# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
核心速递:
这个国庆节,AI 圈主打一个谁都不许放假。
前有 Deepseek-V3.2 开源,后有 Claude Sonnet 4.5 突袭,头部 AI 公司都挤在节前这两天秀肌肉。
在这场混战里,智谱也放出了新模型 GLM-4.6,迄今智谱最强的 Coding 模型。
两个月前,我还在 深度评测智谱 GLM-4.5中大力推荐 GLM。
认为综合质量、成本、速度,GLM 毫无疑问是当时最值得使用的国产 Coding 模型。智谱也凭此在 Openrouter 上,模型调用收入一跃超过其他国产模型收入之和。
而这次 GLM-4.6,则带来了更多提升:
本文将从模型信息、实测效果(直接对比 Claude 4.5、Deepseek V3.2)、价格、综合结论等方面,给到有价值的实测参考信息。
智谱这次只发 1 款模型:
GLM-4.6,大杯,355B-A32B。
在真实编程、上下文长度、token 效率、推理能力、Agent 任务等维度,全方位提升。
这是我总结的官方介绍一图流,方便你快速了解新特性:
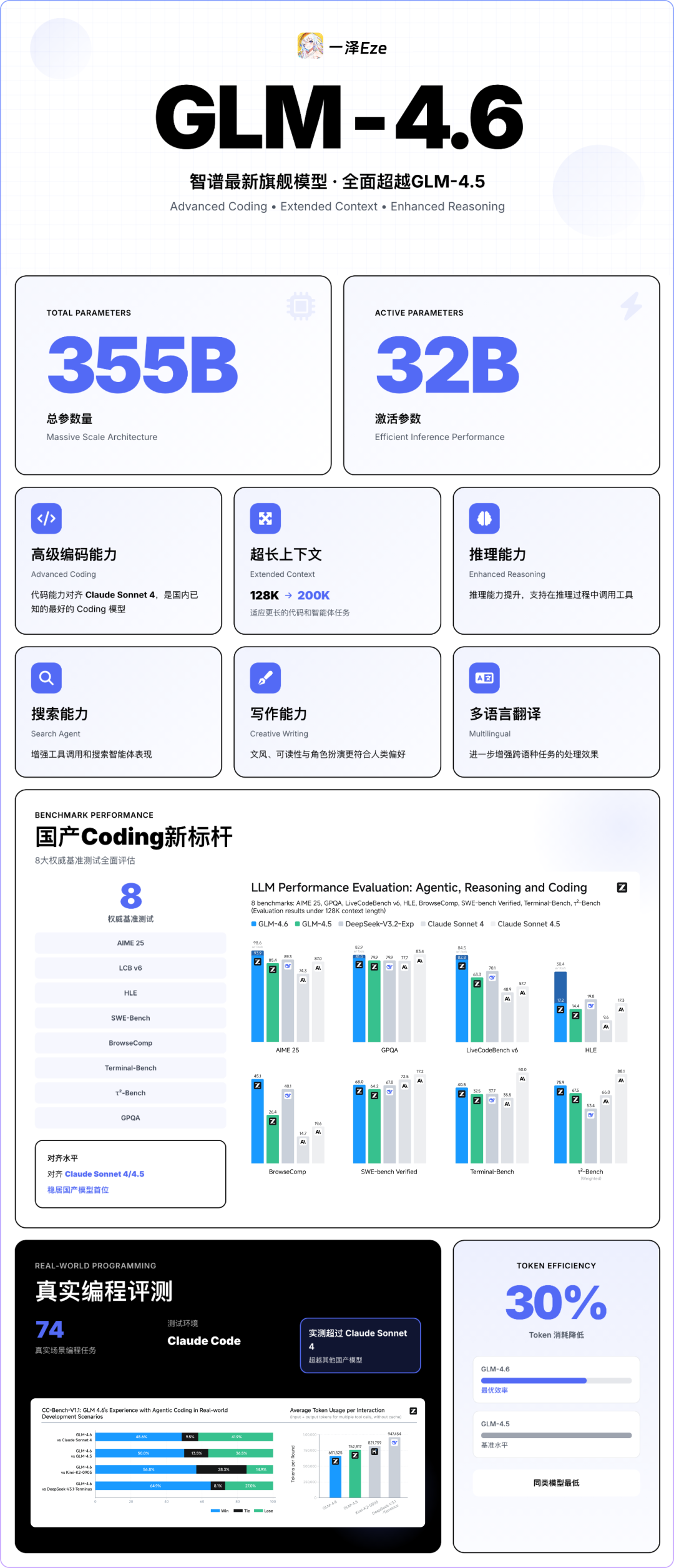
提炼这次升级的重点:
所以,真正的问题来了:
作为上季度的最强国产 Coding 模型,GLM-4.6 在遇到 Claude Sonnet 4.5、DeepSeek V3.2 扎堆发布的情况,
是被迫原地踏步,还是再次超出预期?
