# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

随着大模型在单点推理上日益逼近 PhD 水平,Agent 领域迎来了新的分水岭:短程任务表现惊艳,长程任务却显乏力。为精准评估大模型的多模态理解与复杂问题解决能力,红杉中国在两周内连续发布两篇论文,旨在通过构建更科学的评估基准,预判技术演进的未来方向。
xbench 正式推出 AgentIF-OneDay 评测体系,不再单纯考核模型知道多少知识,而是衡量它解决复杂任务的能力。AgentIF-OneDay 深入探索了从 OneHour 到 OneDay 的能力跨越,揭示了主流 Agent 在工作流执行、隐式推断与迭代编辑中的真实表现。让我们共同见证,Agent 是如何通过 Scaling Context 与 Scaling Domain,从单纯的提问助手进化为真正创造经济价值的“数字员工”。
自从红杉中国 xbench 发布 ScienceQA 与 DeepSearch 以来,这两个评测集已经经历了多次迭代升级。无论是模型本身,还是围绕模型构建的 Agent 系统,都已经在这些以分钟级为单位的集中推理任务上能够稳定胜任,从最初的 human-average 水平,逐渐达到接近 PhD-level 的表现。
随着我们进一步进入 Agent 能力评测的领域,我们发现 Agent 完成短时任务与长时任务之间存在巨大的能力鸿沟。即便在单点推理和局部任务中已达到极高水平,一旦任务在突破一般人一小时可处理的复杂度,Agent 的整体完成度就会出现明显下降。
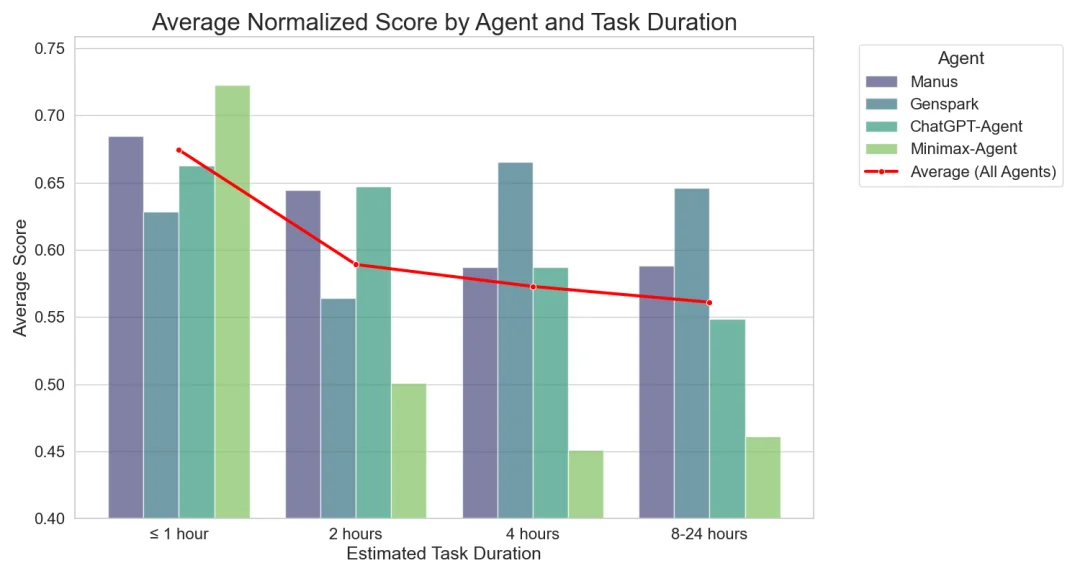
从 xbench 所坚持的理念出发,更好的评估模型和智能体在实际工作和生活中的价值。我们希望通过评测体系来观察行业技术路线的演进,预测模型能力的上限,同时也希望给业界补充一个面向 utility 和 economic value 的思考视角。我们提出一个新的视角来理解 Agent 的能力边界:任务复杂度,任务复杂度并不等同于知识点有多深奥或推理难度,而是完成一个任务所需的人类时间投入,并由此对应其潜在的经济与使用价值。
我们认为 Agent 能力的演进会沿着两条主线展开:Scaling Context 与 Scaling Domain。这两条轴线共同决定了 Agent 能够承担的任务复杂度上限,也是 Agent 系统从工具走向数字员工的发展方向。
Scaling Context 指的是完成的任务在时间维度上的延展。随着任务复杂度的提升,Agent 需要在更长的执行周期中持续维护上下文状态,跟踪中间目标与约束,并在多步骤、多工具的交互过程中保持一致性。从分钟级任务,到一天级、乃至一周级的工作量。
