# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
中国自研世界模型Matrix-3D只需单张图就能生成可自由探索的3D世界,不仅效果对标李飞飞的World Labs,而且还能实现更大范围的探索空间,率先进入AI理解世界的前沿领域。
一花一世界,一叶一菩提。
千百年来,人类只能凭想象勾勒图画之外的世界,梦境与现实之间始终隔着一层不可触及的纱幕。
而今天,当AI的力量被无限延伸,这层纱幕终于被揭开——
Matrix-3D,一个真正从「一图生万境」的世界模型!
它不仅是昆仑万维第一款,也是第一首款全自研世界模型「Matrix-Zero」的全新升级。
进化后的世界模型Matrix-3D,可以从一张山间草地的照片出发,创造出风吹草动、远山起伏的全景风光。


从现代城市的一角出发,它能「脑补」出画面之外,繁华的街道和大厦。


现在,我们不再需要多个视图,也不再局限于局部透视,而是真正实现了几何结构精确、可以360°自由漫游的3D世界。
值得一提的是,本周还是昆仑万维如火如荼的AI技术发布周,而Matrix-3D便是第二个出场的模型。
大模型赛道卷了两年,谁都在观望,下一个破局的方向在何方。
在这之中,李飞飞仅用3个月就实现10亿估值的World Labs也许能证明:具有空间智能的世界模型正是AI理解世界的下一个前沿。
最近,谷歌发布的Genie 3再次让所有人对「世界模型」充满期待,它能以每秒20-24帧速度,实时生成720p画面,还能持续数分钟一致性。

作为探索,昆仑万维也在今年2月时发布了自研的Matrix-Zero世界模型:
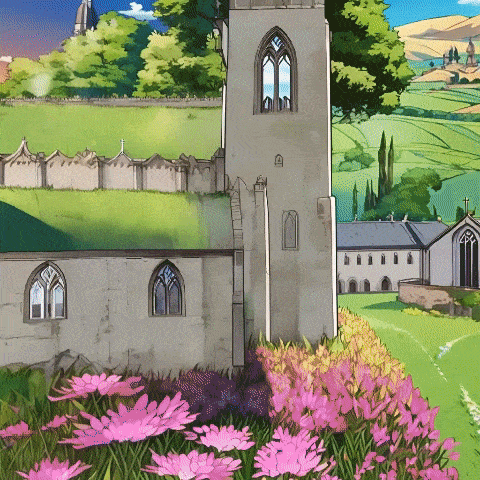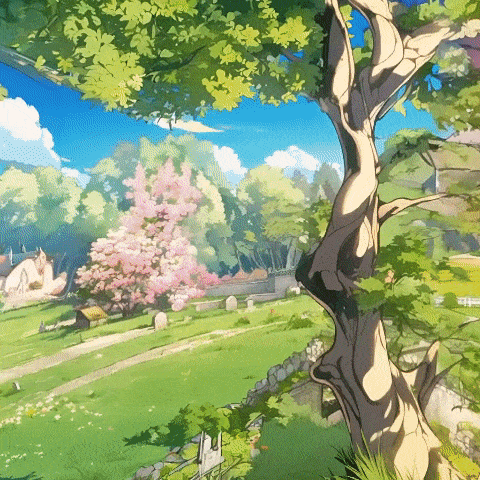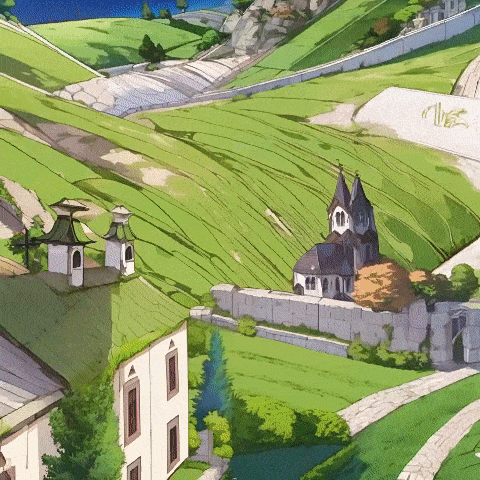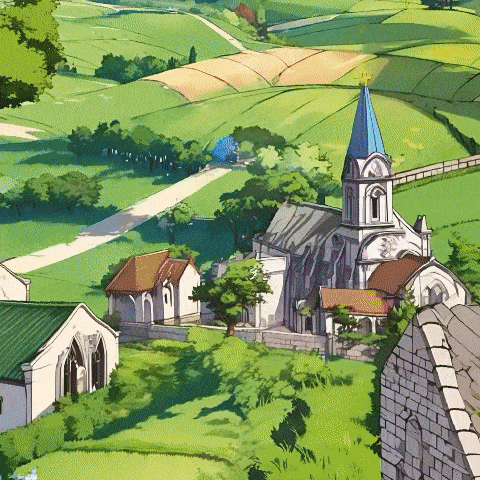
而这次全新发布的Matrix-3D,首次具备了「从一图入实境」的构建能力,让世界模型再次得到了进化:

