# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天下午,DeepSeek 官方正式发布 DeepSeek-V3.1。

相比于前天只在用户群里通知,今天新增了模型升级点、榜单成绩、model card,huggingface 上现在也可以下载模型文件了。
模型传送门:
https://huggingface.co/deepseek-ai/DeepSeek-V3.1
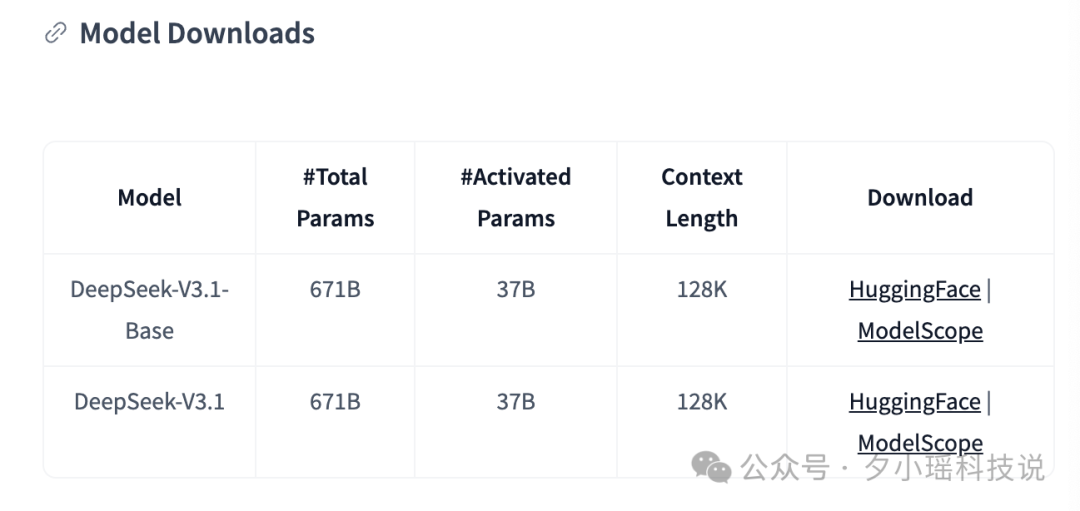
一共两个模型,分别是 V3.1 和 V3.1 base。两个模型结构完全一致,V3.1 的 Base 模型在 V3 的基础上重新做了外扩训练,一共增加训练了 840B tokens。
从 Deepseek 官方的标题:“迈向 Agent 时代的第一步”就可以看出来,DeepSeek 把 V3.1 的主轴放在 【128K 长上下文 + 混合思考范式 + 更强工具/多步执行】,是对齐 2025 年“从聊天到能干活的 Agent”这条主赛道。