Scaling Domain 则指 Agent 在任务类型上扩展带来的复杂度。与高度结构化、domain 集中的任务(如 Coding 或数学推理)不同,现实世界中的工作往往横跨多个领域与语境,不同任务在目标表述、隐含约束、工具使用方式与评估标准上差异显著。Agent 能力的进一步提升,伴随着对更广的任务分布的覆盖能力。
xbench 在设计 AgentIF 评测体系时,会同时沿着 context 与 domain 两个方向推进。一方面,通过逐步拉长任务对应的人类时间尺度,从 OneHour 走向 OneDay;另一方面,通过覆盖更加多样的生活、学习与职业场景,刻画 Agent 在真实世界任务分布中的整体能力边界。
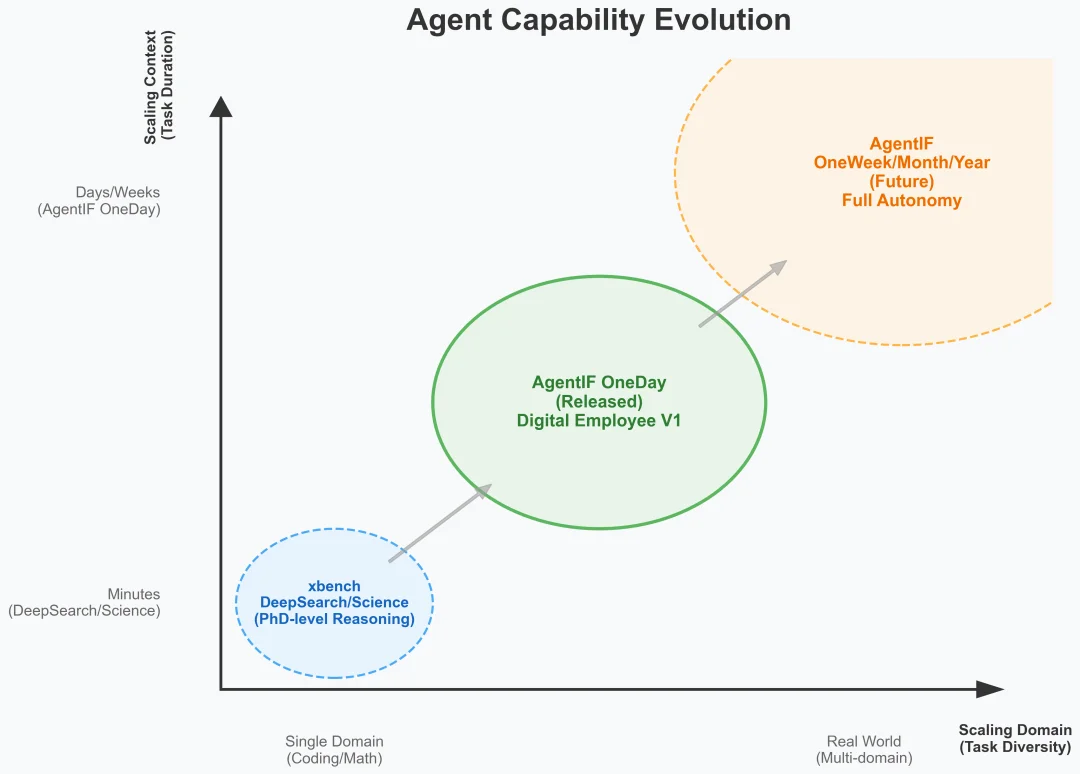
本次发布的 AgentIF-OneDay 是 xbench 在该评测系列中的一个新工作。我们以人类一天内可完成的任务复杂度作为基准,测试一个 Agent 是否具备在无需人类介入的情况下,稳定完成整套任务并交付结果的能力。尽量覆盖更 diverse 的 domain,包括生活、学习和职业场景会遇到的多种多样的任务以及多种工具。
在对大量用户真实工作日志进行分析后,我们发现尽管具体任务内容差异巨大,但日常工作在类型上呈现出高度稳定的模式。大多数普通人的一天可以按照使用场景被抽象为三个任务类型 —— 工作流执行、范例参考以及迭代式编辑。
场景一:当你知道该怎么做,但执行太繁琐
用户已知完整流程并明确给出操作步骤,Agent 只需精确执行。我们称此类任务为工作流执行(Workflow Execution)。
例题
我计划去 NeurIPS 2025,帮我规划一个好的行程方案。请你先去官网确认 NeurIPS 2025 会议的主会场位置(San Diego Convention Center, San Diego)是否准确,然后用另一个可靠来源交叉验证这个信息,确保万无一失。接下来,帮我收集基本信息,比如会议时间、地点和论文提交截止日期。还要确认完整的会议日程是否已经发布 —— 如果还没发布,请明确告诉我。最后,从纽约出发给我两套去圣地亚哥的行程方案:一个最便宜的 Cheap Plan,一个最快的 Fast Plan。
当 Agent 能够在整个流程中保持一致性、逐步完成步骤、并在长上下文中保持状态,就意味着它具备帮我把事情做完的潜力。这也是大量用户希望 Agent 能真正替代重复性劳动的原因 —— 当流程执行能力成熟时,Agent 就能自然承担原本需要人工耐心完成的碎片化任务。