每次新模型的发布,用户在乎的其实是相对的结论:
1.新模型,在目标任务中,排全球/国内模型第几?
2.和当前在用的模型相比,有没有必要迁移?
以下是 GLM-4.6 和最新 Claude Sonnet 4.5、GPT-5 Codex、DeepSeek V3.2,
以及上代但足够优秀的 Gemini 2.5 Pro、Claude Sonnet 4 等 真实对比与结论。
也选了众多测试中,几个有代表性、方便观测对比差距的 Case,与你们分享:
熟悉我的读者,应该知道我的经典 Benchmark:
让模型阅读长文后,自行提炼关键内容,总结生成一图流网页。
非常经典的任务设计,同时考验模型的长上下文任务表现、推理能力,以及前端 Coding 的质量与设计审美。
模型水平提升很快,这次也增加了任务难度,让 AI 直接挑战论文的提炼,生成总结一图流 html。
我测试用的是 OpenAI 最近发布的 Paper:《How people are using ChatGPT》。
PDF 共 64 页,9.3 MB,需要分析提炼的内容量相当大。(其他模型统一用 Cherry Studio 调用 API 进行测试)
这是两次不同的对比结果,一次与最新模型比,一次与前代 & 自身比:
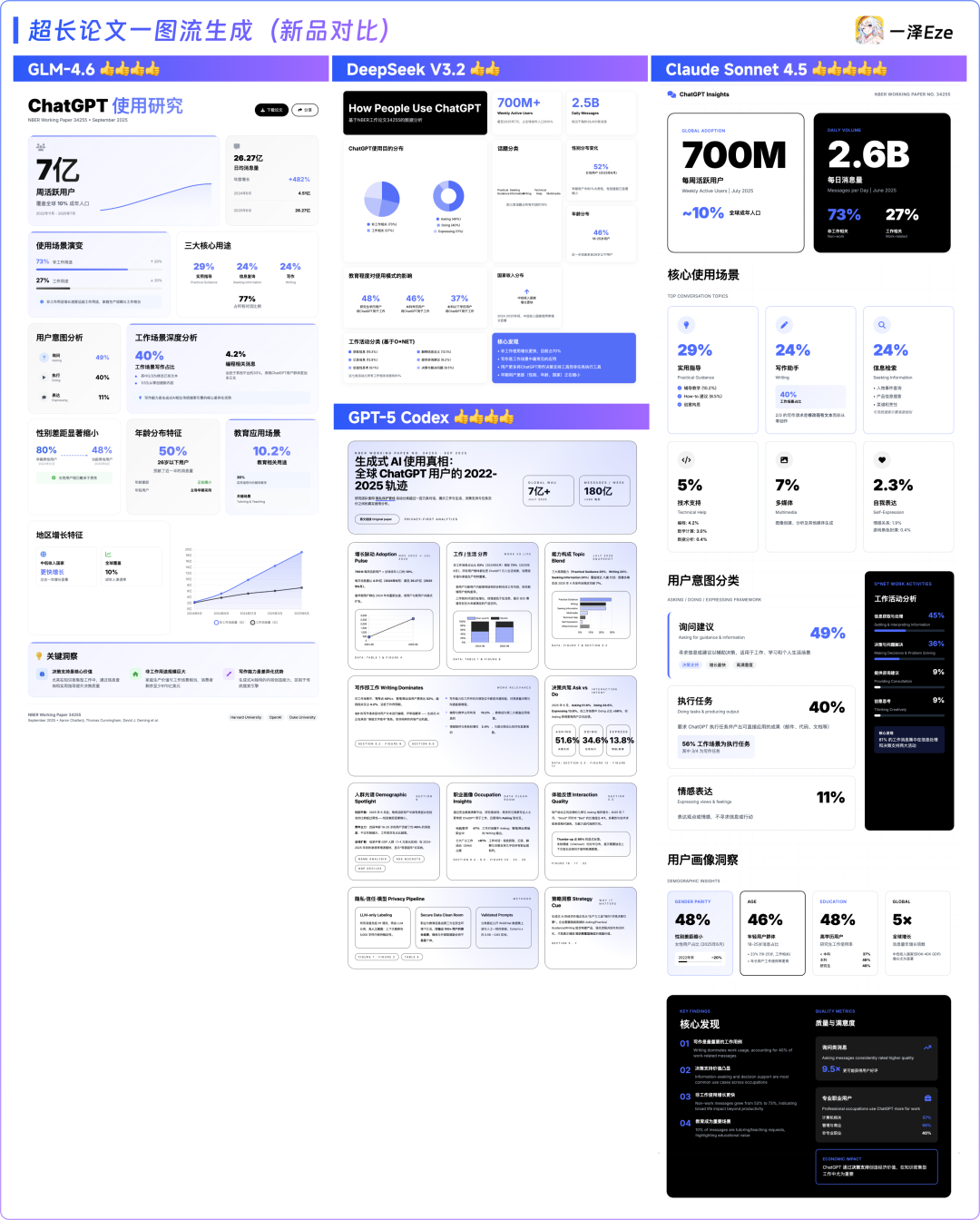
1)GLM-4.6 与新模型对比:DeepSeek V3.2、Claude Sonnet 4.5、GPT-5 Codex
2)GLM-4.6 与前代对比:GLM-4.5、Claude Sonnet 4、Gemini 2.5 Pro、Qwen3-Max
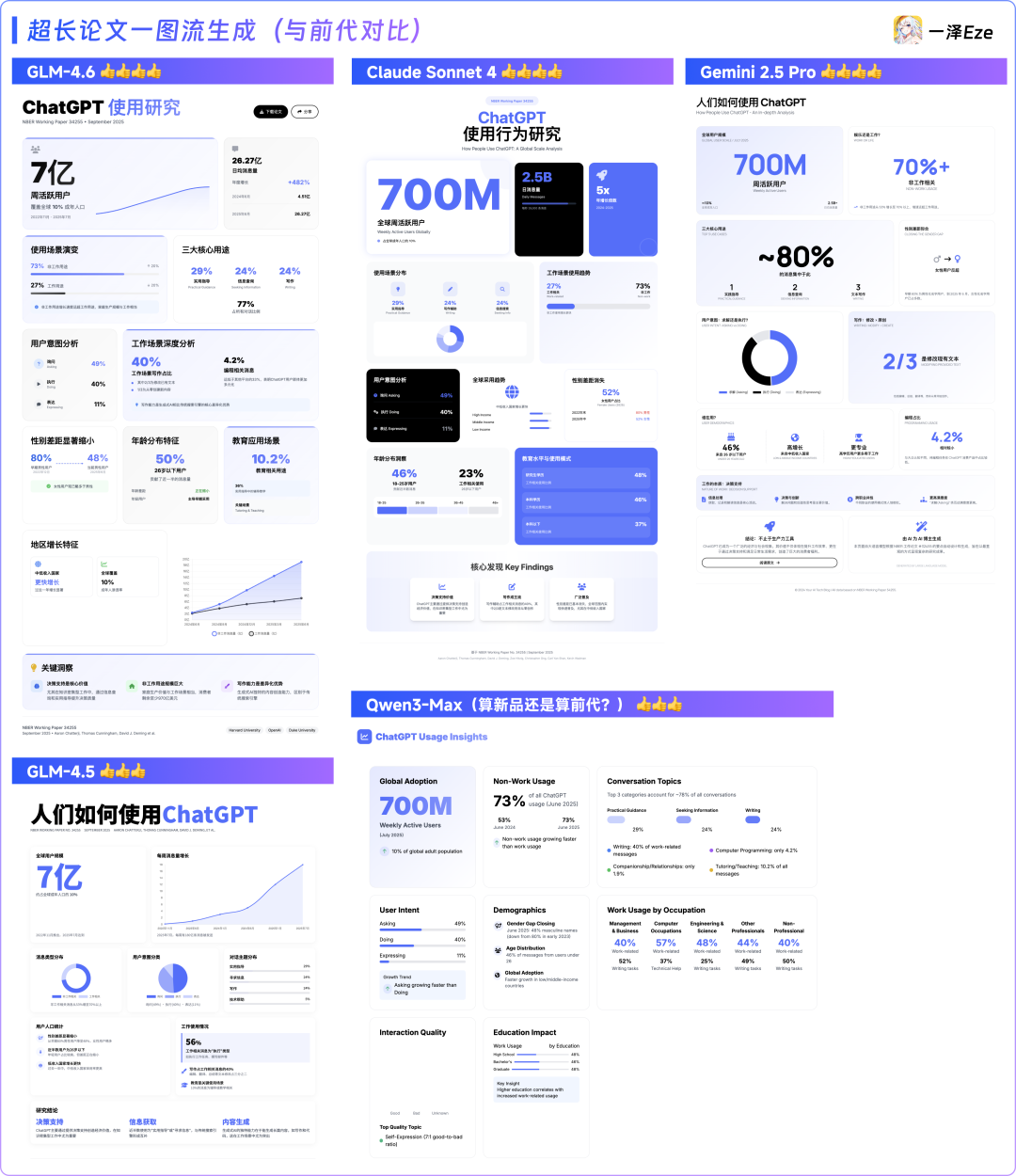
整体来看,不难发现这个趋势:
这一波 9 月底的 Coding 模型,在推理、上下文注意力、编程稳定性与前端审美,都有了新一轮明显的进步。
本轮测试结论:GLM-4.6 没全守住,但又做得效果非常好。
面对 Claude 4.5 全球最新的顶级模型,GLM-4.6 在设计与长文理解上确实还差一口气。
但它依旧巩固了国产 Coding 模型的一流水准,较自身与前代国产模型有明显进步,甚至与 GPT-5 Codex 相比也互有长处。
考虑到它的高性价比,第一轮测试中,GLM-4.6 在自己的价格区间内,继续做到了最好。
继续提升 Coding 任务难度:
我让 AI Deep Research 了24 年国庆节全国旅游数据,并把结果报告给到了 AI,
让其根据数据详情,自行设计一个静态数据大屏。
任务 Prompt 如下:
这轮拉了 Claude Sonnet 4.5、GLM-4.5、Claude Sonnet 4、DeepSeek V3.2 - reasoning、Gemini 2.5 Pro ,与 GLM-4.6 进行对比。
在没有任何设计风格 Prompt 引导下,各个模型在 1 轮任务 + 1 轮优化后,各个模型生成的前端如图所示:
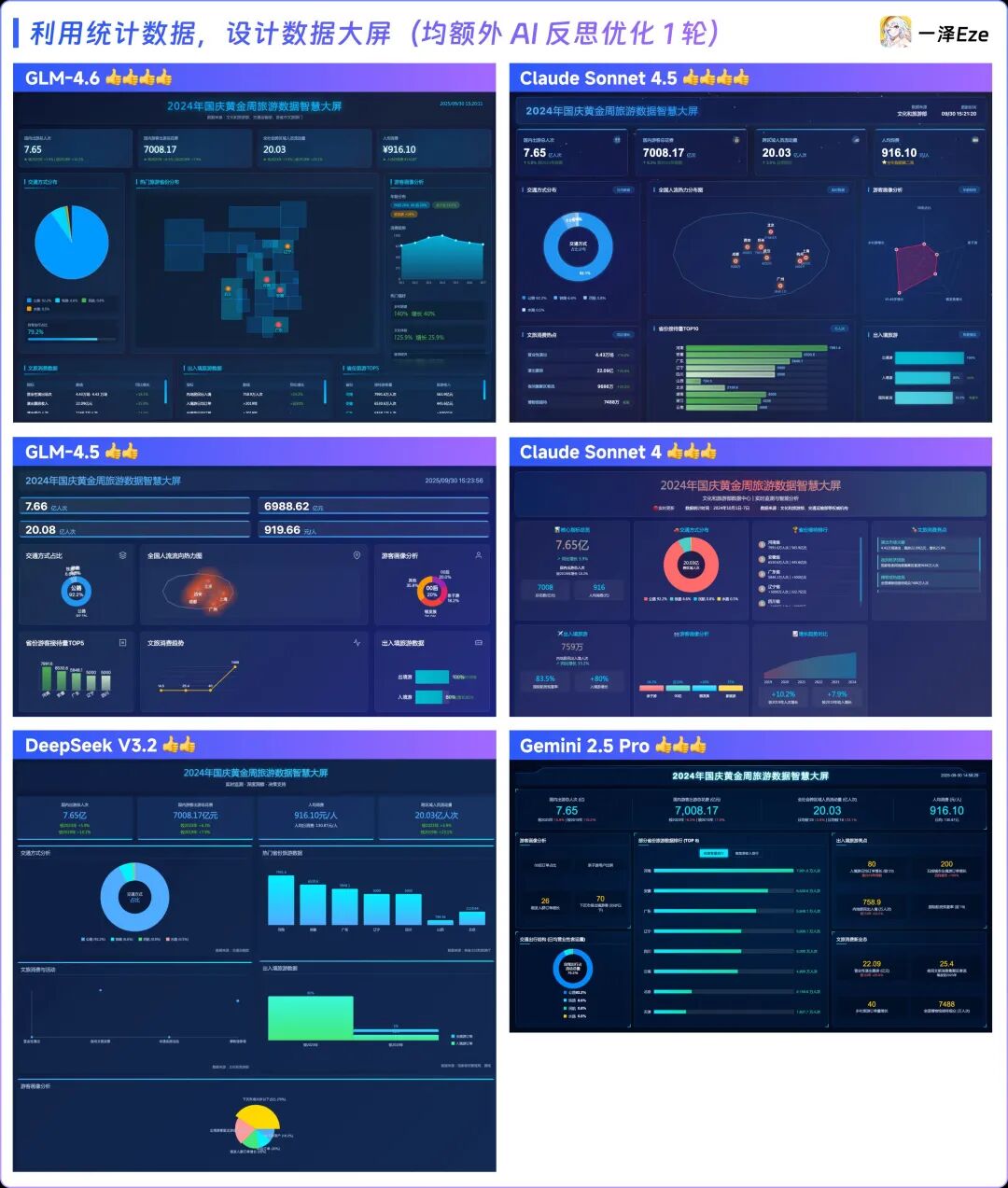
结果令人意外,本轮测试排名:
这个结果,说实话,完全超出了我的预料,我本以为这会是 Claude 4.5 的主场,但 GLM-4.6 给足了惊喜:
也难怪朋友 #赛博禅心 @大聪明 刚刚发布的公众号排版 Agent,其自动排版的底模也选择了 GLM-4.6。

一次胜出是巧合,那两次、三次呢?
可能不得不承认,在需要结合编程与审美的 Coding Agent 任务上,GLM-4.6 可能已经找到了自己的甜点区。
聊完了性能,我们再聊点更实在的——价格。
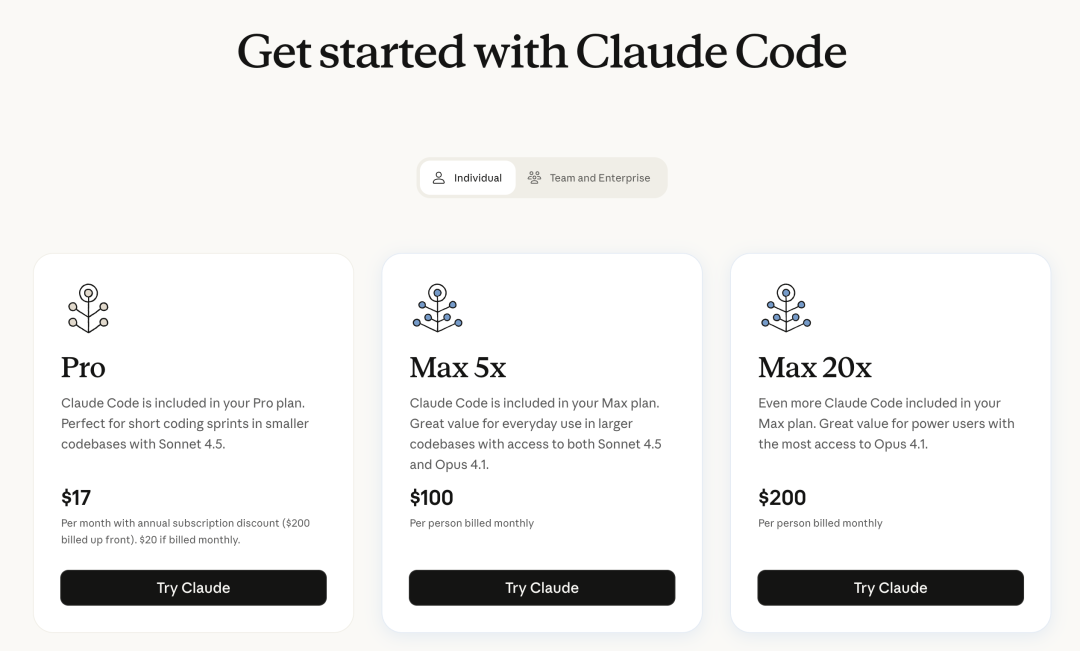