一抓长上下文;二强推 agentic 能力。
先来说长上下文能力。
V3.1 从原来 32K 拓展到 128K 上下文长度,和 Kimi K2 、智谱 GLM-4.5 都在 128K 档位。GPT5 公布的最大上下文是 400K, 而 Claude Opus 4.1 和 MiniMax M1 都是 1M 的窗口,谁还低于 128K 都不好意思拿出来说了吧。
毕竟真实任务常涉及长文档、仓库代码、日志/网页轨迹,长上下文是这一切的物理层,这才是真的迈向 Agent 的第一步。
其实是 agentic 能力。
现在国内外所有搞大模型的厂商都把工具调用、多步执行摆在了最显眼的位置,DeepSeek 必须在这条线上与之对齐,还给出了量化指标。
在官方测评中,V3.1 选择在编程与搜索两个领域证明:
编程:
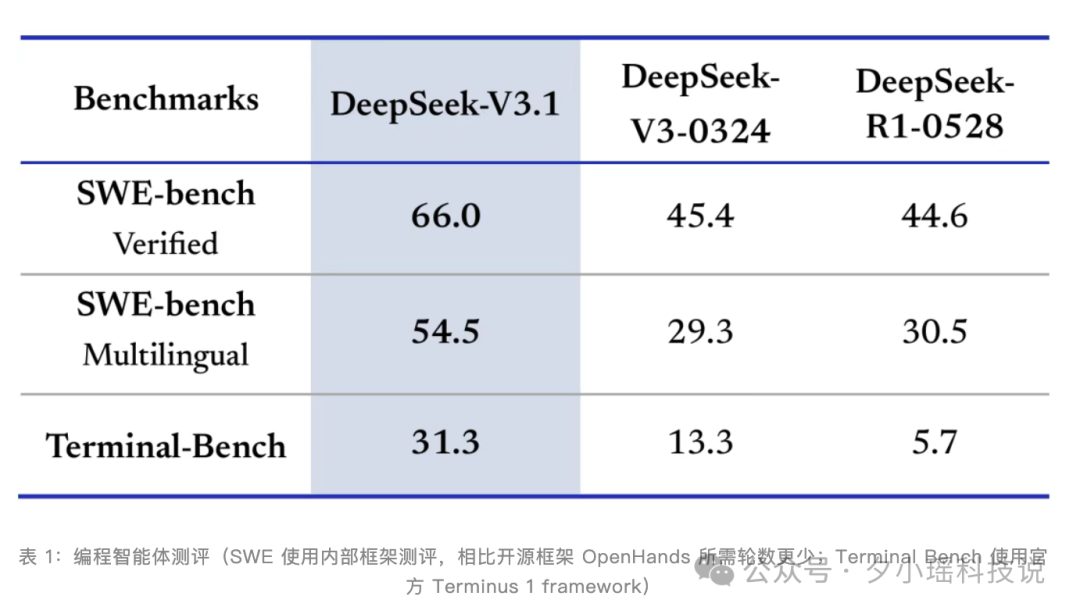
为了让大家更方便感知横向的水平,我列了一个表格,分别有当前最热的几个模型的分数。
前两名还是 GPT-5 与 Claude Opus 4.1,kimi K2 紧随其后。V3.1 从原来落后的成绩拉到了同一个区间了,最起码证明成绩没有掉队。