场景二:当你不知道规则,只能给个参考
用户不明确知道完整的工作流或者条件约束,只提供若干案例或参考资料。我们将此定义为范例参考(Latent Instruction Inference)。
例题
我现在用的是 iPhone13 Pro Max,AT&T 套餐每月 20 美元预付费。我想换 iPhone17 Pro Max。基于附件里的购机方案和运营商优惠,帮我找出总成本最低的方式。
范例参考是人类最自然的工作方式,人们不会每次都从零写起,而是需要 Agent 从提供的示例文件中挖掘出潜在的意图,并交付同时满足用户的显示指令与附件的隐式指令;Agent 如果具备这种能力,就能真正参与内容生产、报告生成、数据整理等职业型任务,而不是停留在浅层回答问题的阶段。
场景三:当需求本身是动态的,要边做边看
人类的工作普遍呈现多轮迭代结构,在工作的开始并不知道完整解法、也没有参考示例,需要在与 Agent 多轮交互中逐渐提出新需求。Agent 也必须具备在不断变化的约束下维持上下文一致性并稳定推进任务的能力。这类任务称为迭代式编辑(Iterative Refinement)。
例题
拿着这个 SVG 平面图(venue_layout.svg)和 Excel 约束表(venue_constraints.xlsx),更新会场布局以满足所有约束条件,同时保持设计的可读性和可行走性。
我们在过去 3 个月按照这三个类型,制备了 AgentIF 第一期的题库,总共由 104 道任务组成,覆盖了工作、生活(例如游戏攻略、旅游规划)和学习。其中 62 道由文件驱动的合成任务用于补充长尾场景,覆盖 PDF、PPT、Excel、图像、代码文件在内的 15 种以上格式。本质上模拟了真实工作流程中极常见的跨格式、跨来源的模式。
每道任务都带有一套细粒度的评判标准,总计 767 个评分点,分为正向指标(如格式一致性、结构复现、步骤完整)与负向指标(如误删内容、越界生成、错误操作)。评测系统采用 LLM 作为裁判(值得一提的是 Gemini 3-pro 的出现让 rubrics 打分的准确性也提升到可用的程度),并结合网页检索、HTML 渲染、多模态比对等方法做自动校验。在这套机制下,Agent 系统的得分不仅取决于它最终是否完成任务,还包括流程是否干净、是否出现误操作、是否正确解析附件、是否能在迭代过程中保持一致性。
在 AgentIF 的测评框架下,我们对现有主流 Agent 系统进行了系统化测试,也有了一些有趣的发现:
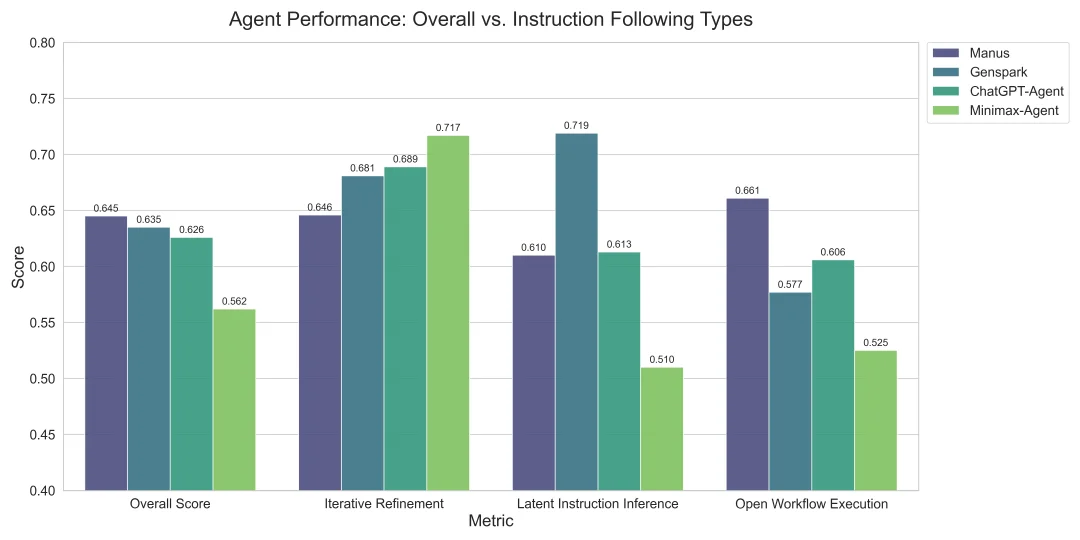
