# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
不er,这个世界还有什么是真的?反正我是已经分不清了...
短短3秒,连续切了3个镜头,从人物脸上的皮肤纹理,到满天纷飞的大雪,细节真实到有点离谱!

再看看这个,湿漉逼真的头发、肉眼可见的面部雀斑、超自然的景深,有点好莱坞大片内味儿了嗷:

还没完,咱再来看这个,机械义体与人脸的融合,以及构图处理都非常到位,妥妥滴赛博大片即视感!

你就说逼真不逼真吧…
不卖关子,就是Runway刚刚发布的——全新「Gen 4.5」模型。
这次更新主打的是图生视频,在镜头控制和故事叙事上,明显往next level推了一步~
这波效果一出来,网友当场坐不住了,直呼:感觉都能吊打好莱坞制作团队了好吧?太逼真!(doge)
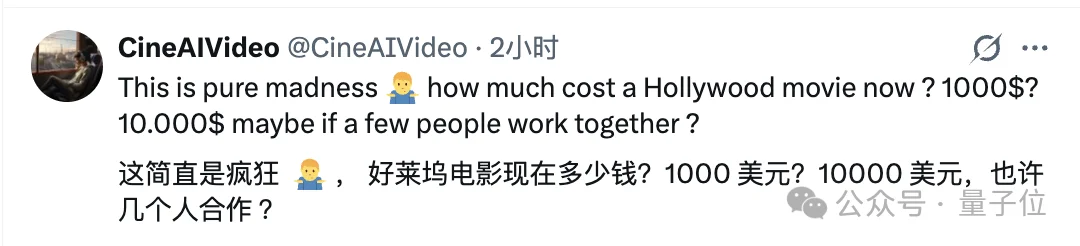
甚至逼真到,在Runway做的一项1000人参与的调查中,结果只有约一半的人能分辨出该模型和真实视频的区别……

问题来了,那这超超超逼真的——Gen 4.5模型效果到底咋样?咱一起来看!
咱先来说说,这次全新的Gen 4.5在模型能力上的有啥亮点看头~
咱直接边看效果边细细道来~
从官方给出的效果看,在镜头控制上,Gen 4.5能在5秒的时间内快速生成包含「近景」「中景」「远景」的三个镜头。
即便镜头不断晃动,人物面部依旧保持了较高的一致性。
哪怕骑在快速飞行的章鱼身上,小女孩依旧「面不改色」,面部细节完全没崩~

还有下面这个让巨型毛绒大猩猩走在纽约街头徘徊的视频,不论是镜头比例、透视逻辑,还是主体与城市背景的光影一致性,都处理得相当稳:

我们再来看看模型「讲故事」的能力。
下面这个Runway CEO用Gen 4.5生成的两分多钟剧情视频,在叙事完整性和场景一致性上,已经接近一条可用的短片水准:

即便在同一个车厢环境中,多次切换主体的镜头位置和动作,画面之间的空间关系和镜头衔接依旧保持连贯,没有出现明显的跳轴或场景漂移问题。
再来看看下面这位网友制作的超有「镜头漂移感」的视频,镜头一拖一拽,给到每个人的特写,再恢复远景镜头,感觉就差一段超热血的bgm了!!!

怎么说呢,如果你跟我说这不是AI做的,我真会以为是哪个影视公司的新片片段。(真·脑子宕机了)
甚至,真实到什么程度呢?
连Runway自家公司里的《员工》,都已经分不清哪条是他们模型生成的,哪条是真拍的了……