技术报告:https://github.com/SkyworkAI/Matrix-3D/blob/main/asset/report.pdf
项目主页:https://matrix-3d.github.io/
Github:https://github.com/SkyworkAI/Matrix-3D
Hugging Face:https://huggingface.co/Skywork/Matrix-3D
接下来,我们就来直观感受一下,Matrix-3D的「威力」吧。
首先,不管是生成的内容还是颜色,都能做到统一一致。
其次,在视角上,Matrix-3D可以支持360°的自由环视。
一座有草屋顶的房子,风车,以及延伸至地平线远端的花田的动漫风格村庄,极为精细,暖光,舒适的氛围。


此外,物体之间的几何和遮挡关系,也能符合物理定律。
一幅印象派风格的冬日风景,包含山脉、湖泊、小屋、树木和积雪,以蓝色调为主,笔触质感丰富,氛围宁静,高分辨率,色彩鲜明。

Matrix-3D生成的全景视频如下:

而最终的3D场景渲染结果长这样:

一个方块像素化的景观,包含山脉、树木、水体、天空、云朵,类似《我的世界》风格,高分辨率,色彩鲜艳,纹理细节丰富,氛围宁静。


3D世界中,我们的视角通常会随心所欲地沿着不同路径,向各种各样的方向移动。
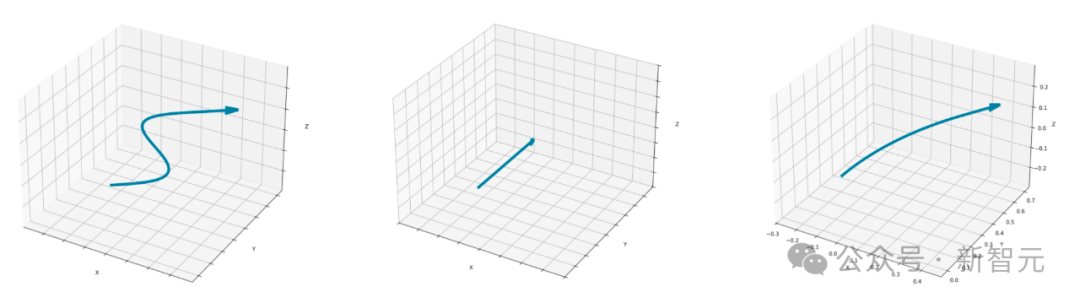
针对这些不同的轨迹,Matrix-3D能够生成与之对应的3D场景。

比如,沿着S形的弯折前行:

或者,向右前方移动:

对比李飞飞World Labs方法,Matrix-3D支持更大范围的移动。

可以看到,在World Labs发布的视频中,「我们」刚走两步,就碰到边界了。

类似的,Hunyuan World 1.0在边缘的生成上也存在问题。

相比之下,Matrix-3D「生成」的3D世界动态范围更大,视角更丰富,范围更广。

创造的意义就在于,我们可以根据已知来描绘「未知」。
Matrix-3D生成一段场景后,可以允许用户在此基础上对场景进行扩写。
比如一开始是一张静态图片,描绘了一座建在冰川上的未来研究基地,配有发光穹顶和先进机械,四周环绕着冰封景观,具有科幻美学风格,画面极为细致精美。