发现一:以 Overall 的完整任务成功率为标准,Manus、Genspark与 ChatGPT-Agent 都集中在 0.62–0.65 区间,构成当下能力最强的第一梯队。
这意味着和我们想象的有所差别,不论 Agent 系统是通过模型原生甚至RL训练出来的模型,还是基于 API 的工具链集成或深度的 Multi-Agent 系统,在完成一套真实任务链时,用户侧感受到的能力是比较相近的。
这一现象在一定程度上印证了模型即 Agent 的判断 —— 在底层模型能力不发生变化、且不引入 test-time scaling 的前提下,不同多智能体框架本身难以拉开数量级上的性能差异。基座模型会逐步集成 agentic 能力,下游基于 api 的 Agent 产品,在能力表现上也会体现出 agent rl 的能力。
虽然这些 Agent 系统能力非常接近,但在任务领域上与能力维度存在明显差异。
发现二:从任务领域上,任务领域上从 ChatGPT 是最优生产力工具,Manus 是最佳生活助手,Genspark 是最好学习伙伴。
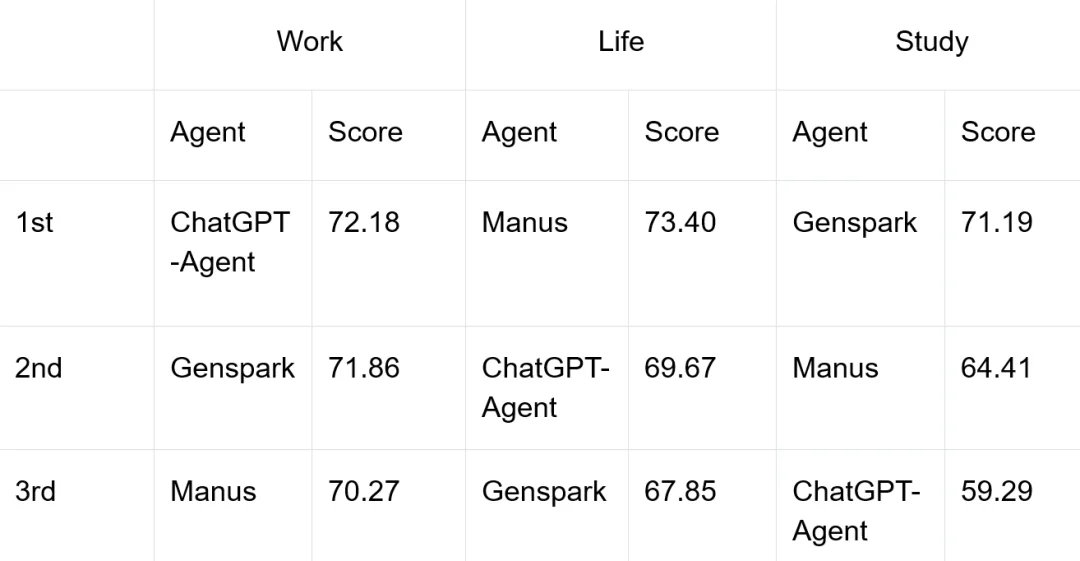
三个产品具有不同迭代方向,ChatGPT-Agent 重点关注 GDPval,聚焦专业工作场景的体验;相对来说 Manus 与 Genspark 更侧重用户反馈。不同的评测体现带来了不同的产品长项与短板。我们认为优秀的通用 Agent 应当兼顾最多样的任务,而不侧重一方。
发现三:在能力维度上,GenSpark 在隐式指令推断上表现最优,Manus 在开放工作流执行最优,MiniMax-Agent 具有最好的迭代式编辑能力。
能力维度的表现不一或来源于 Agent 框架的差异。隐式条件推断是目前 Agent 普遍最薄弱的能力项。一些任务要求 Agent 从附件中自动识别格式规则,例如从PPT 模板中抽取页眉页脚结构或引用标注方式,再迁移到新的内容生成中。我们观察到,即便是整体表现最好的系统,在这类任务中也很难做到完全正确。要么格式复现正确但覆盖不足,要么内容理解到位但无法保持结构一致。
综合来看,稳定性、文件处理链路、隐式结构理解能力,乃至跨工具的状态管理,都是决定 Agent 能否真正承担一天工作量的关键环节。AgentIF-OneDay 通过这类任务,揭示了当前 Agent 在真实使用场景中的能力边界和一些常见的失效模式,也帮助我们更清楚地看到下一阶段能力演进的方向。
随着系统能力不断提升,我们预计在 2026 年 Agent 将开始挑战 one-week 的人类工作量。围绕 one-week 的人类工作量,我们已经开始着手构建 OneWeek 的评测集。我们认为当一个 Agent 能够在一周尺度的工作量上保持稳定高质量的产出,它就具备了承担真实岗位的能力,也能够在组织内开始创造更多实际价值。