于是乎,灵机一动的Runway索性直接找了1000个人来测一把,看看Gen 4.5到底能把人「骗」到什么程度,其规则是:
Runway把自家AI生成的视频和真实视频放在同样的分辨率和时长条件下,让参与者在10秒内判断,哪些是真人拍的,哪些是AI做的。
结果您猜怎么着?
这一千个人里头,只有57%的人能成功识别出哪条是AI生成的。(天塌啦!)
是的,在这场「安能辨我是AI」的大戏里,AI的生成水平,已经和人类的肉眼辨别能力打到了势均力敌的程度。
(好好好,这个世界到底还有什么是真的啊!!!)
没准哈,下一步可能真得靠AI去鉴别AI了……
Runway这波模型更新,确实有亿点点不一般,与此同时带给我们的还有一个感受是:诶?这模型能力感觉好熟悉…
其实细细盘算一下,从去年年底到现在,市面上的视频模型一波接一波地更新,虽然各家厂商走的路线不完全一样,但整体看下来也有一些明显的共同趋势。
我也帮大家浅浅概括了一下:
直接拿俩个大家感受比较深的模型能力趋势和大家聊聊。
首先,就是真实度和一致性的要求被整体抬高。
具体指的主要是纹理与细节保真、光影与氛围、整体画面质感等等,能体现物理世界的细节地方。
也就是说,现在的视频模型越来越注重AI是否能理解并遵守现实世界的物理规律,能否在「跨帧」这事儿上表现得更自然。
像Veo 3.1上一波的升级,就在视觉保真度和电影级打磨上大幅提升,许多官方demo的细节处理上已经接近电影级:
咱们再来看看声画同步能力。
给我们最直接的感受就是:视频终于不只是画面更真了,声音也终于安排到位了,哪怕是侧脸、极端角度,或者多人对话场景,声画方面也不太容易崩。
各厂商们都确实都在想着怎么让AI视频开始真正具备做带台词的短剧 、广告 、社交内容的可用性。
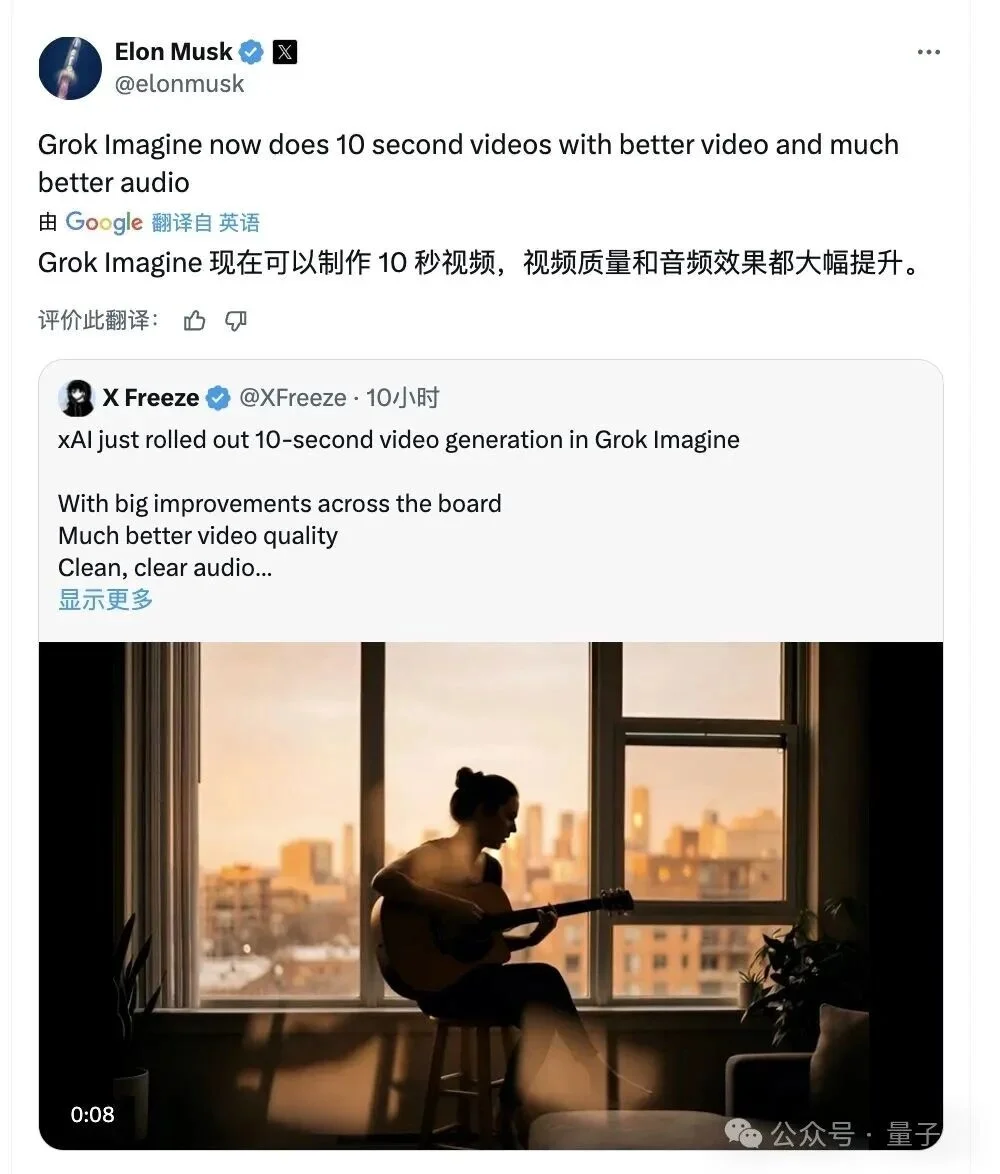
就在昨天,马斯克也官宣了Grok Imagine的最新成果,原生声画同步能力同样迎来了一波明显升级~
(这波热闹凑的好啊,好热闹啊)
总的来说,现在的主流视频模型,已经明显越来越接近可商业化应用、具备普适性的能力了。
当然了,各大厂商的发布节奏越来越「密」,说不定到了明天,又一个「新趋势」就会被端上台面。
但不管怎么说,Runway这波Gen 4.5的更新,确实有点出乎意料,也是真·一代更比一代强了。
感兴趣的朋友,可以直接上手搓搓试试~
参考链接:
[1]https://x.com/elonmusk/status/2014112911783084046?s=20
[2]https://x.com/runwayml/status/2014090404769976744
[3]https://www.youtube.com/watch?v=cOcsxd5mC8k
文章来自于“量子位”,作者 “梦瑶”。


