# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
设定角色,让AI照“本”生成主角不变的不同图像,对于各路AIGC工具来说一直是不小的挑战。
而现在,字节再进一步,最新发布多主体控制生成模型Xverse——
既可以对设定好的每个主体进行精确控制,也不会破坏图像的生成质量。


多主体?多光源?多风格?它说:安排!

那么Xverse是如何做到又稳又准的呢?
XVerse的核心是通过学习DiT(Diffusion Transformer,一种扩散模型和Transformer架构的生成模型)中文本流调制机制中的偏移量,实现对多个主体身份和语义属性的一致控制。
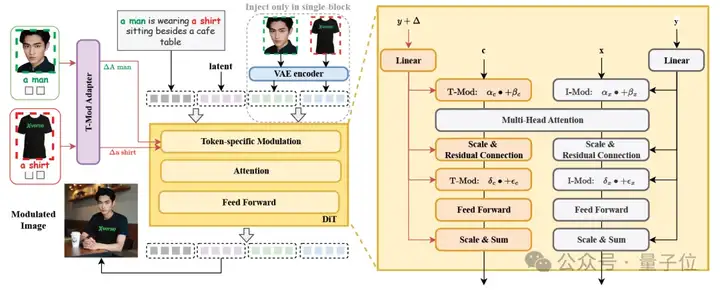
此方法包括四个关键组成部分:
T-Mod适配器
采用perceiver重采样器作为文本流调制的核心,将CLIP编码的图像特征与文本提示特征结合,生成交叉偏移量。通过对每个token进行精细调制,模型得以精准控制多个主体的表现。
文本流调制机制
将参考图像转换为文本流调制的偏移量,并将这些偏移量添加到注入模型的相应token嵌入中,同时调整原始的缩放和移位参数,以实现对生成过程的精确控制。
VAE编码图像特征模块
将VAE编码的图像特征作为辅助模块集成到单个FLUX模块中,增强了细节保留能力,使生成的图像更加逼真,同时最大限度地减少了伪影和失真的出现。
正则化技术
为了进一步提升生成的质量和一致性,XVerse引入了两种关键的正则化技术:
为了全面评估多主体控制图像生成能力,字节提出了XVerseBench基准测试。
该测试的数据集主题丰富多样,包含20种不同的人类身份、74种独特的物品,以及45种不同的动物物种或个体,共设有300个独特的测试提示。
不仅如此,XVerseBench还采用多维评估指标:
XVerse方法被用于与多种领先的多主体驱动生成技术进行对比,生成结果涵盖单主体和多主体任务,相关的量化数据详见下表。
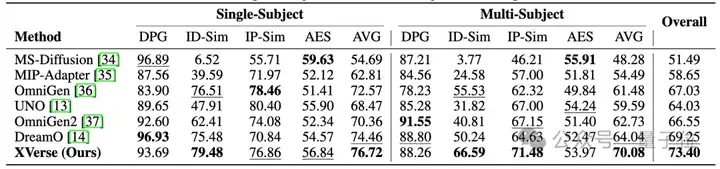
此外,XVerse在保持生成图像中身份与相关物体之间的一致性和关联性方面也表现出更强的能力。

△XVerse其他先进技术的定性对比
这不是字节第一次在AIGC一致性方向上发力。
字节跳动智能创作团队是字节跳动旗下专注于AIGC研发的核心技术团队,长期致力于推动AI在图像、视频、文本等多模态内容创作中的创新应用,开发前沿生成模型和算法,提升内容的质量、效率与多样性。
自2023年底上线的DreamTuner,该团队率先实现了“从一张图中学会记住一个人”的高保真身份保留。
紧接着,此团队于2024年又推出了DiffPortrait3D,将一致性从2D拓展到3D空间,实现多视角下的精准建模。
进入2025年,字节在动画生成方向发力,发布了OmniHuman-1,首次在音频驱动下实现人物动作与表情的自然一致,进一步推动人物生成从“像”走向“活”。
而在多任务统一建模上,4月亮相的DreamO则成为关键节点:基于DiT框架,不仅支持身份控制、虚拟换装、风格迁移等复杂任务,还实现了全流程中的稳定一致性。
这些研究成果均为XVerse的提出打下了坚实基础。
接下来,该团队的研究方向是,不断提升AI创作的智能化和趣味性,使其更加贴合人们的日常需求和审美体验。
论文地址:https://arxiv.org/abs/2506.21416
参考链接:https://bytedance.github.io/XVerse/
文章来自于“量子位”,作者“时令”。