Claude 一向很强,但是限于其高昂的计费价格($3/M input tokens),以及高达 $100~$200 刀,动辄就对国内封号的 Claude Code 套餐,还是让不少开发者没法下决心去付费。
而 GLM-4.6 发布后,除了常规按量付费定价如下外:
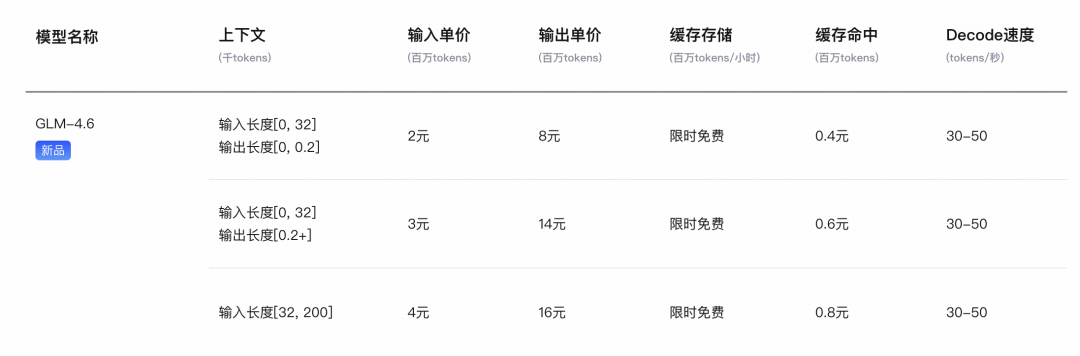
智谱也自动升级了 GLM-4.5 时期推出的 GLM Coding Plan 套餐:

结合此前的测试结果,你或许可以把 GLM-4.6 视作……
⬇️
大概只用 Claude 1/7 的价格,换来真实开发场景中,超越昨天发布的 DeepSeek-V3.2,比肩 Claude Sonnet 4,甚至一些场景还能不弱于 Claude 4.5 的开发体验?
总之,数据不会撒谎:
自打 GLM-4.5 开放 Coding Plan 以来,智谱 MaaS 开放平台的 API 商业化,已实现 10 倍以上的增长。
开发者们,早已用真金白银,进行了投票。
写到这里,我对 GLM-4.6 的密集测试,总算暂告一段落。
说实话根本没想到在国庆节前最后 2 天,会迎来如此密集的模型发布。(本来都要去度假了……)
一方面,是调用成本降低 50% 的 DeepSeek V3.2,
一方面,Anthropic 家发布 Claude Sonnet 4.5 模型,再次刷新 AI Coding 能力天花板。
在这波 9 月底的模型扎堆迭代的“神仙打架”中,再回头看 GLM-4.6:
这些实测结果,让最后的结论变得不言而喻:
结合性能以及越来越值的 GLM Coding Plan ,GLM-4.6 守住了它「国产最好用 Coding 模型」称号。
GLM-4.6 可能还无法在每一个维度上都比肩像 Claude 4.5 这样“天花板”级别的存在,但它用一个极具诚意的价格,为你提供了一个在绝大多数场景下都“足够好用”,甚至时常有惊喜的 Coding 模型选择。
还是那句话,如果你有 Coding、Agent 任务需求,并且在乎“用得爽”和“用得起”,GLM-4.6 绝对值得你花时间亲自上手试试。
我也很期待你的实测反应与反馈。
希望一泽的文章对你有所启发。
文章来自于微信公众号 “一泽Eze”,作者 “一泽Eze”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
