# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着AI浪潮的袭来,笔者本人以及团队都及时的调整了业务方向,转型为一名AI开发者和AI产品开发团队,常常需要微调大模型注入业务场景依赖的私域知识,然后再把大模型部署上线进行推理,以支撑业务智能体或智能问答产品的逻辑流程。
相信有相同转型经历的朋友们都会感同身受,转型之路必然是伴随着阵痛的,好在对技术的热情以及对职业发展的理性分析促使我们克服各方面的困难,包括:大模型知识的学习和积累、AI产品的需求定义和开发交付,以及最困难的是GPU资源的协调与实验室建设。
为什么说获取GPU资源非常困难呢?首先,没有卡就没有实践,没有卡就开展不了研究,更不用说开展产品原型的设计工作了。然而事实上,由于GPU价格高昂,公司只会分配一个公共GPU服务器给多个团队轮流使用。这样的情况下存在2个关键问题:
1)GPU服务器要申请时段轮流使用,无法第一时间验证新的想法和代码实现,导致产品迭代效率低下;
2)GPU服务器的软件环境经常被改变了配置和版本,每次使用前还得浪费时间先恢复配置,实际用于生产的时间并不多,还容易引入环境变化导致的Bug等问题。
可见,就像以前传统应用开发需要CPU开发机一样,AI时代的AI开发者也需要自己的GPU开发机,这是可以持续稳定且高效产出工作成果的前提。那么,采购个人电脑的消费级GPU行不行呢?其实不大可行,因为消费级
GPU并不是为大模型而设计的,只有几十GB显存很难流畅的运行一个大模型及其开发框架。
经过笔者长时间的实践后证明公用的GPU服务器和个人的消费级GPU卡都难以满足笔者个人日常进行AI开发工作的算力需求,直到我发现了联想ThinkStationPGX—— 联想和NVIDIA联合推出的AIPC(桌面上的AI超级计算机)产品,它是一款开发者个人能独占的且能够稳定运行200B~400B 参数量大模型的AI开发机。

联想ThinkStationPGX的定位是GPU工作站,处于GPU服务器和GPU个人电脑之间,它面向AI开发者提供一个在本地进行大模型开发和测试的平台。可以号称是“全球迄今最小的AI超算”。
联想ThinkStationPGX产品的发布标志着AI算力正从大型机构向个人开发者或小型团队渗透。随着产品生态的逐渐成熟,相信越来越多的AI开发者都可以人手一台趁手的开发机,可以在本地直接开展AI模型开发、调试与部署工作。从此我不必再申请GPU服务器的时间,不必再争抢资源。如果想要更改环境的软件配置以满足各种需求,
它就在那里,我随时可以动手。
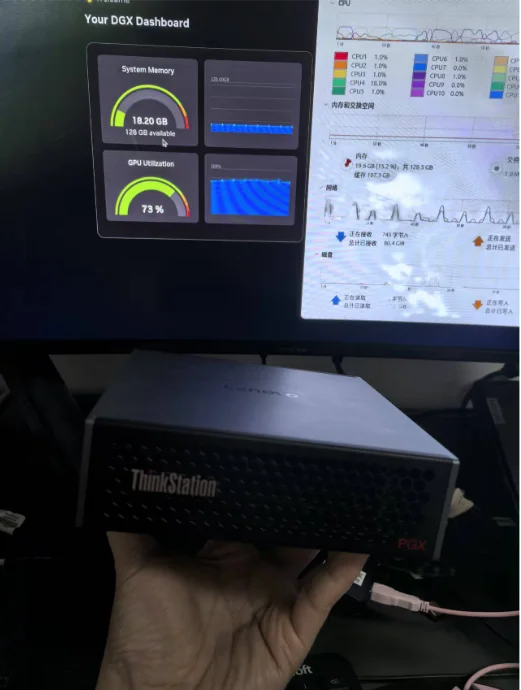
PGX除了让AI开发者可以“随心所欲” 之外,更重要的是让我们的研究和产出可以持续演进,比方说业务智能体团队要求我们通过微调的方式注入特定的私域知识数据集,此时我们立即就可以选择合适的模型分支在本地进行微调训练,然后部署推理验证效果。如果效果符合预期,我们就会部署上线。如果上线后出现了问题,我们也可以立即在本地进行问题的复现和排查。
当我们在AI开发机上开发的模型,无需修改代码即可无缝迁移至生产环境,这是一种符合CI/CD思想的产品迭代方式。换句话说,当大模型可以在个人开发机上完成微调、推理与迭代,那么开发机的角色也随之发生改变——它不再是终端,而是个人AI基础设施,作为桌面端与云端之间的桥梁,它与生产环境AI基础设施具有可移植性。
显然,PGX的核心价值在于提供了本地化的大模型运行环境,便于进行模型原型设计、微调与测试。对于单兵或小团队作战的开发者是革命性的生产力提升。
在售后服务上,联想作为国内TOP1的专业工作站品牌则有很大的优势。不仅为用户提供了ThinkStationPGX专享售后服务,可以支持长达三年的上门服务、保修和技术支持,这对于注重服务喜欢省事省力的用户非常有吸引力。此外还可以提供三年一次的硬盘恢复、专享NV技术咨询等PRC增值服务。
虽然说AI开发机较GPU服务器的价格已经非常亲民,但仍属于高价值消费品,所以还是建议要找一个国内售后服务实力较好的品牌。对此,联想在全国拥有超过1万名认证工程师,2300多个专业服务站,100%覆盖1~6线城市,保证7x24小时在线支持,是非常值得信赖的。
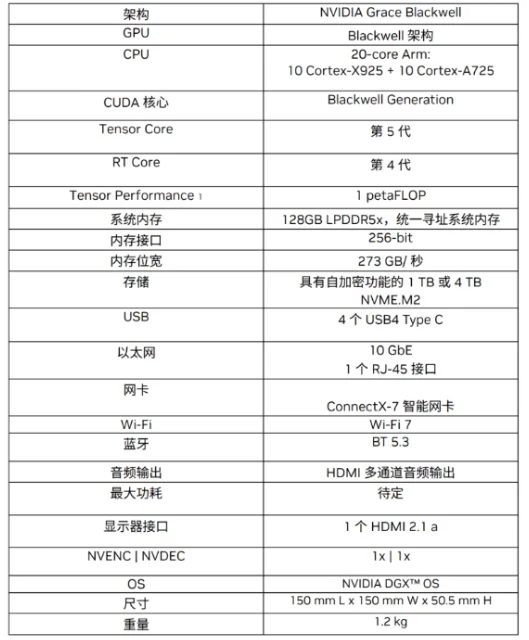
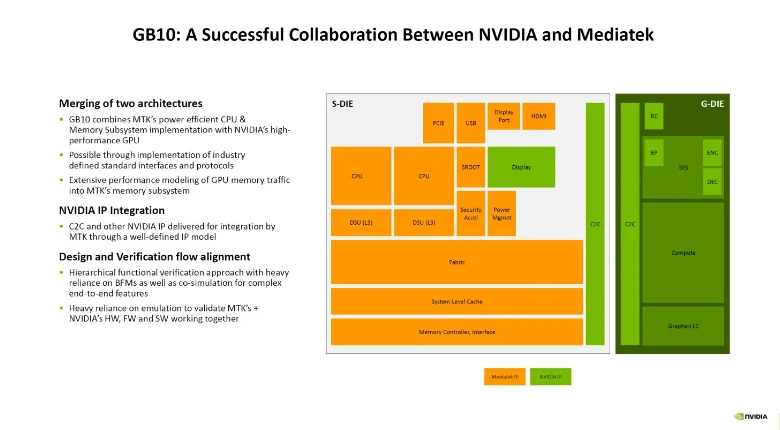
在硬件层面,PGX是一款基于Grace-Blackwell芯片架构的桌面级AI超级计算机,其核心是一颗NVIDIAGB10 GraceBlackwellSoC芯片,将GraceCPU和BlackwellGPU融合于一体。如下图所示,除了GB10之外,还配备了128GB统一内存、ConnectX-7网卡、4TBSSD存储等服务器级硬件模块。

下图是一张硬件参数概览表,接下来我们将逐一的分析每个硬件参数,以此来理解“ThinkStationPGX专为AI开发者设计的桌面级AI超级计算机” 的设计理念。
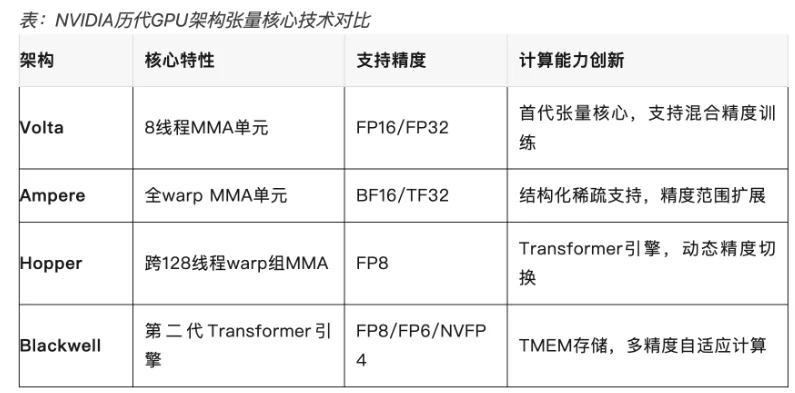
GB10 SoC芯片上的GPU模组采用的是Blackwell架构。如下图,从芯片原件排布就能看出左边是GPU,采用台积电的3nm工艺技术集成了48个SM、约6144个CUDAcore,以及5代的Tensorcore(张量核心)和4代的RTcore(光追核心)。
GB10的显著特点是支持FP4/FP6/FP8低精度计算,这是专为AI开发机应用场景而设计的。特别是FP4精度,基于成熟的NVFP4 大模型量化技术,采用FP4精度再结合稀疏性技术可以在一台ThinkStationPGX上提供惊人的1PFLOP/s(1 千万亿次每秒)AI算力峰值。
这意味着采用FP4精度来处理大模型推理时,ThinkStationPGX可以显著提高了整体吞吐量,效率较FP8 和FP16成几倍的提升。显然这是为了让AI开发机能够尽可能的更快微调训练和更大吞吐推理而设计的。

GB10的CPU模块采用了精简指令集的ARM10+10架构。
其中,ARMv9.2架构在保证高性能的同时,兼具低功耗和小型化优势。这使得ThinkStationPGX能够使用标准的家用插座供电,无需额外的专用充电设备,使其能够放置于桌面上使用。
另外,10+10共计20个core,包括10个Cortex-X925 core(高性能核)负责高负载的通用计算任务;10个Cortex-A725 core(高能效核)负责处理后台进程和I/O 调度。10+10组合是一种专门为了优化大模型训练数据加载、数据预处理和流程编排的设计,能够加速从数据清洗到模型调整的全流程。

ThinkStationPGX另一个专为AI开发机而设计的就是128GB的统一系统内存(UMA)技术,使得CPU和GPU能够在保证访存寻址一致性的前提下共享128GBLPDDR5X内存,而不再是分开为各自独立的主存和显存。
128GBUMA从根本上解决了消费级GPU只有24GB/48GB显存容量受限的关键痛点。这意味着训练和推理数据无需在CPU主存和GPU显存之间拷贝,降低了延迟。处理大模型时,也避免了传统GPU因为显存不足反复交换主存的开销,提高了效率。
另外,结合FP4精度可以将一个更大的模型塞入到一台ThinkStationPGX中。例如,在扣除CPU的操作系统占用空间后,128GB中的100GB能够提供给GPU使用。在使用FP4精度量化模型后,原本需要200GB显存的200B大模型,现在只需100GB左右即可部署,使得在桌面端部署和运行超大规模模型成为了可能。
容量之外的带宽层面,128GBUMA和CPU/GPU之间的访存总线宽256bit,带宽约273GB/s。并且,如下图所示,GB10的CPU和GPU模块之间采用了最先进的NVLink-C2C互联技术,CPU和GPU之间的数据传输不再需要经过PCIe,而是Chip-2-Chip直连,总线带宽最高可达141GB,是PCIe 5.0的5倍。NVLink-C2C技术突破了传统PCIe的瓶颈,带来更快的协同运算性能。这也是GBXX架构被称为SuperChip的原因。
综上,GB10 SuperChip、128GBUMA、FP4精度这3者之间的组合,使得专为NVIDIANVFP4优化过的vLLM等AI框架会根据实际负载动态地分配UMA内存资源,读写模型参数、KVCache等数据,而且过程中的中间激活值也不再需要在CPU主存与GPU显存之间反复搬运,不仅降低了内存拷贝带来的时延,也显著简化了大模型部署与调优的复杂度。这意味着可以在单机环境中承载更大的模型规模—— 最终实现了一台ThinkStationPGX最大可以承载200B规模的大模型进行推理,或对70B规模的大模型进行微调。
通常情况下,要实现这一目标,我们往往需要在GPU服务器上轮流协调2~4张卡来实现。而有了ThinkStation PGX后我们就可以随时随地的开展工作了。
值得一提的是,128GBUMA对MoE(混合专家)模型的适用性很强,例如:Qwen3-235B-A22B等MoE模型,虽然其总参数庞大,但实际上单次激活参数较少。这一特性与PGX的大内存优势高度匹配。无需复杂的显存优化操作,即可实现此类模型的稳定运行,拓展了硬件的应用场景。
另外,实际上273GB/s内存带宽是偏低的,这是进行大规模推理时的主要性能瓶颈。但PGX的128GB大内存确实为部署超大MoE模型提供了很好的支撑。可见PGX的价值在于容量而非速度,其性能虽然受限于内存带宽,但综合效果也远超消费级GPU个人电脑方案。
ThinkStationPGX在一台小小的设备上也实现了GPU服务器级别的高性能存算分离网络连接。包括:
通过CX7组成双机集群后,可以实现256GB的UMA扩容,这种扩展能力为超大规模模型的本地部署提供了显存容量的基础,可以部署如LLama3.1 405B和Qwen3 235B此等量级的大模型推理而无需担心内存溢出。
更进一步的,通过MicroickCRS812DDQ交换机,可以将进一步扩展PGX集群至6个或更多的系统。

前文中我们着重介绍了ThinkStationPGX在“GPU服务器化” 方面的能力,接下来我们转而介绍ThinkStation PGX在“PC 化”方面的设计。
首先是尺寸,ThinkStationPGX是一个只有巴掌大小的金属壳盒子,体积为150×150×50.5mm,重量仅1.2kg。整机采用紧凑式设计,金属外壳兼具质感与耐用性,放置于办公室桌面上的体积非常小。充分体现了NVIDIA旗舰级硬件的工业设计水准,第一次拿到手的时候不禁为其精湛的工艺感到不可思议。
其次是功耗,ThinkStationPGX满载功耗理论上只有240W 左右,其中GB10 SoC芯片本身TDP约140W,其余的100W 留给网卡、SSD等组件。所以标配了240W 外置电源适配器供电,适用于任何办公桌上的电源插槽,无需额外的供电设备。
然后是散热,ThinkStationPGX的散热系统非常讲究,采用了静音散热设计,运行过程中风扇噪音控制很好,空闲时约13dB,满载时约35dB。非常安静,适用于办公环境。
再来是各类外设的输入输出接口,ThinkStationPGX配备了4 个USBType-C,其中一个用于供电输入。还配备了1 个HDMI 2.1a 显示器接口,支持多声道音频输出和最高8K 的显示输出。无线方面,ThinkStationPGX集成Wi- Fi 7 和BT 5.3 蓝牙模块,方便无线联网和外设连接,很好的覆盖了无线办公的使用场景,而无需配备特殊的外设接口转换器。