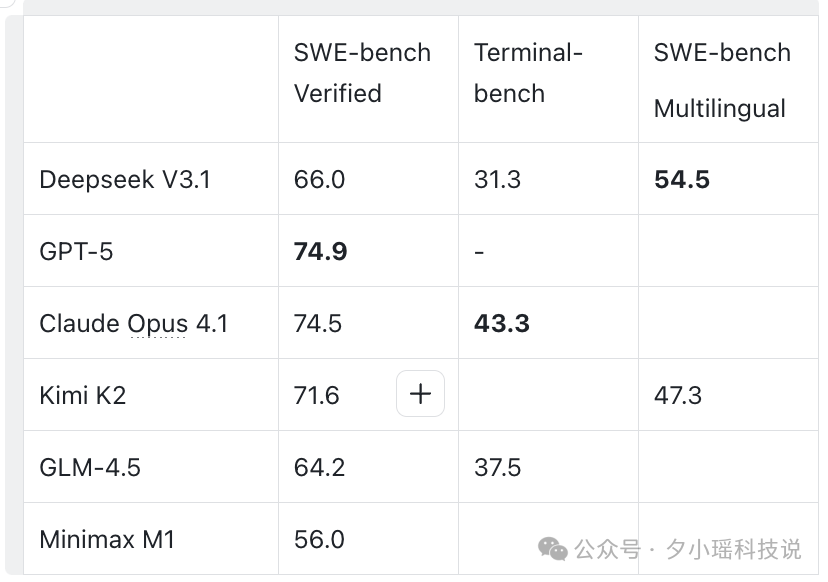
最近“搜索智能体评测”成了热点,用户不再满足离线跑分,开始盯真实互联网任务能不能完成。因为搜索任务实时变动、跨站点、多约束,更能拉开差距。
128K~1M 的上下文和函数调用/浏览器工具的配合,让这个任务成为可能。
V3.1 的搜索智能体表现:
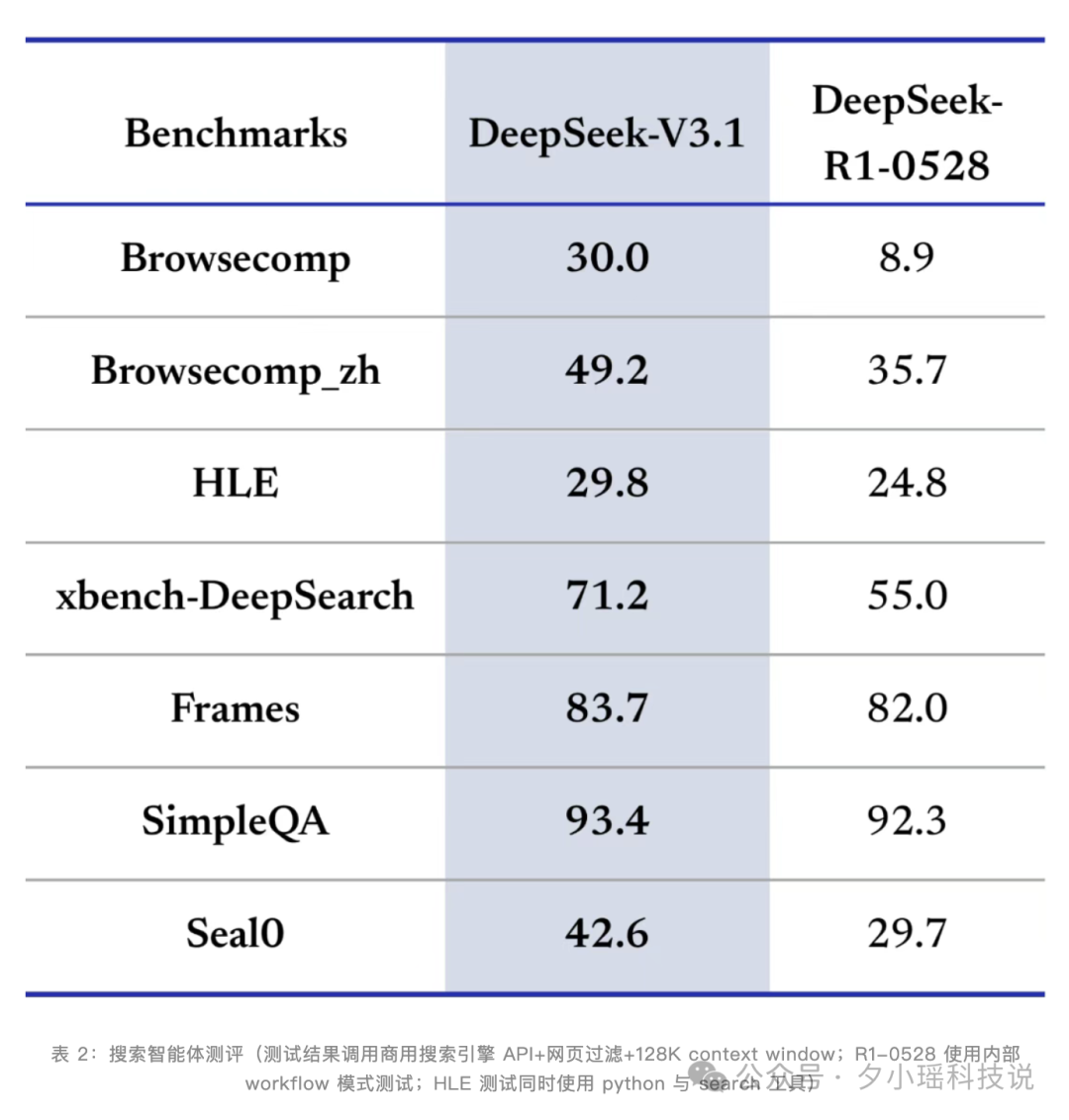
在开放网络检索难题集 BrowseComp 上,V3.1(Thinking)给出 30.0% 的准确率,而 R1-0528 为 8.9%;同时提供了中文变体 BrowseComp_zh 49.2%。
除了官网、APP,DeepSeek API 也已同步完成了升级:
API 的上下文窗口均扩展至 128K,可以通过调用 deepseek-chat 接口使用标准模式,通过 deepseek-reasoner 接口启用专为复杂任务设计的深度思考模式。
