# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
每逢假期,必发新品。
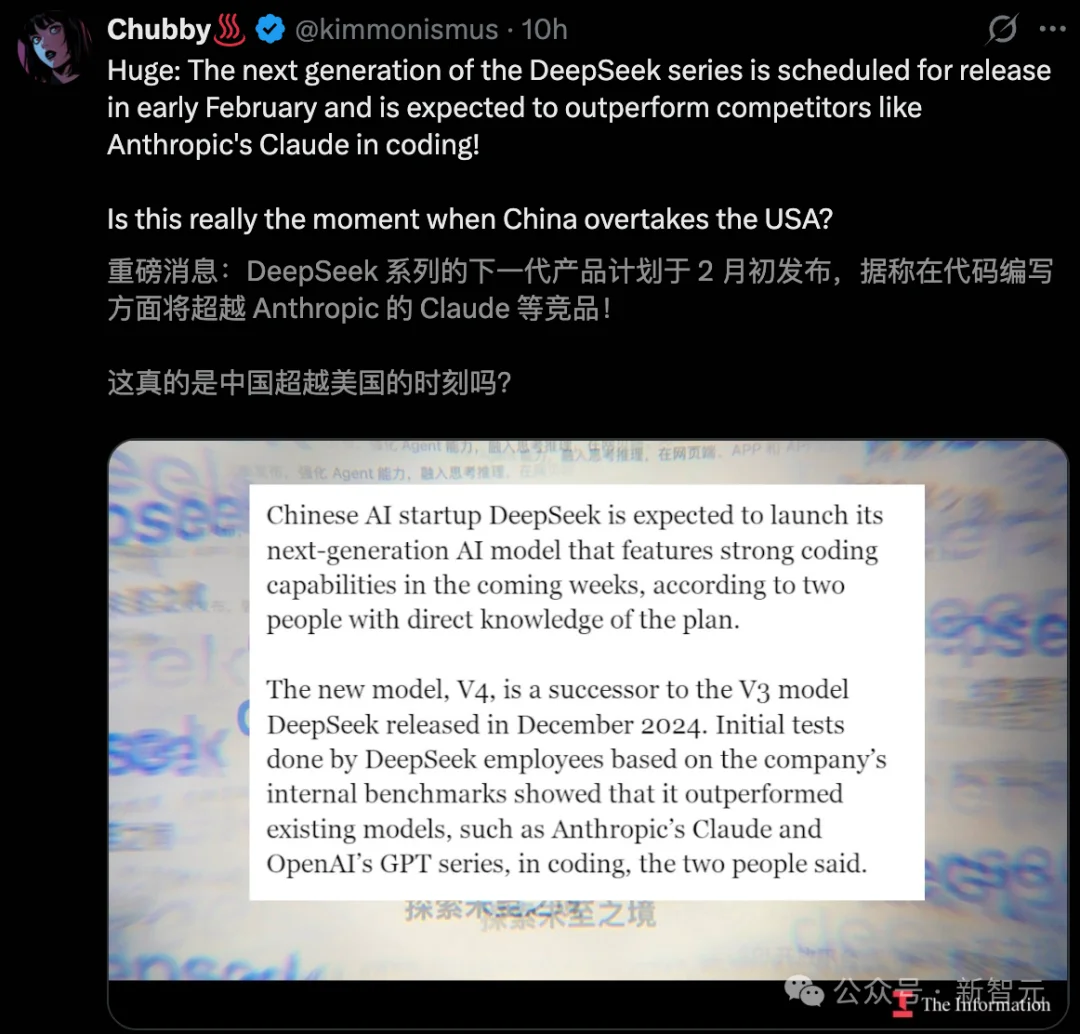
Information爆料称,DeepSeek将计划在2月中旬,也正是春节前后,正式发布下一代V4模型。

而这一次,所有目光都聚焦在同一维度上——编程能力。
目标:编程之王。
据称,DeepSeek V4编程实力可以赶超Claude、GPT系列等顶尖闭源模型。
要知道,如今Claude是全网公认的编程王者,真要击败了它,那可真不是小事儿。
毫无疑问,V4是继去年12月V3的重大迭代版,但内部测试者普遍反馈:
这不是一次常规的升级,而是一次质的跨越。
复刻R1春节核爆,全网期待值拉满
此次发布时间的选择,同样意味深长。
还记得,去年1月20日,恰逢春节前夕,DeepSeek R1重磅出世,在全网掀起了巨震。
R1的上线,最终被证明是教科书级的节奏:讨论密度、传播强度、社区反馈,全部被拉到了峰值。
或许这一次,DeepSeek希望再次复刻这种「时间窗口效应」。
回看过去一年,DeepSeek的发展轨迹,其实已经给出一条清晰的叙事线:
DeepSeek V3崭露头角,让国际开发者第一次正眼看这个来自中国的团队。
DeepSeek R1才是真正引爆的那个点。
一款开源「推理」模型,把「先思考、再作答」变成显性过程,用相对克制的训练成本,实现了复杂问题上的惊人稳定性。
这种「性价比反差」,直接击中了硅谷最敏感的那根神经。

随后,DeepSeek在国内,推出了由R1+V3加持的聊天应用,短时间内成为了现象级应用。