可见,以上都是完全标准的“PC化” 设计,使我能够经常背着ThinkStationPGX上下班。在实际使用中,我只需要插上电源和视频转接器就可以继续我在办公室或家里的工作进展。
最后不得不提的是ThinkStationPGX采用了1TB或4TBNVMeM.2 SSD存储,一方面避免了模型训练中的I/O瓶颈,另一方面还支持自加密(Self-Encrypting)功能,为大模型权重数据和代码资产的安全提供了全面的保护。这也使得我相对放心的带着ThinkStationPGX出去参加交流和学习等活动。
前文中我们从硬件参数设计的层面逐一分析了为什么将PGX称之为“专为AI开发者设计的桌面级AI超级计算机”,接下来我想从软件堆栈设计的层面来说明为什么PGX不仅仅是AI开发机,而是一个个人级的AI基础设施。
AI开发机和个人级AI基础设施的核心区别在于其是否真正融入到了生产环境的CI/CD工作流程中,这取决于个人环境和生产环境是否具有一致性的软件堆栈,使得代码和模型参数是否可以无缝的在个人环境和生产环境流转起来。
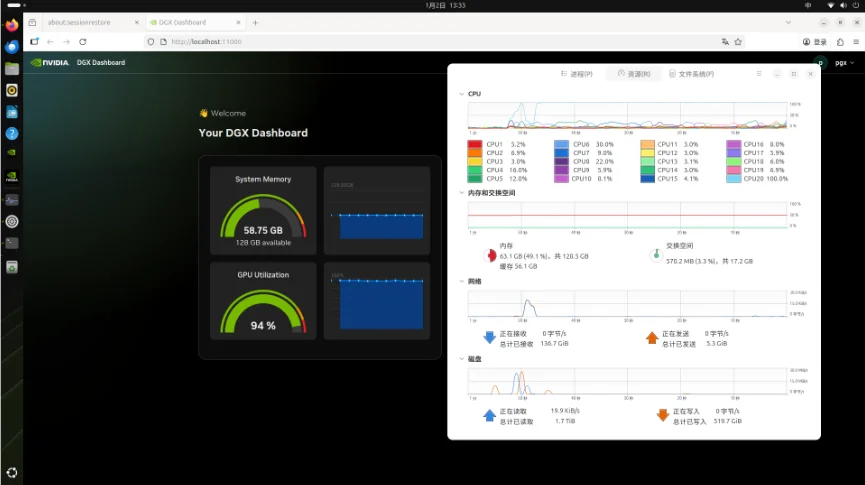
ThinkStationPGX在软件方面尽量做到了开箱即用,初次配置只需联网更新并简单设置用户信息,即可得到一个完整的NVIDIAAI开发环境。后续使用中,通过NVIDIA提供的Dashboard工具等,即可以方便地维护系统状态并获取最新优化。
PGX已经预先安装了和GPU服务器一致的NVIDIAAI软件栈,包括经过优化的GPU驱动、CUDA库以及NVIDIA提供的各种AI工具和框架支持等等。如下图所示,开发者可直接访问NVIDIANIM、NVIDIABlueprint和AI Workbench平台,可以拉取NVIDIA提供的容器镜像,其中包含经过测试的PyTorch / TensorFlow + CUDA运行环境,在PGX上直接运行。
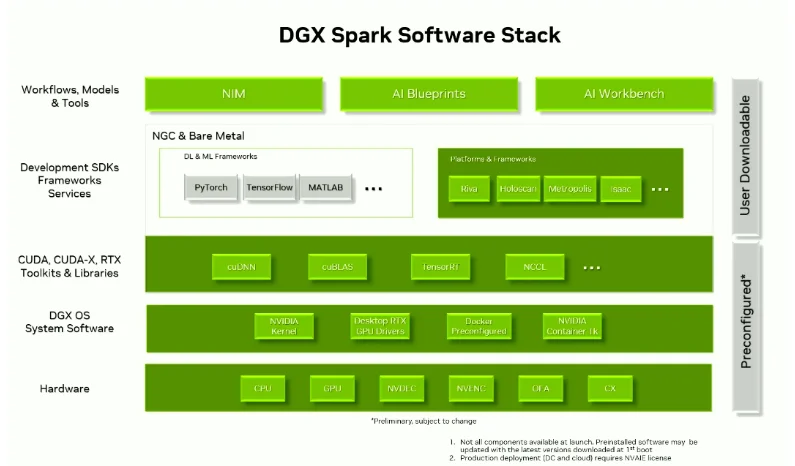
并且也可以在PGX上立即使用PyTorch、TensorFlow、TensorRT-LLM等主流框架和JupyterNotebook、Ollama等主流开发工具。开发者在PGX上开发调试的代码和容器,可无缝移植到企业级GPU服务器或NGC(NVIDIAGPUCloud)云服务上运行。
PGX实际上就是生产环境CI/CD流程中的一个开发环境,在本地重现了生产级GPU服务器的架构和软硬件环境,让开发者“所见即所得” 地进行开发和调试。在日常工作中,我们会先用单机PGX验证,然后小规模集群进一步测试,最后再上线到生产环境GPU服务器集群中。
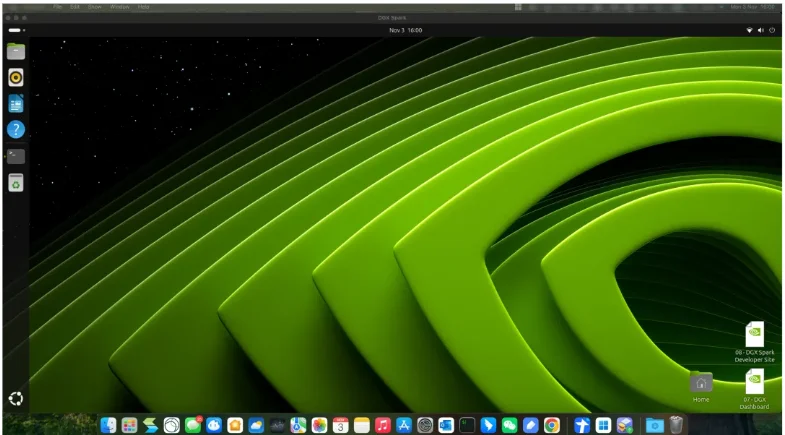
首先是操作系统。区别于纯粹指令行的GPU服务器,PGX OS是基于Ubuntu 24.04LTS定制发行的桌面操作系统。
因为对于模型可视化、模型性能优化、图形图像开发等工作的开发者而言,经常需要使用到NsightSystems等GUI工具对GPU程序进行调试,只有指令行显然无法满足所有工作的实际需求。所以PGXOS桌面操作系统为了能够让开发者在一台电脑上完成所有工作而设计的。
此外,为了让习惯在macOS或Windows操作系统上工作的开发者也能获得较好的使用体验,PGX也预先安装并启用了xRDP图形远程桌面服务。可建立稳定顺畅的远程GUI连接,在自己习惯的笔记本上访问PGX的桌面环境。如下图所示。
启动操作系统之后,我们需要做一些基础的软件环境检查。
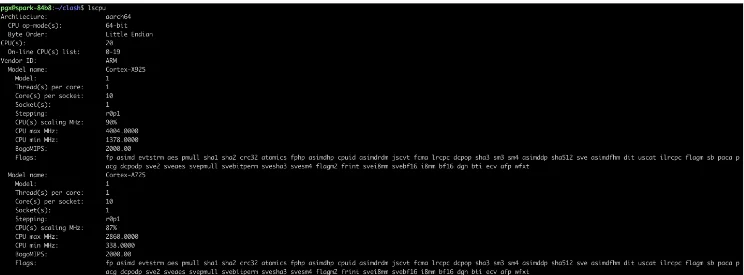
1. 查看GraceCPU 信息:
2. 查看128GBUMA内存容量:free和nvidia-smi看见的内存容量信息是一致的,因为是UMA架构。

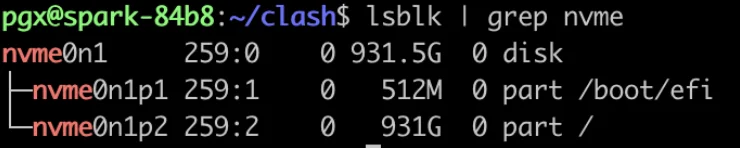
3. 查看SSD硬盘容量:
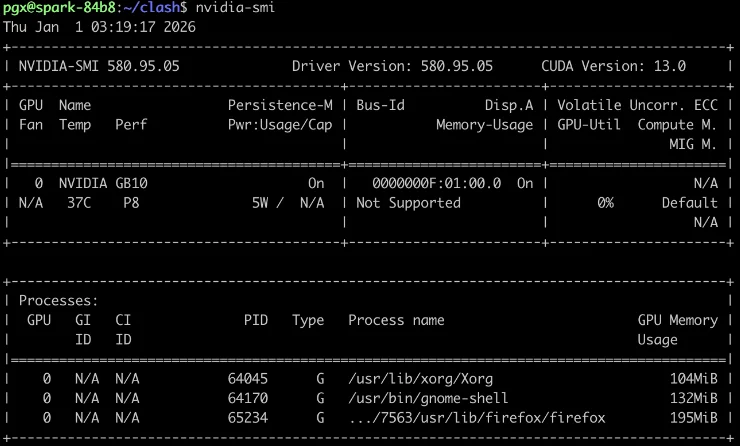
4. 查看GPU信息:nvidia-smi的MemoryUsage一栏会显示“NotSupported”,这是正常情况,因为UMA架构下GPU无独立显存,此信息不适用。
5. 查看预安装的Docker版本:

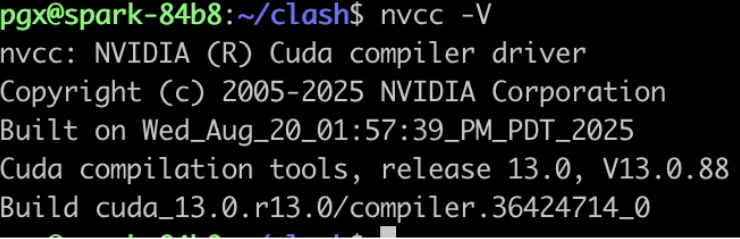
6. 查看预安装的CUDA工具链版本:
如果我们直接运行Docker容器,那么在容器内是看不见GPU设备的,所以需要安装NVIDIAContainerRuntime和Toolkit来支持dockerrun --gpus选项。NVIDIAContainerRuntime运行HostOS中,是一种用于在DockerContainers中无缝使用GPU的关键技术。
NVIDIAContainerToolkit则运行在Containers内部,提供了必要的组件,以便为容器化应用动态配置并接入GPU设备和CUDA库。具有以下优势:
1. 容器内无缝访问GPU设备;
2.自动管理GPU 驱动程序与CUDA 库;
3. 支持自动配置Multi-GPU;
4. 与Docker等主流的容器编排平台兼容。
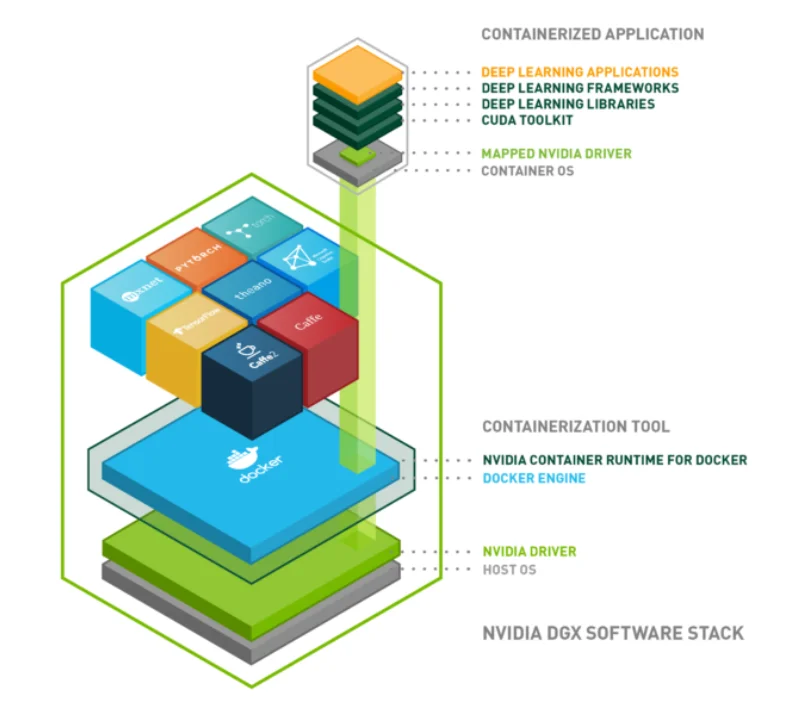
如下图所示,NVIDIAContainerRuntime与NVIDIAContainerToolkit相互结合使用,实现了在Dockerd与NVIDIADriver驱动程序之间建立协同交互,能够让Containers直接高效地调用GPU资源。
在PGX系统中已经预先完成了NVIDIAContainerRuntime & Toolkit的安装和配置,包括:与Docker集成、配置GPU设备访问、配置CUDA库等。所以PGX操作系统可以开箱即用,立即开始处理AI工作负载、CUDA应用程序以及其他GPU加速软件。
测验证证是否可以正常调用GPU设备和CUDA库。
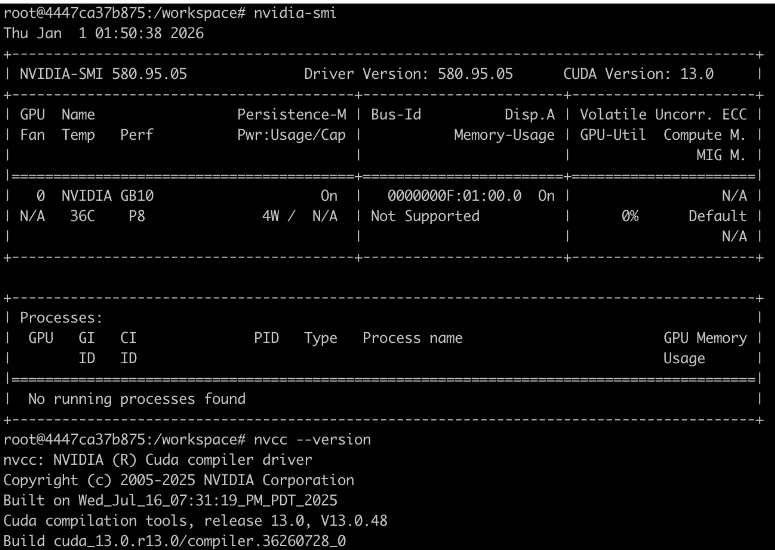
1. 启动容器,使用--gpusall参数让容器直接使用主机GPU。
2. 在容器内输入nvidia-smi、nvcc --version等命令,如果均能获取正常输出,即说明Docker容器内GPU和CUDA环境已就绪。