与 AgentIF-OneDay 相比,OneWeekIF 面临的挑战并不只是任务变得更长。随着时间跨度增加,评测本身的出题难度也增加很多,rubric 的设计会更加严格。一周尺度的任务往往开始呈现出明确的行业语境,无论是金融、医疗还是法律,这些高价值场景数据的获取成本也会显著上升。
当任务复杂度发展到这一阶段,依赖静态数据集和离线构建的训练与评测方式,开始显露出难以回避的局限性。也正是在这里,一个方向变得越来越自然:让 Agent 在实际运行过程中具备主动学习的能力 —— 能够在真实或半真实环境中自主收集经验,对自身行为进行评估与修正,并通过长期交互逐步形成稳定策略。
从更长期的技术演进来看,静态训练与静态评测可能都不是未来 Agent 系统的发展路径。近期关于 online learning 的讨论越来越多,更多 researcher 倾向于认为,如果模型只在既有的人类知识分布内循环,就无法突破到更高层级的智能,下一步的能力 scaling 不是训练完成的那一刻,很可能发生在模型被部署之后,通过不断的 real world RL 来获取 practical 的知识,持续学习、持续适应。
用户数据飞轮带来高可靠 Agent 的出现
一个赢得用户信任的 Agent 助理需要交付可靠结果,在长程任务中,错误累计效应会呈指数级放大。我们将长程任务 Agent 的发展类比自动驾驶的发展历程,同样是从有限路段走向通用路段,从依赖频繁人工干预走向长时无干预 FSD。该过程的实现依赖于大量用户驾驶数据的积累,用户数据可以最大化拓展场景的丰富度,并给系统带来最好的泛化性。
在长时任务的 Agents 中,我们同样可以推演,有效的数据累计可以带来高可靠 Agent 系统的出现,优先转起数据飞轮的公司将率先实现通用 Agent 的 FSD 时刻。
开源链接
Paper Link: https://github.com/xbench-ai/AgentIF-OneDay/blob/main/paper/AgentIF_OneDay_0117.pdf
website: https://xbench.org/
github: https://github.com/xbench-ai/AgentIF-OneDay
huggingface: https://huggingface.co/datasets/xbench/AgentIF-OneDay
文章来自于“特工宇宙”,作者 “宇宙编辑部”。


【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