此外,为了提升 API 调用的可靠性,API Beta 接口还引入了 strict 模式的函数调用,能够强制要求输出结果严格匹配预设的 schema。
官方文档:https://api-docs.deepseek.com/zh-cn/guides/function_calling
Deepseek 3.1 刚出来,我们就进行了 V3.1 的第一波评测。明显感觉到速度快了不少,没有之前那么啰嗦。官方也放出了证据,V3.1 相比 R1,推理过程的 Token 消耗显著降低了 20%-50%。
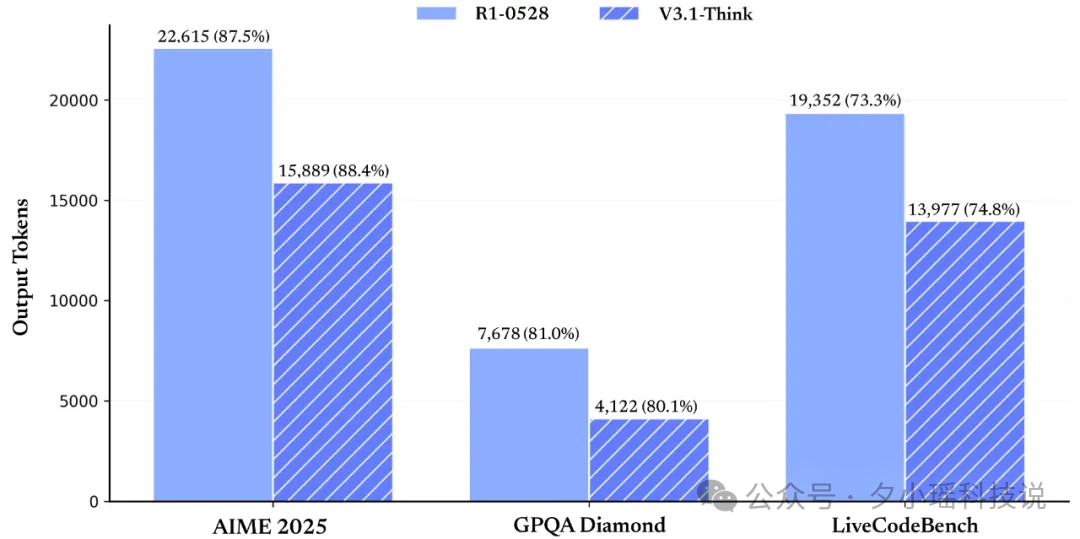
在各项评测指标得分基本持平的情况下(AIME 2025: 87.5/88.4, GPQA: 81/80.1, liveCodeBench: 73.3/74.8),R1-0528 与 V3.1-Think 的 token 消耗量对比图
更令人惊喜的是:
DeepSeek 这次增加了对 Anthropic API 格式的支持,终于可以将 DeepSeek-V3.1 的能力接入 Claude Code 了!