默认情况下,PGXOS执行docker指令需要sudo权限。为了方便可以将pgx用户添加到docker用户组,即可无需使用sudo直接运行了。

值得注意的是,PGXCPU是ARM64平台,所以我们自行安装软件和启动容器时,需要选择对应的arm64版本。
例如:
直接dockerpullpytorch/pytorch:latest默认拉的是x86_64镜像,在ARMCPU上运行会报非法指令。因此要使用NVIDIANGC提供的镜像或在DockerHub上标记支持arm64平台的镜像。
NVIDIA官方提供了可以直接应用到PGX上的容器镜像,涵盖CUDA13、PyTorch等。拉取nvcr.io/nvidia/cuda:13.0.1-devel-ubuntu24.04作为基础镜像,然后在其中安装AI框架就可以保证兼容。
链接如下:https://catalog.ngc.nvidia.com/
NVIDIADashboard是NVIDIA提供的软件管理工具,用于检查软件更新、安装补丁、升级GPU驱动、NIC固件等。NVIDIA会定期(每半年左右)发布OS的重要更新,以及不定期的安全补丁,为了获得更好的稳定性和性能,建议定期检查系统更新。通过NVIDIADashboard可以方便地查看并一键安装可用更新。
非常建议优先使用Dashboard执行系统更新,因为NVIDIA针对PGX的软件栈进行的特殊的更新验证和优化,使用Dashboard可避免不兼容更新导致的问题。
另外,NVIDIASync桌面程序能够实时显示PGX设备的资源利用率,并集成命令行终端,为用户提供统一界面来管理SSH访问以及在PGX上启动开发工具。
随着大模型参数量的增长,显存优化技术之一的低精度量化技术得到了飞速发展。从行业的整体趋势来看,大模型正朝着低位宽浮点数的方向演进(FP32=>FP16=>FP8=>FP4)。并且在业内经过长期的测试发现,不同低精度格式的效果排序为FP8 >FP4 >INT8 >INT4。由于FP4兼具了体积和精度的综合优势,现在已经成为了大模型量化技术的主流趋势。
PGX的BlackwellGPU支持NVIDIA专为推理优化的NVFP4(4-bit浮点)格式,结合FP4量化技术,能够实现接近FP8的精度(仅降低1%)。NVFP4量化技术可以将模型权重压缩至原始大小的约3到3.5倍(相比FP16),或1.8倍(相比FP8),同时将吞吐量提升。从而在不牺牲准确性的前提下,可以放下更大参数规模的模型。在NVFP4的加持下,一台PGX才得以实现最大承载200B规模的大模型进行推理。

并且由于FP4的数据占用空间更小,系统性能也得以提升。因此,应用了NVFP4量化技术后的PGX可在不牺牲模型精度的前提下实现:
1. 更高的推理吞吐
2. 更低的响应延迟
3. 更快的Token生成速度
4. 更顺畅的Prompt处理能力
而高效的Prompt处理能力有助于提升token响应速度,加快端到端的吞吐量,改善用户体验。下表展示了PGX在NVFP4 + TensorRT-LLM /llama.cpp环境下多款大模型的测试表现。
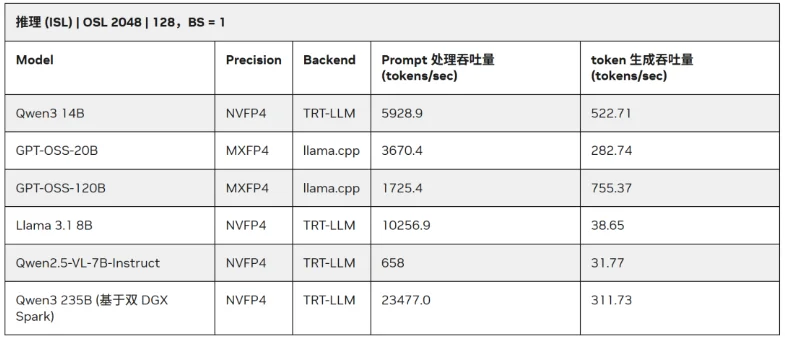
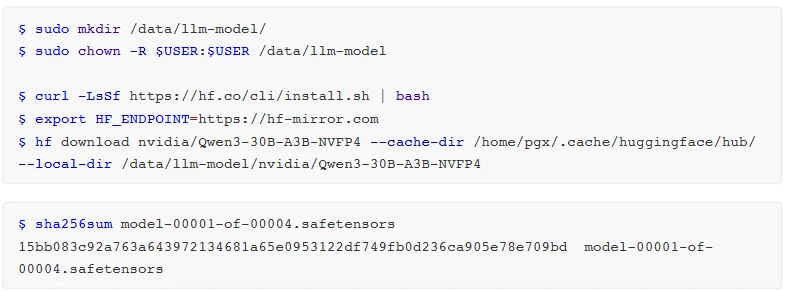
所以在本文的推理实践中采用了NVIDIA官方发布的NVFP4量化模型nvidia/Qwen3-30B-A3B-NVFP4,总参数量30B、单次激活参数量3B的MoE模型,可以最大化发挥硬件的内存与算力优势,是PGX的理想应用场景。
采用NVIDIA官方推荐的TensorRT-LLM框架搭配NVFP4 量化模型进行测试。
https://huggingface.co/nvidia/Qwen3-30B-A3B-NVFP4
启动命令如下:

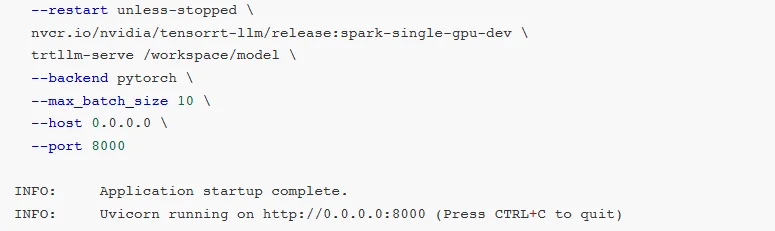
注意,官方推荐的--backendpytorch参数,会让模型跳过TensorRT的CUDAGraph优化与Kernel算子融合功能,仅以PyTorch原生模式运行,未能发挥TensorRT-LLM的核心加速优势。

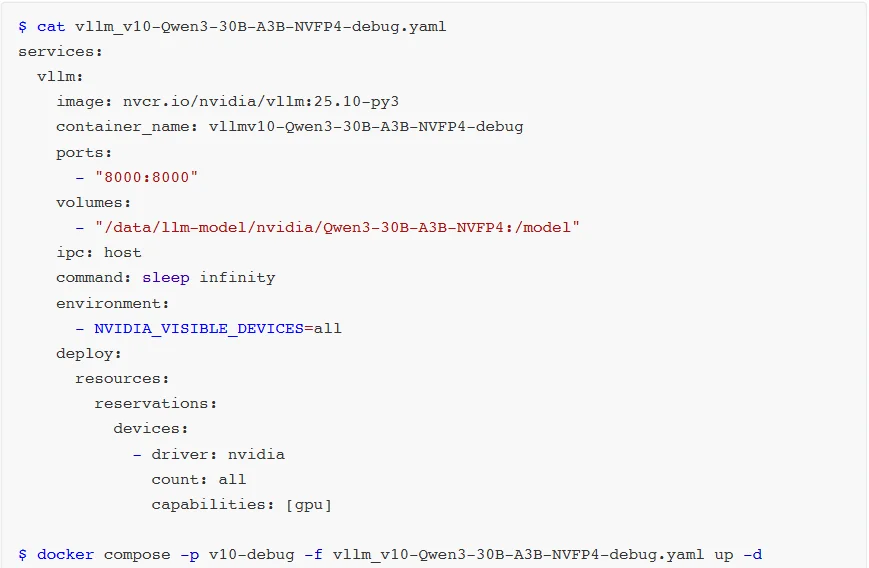
在v0.12.0 版本以前,使用vLLM + Qwen3-30B-A3B-NVFP4组合在执行CUTLASSFP4MoE矩阵乘法操作时会遇见RuntimeError:
FailedtoinitializeGEMM错误。这是因为旧版本的vLLMMoE模型对GB10 SM12.1架构NVFP4格式的适配并不成熟,有些关键Kernel核函数适配没有完成。
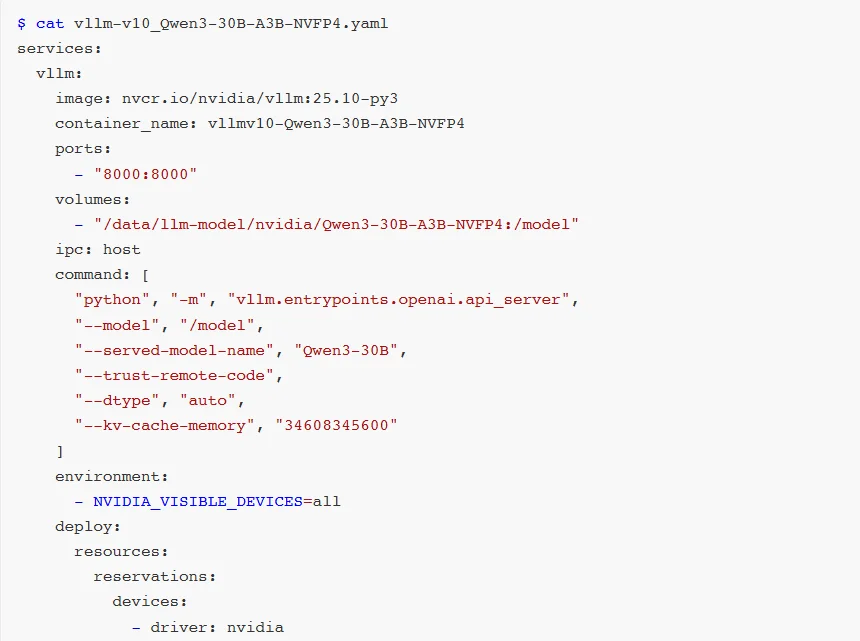

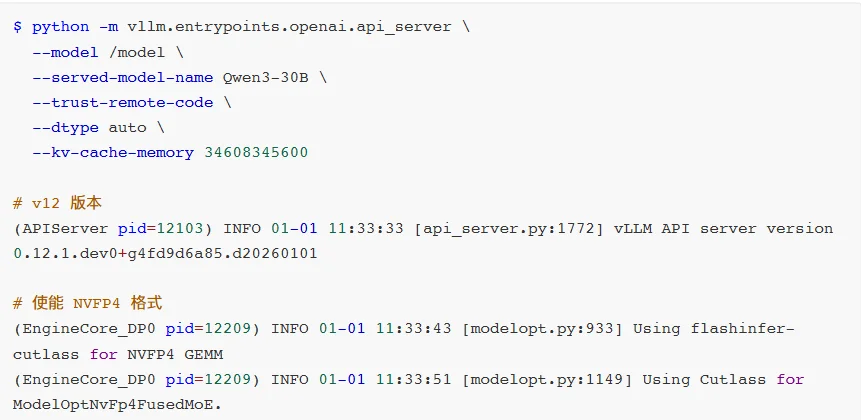
直到v0.12.0版本,vLLM就正式支持了NVFP4,标志着FP4格式逐渐被主流认可。

NGC已经提供了vLLMv0.12.0版本的镜像我们可以直接使用。
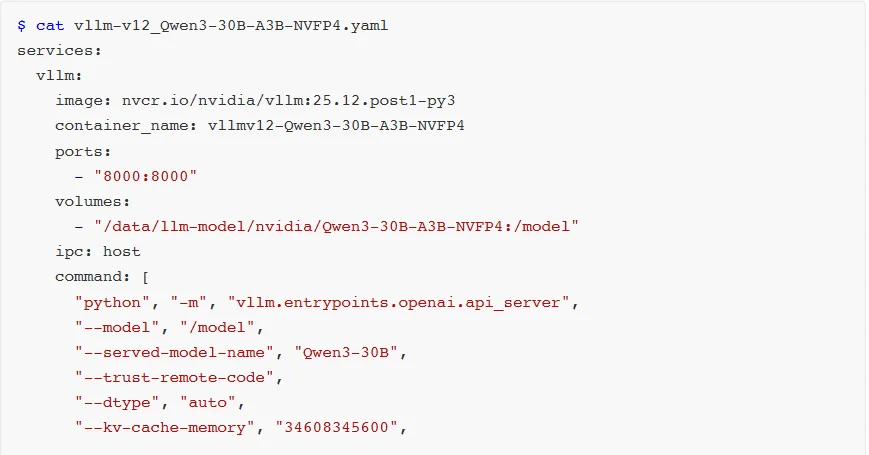

如果想使用自己的镜像时,可以手动编译v12版本。


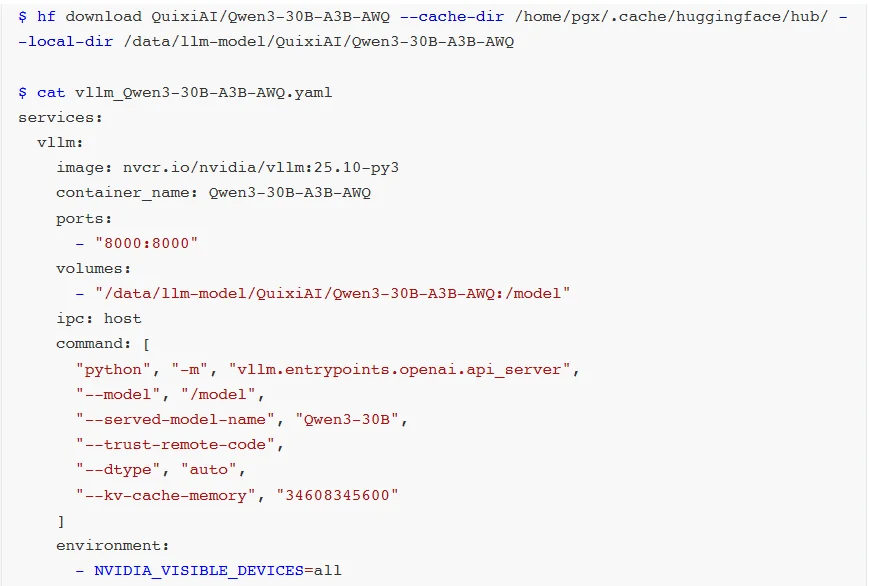
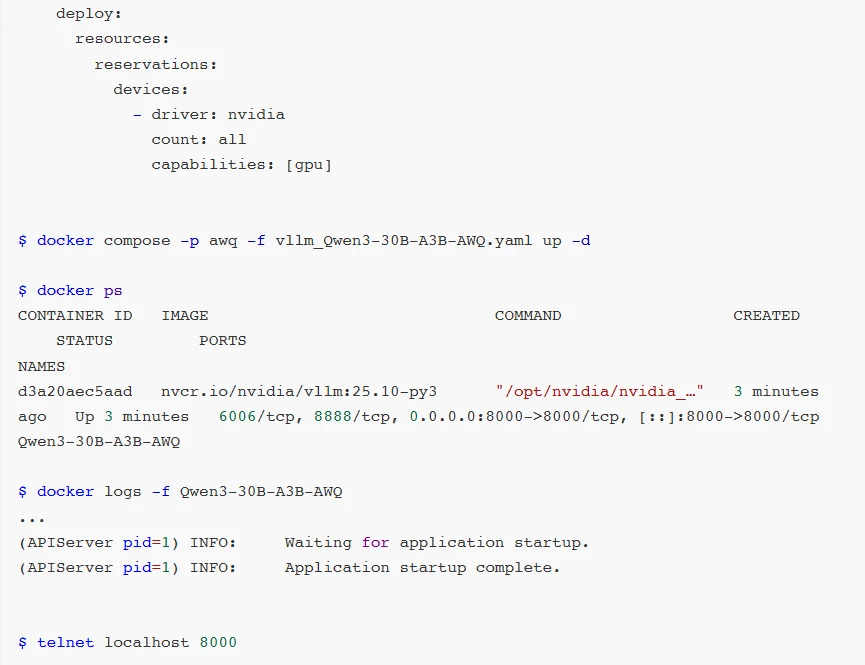
如果使用较久的vLLM版本时,推荐可以使用AWQ量化的Qwen3-30B-A3B-AWQ模型。
AWQ作为成熟的量化技术,拥有完善的社区支持与大量实践验证。vLLM框架对AWQ的适配经过多轮优化,具有稳定高效的运行链路。