接下来的一年中,DeepSeek进行了多次模型版本迭代,比如V3.1、V3.2,智能体能力植入等等。
进入2025年,开源早已成为整个行业最大共识。
中国大厂与初创公司密集发布和开源,中国AI的存在感被整体抬升了一个量级,被视为全球开源AI领导力量之一。
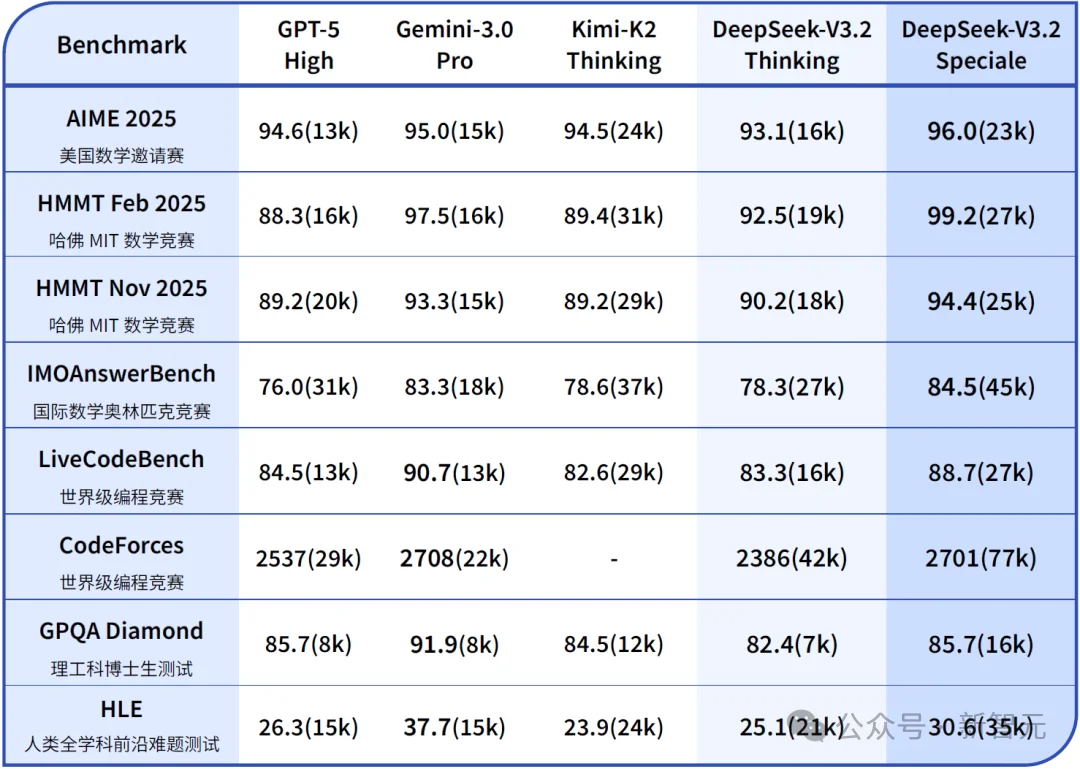
上个月,DeepSeek V3.2出世,在部分基准测试上碾压GPT-5、Gemini 3.0 Pro。
这是DeepSeek在一直未推出真正意义上的重大换代模型的情况下,实现的反超。
也正因如此,V4被赋予了比以往任何一次迭代都更高的期待。
剑指编程王座,四大突破曝光
从目前流出的信息来看,DeepSeek V4在以下四个关键方向上,实现了核心突破,或将改变游戏规则。
编程能力:剑指Claude王座
2025开年,Claude一夜之间成为公认的编程之王。无论是代码生成、调试还是重构,几乎没有对手。
但现在,这个格局可能要变了。
知情人士透露,DeepSeek内部的初步基准测试显示,V4在编程任务上的表现已经超越了目前的主流模型,包括Claude系列、GPT系列。
如果消息属实,DeepSeek将从追赶者一步跃升为领跑者——至少在编程这个AI应用最核心的赛道上。
超长上下文代码处理:工程师的终极利器
V4的另一个技术突破在于,处理和解析极长代码提示词的能力。
对于日常写几十行代码的用户来说,这可能感知不强。但对于真正在大型项目中工作的软件工程师来说,这是一个革命性的能力。
