能只要开着,每一轮都会额外消耗 Token。
除非我们对初步的回答不满意,或者明确需要这些功能,平时在简单地聊天时,可以关闭这些附加功能。
7、用不同的模型解决不同的问题
一些简单的任务,像检查语法、简单排版、快速翻译这些基础活,完全可以使用成本最低的 Haiku 模型。把节省下来 50%–70% 的额度,留给那些真正需要深度思考的复杂任务,交给 Sonnet 或 Opus。
8、把工作分散到全天的不同时段
Claude 的使用限制是基于「滚动 5 小时」窗口来计算的,而不是半夜统一清零。
如果我们早上把额度耗光了,下午就会很难受。建议把工作分成早、中、晚几个时段,这样额度会不断自动恢复。
9、尽量避开高峰时段
从 2026 年 3 月 26 日开始,如果在工作日的高峰期(太平洋时间早上 5 点到 11 点)使用,同样的请求会更快地消耗限额。如果把重度耗费算力的任务挪到非高峰期(比如晚上或周末),额度会经用得多。
这是基于 Claude 之前推出的错峰双倍福利,一方面是 Anthropic 的尖峰服务器压力大,给一些福利希望用户在平谷时候使用 Claude,另一方面也确实给北京时间的用户实实在在的优惠。
目前在 Cursor 等应用内使用大模型,有时候还是会碰到请求过多的提示,尤其是在晚上的时间。
10、开启超额使用 (Extra Usage)作为安全网
如果是 Claude 付费用户,可以在设置里开启超额功能并设定预算上限。
这个方法虽然不省 Token,但可以保证当我们的额度耗尽时,系统会自动切换到按量计费,防止在十万火急的工作关头突然被强制阻断。
无论是靠 Skills 还是我们自己调整提示词,这些方案的底层逻辑都是要减少毫无意义的上下文重读。从千禧年按字算钱的短信,到如今按 Token 计费的大模型,人类追求沟通效率的本质其实从未改变。
在使用 AI 的过程中,逐渐养成这些习惯,用「山顶洞人」的语言,只说重点,把 Token 用在刀刃上,或许是这个 Token 堪比真金白银的时代,最顶级的提示词技巧。
Less is More.
文章来自于"APPSO",作者 "APPSO"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