使用第三方压测工具:
https://evalscope.readthedocs.io/zh-cn/v0.7.1/user_guides/stress_test/quick_start.html
压测参数设置:
对比测试结果:

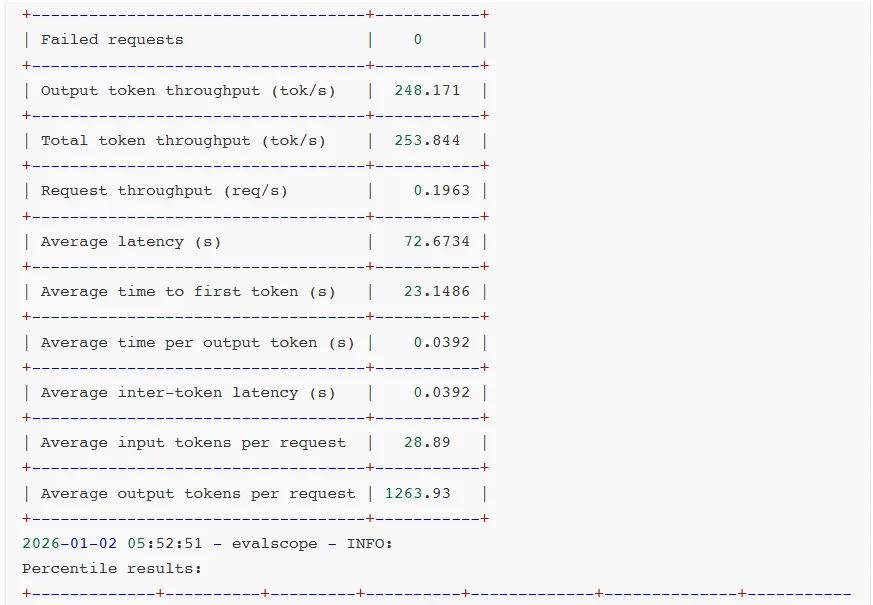
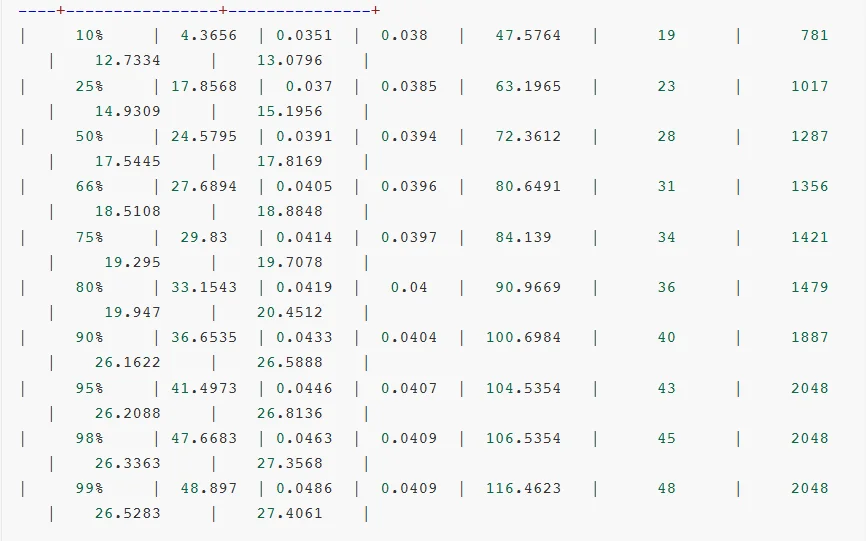

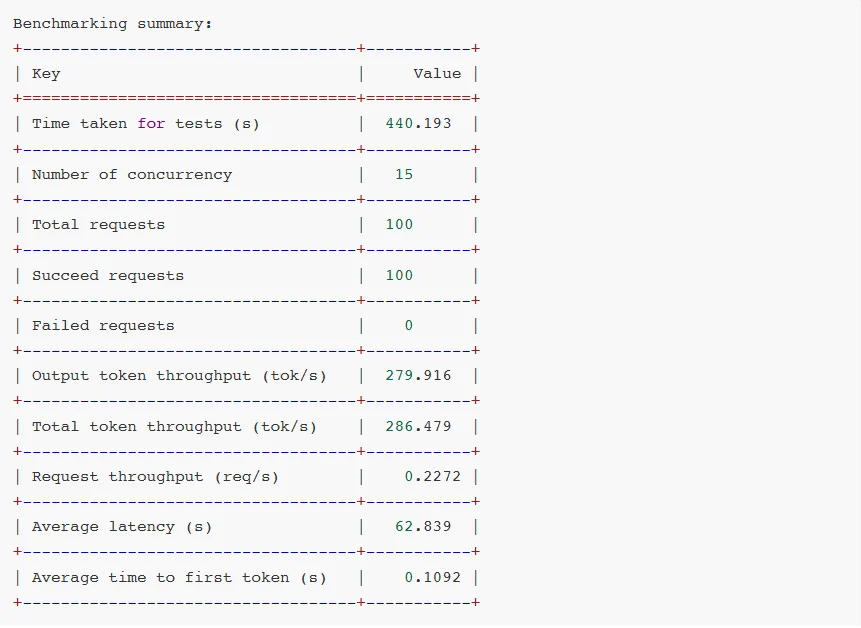
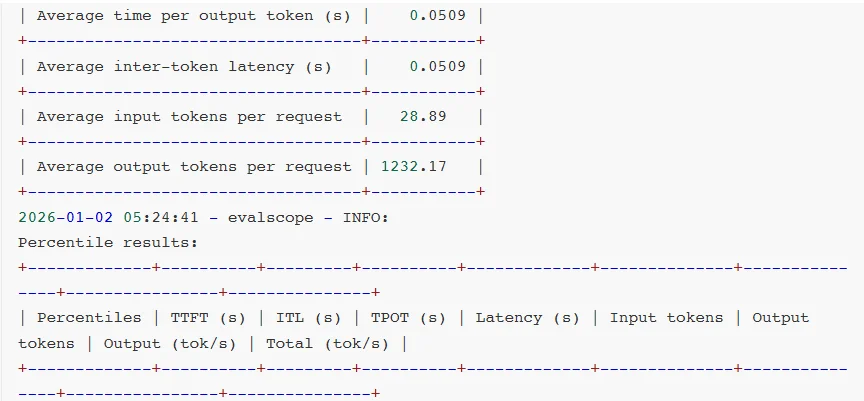
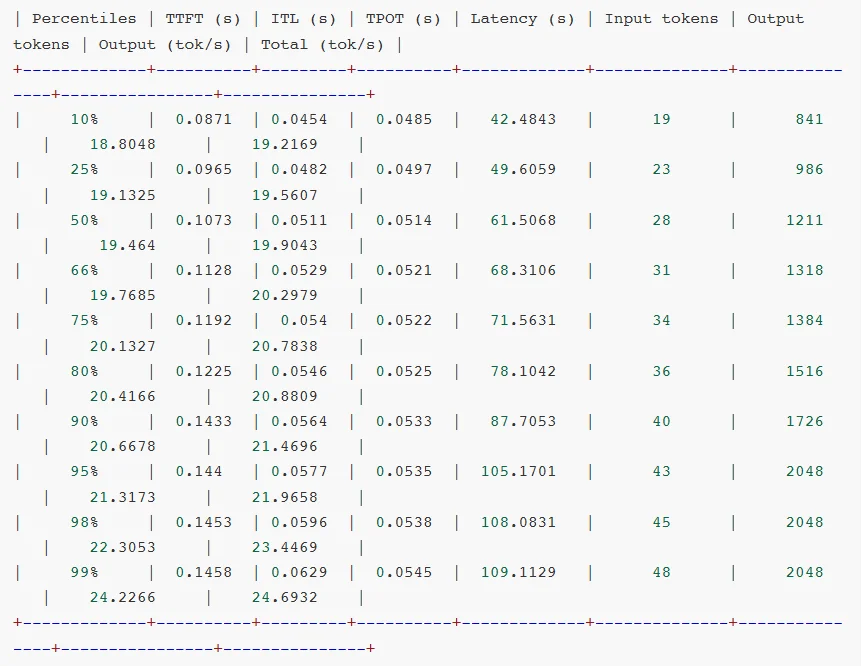
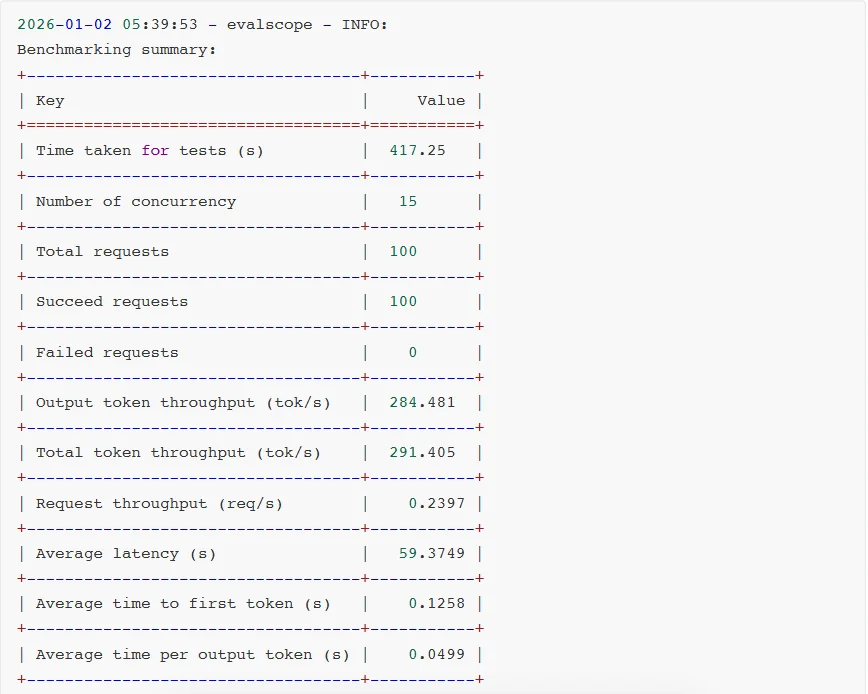
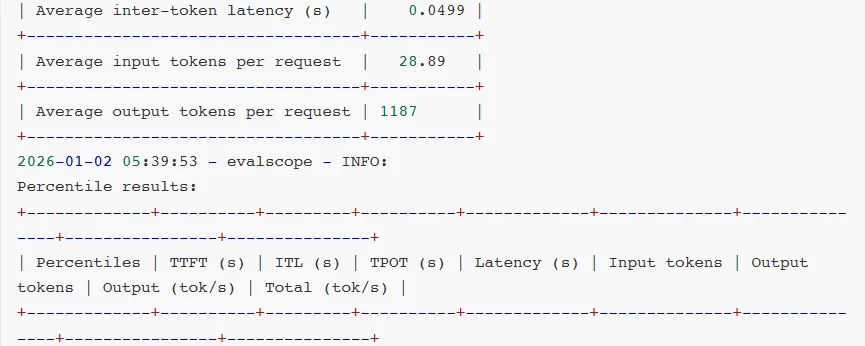
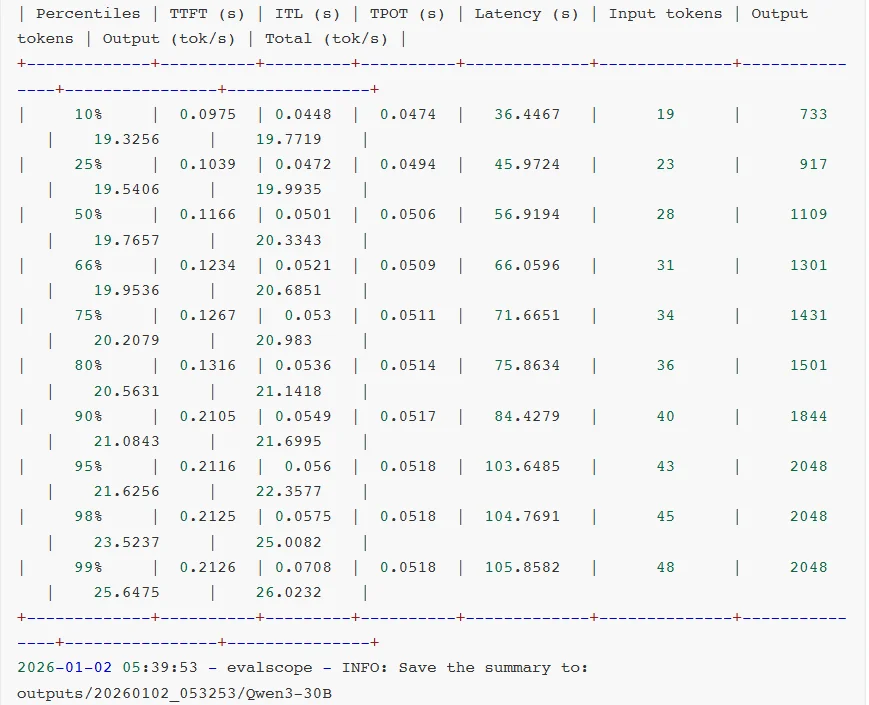
对比测试分析:
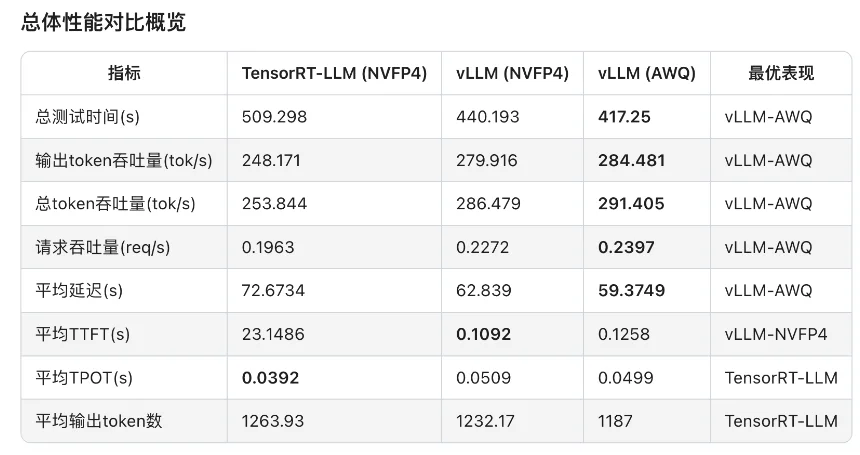
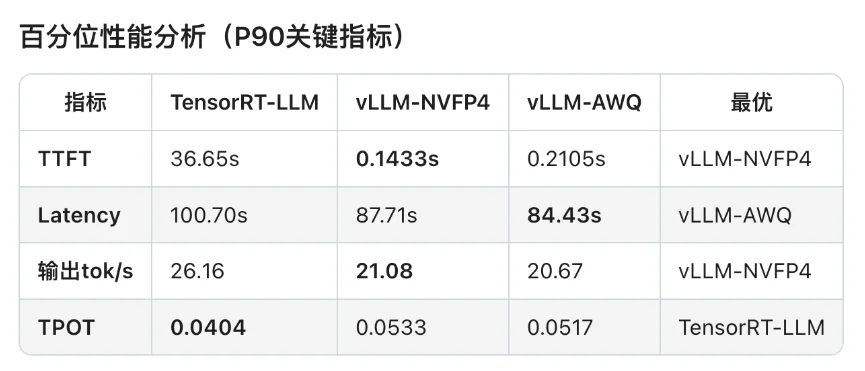
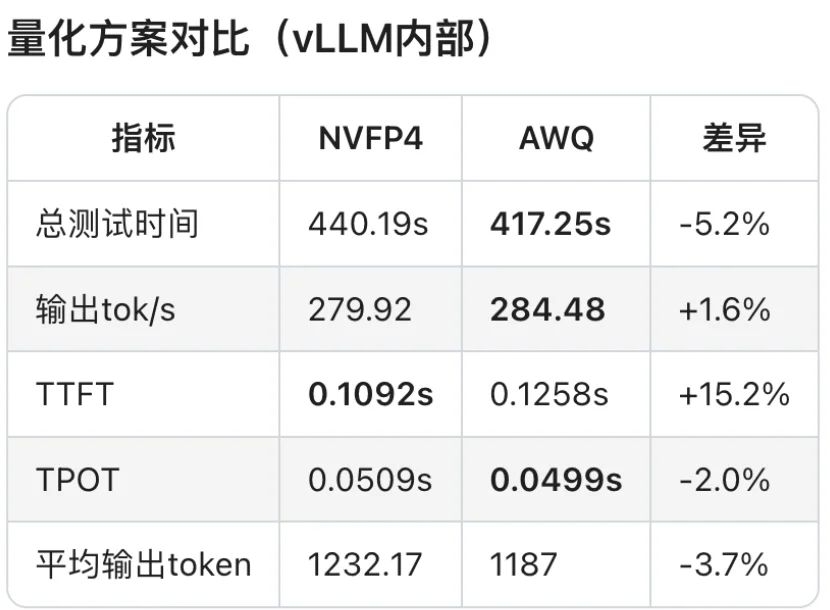
可见,软件生态成熟度通常是滞后于硬件迭代的。GB10 SM12.1属于新型架构,TensorRT-LLM框架对其优化仍处于初期阶段,所以部分性能优化实现无法启用,整体软件栈尚未完成与新硬件的深度适配。
相较于AWQ量化技术,虽然NVFP4具备理论技术优势,但NVFP4针对MoE模型推理所需的FusedMoEKernel尚未完成全场景适配。从报错日志可见,FlashInferkernels的缺失导致TensorRT-LLM即便能运行模型,也无法调用最优Kernel实现,限制了性能发挥。
另外,NVIDIA官方目前还没有针对batchsize、KVcache等vLLM参数配置给出最佳实践方案。可见NVFP4的软件生态仍处于建设阶段,尚未形成成熟的应用闭环。不过好在NVIDIA已经明确NVFP4的全面优化将会很快上线。
在模型开发的日程工作中离不开性能剖析的工作,尤其是NsightSystem和NsightCompute这两款NVIDIA性能剖析工具的使用,这些工具都被预先安装在PGX上了,我们可以方便的通过GUI桌面进行使用。
例如,上述性能测试对比我们知道,在同等条件下NVIDIA官方提供了TensorRT-LLM + Qwen3-30B-A3B-NVFP4方案的TTPT比较高,此时我们会就需要使用性能剖析的工具和方法来进行调查。这里主要介绍如何在PGX上使用nsys等工具的流程。
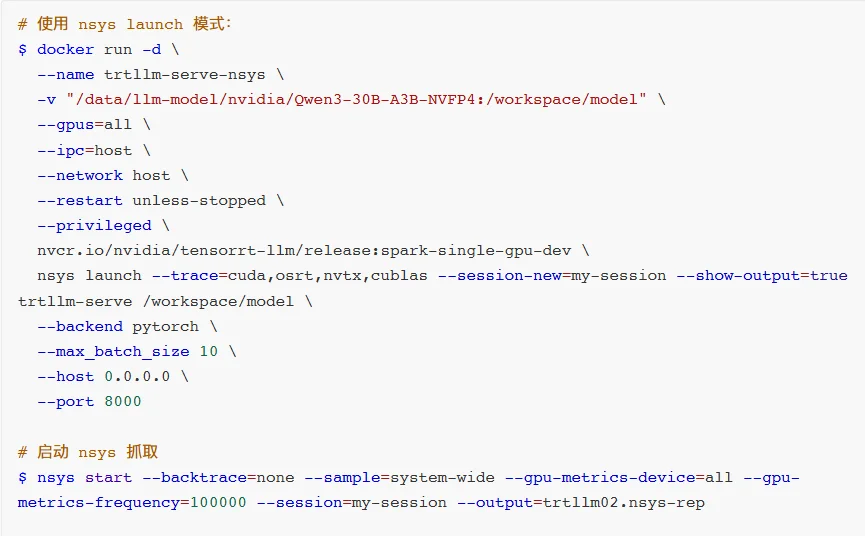
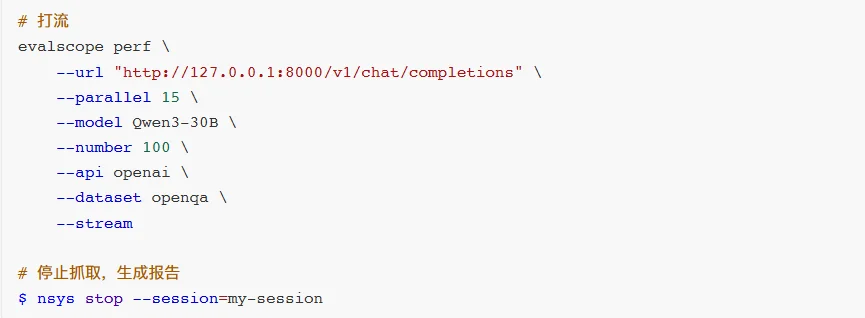