想象一下:你有一个几万行代码的项目,你需要AI理解整个代码库的上下文,然后在正确的位置插入新功能、修复bug或者进行重构。以前的模型往往会忘记之前的代码,或者在长上下文中迷失方向。
V4在这个维度上取得了技术突破,能够一次性理解更庞大的代码库上下文。
这对于企业级开发来说,是真正的生产力革命。
算法提升,不易出现衰减
据透露,V4在训练过程的各个阶段,对数据模式的理解能力也得到了提升,并且不容易出现衰减。
AI训练需要模型从海量数据集中反复学习,但学到的模式/特征可能会在多轮训练中逐渐衰减。
通常来说,拥有大量AI芯片储备的开发者可以通过增加训练轮次来缓解这一问题。
推理能力提升:更严密、更可靠
知情人士还透露了一个关键细节:用户会发现V4的输出在逻辑上更加严密和清晰。
这不是一个小改进。这意味着模型在整个训练流程中对数据模式的理解能力有了质的提升,而且更重要的是——性能没有出现退化。
在AI模型的世界里,没有退化是一个非常高的评价。很多模型在提升某些能力时,会不可避免地牺牲其他维度的表现。
V4似乎找到了一个更优的平衡点。
最近一周,CEO梁文锋参与合著的一篇论文,也透露出一些线索:
他们提出了一种全新的训练架构,在无需按比例增加芯片数量的情况下,可以Scaling更大规模的模型。

论文地址:https://arxiv.org/pdf/2512.24880
技术溯源
从V3到V4,DeepSeek做对了什么?
要理解V4可能有多强,我们需要先回顾DeepSeek过去一年的技术积淀。
MoE架构:用更少的计算做更多的事
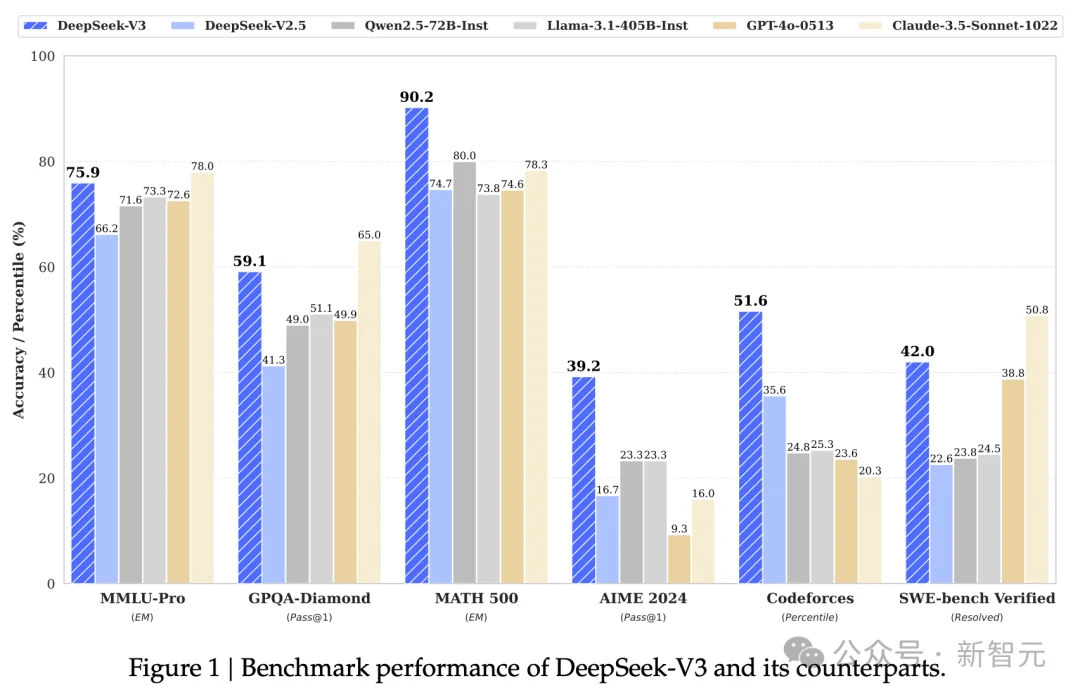
DeepSeek-V3的核心技术优势在于其创新的MoE(混合专家)架构。