我立马上手跑了下,此处放上保姆教程,跟着步骤你也原生接入 Claude Code(不再需要曲线救国了)。
第一步:先安装 Claude Code
在终端执行:
**npm install -g @anthropic-ai/claude-code**
在这一步,确保你的终端中的网络走的是代理网络和端口。在终端里设置网络代理,最常用和标准的方法就是配置环境变量。临时设置的办法是,打开 terminal,输入一下命令:
export http_proxy="http://127.0.0.1:7890"
export https_proxy="http://127.0.0.1:7890"
将 IP 和 port 替换成您自己的代理服务器地址和端口。
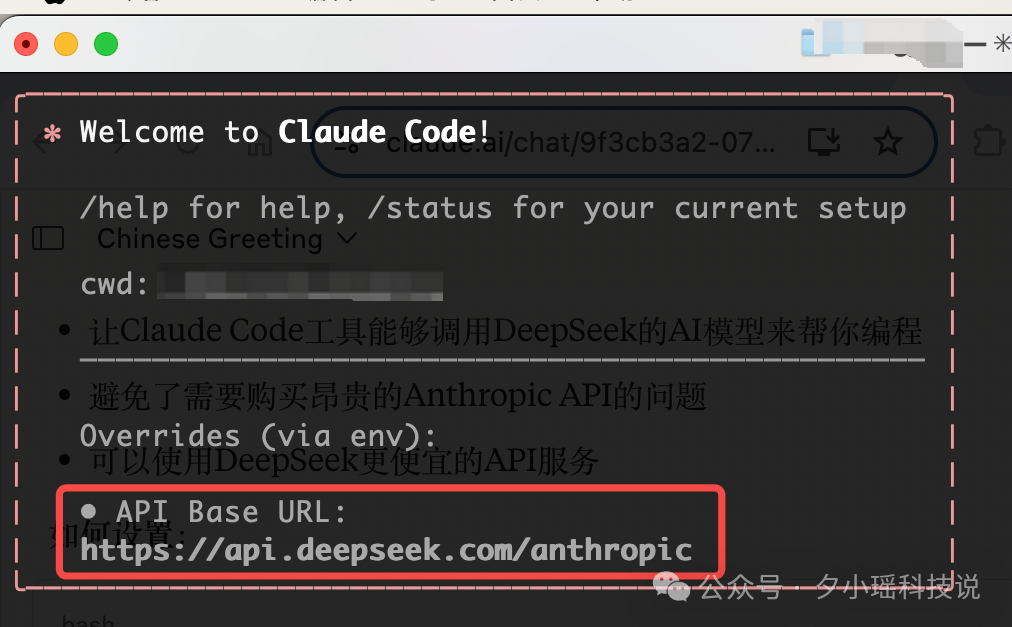
第二步:配置环境变量,让 Claude Code 能够使用 DeepSeek 的 API 而不是 Anthropic 的 API。
这里需要使用你的 DeepSeek API 密钥进行认证&指定使用 DeepSeek 的 chat 模型。
_# 临时设置(当前终端会话有效)_
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_AUTH_TOKEN=你的DEEPSEEK_API_KEY
export ANTHROPIC_MODEL=deepseek-chat
export ANTHROPIC_SMALL_FAST_MODEL=deepseek-chat
第三步:在你的项目目录下,执行 claude 命令,即可开始使用了。
出现红框,就说明你配置成功啦 🎉
Claude Code 中的 V3.1 测试了下昨天推文中的样例,提示词如下:
帮我开发一个基于 Web Audio API 的网页播放器,我希望你实时分析音乐频谱和节拍,配合驱动一个动态生成的、响应音乐情感的抽象视觉背景

中间我全部接受让它自动执行到最后一步,本地服务可以直接试用。
从此之后,可以在 Claude Code 里随便霍霍用 Deepseek 了。
说实话,在昨天的 DeepSeek V3.1 网页版本更新的测评,确实让我感到一丝落差,模型表现出的些许“人格分裂”和不稳定性。
但是,这并不意味着这次的更新是无效更新:
第一,社区的期望值实在是太高了。
DeepSeek 如今已经是“AI 圈第一大网红”,任何一点风吹草动都会被大家拿着放大镜来审视。这种高关注度,无形中压缩了其“试错”的空间。
第二,这只是一个“.1”的迭代版本。
V3.1 的核心定位其实只是一次小步快跑的“尝试”,对“混合推理”架构的探索,而非准备颠覆一切的 V4 或者 R2。
V3.1 发布后,社区里很多人都在讨论一个问题:混合推理模型这条路,到底能不能走通?