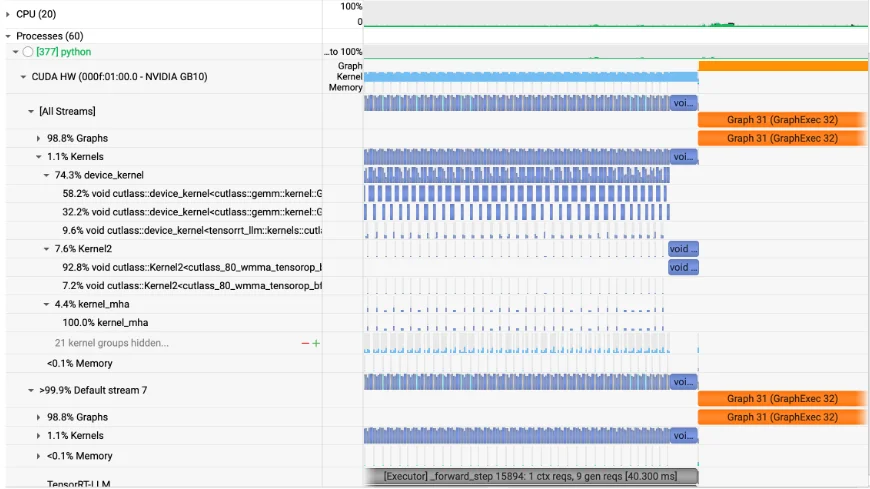
nsys性能剖析数据抓取完成之后就可以直接在PGXGUI桌面上查看了,如下图,我们可以用可视化的方式观测到TensorRT-LLM的Kernel核函数的执行过程Timeline图,对理解其执行流程有至关重要的作用。这些工具在PGX上都是预先安装好的,非常方便。
微调是指在已经训练好的大型预训练模型的基础上,进一步训练该模型以适应特定任务或特定领域的数据。可以在特定任务上取得更好的性能,因为模型在微调过程中会重点学习与任务相关的特性。还可以在多种领域(如情感分析、问答系统等)上进行微调,从而快速适应不同应用场景。另外,相比从零开始训练一个模型,微调所需的数据和计算资源显著减少了。
在实际大模型应用场景中,高效微调主要用于以下四个方面:
1. 改变对话风格:根据特定需求调整模型的对话风格。比如客服、虚拟助理等场景,通过微调少量的参数(例如对话生成的策略、情感表达等),可以使模型适应不同的语气、礼貌程度或回答方式。
2. 注入私域知识:将外部知识或领域特定的信息快速集成到预训练模型中。比如法律、医疗、IT等专业领域,
通过少量的标注数据对预训练模型进行微调,帮助模型理解特定行业的术语、规则和知识,进而提升专业领域的问答能力。
3. 提升推理能力:在处理复杂推理任务时,微调使模型能够更高效地理解长文本、推理隐含信息,或者从数据中提取逻辑关系,进而在多轮推理任务中提供更准确的答案。这种微调方式可以帮助模型在解答复杂问题时,提高推理准确性并减少错误。
4. 支撑Agent需求:通过Agent使得模型能够有效地与其他系统进行交互、调用外部API执行特定任务。通过针对性微调,模型可以学会更精准的FunctionCalling策略、参数解析和操作指令,从而支撑Agent的能力。
现在绝大多数开源模型,在开源的时候都会公布两个版本的模型。一个是Base模型,该模型只经过了预训练,没有经过指令微调。其二则是微调模型,是在Base模型的基础上进一步进行全量指令微调之后的对话模型。
从广义上讲,微调可以分为2 种主要方式:全量微调和高效微调。选择哪种微调方法,取决于开发者希望对原始模型进行多大程度的调整。
LLM微调是一种对GPU显存和计算要求极高的工作负载,在每个训练步骤中都需要进行以数十亿次量级的矩阵乘法来更新模型权重。即使是像Mistral 7B这样的小型LLM进行全面微调,也可能需要高达100GB的内存。所以,在进行微调前,需要考虑的因素是各种微调方法的GPU显存需求。
并且显然的,相较于LoRA和QLoRA高效微调,完整微调对内存和吞吐量要求更高。尽管完全微调可以对模型的能力进行深度改造,但要带入模型全部参数进行训练,需要消耗大量的算力,且有一定的技术门槛。相比之下,在绝大多数场景中,如果我们只想提升模型某个具体领域的能力,那高效微调会更加合适。
由于微调需要消耗大量的显存,因此参数规模超过30B的大模型往往无法在32GB消费级GPU上运行,但却可以轻松在拥有128GBUMA的PGX上随时进行。下表展示了在PGX上对Llama系列模型进行微调的性能表现。
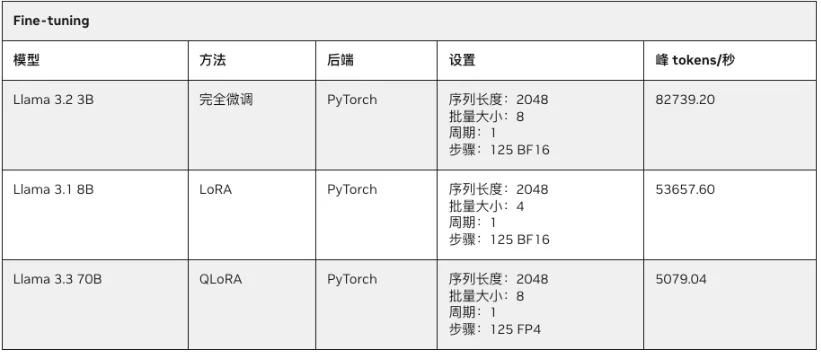
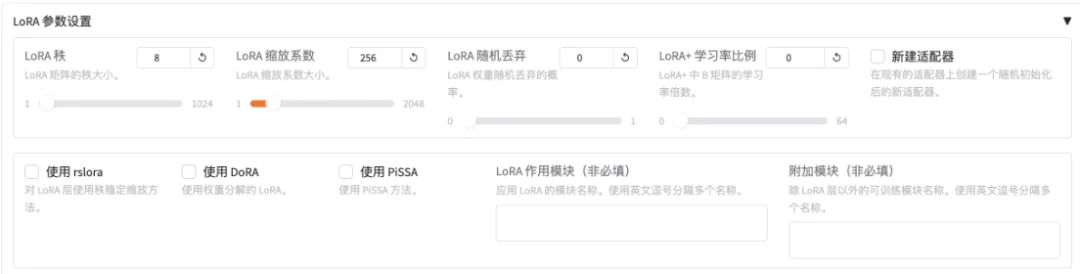
LoRA(Low-RankAdaptation,低秩适应)旨在通过引入低秩矩阵来减少微调时需要调整的参数数量,从而显著降低显存和计算资源的消耗。具体来说,LoRA微调并不直接调整原始模型的所有参数,而是通过在某些层中插入低秩的适配器(Adapter)层来对低秩矩阵进行训练。
LoRA的原理:
在完全微调中,会修改模型的所有权重,而在LoRA中,只有某些低秩矩阵(适配器)会被训练和调整。这意味着原始模型的参数保持不变,只是通过少量的新参数来调整模型的输出。
低秩矩阵的引入可以在显存和计算能力有限的情况下,依然有效地对大型预训练模型进行微调,从而让LoRA成为显存较小的设备上的理想选择。
LoRA的优势:
1. 显存优化:只需要调整少量的参数(适配器),显著减少了显存需求,适合显存有限的GPU。
2. 计算效率:微调过程中的计算负担也更轻,因为减少了需要调整的参数量。
3. 灵活性:可以与现有的预训练模型轻松结合使用,适用于多种任务,如文本生成、分类、问答等。
QLoRA(QuantizedLow-RankAdaptation)是LoRA的一个扩展版本,它结合了LoRA的低秩适配器技术和量化技术。在LoRA的基础上再进一步优化了计算效率和显存需求,特别是在极端显存受限的环境下。
QLoRA的原理:
与LoRA不同的是,QLoRA会将插入的低秩适配器层的部分权重进行量化,通常是量化为FP4、INT4 或INT8 等低精度格式,在保持性能的同时显著降低模型的存储和计算需求。
可见,QLoRA涉及量化(quantization)技术,将模型的一部分权重参数存储在较低精度的数值格式中,以此减少内存使用和计算量,同时结合LoRA的低秩调整,让适应过程更加高效。
QLoRA的优势:
1. 在显存非常有限的情况下仍能进行微调。
2. 可以处理更大规模的模型。
3. 适合用于边缘设备和需要低延迟推理的场景。
安装部署
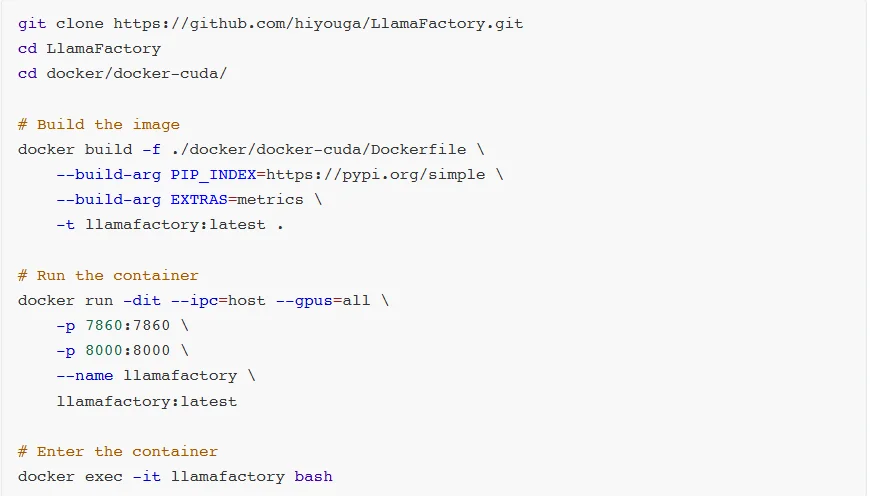