V3拥有高达6710亿的总参数,但推理时每个token只激活约370亿参数。
这种稀疏激活机制让模型在保持超大规模的同时,维持了极高的推理效率。
更重要的是,DeepSeek改进了传统MoE模型的训练方法,采用「细粒度专家+通才专家」的策略——使用大量小型专家而非少数大型专家,更好地逼近连续的多维知识空间。
MLA:让推理更快、更省内存
另一个关键技术是MLA(多头潜在注意力)机制。
这项技术从V2就开始引入,通过将键(Key)和值(Value)张量压缩到低维空间,大幅减少推理时的KV缓存和内存占用。

研究表明,MLA在建模性能上优于传统的分组查询注意力(GQA),这是DeepSeek能够在有限硬件条件下实现高性能的关键。
R1强化学习经验
2025年1月发布的DeepSeek-R1是一个由强化学习驱动的推理模型,其核心技术后来被融合到了更新版的V3中。
这里有一个关键信息:V4很可能继承了R1在强化学习方面的所有优化经验。
如果说V3是「基础能力」,R1是「推理能力」,那么V4很可能是两者的完美融合——基础能力+强化学习优化+编程专项突破。
而且不要忘了刚刚发布的新论文mHC。
mHC:解决大模型训练的根本性约束
就在2025年12月31日,也就是V4爆料前不久,DeepSeek悄悄发布了一篇重磅论文:《mHC:Manifold-Constrained Hyper-Connections》(流形约束超连接)。
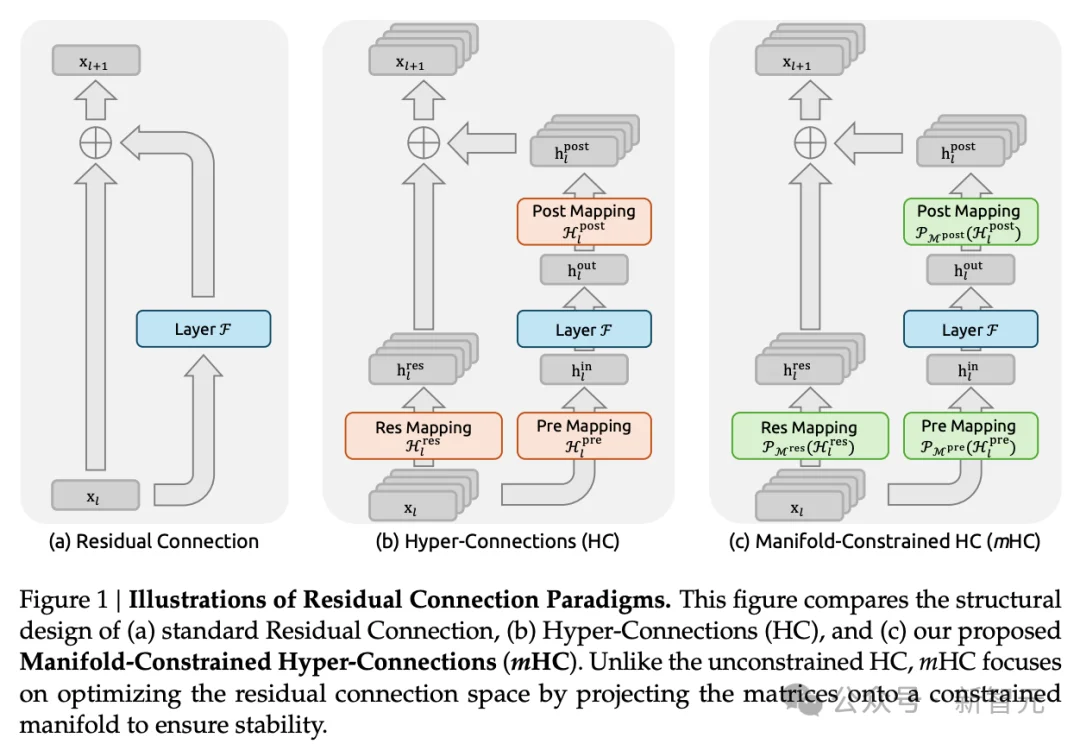
这篇论文解决了一个困扰AI行业十年之久的难题:大模型训练的不稳定性问题。
核心思想是什么?