从今年年初开始,这条路线一度看似前景大好:从 2 月 25 日 Claude 3.7 Sonnet 率先入场,到 4 月 17 日 Gemini 2.5 Flash 紧随其后,再到 4 月 29 日 Qwen3 系列作为首个开源模型加入。
虽然说是一次很大的架构上的更新,但是后续确实没有什么水花了。。
而且,作为开源先锋的 Qwen3,其最新的版本却依然保留了独立拆分的模式。并且在那之后,其他主流厂商似乎也放缓了在混合推理上的跟进脚步。
最后,Deepseek 调价了,而且是涨价了。
取消了之前夜间折扣 ,从 2025 年 9 月 6 日凌晨开始,执行新价格。
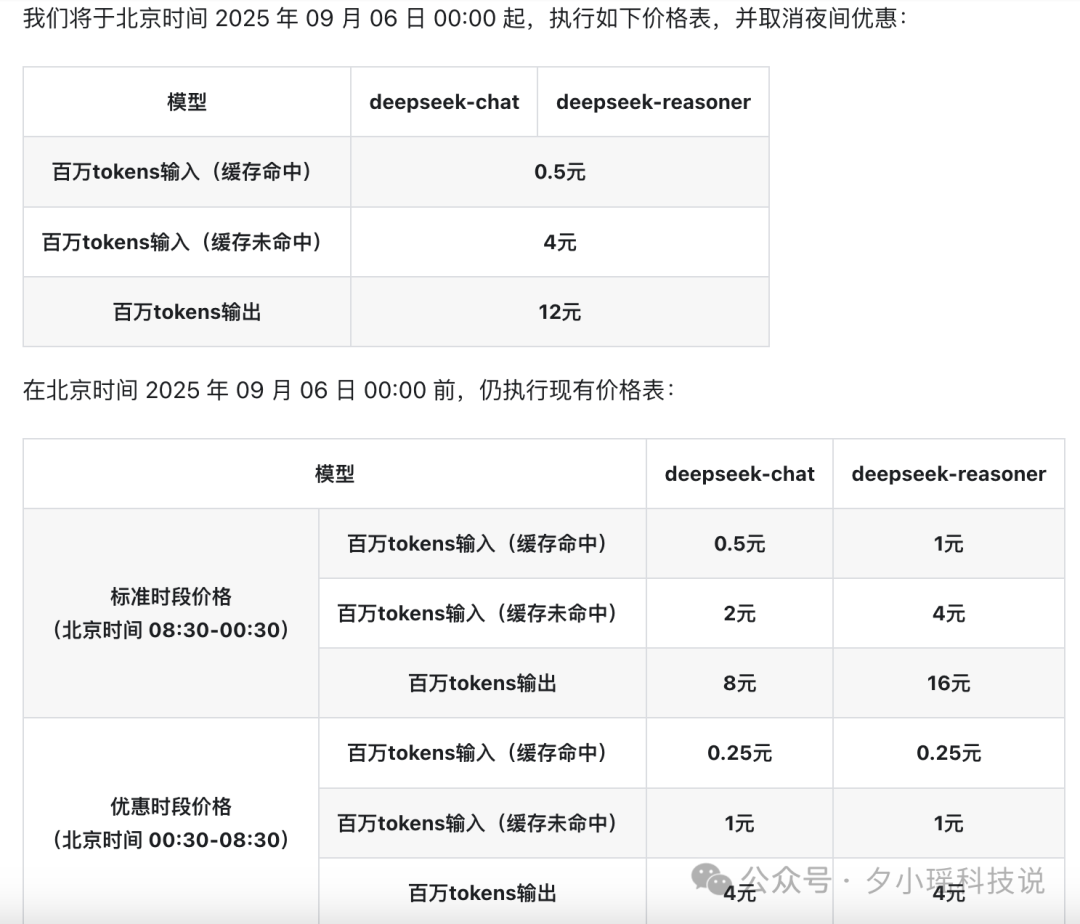
不过相比其他主流模型,依旧有优势。
文章来自于微信公众号“夕小瑶科技说”,作者是“兔子,小鹿”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