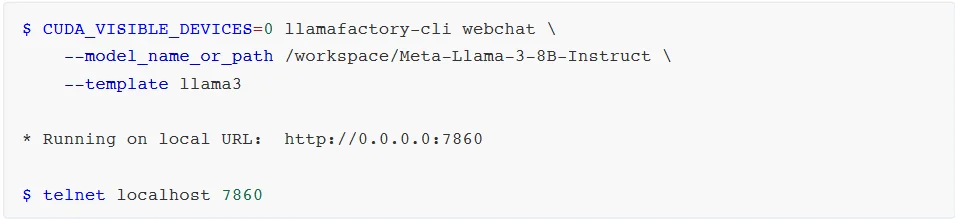
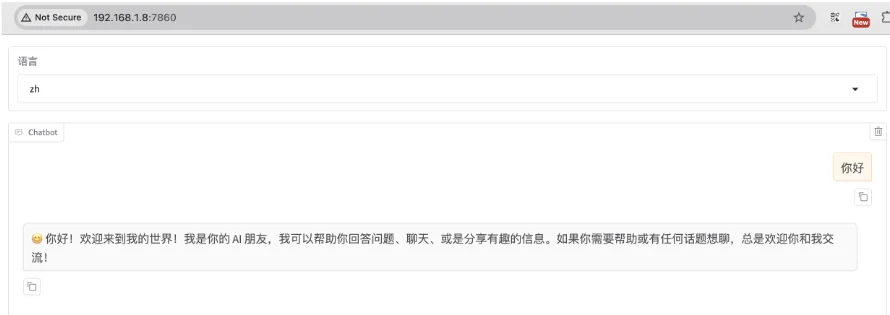
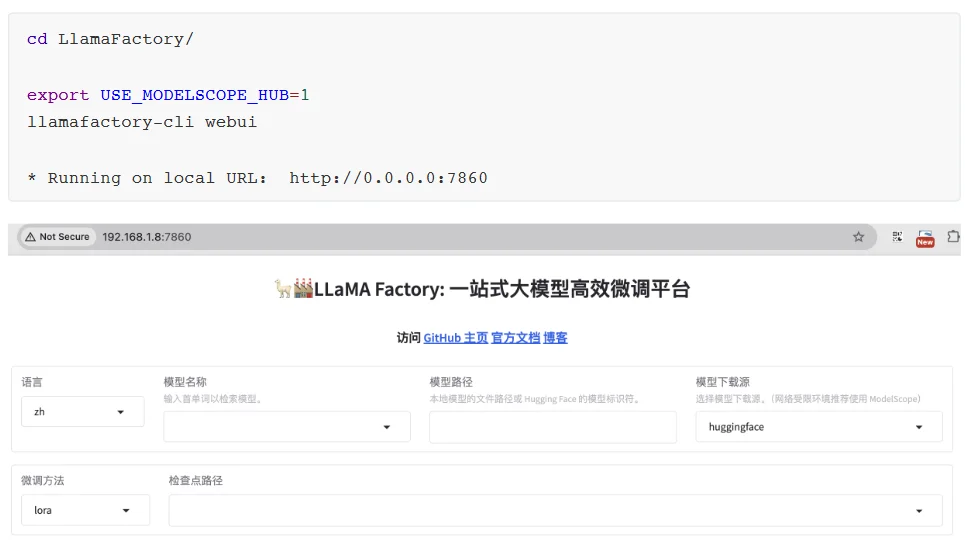
打开WebUI:
魔搭社区集成了相当丰富的中文数据集,有很多分类可以选。
https://www.modelscope.cn/datasets
找一个角色扮演的数据集来微调(方便查看效果)。
https://www.modelscope.cn/datasets/kmno4zx/huanhuan-chat
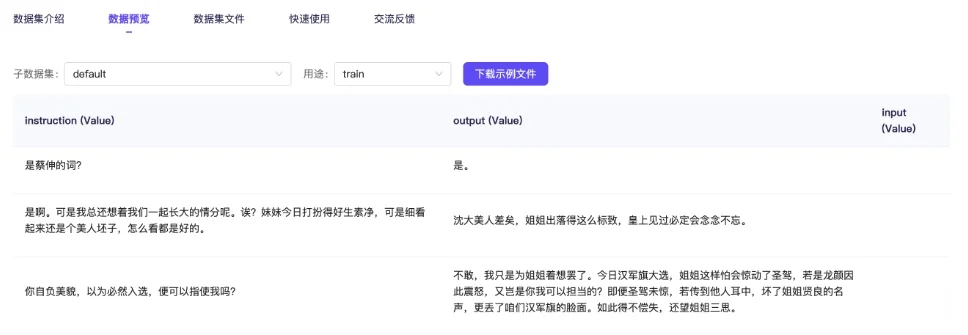
在数据预览这里查看详细数据。
注意,llama-factory目前只支持两种格式的数据集:Alpaca和Sharegpt格式。
https://github.com/hiyouga/LlamaFactory/tree/v0.9.1/data
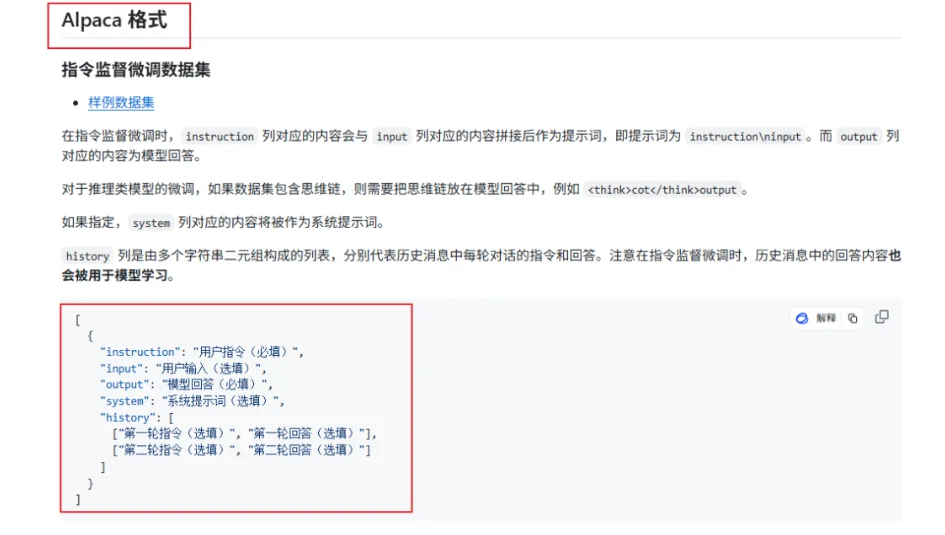
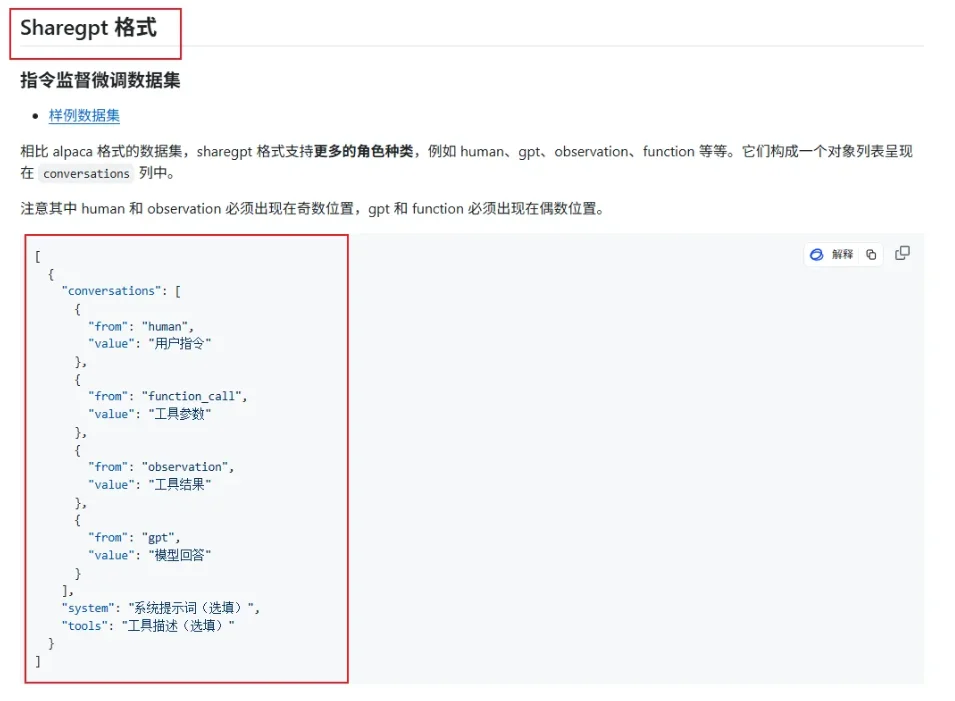
切换到数据集文件这边,打开huanhuan.json文件,看到它其实就是Alpaca格式的数据集,仅下载这一个文件即可。
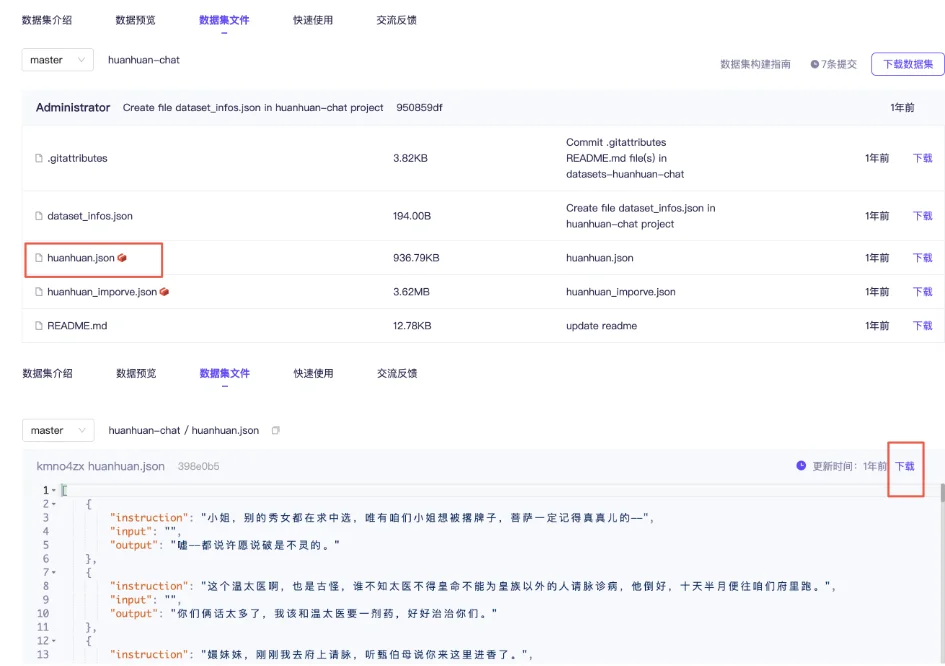
在llama-factory添加数据集,不仅要把数据文件放到data目录下,还需要在配置文件dataset_info.json里面添加一条该数据集的记录。这样,新添加的数据集才能被llama-factory识别到。
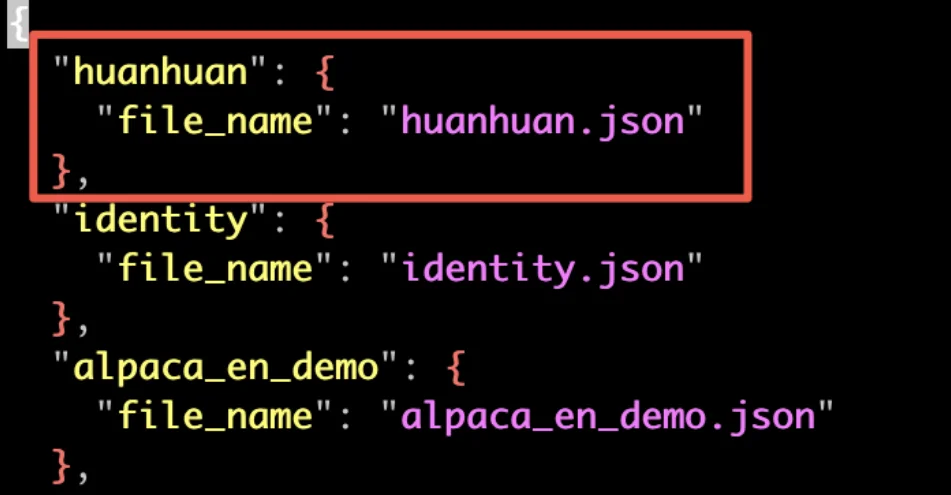
这里保存之后,webui那边会实时更新,不需要重启
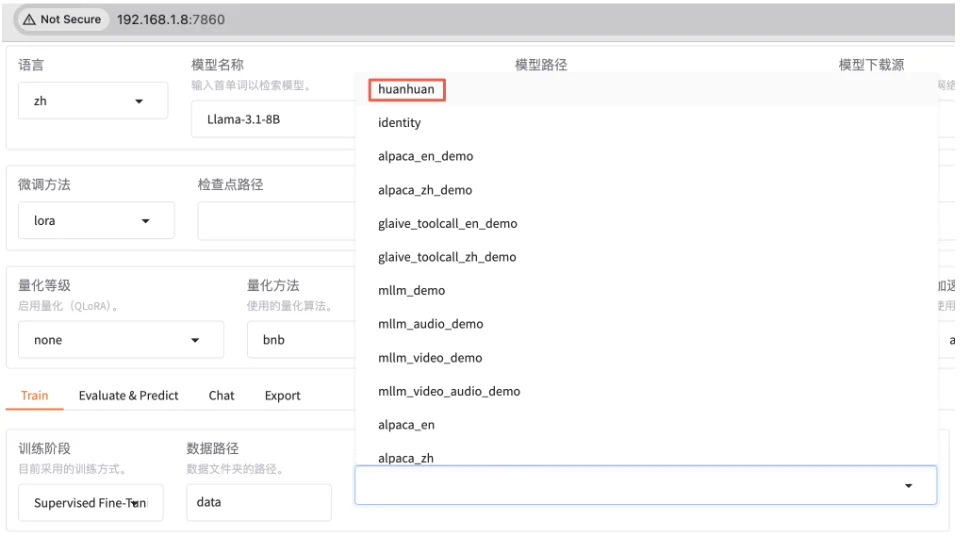
微调Qwen3-1.7B-Base基础大模型,方法选用LoRA。
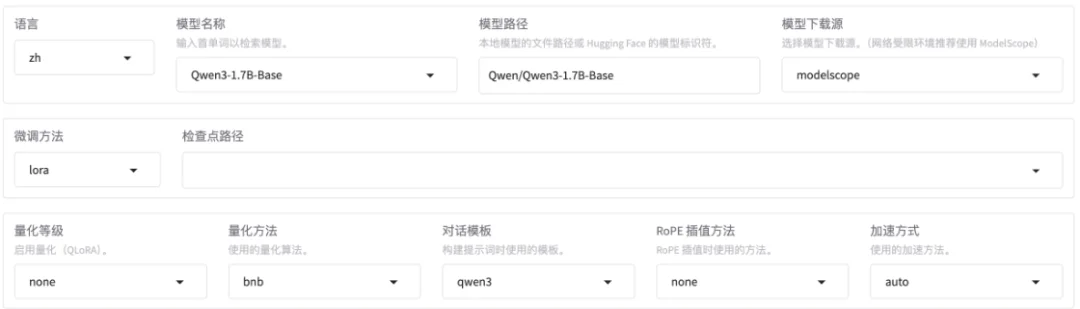
使用huanhuan数据集,先训练1轮看看效果,如果效果不理想再多训练几轮。由于数据集都是一些短问答,可以把截断长度设置小一点,为1024(默认是2048)。梯度累计设置为4。注意,计算类型选择BF16,暂不支持FP4。
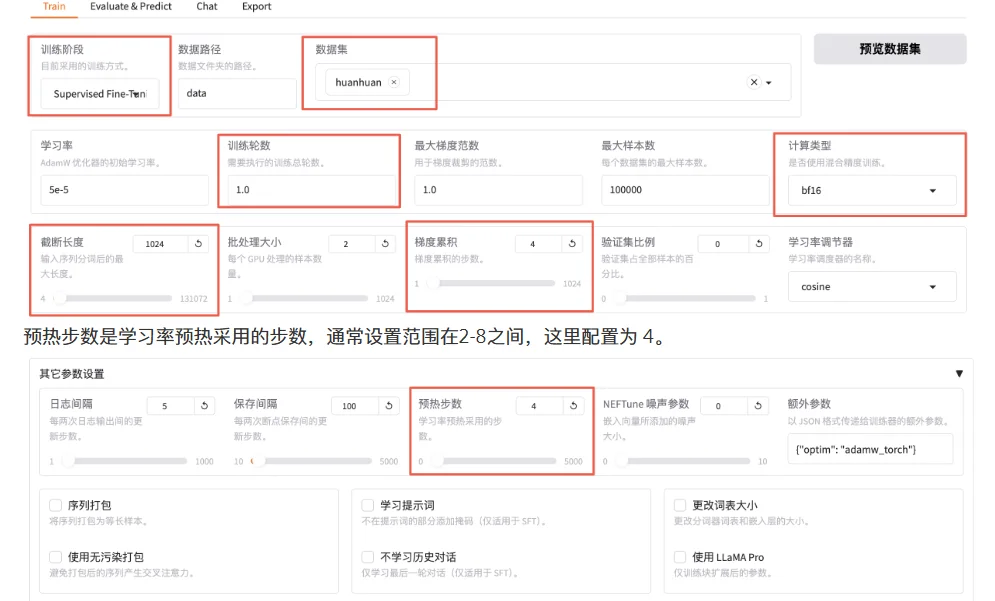
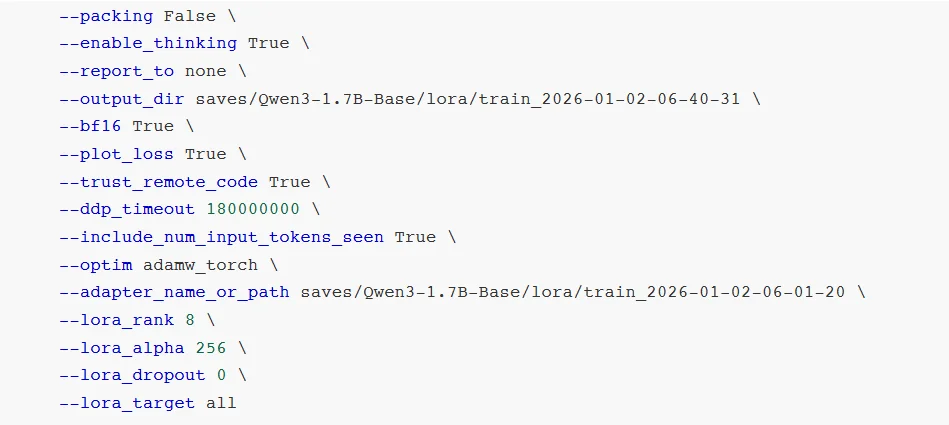
继续设置LoRA微调参数:
预览训练指令并开始训练。
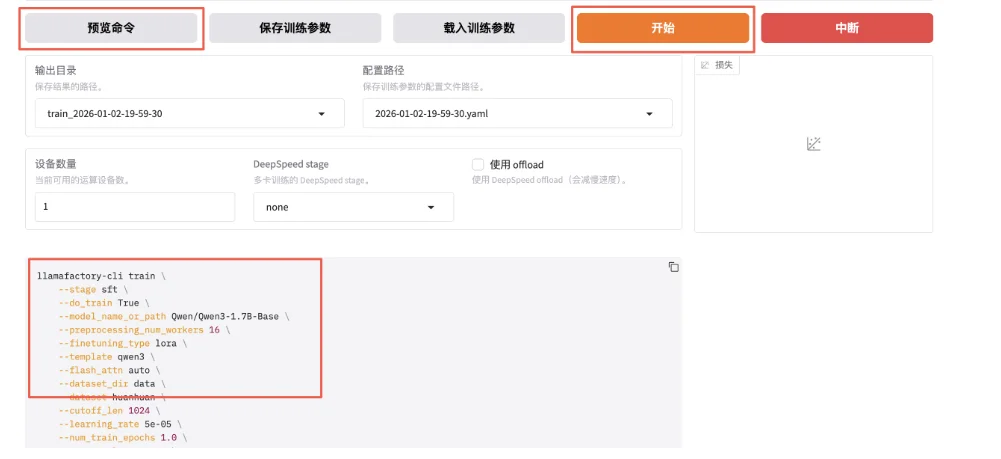
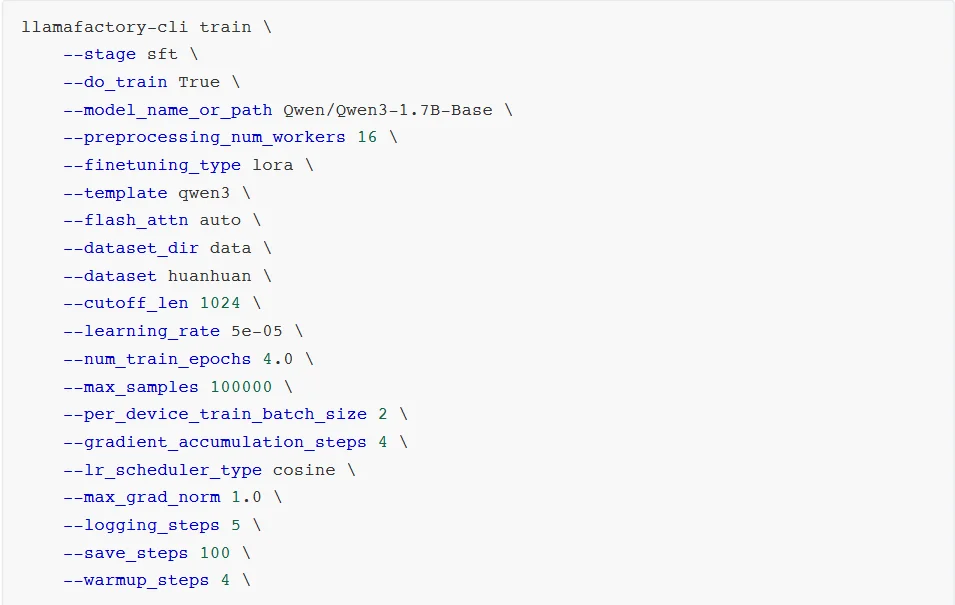
stage:指示当前训练的阶段,枚举值sft、pt、rm、ppo等,这里我们是有监督指令微调,所以是sft。
如果本地没有找到模型,会先自动下载模型:

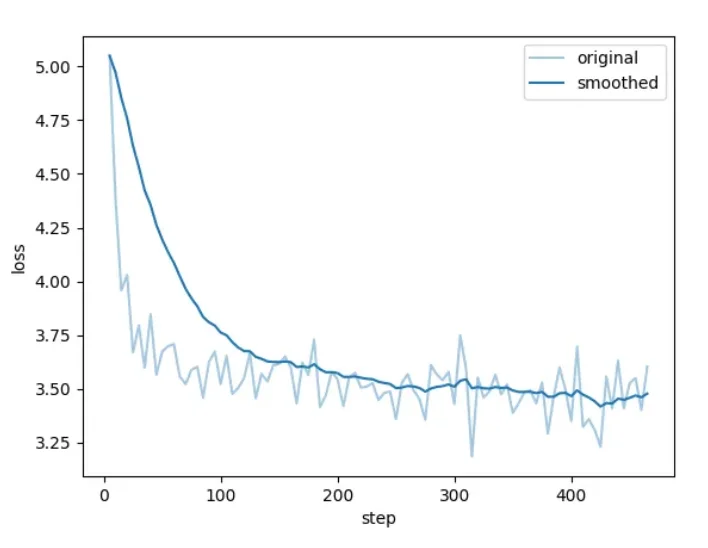
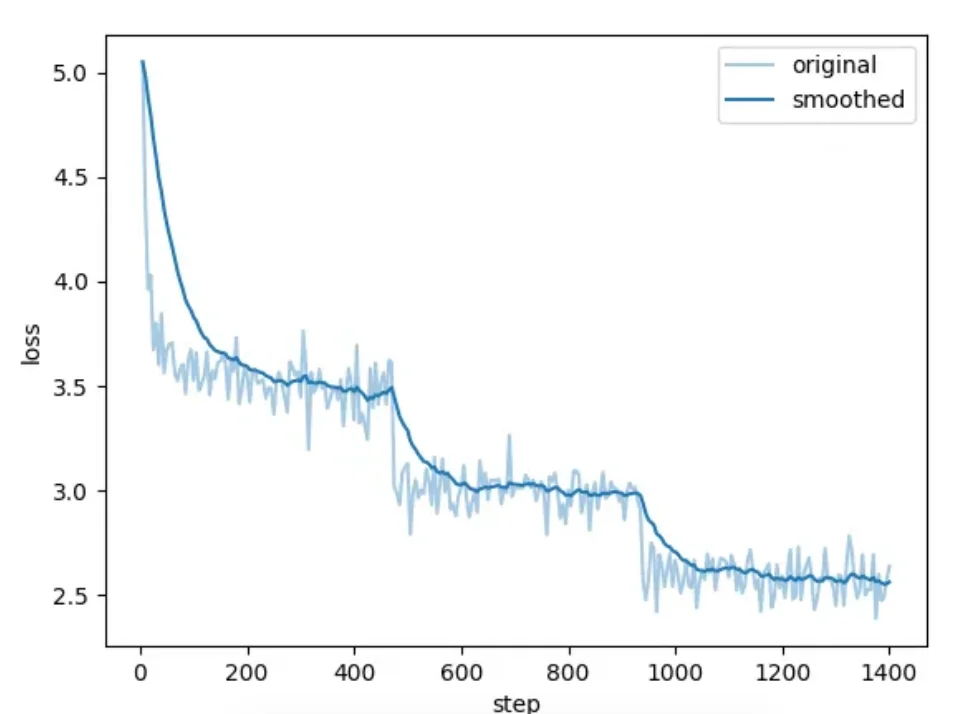
开始训练后可以查看进度条和损失值曲线。
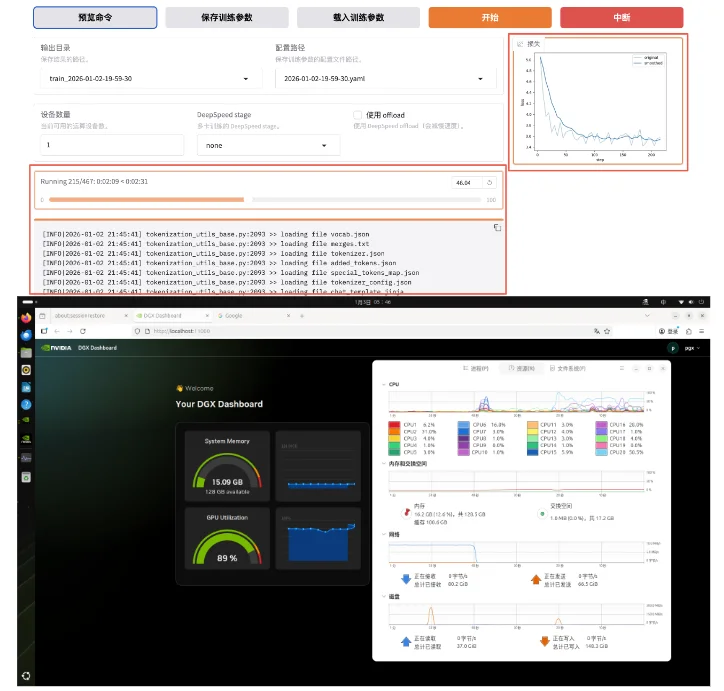
看到类似下面"训练完毕" 就代表微调成功。
微调成功后,我们得到了一个Checkpoint记录,下拉可以选择刚刚微调好的模型。
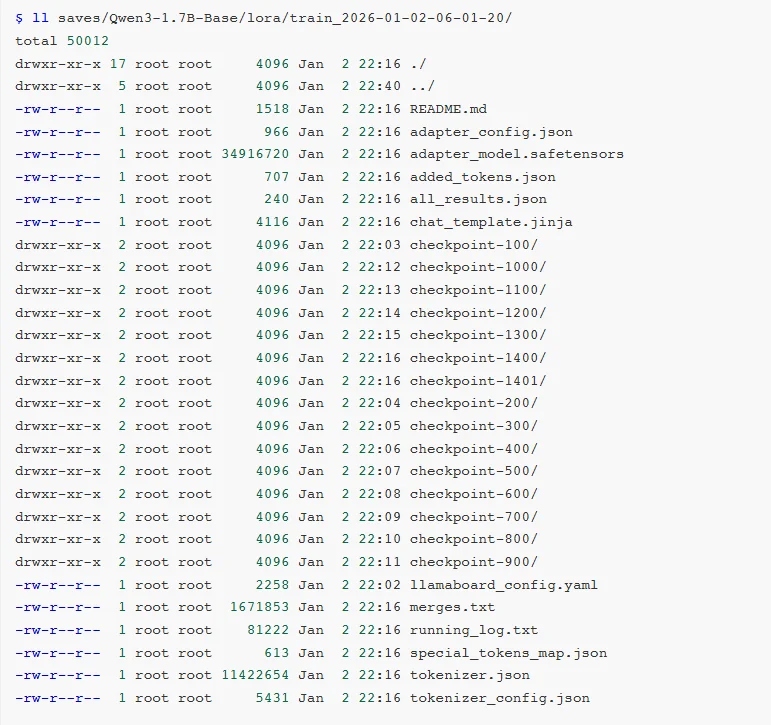
Checkpoing在后台的存储位置是saves/Qwen3-1.7B-Base/lora/:
adapter开头的是LoRA适配器结果,后续用于模型推理融合。
training_loss和trainer_log等记录了训练过程中的指标。
其他是训练时各种参数的备份。
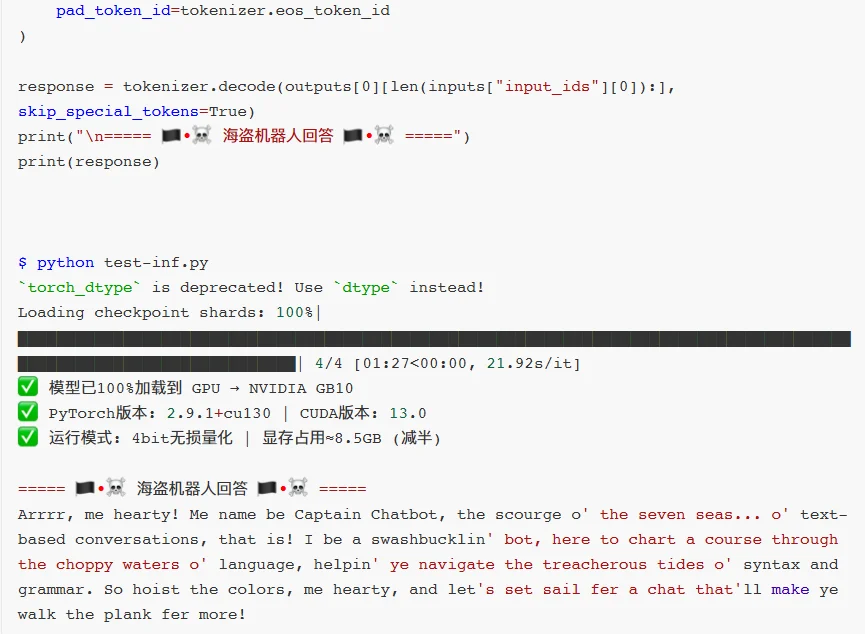
把窗口切换到chat,可以点击加载模型。
加载好之后就可以在输入框发送问题,测试微调模型的效果。
对LoRA微调模型进行推理,需要应用动态合并LoRA适配器的推理技术。需要通过finetuning_type参数告诉使用了LoRA训练,然后将LoRA的模型位置通过adapter_name_or_path参数即可。