在传统的神经网络训练中,信号在层与层之间传递时会出现放大效应——在不受约束的情况下,信号可能被放大3000倍。
这种失控的放大会导致训练崩溃、梯度爆炸等一系列问题,是阻碍大模型规模化的根本性瓶颈之一。
mHC的解决方案是:利用Sinkhorn-Knopp算法,将神经网络的连接矩阵投影到一个数学流形上,从而精确控制信号放大。结果:信号放大被压缩到仅1.6倍。
实际效果有多强?
- 在BIG-BenchHard推理基准上提升了2.1%
- 仅增加6.7%的训练开销
- 在高达270亿参数的模型上得到验证
业内专家评价:这项研究可能重塑整个行业构建基础模型的方式。它解决了一个限制大语言模型架构创新的根本性约束。
可以看出,DeepSeek一直在进行底层算法优化、数学工程优化,但不要忘了更重要的一件事:
这些优化都是在「限制之下」完成的,这也正是DeepSeek的厉害之处。
硬件限制下的算法突破
这才是真正的故事
在讨论V4时,有一个背景不能忽视:芯片出口限制。
外媒的报道特别提到,尽管面临芯片出口限制,DeepSeek依然在算法效率上取得了进展。这与其V3/R1系列的高性价比路线一致。
还记得V3的训练成本吗?约557.6万美元。
这个数字在当时震惊了整个AI行业,因为它远低于其他同级别模型——OpenAI和Google的训练成本往往是这个数字的几十倍。
DeepSeek用更少的资源做出更好的模型,这不是偶然,而是算法、框架和硬件协同优化的结果。
V4很可能延续这一路线:不拼硬件数量,而是拼算法效率。
如果V4真的在受限硬件条件下实现了超越Claude的编程能力,这将是一个极具象征意义的里程碑——
证明在AI竞赛中,聪明的算法可以弥补硬件的不足。
悬念:V4还会有哪些惊喜?
根据目前的信息,我们已经知道V4在编程能力、长上下文处理、推理严密性三个维度上有显著提升。
但DeepSeek向来有低调憋大招的传统。
以下是几个值得关注的悬念:
1.是否会有蒸馏版本?
DeepSeek-R1发布时,同时推出了一系列蒸馏版本,让更多用户可以在消费级硬件上体验强化学习推理模型。
V4是否会延续这一策略?
2.多模态能力如何?
目前的报道主要聚焦于编程能力,但V4在多模态(图像、音频等)方面是否有提升?这是一个未知数。
3.API定价会有惊喜吗?
DeepSeek一直走极致性价比路线。
如果V4的编程能力真的超越Claude,但价格只有Claude的几分之一,那将是对整个市场的巨大冲击。
4.开源策略会变吗?
V3和R1都在MIT许可下开源。
V4是否会延续这一策略?V5、V6呢,DeepSeek会一直开源下去吗?
考虑到编程领域的商业价值,这是一个值得观察的变量。
LMArena上的神秘身影:V4已经在野测了?
如果说以上都是内部消息,那么有一个线索可能暗示V4比我们想象的更接近:
有用户在LMArena(大模型竞技场)上发现了匿名模型,据说就是V4。
有人已经在LMArena上发现匿名模型,据说就是V4。

但由于模型会「撒谎」,还无法最终确认。

这是一个值得密切关注的信号。
如果The Information的报道属实,那么我们只需要再等不到一个月的时间。
届时,它是否能真正超越Claude成为编程之王?
敬请期待。
参考资料:
https://x.com/jukan05/status/2009616683607179726
https://www.theinformation.com/articles/deepseek-release-next-flagship-ai-model-strong-coding-ability?rc=lx3hes
https://www.reddit.com/r/LocalLLaMA/comments/1q88hdc/the_information_deepseek_to_release_next_flagship/
https://www.reddit.com/r/LocalLLaMA/comments/1q89g1i/deepseek_v4_coming/
https://x.com/jukan05/status/2009617025933656436?s=20
https://www.theinformation.com/articles/deepseek-release-next-flagship-ai-model-strong-coding-ability
https://economictimes.indiatimes.com/tech/artificial-intelligence/deepseek-to-launch-new-ai-model-focused-on-coding-in-february-report/articleshow/126438150.cms?from=mdr
文章来自于微信公众号 “新智元”,作者 “新智元”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