很快,Matrix-3D就根据图片渲染出了首段视频。
可以看到,画面镜头从图片开始缓缓前移,然后中途360°旋转回正。

但是,如果我们想继续知道「前路如何」呢?
Matrix-3D可以根据已经生成的全景视频继续完成续写,可以看到画面随着镜头继续前移,最终进入新的场景。

为了综合考虑生成速度和质量,Matrix-3D有两套场景生成框架——看中速度的「全景前馈重建」,以及看中质量的「3DGS优化」。
举个栗子,这是一张描绘河道的图片。

如果就是想要快速生成,那么全景前馈重建只需不到10秒,即可给出一个可360°观看的3D场景。

但如果希望得到更好的生成效果,就可以使用3DGS优化,让最终的场景既细致又准确,看上去就像真实拍摄的一样。

如果说经过30年发展的互联网世界为当下大模型时代提供了足够「优质」的训练数据。
那么3D场景数据的稀缺性,也正是目前制约空间智能、3D场景生成的重要原因之一。
为了获取3D数据,目前一种主流的研究方法是利用图像生成模型或者视频生成模型,作为三维生成的先验。
但这类方法存在一个根本性的缺陷:
由于训练过程主要基于透视图(Perspective View)进行,模型只能学习到局部视角下的有限空间结构。
一旦用户视角超出训练数据所覆盖的范围,场景就会出现明显的「边界效应」或「断层」。
如下图所示,这种不连续性会严重破坏用户的沉浸感,直接影响VR/AR等需要自由视角探索的下游应用体验。
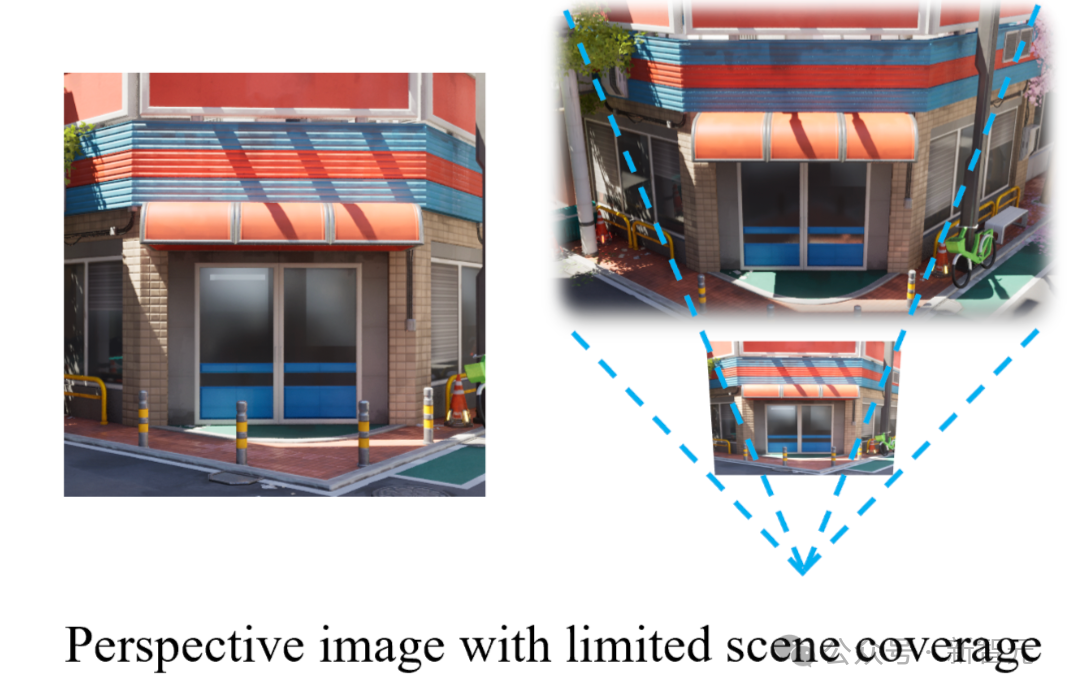
为了实现任意地点、任意角度的自由视角浏览,Matrix-3D引入了全景图像(Panoramic Images)作为场景生成的中间表达形式。
与传统透视图相比,全景图具备更全面的空间感知能力——
它能够覆盖360°水平视角和180°垂直视角,几乎囊括了人眼可见的全部方向,如下图所示,用户可以从任意角度对场景进行观察与探索。