但是渲染只训练了一次的效果很差。

如果想切换回微调之前的模型,只需先卸载模型,选择想要的Checkpoint,然后再加载模型即可。如果想重新微调,需要修改红框中的两个值。
在经过3 个Epoch的训练之后,效果也越好越好了。
批量推理和训练效果评估
上文中的人工交互测试实际上并不严谨,通常我们需要进行自动化的批量测试。例如:使用自动化的bleu和rouge等常用的文本生成指标来做评估。
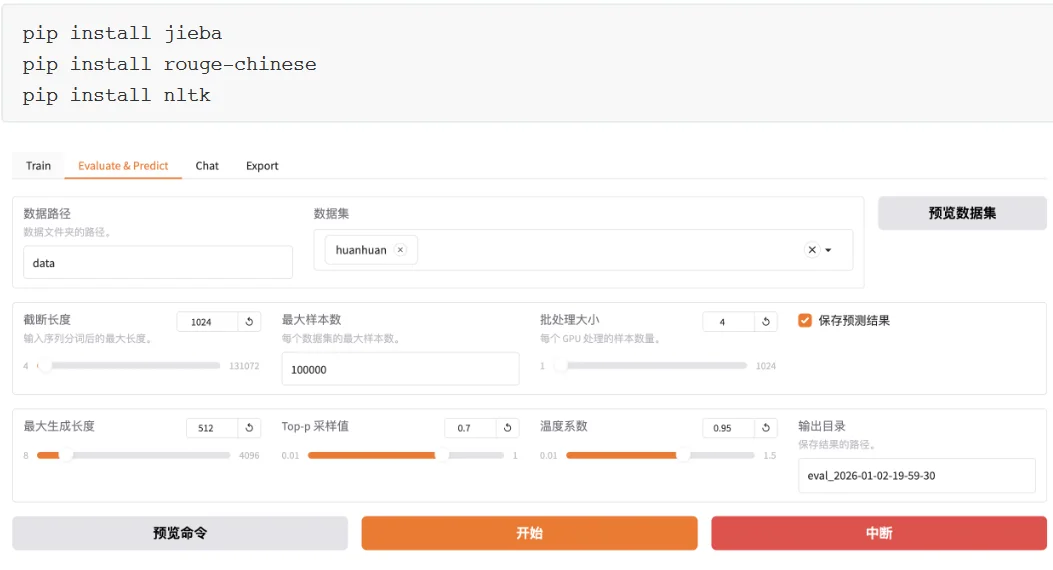
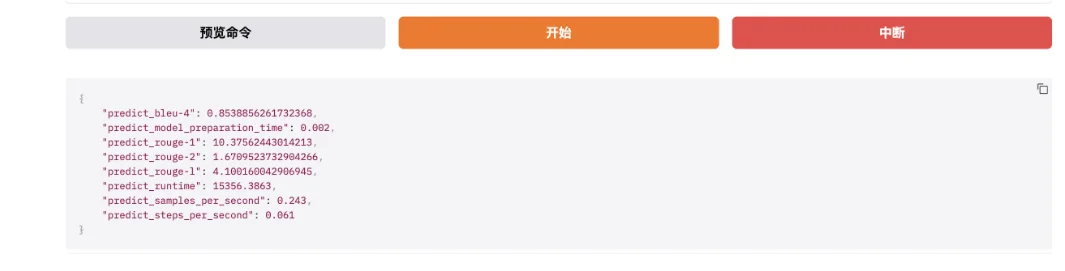
与训练脚本主要的参数区别如下3 个:
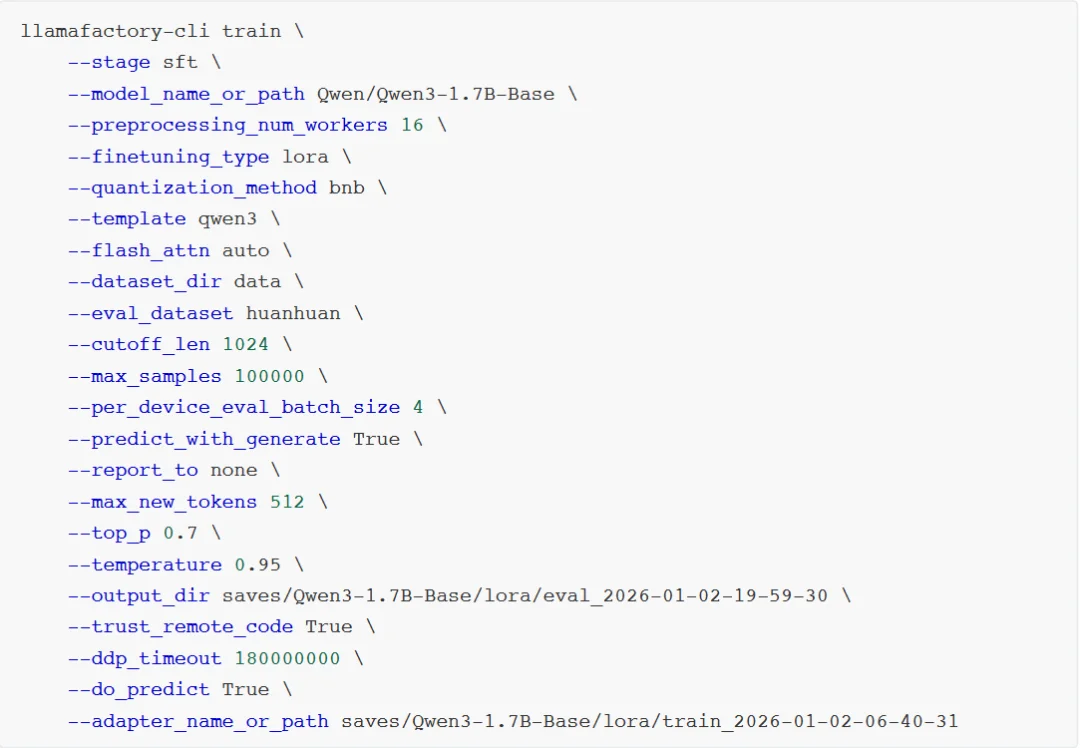
完成后查看微调质量评估结果,下面是训练效果评估指标。
质量类指标:BLEU-4 +ROUGE-1/2/L,衡量模型生成文本的好坏、和标准答案的匹配度、内容质量优劣。
BLEU-4:是一种常用的用于评估机器翻译质量的指标。BLEU-4 表示四元语法BLEU分数,它衡量模型生成文本与参考文本之间的n-gram匹配程度,其中n=4。值越高表示生成的文本与参考文本越相似,最大值为100%。如下,BLEU-4=0.8539 属于高分,说明模型生成的文本,和标准答案的语义贴合度极高、核心信息无遗漏、表达逻辑一致,对于8B 量级的开源大模型,这个分数是优秀水平。
predict_rouge-1:是一种用于评估自动摘要和文本生成模型性能的指标。ROUGE-1 表示一元ROUGE分数,衡量模型生成文本与参考文本之间的单个词序列的匹配程度,即:词汇层面的匹配度,看生成文本有没有用到标准答案里的核心词。值越高表示生成的文本与参考文本越相似,最大值为100。如下,rouge-1=10.37属于高分,模型能精准捕捉到标准答案里的核心关键词,生成内容不会偏离主题,这是优质模型的核心特征。
predict_rouge-2:ROUGE-2 表示二元ROUGE分数,衡量模型生成文本与参考文本之间的双词序列的匹配程度,即:短语/ 短句层面的匹配度。同上,最大值为100。如下,rouge-2=1.67分数偏低,但这是正常现象,ROUGE-2要求连续两个词和标准答案完全一致,而大模型的优势是语义一致但表达多样化的泛化能力。大模型使用不同的短语表达相同的意思,这是生成能力的体现,不是缺陷。如果rouge-2分数很高,反而说明模型在的泛化能力极差。
predict_rouge-l:ROUGE-L表示最长公共子序列匹配率,衡量模型生成文本与参考文本之间最长公共子序列的匹配程度,即:整句的语义连贯性和语序一致性。同上,最大值为100。如下,rouge-L=4.10中等分数,表示模型生成的文本语义完整、逻辑通顺,虽然句式和标准答案不同,但核心信息完整、语序合理,能准确回答问题。
如果是文本摘要任务,那么rouge-1 一般20-40,rouge-2 5-15,rouge-L10-25;如果是开放问答/ 对话/ 指令遵循任务,那么rouge-1 8-15,rouge-21-3,rouge-L 3-6。下列数值完全落在这个区间内,是标准水平。
性能类指标:耗时/ 吞吐量/ 加载时间,衡量模型推理速度、效率、硬件利用率。
predict_model_preparation_time:表示模型加载和预热(显存初始化)的耗时。如下,0.002s是优秀的数值。
predict_runtime:本次批量推理的总耗时,单位为秒。如下,15356秒= 4小时16分钟。
predict_samples_per_second:每秒推理生成的样本数量,推理吞吐量核心指标的核心指标,表示模型每秒钟能够生成的样本数量。用于评估模型的推理速度。如下,0.243样本/秒,表示模型平均每4.1秒处理1条推理样本。
predict_steps_per_second:每秒执行的step数量,模型每秒钟能够执行的step数量。模型每生成一个token就是一个step。如下,0.061 step/s表示每秒生成约0.061 个token。
通过对比1 Epoch和3Epoch微调的结果可以看出,多轮训练后的效果会更好一些。

训练后也会在output_dir下看到如下新文件:

LoRA模型合并导出:
通过不断“炼丹” 直到效果满意后就可以导出模型了。即:把训练的LoRA模型和原始Base模型进行融合,输出一个完整的模型文件。
检查点路径选择我们刚刚微调好的模型,切换到export,填写导出目录output/qwen3-1.7b-huanhuan。
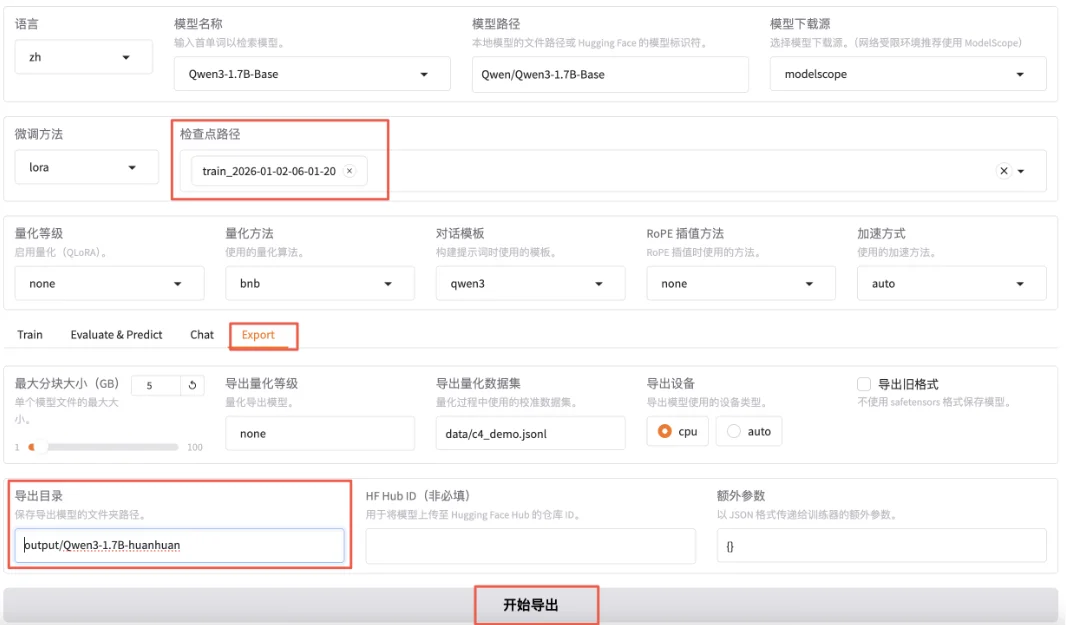
导出完成之后就可以在output目录下看到qwen3-1.7b-huanhuan目录了。
这里用Ollama + GGUF进行部署。
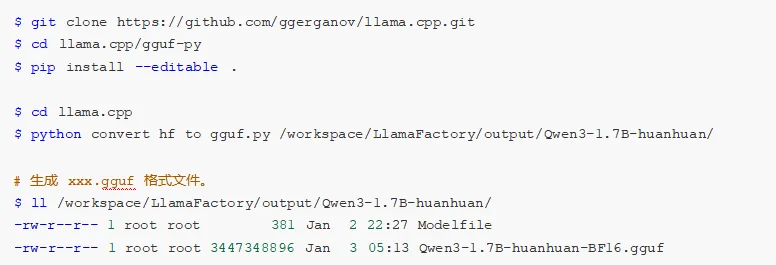
其中,GGUF是大模型的存储格式,可以对模型进行高效的压缩,减少模型的大小与内存占用,从而提升模型的推理速度和效率。如下,安装GGUF并将微调后大模型的格式进行转换。
另外,Ollama是大模型推理框架,适用于个人环境使用,简单而高效。

相信很多AI开发者都经历过和笔者同样的困境:一方面,公司仅有的公共GPU服务器要排队申请,好不容排到时段却发现环境被改得面目全非,调试半天才能跑代码;另一方面,想用消费级显卡本地验证想法,却发现小几十GB显存连70B的大模型都加载不动。资源短缺和环境割裂,让我们80% 的时间浪费在等待和折腾上,而非真正的创新。
ThinkStationPGX这台巴掌大的设备确实能够解决我们从事AI开发时的关键痛点:
1. 独占算力,不再排队:128GB统一内存+FP4量化技术,单机支持200B模型推理或70B模型微调,相当于把2-4张高端显卡的算力浓缩进桌面设备。从此不必再争抢资源,想研究什么AI技术,想安装什么AI框架,想开发什么AI应用,都可以立刻开始。
2. 开箱即用的生产级环境:预装与NVIDIA数据中心完全一致的软件栈(CUDA、PyTorch),本地调试的模型和容器可直接部署到云端服务器,告别“开发环境能跑,生产环境崩掉” 的尴尬。
3. 移动式超算工作站:1.2kg重量+ 35dB静音设计,插上电源和显示器就能在工位、实验室甚至咖啡厅继续工作,研究进程不再被地点束缚。
在深度使用和体验之后,笔者觉得ThinkStationPGX会非常适用于以下人群和场景:
简而言之,如果你厌倦了在共享GPU的等待队列中消磨创造力,受够了消费级显卡的显存天花板,ThinkStation PGX就是那台能够让我们把“超算装进背包” 的终极武器—— 让开发环境沉默而可靠,让创新专注且自由。
文章来自于“CSDN”,作者 “CSDN”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
