# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
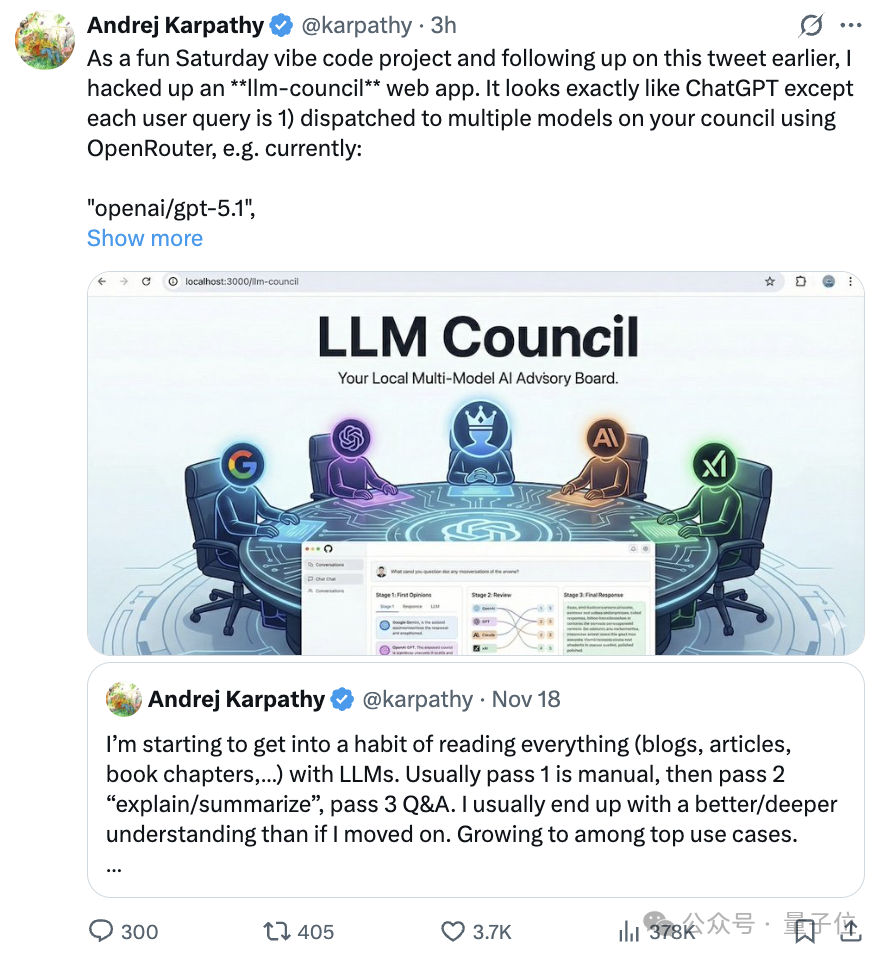
卡帕西又来发布趣味编程项目了~
这次直接整了一个“大模型议会”(LLM Council)web app。
界面看起来和ChatGPT的聊天形式别无二致,但实际上当用户输入问题后,系统会通过OpenRouter调起多个大模型开会商议。
有意思的是,它们不仅会一起答题,而且还会互相评分、排序,最终将由主席模型给出一个统一答案。
卡帕西刚把这个应用的安装部署教程分享出来,就立马被不少网友码住:
更有甚者表示,或许以后模型自己评价模型本身就能变成一种新的“自动benchmark”:

畅销书《Python机器学习》作者也很看好这个思路:
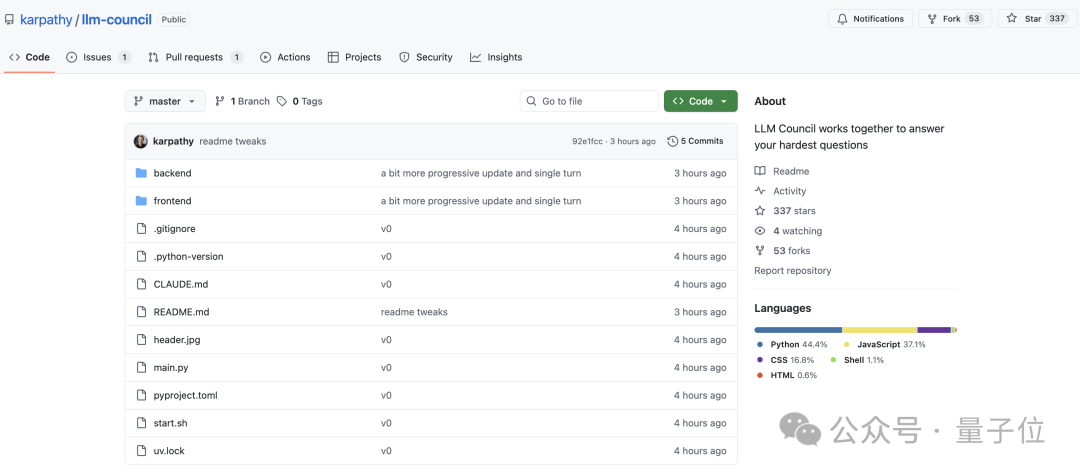
具体来说,卡帕西的这个LLM议会系统,主要可分为三步流程:
Step 1:让多个模型同时回答一个问题。
首先使用中间层OpenRouter同时调用多个大模型,包括:
然后在同一问题下逐个收集它们的回复,并以标签视图的形式展示,以便用户进行检查。
Step 2:所有模型进行匿名互评。
这时,每个LLM都会收到其他LLM的回复。
为避免偏袒,对它们的身份都做了匿名化处理。
然后要求模型根据准确性和洞察力对其他模型的回答质量进行评估,需要给出评分和详细理由。

Step 3:主席模型汇总最终回答。
LLM委员会将指定一名主席,将所有模型的回复汇总,并形成一个最终的答案,再转交给用户。
于是通过这个过程,就能直接对比不同模型,在处理同一个问题时的风格差异,而且能够直观地看到模型之间互相评价的过程。
这套系统,其实是延续了卡帕西最近分享的用LLM分阶段深度阅读的项目。
PS:在GitHub上也收获了1.8k Stars。

该项目将传统的阅读流程重塑为与LLM协作的流程,通常阅读一篇文章内容也分为三个阶段:
1、先人工自己通读一次,获得整体感知和直觉理解。
2、然后将内容交给大模型处理,让它理解重难点、提取结构、总结内容等。
3、对文章细节进行深度追问,例如“为什么作者这里会这样写?”
最终就是将写作对象从人类读者转变为LLM读者,让LLM作为中介理解内容,再个性化翻译给不同的读者听。
当将大模型议会融入其中后,大模型们的商议结果也很有意思。
卡帕西发现,大模型一致认为最强、最有洞见的答案来自GPT-5.1,而Claude被公认为最弱,Gemini 3和Grok-4则排名位于中间。

但显然他对这个答案并不认同,在卡帕西的个人主观评价中,GPT-5.1内容丰富但是结构不够紧凑;Gemini 3答案更简洁凝练、信息处理得更好;而Claude答案过于简略。
此外,令人出乎意料的是,模型几乎很少出现明显的偏见,它们通常会愿意承认自己的答案不如另一个模型好。
总的来说,卡帕西认为虽然模型内部自评不一定与人类主观一致,但类似的多模型集成或许将成为一个巨大的可探索空间,甚至可能成为未来LLM产品的一个突破点。
参考链接:
[1]https://x.com/karpathy/status/1992381094667411768?s=20
[2]https://github.com/karpathy/llm-council
[3]https://x.com/karpathy/status/1990577951671509438
文章来自于“量子位”,作者 “鹭羽”。