更进一步,将多个地点的全景图顺序拼接,即可构建出一段连续的全景视频(Panoramic Video)。
这种结构不仅保留了各个观察点的空间信息,也为3D场景重建提供了充足的视觉线索,相当于以二维方式完整记录了三维世界的骨架与细节。
这为后续的3D世界生成奠定了数据基础,也极大提升了下游应用(如VR/AR)的沉浸式体验质量。
确定使用全景视频作为中间表达后,Matrix-3D设计了三个核心模块来实现3D世界生成:
每一个空间智能问题,最终还是要回归到数据集。
收集真实世界的3D场景数据仍然成本高昂,但是目前3D场景数据集存在规模小、视角不全、质量参差、缺乏精准相机/几何标注等问题。
于是,昆仑万维提出了Matrix-Pano数据集——这是一个基于Unreal Engine构建可扩展的全景视频数据集,专为生成高质量、可探索的全景视频而设计。

Matrix-Pano数据集具有以下特点:

同时,Matrix-3D的全景视频生成结果在全景视频生成评测集上也取得了最好的生成质量。
此外,Matrix-3D方法在生成结果的视觉质量和相机可控性层面都优于现有方法。
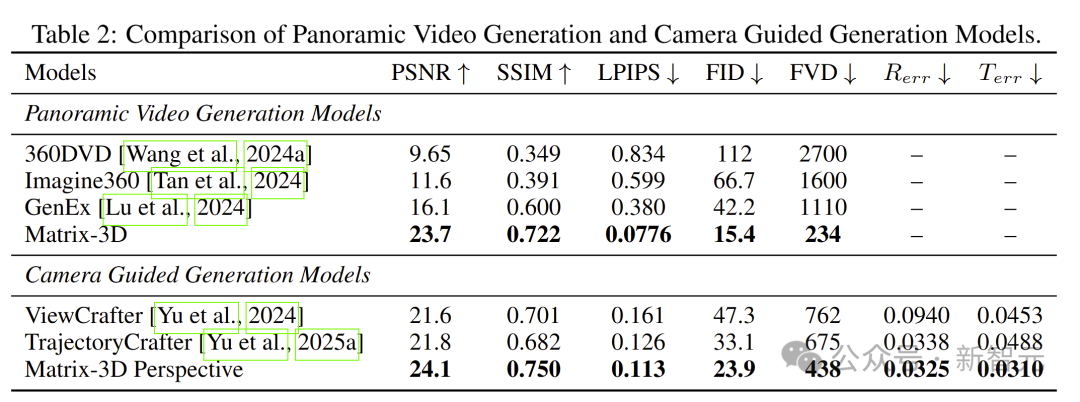

不同方法生成全景视频不同时刻对比图,其中Matrix-3D方法生成视频的质量更高、一致性更强(下方小图为四方向透视图)
轨迹引导是突破控制性与3D视觉质量的关键技术。
所以,首要问题是如何构建轨迹引导?

· Initial Panorama with depth:输入为带深度的全景图,提供基本的空间信息
· Trajectory guidance from point cloud:基于点云的轨迹引导
· Trajectory guidance from mesh:基于三角网格的轨迹引导方式
Matrix-3D根据输入的全景图像与深度图构建三维网格,并结合预设相机轨迹生成引导视频序列。
系统通过深度变化检测遮挡区域,标记不可见像素并剔除其对应顶点,确保遮挡关系清晰准确。
每一帧引导图像都配有可见性掩码,用于精确控制模型输入。
与传统点云渲染相比,该方法有效缓解摩尔纹和遮挡错误,提升了几何一致性和生成质量。
解决了轨迹引导,就可以进行全景视频生成。
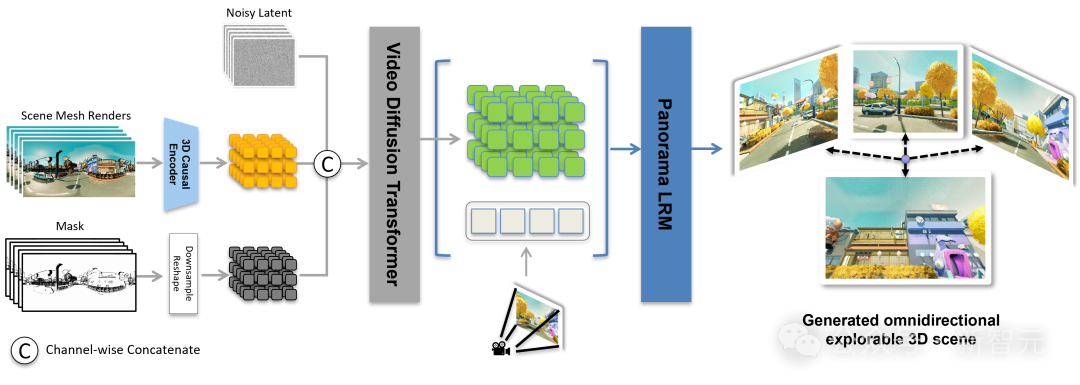
Matrix-3D通过一套「全景渲染+视频扩散」的流程,实现从2D全景图生成可自由探索的3D世界:
有了数据,也有了轨迹引导的可控全景视频。
那如何将全景视频还原为可自由探索的高质量3D场景呢?
Matrix-3D提供两种方案,将全景视频还原为可自由探索的高质量3D场景:
1. 优化式三维重建:追求极致画质
通过估算全景视频深度并结合相机轨迹生成点云,作为三维高斯渲染(3DGS)的基础输入。
进一步引入超分辨率提升视频质量,并将全景图裁剪为12个透视视角,实现高精度3D重建。
适用于对细节要求极高的场景,如虚拟仿真与高保真还原。
2. 前馈三维重建:主打高效快速
为了提升效率,直接从视频潜变量预测3DGS表达,显著降低计算成本。
通过Transformer+DPT解码器预测颜色、深度、尺寸、透明度等属性,并结合Plücker编码精准建模相机姿态。
采用专为全景图设计的CUDA光栅器实现无需多视角的高效渲染。
训练时采用两阶段策略,先引导模型学习几何,再优化真实渲染效果,兼顾准确性与泛化能力。

最左侧输入为视频潜变量+相机编码。
上支路:对视频潜变量进行 2D 卷积提取特征;下支路:对相机姿态(如 Plücker 编码)进行3D卷积处理,提取时空结构信息。
然后进行特征融合+Transformer 编码,两路特征拼接后送入多层Transformer进行全局建模,输出空间一致的语义表达。
最后是分支解码,第一分支预测深度图,为重建提供几何基础;第二分支预测3DGS的其他属性:颜色、尺寸、透明度、旋转方向等。
最终生成可自由视角探索的全景3D场景,具备真实感强、几何一致性好的空间体验。
Matrix-3D作为3D世界生成的重要里程碑,将在多个领域广泛应用:
游戏与影视制作:快速生成高质量3D场景,助力游戏开发与虚拟拍摄,提升沉浸感并显著降低制作成本。

具身智能:构建可控模拟环境,用于机器人训练与自动驾驶测试,提高系统的安全性与泛化能力。

虚拟现实:生成可360°自由探索的沉浸式虚拟空间,为用户带来真实可感的交互体验。

这些应用场景展示了Matrix-3D技术在不同领域中的重要性和多样性。随着技术的进步,这些应用将继续发展并带来更多创新。
从「一图生万境」到「无限宇宙皆可构建」,Matrix-3D 不仅是一项3D生成技术的突破,更是AI迈向空间智能时代的宣言。
它标志着——AI不再只是「解读」图像,而是真正能够「走进」世界;不再只是「构想」场景,而是切实具备「创造」现实的力量。
未来,想象力将成为探索世界的唯一边界。
而Matrix-3D,正在让这道边界彻底消失。
文章来自于微信公众号“新智元”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
